







目录
2.2Transformer中Encoder与Decoder区别
五.多头注意力机制-Multi-Head Self-Attention
5.1多头注意力机制-Multi-Head Self-Attention
一.Encoder
encoder:译为编码器,负责将输入序列压缩成指定长度的向量,这个向量就可以堪称是这个序列的语义。然后可进行编码或特征提取等操作
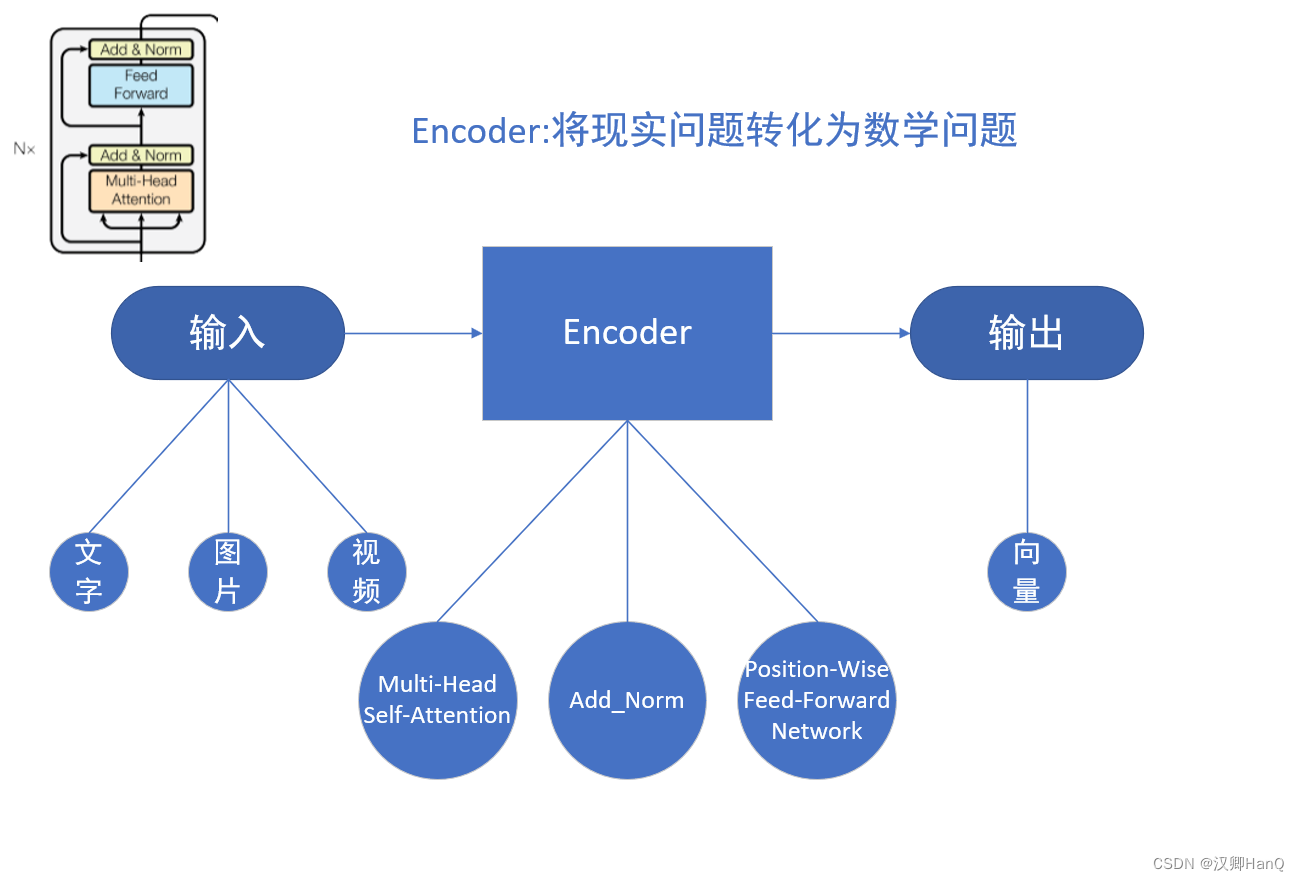
在transformer中encoder由6个相同的层组成,每个层包含
- Multi-Head Self-Attention
- Position-Wise Feed-Forward Network
Transformer中的Encoder可以看作多个Block组成,其中每个Block的输出由自注意力机制+残差链接+layerNorm+FC+残差链接+layerNorm组成

图片来源:Transformer 中 Encoder 结构解读_by 弘毅_transformer encoder_mingqian_chu的博客-CSDN博客
二.Decoder
Decoder:译为解码器,负责根据Encoder部分输出的向量c来做解码工作(推荐先看 三.注意力机制 再回头看二.Decoder)
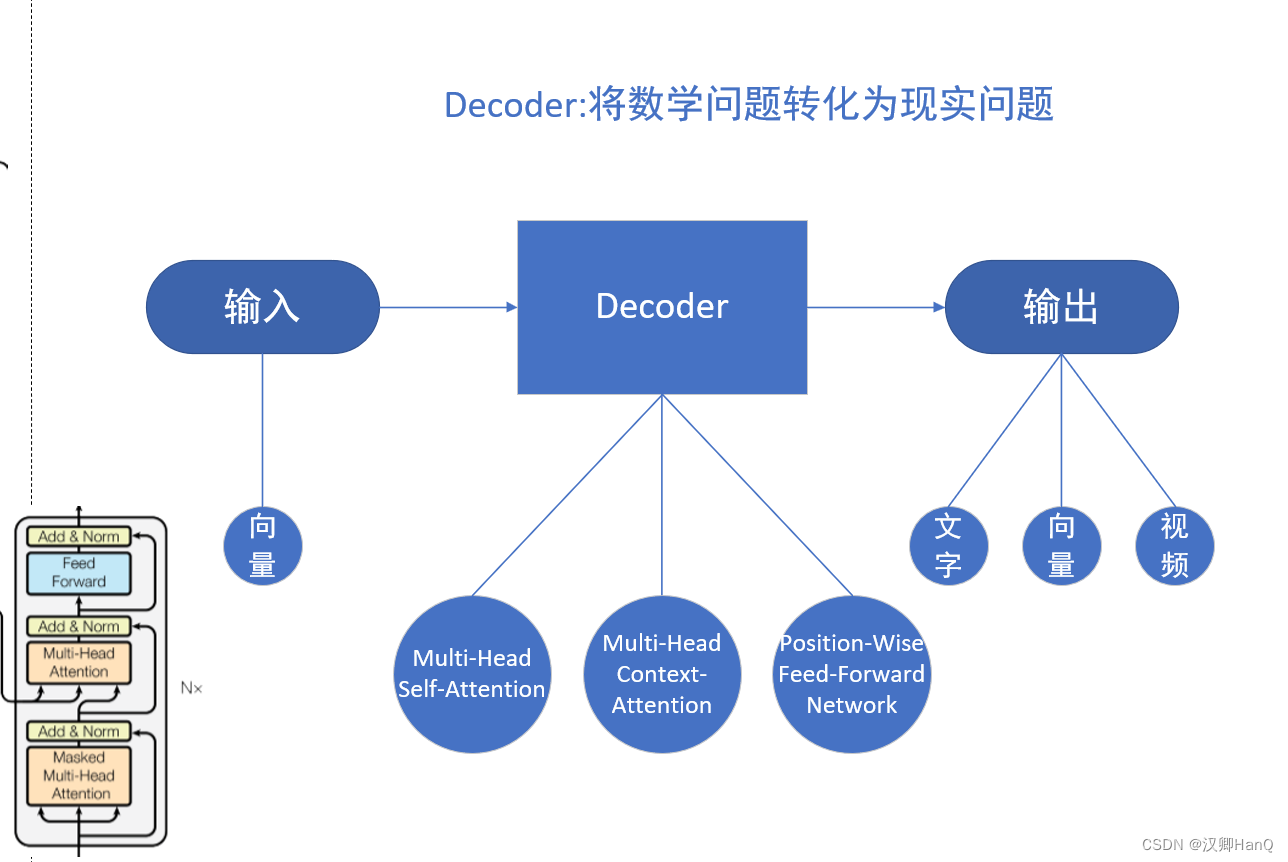
2.1Transformer的Decoder
在Transformer中的Decoder由6个相同层组成,其中每个层包含
- Multi-Head Self-Attention
- Multi-Head Context-Attention
- Position-Wise Feed-Forward Network
2.2Transformer中Encoder与Decoder区别
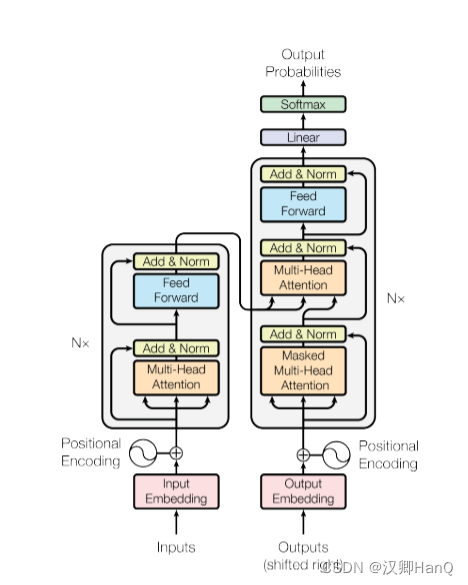
1.第一级中: 将self attention 模块改成了 masked self-attention, 用于只考虑解码器的当前输入和当前输入的左侧部分, 不考虑右侧部分; ( 注意,第一级decoder的key, query, value均来自前一层decoder的输出,但加入了Mask操作,即我们只能attend到前面已经翻译过的输出的词语,因为翻译过程我们当前还并不知道下一个输出词语,这是我们之后才会推测到的。)
2.第二级中,引入了 Cross attention 交叉注意力模块: 在 masked self-attention 和 F C FCFC 全连接层 之间加入;
Cross attention 交叉注意力模块的输入 Q,K,V 不是来自同一个模块: 而是来自K , V K,VK,V 来自编码器的输出, Q QQ解码器的输出
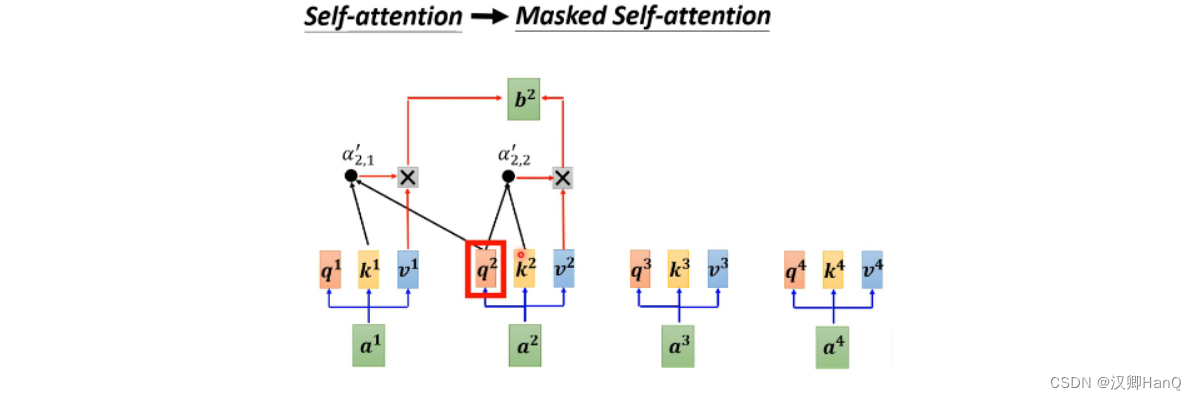
2.3Masked self attention
只需考虑输入向量本身和输入向量只爱按的向量,即左侧向量。在求相关性分数时,q,k,v也只会考虑输入 向量的左侧向量部分
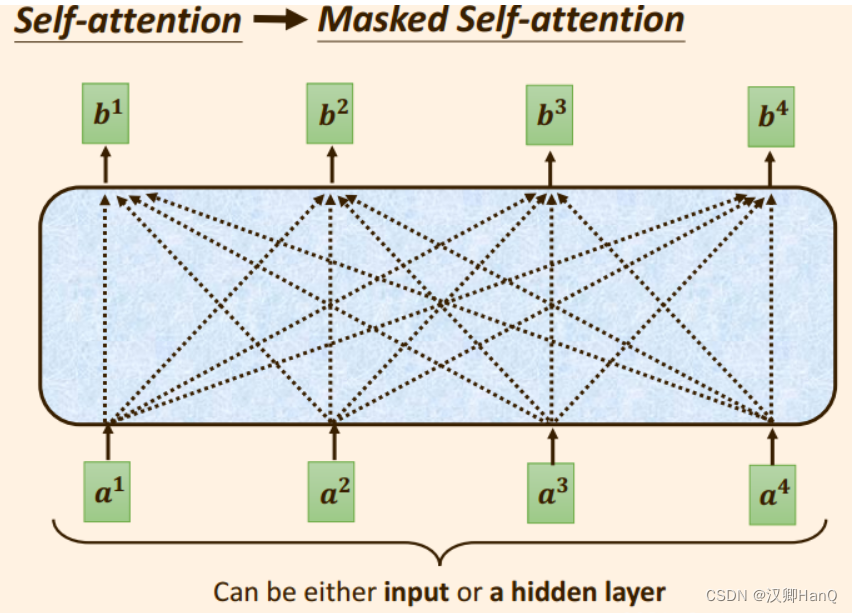
- 输出向量b1,只考虑输入向量a1(k1)
- 输出向量b2,只考虑输入向量a2(k2)和a2之前的输入向量a1(k1)
- 输出向量b3,只考虑输入向量a3(k3)和a3之前输入的向量a2(k2),a1(k
2.3Cross attetion
Cross attetion模块又成为交叉注意力模块,之所以叫做交叉,是因为向量q,k,v不是来自同一个模块,而是将来自解码器的输出向量q与来自编码器的输出向量k,v运算。
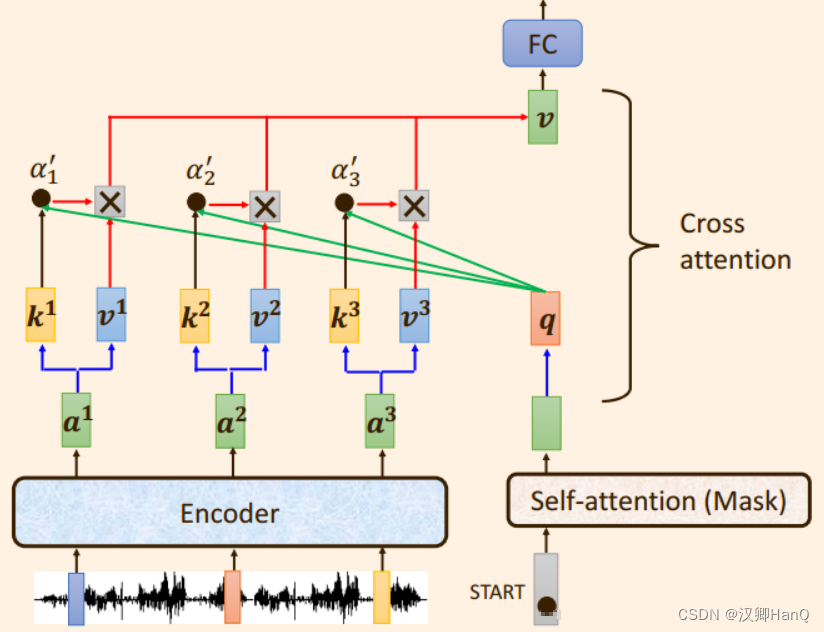
q与v相乘得到注意力得分α1'
注意力得分α1'再与v相乘求和得到向量v
2.4Transformer训练过程
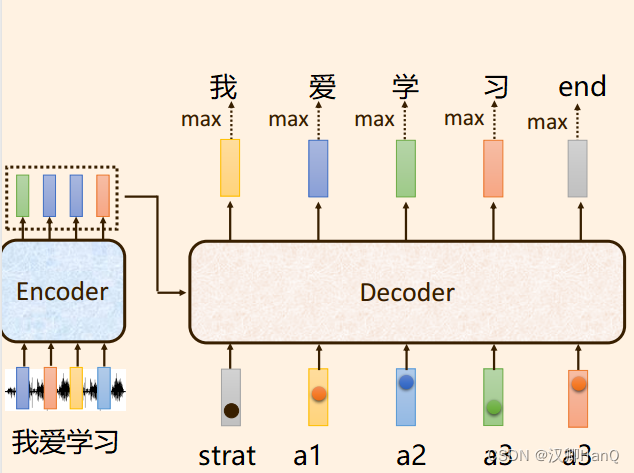
- Encoder将输入数据转换为向量,同时会输入一个启动标志向量Start
- Masked self attention:解码器之前的输出,作为当前解码器的输入。并且在训练过程中,真是标签也会输入到解码器中,得到输出向量q
- Cross attention:将向量q与来自编码器的输出向量k,v运算,得到向量v
- 将向量v输入到feed-forward全连接层
三.注意力机制-attention
3.1注意力机制-attention
注意力机制:注意力机制来源于人对外部信息的处理能力。由于人每一时刻接收的信息都是庞大且复杂的,因此人在处理信息的时候,会将注意力放在需要关注的信息上,对于其他无关的外部信息进行过滤。
对于计算机而言,对数据赋予权重,越重要的地方或者越相关的地方就赋予的权重越高
可以理解成,当我们看人的时候要看脸,看书的时候看书名等等
3.2Query&key&Value q,k,v
| Query 查询 | 查询的范围 | 自主提示 | 主观意识的特征向量 |
| Key 键 | 被比对的项 | 非自主提示 | 物体的突出特征信息向量 |
| Value | 物体本身的特征详细,与key成对出现 |
注意力机制是通过Query与Key的注意力汇聚,实现对Value的注意力权重分配,生成最终的输出结果(给定一个Query,计算Query与Key的相关性, 然后根据Query与Key的相关性找到最合适的Value)

Query可以理解为在搜素时输入的关键字(外套),然后系统会根据这个关键则取查找一系列的Key (商品名称),最后得到相应的value(xx牌衣服)
q,k,v每个属性虽然在不同的空间,但他们是具有一定的潜在关系,可以通过某种变换,使得三者属性在一个相近的空间中
3.3注意力机制计算
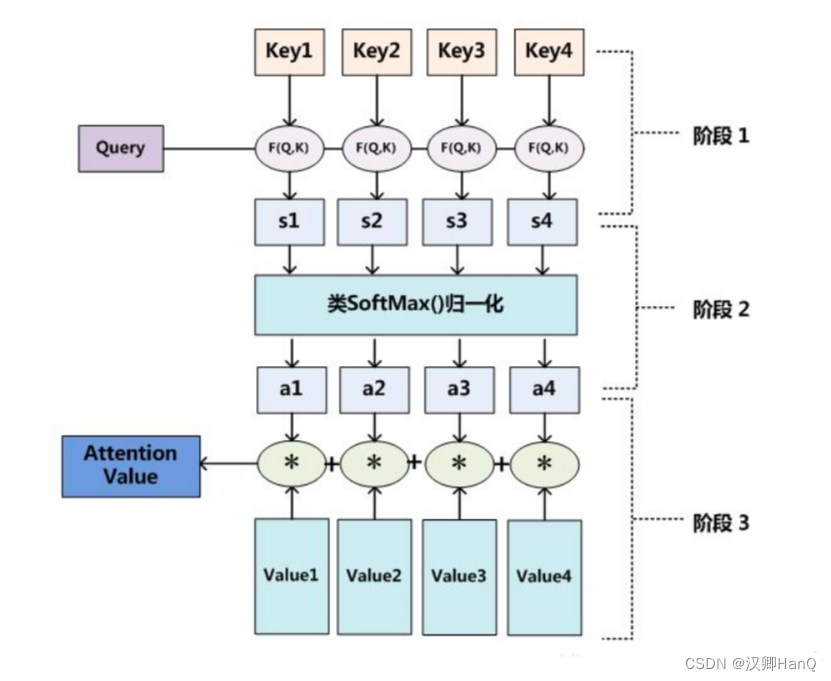
- 阶段一:计算q,k两者之间的相关性或相似性,得到注意力得分

MLP网络请见:全连接神经网络(MLP)_mlp网络_awigu的博客-CSDN博客
- 阶段二:对注意力得分进行缩放scale (除以维度的根号),然后使用softmax函数进行归一化,还可以更加突出权重
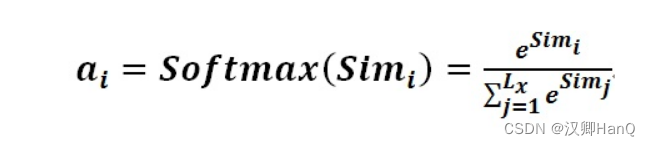
- 阶段三:根据权重系数是对v进行加权求和,得到Attention Value

四.自注意力机制-Self-Attention
4.1自注意力机制-Self-Attention
自注意力机制是注意力机制的一种,解决神经网络接收的输入是很多大小不一的向量,并且不同向量之间又一定的关系,但实际训练的时候无法发挥这些输入之间的关系导致模型训练结果效果极差(机器翻译序列到序列,语义分析等),针对全连接神经网络对于多个相关的输入无法建立起相关性问题,可以通过自注意力机制解决,实际上让机器注意到整个输入中不同部分之间的相关性。
自注意力机制减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性,且q,k,v都来自同一个x,通过x在x内部找关键点。
4.2自注意力机制计算
- 得到q,k,v
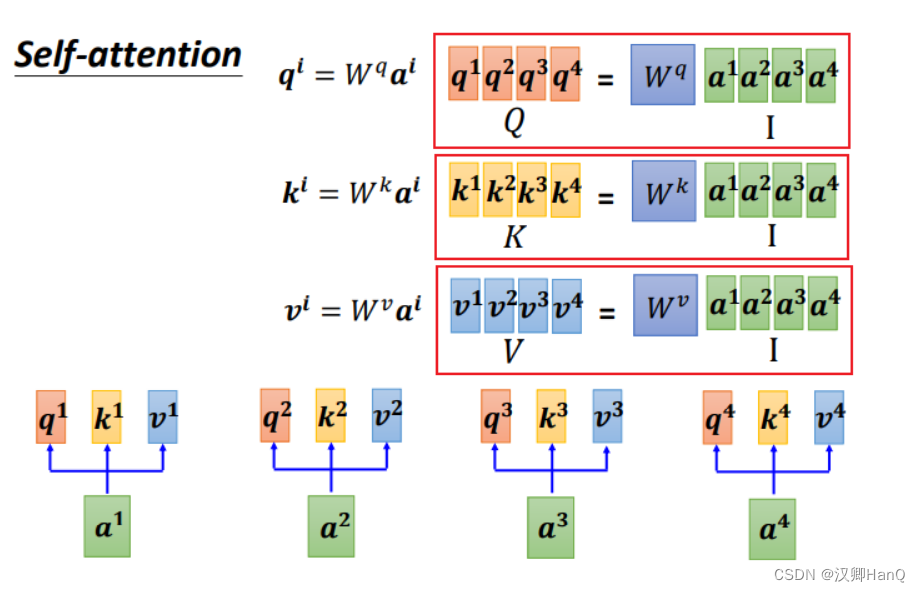
对于每个输入乘上相应的权重矩阵W,得到相应的矩阵q,k,v
- 计算相关性
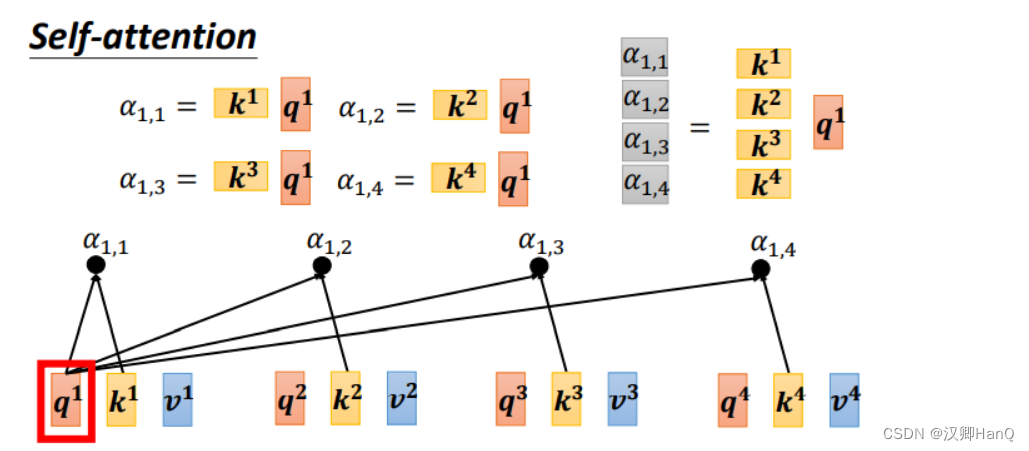
利用得到的q,k计算两个向量之间的相关性,一般用点积计算,即α=q·k ,矩阵形式为A=K^T·Q

- Scale+softmax
将上一步得到的相似度除以d^1/2,再进行softmax归一化
- Matmul
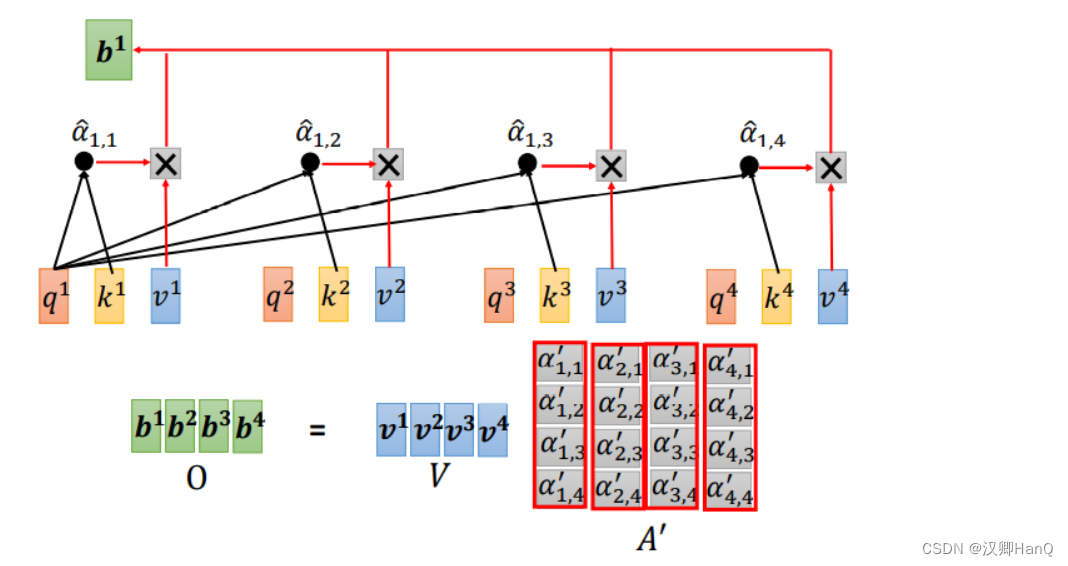
使用权重矩阵与v相乘,计算加权求和
4.3自注意力机制缺点
自注意力机制的原理是筛选重要信息,过滤不重要信息,这就导致其有效信息的抓取能力会比CNN小一些。这是因为自注意力机制相比CNN,无法利用图像本身具有的尺度,平移不变性,以及图像的特征局部性(图片上相邻的区域有相似的特征,即同一物体的信息往往都集中在局部)这些先验知识,只能通过大量数据进行学习。这就导致自注意力机制只有在大数据的基础上才能有效地建立准确的全局关系,而在小数据的情况下,其效果不如CNN。 另外,自注意力机制虽然考虑了所有的输入向量,但没有考虑到向量的位置信息。
五.多头注意力机制-Multi-Head Self-Attention
5.1多头注意力机制-Multi-Head Self-Attention
多头注意力机制:用独立学习得到的h组(一般为8)不同的线性投影来变换q,k,v,然后这h组变换后的q,k,v并行的送到注意力汇聚中,最后将这个h个注意力汇聚的输出拼接到一起,并通过另一个可以学习的线性投影进行变化,一产生最终输出。
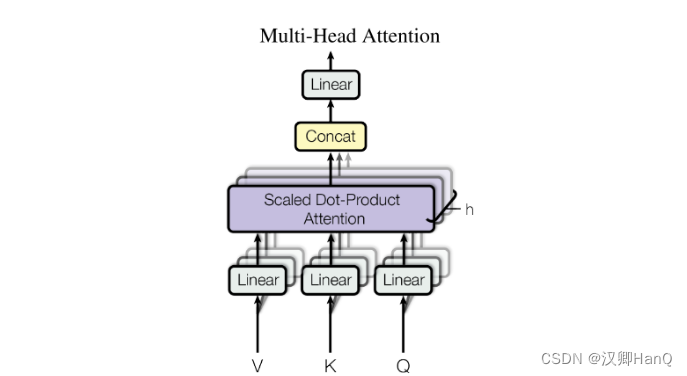
5.2多头注意力机制计算
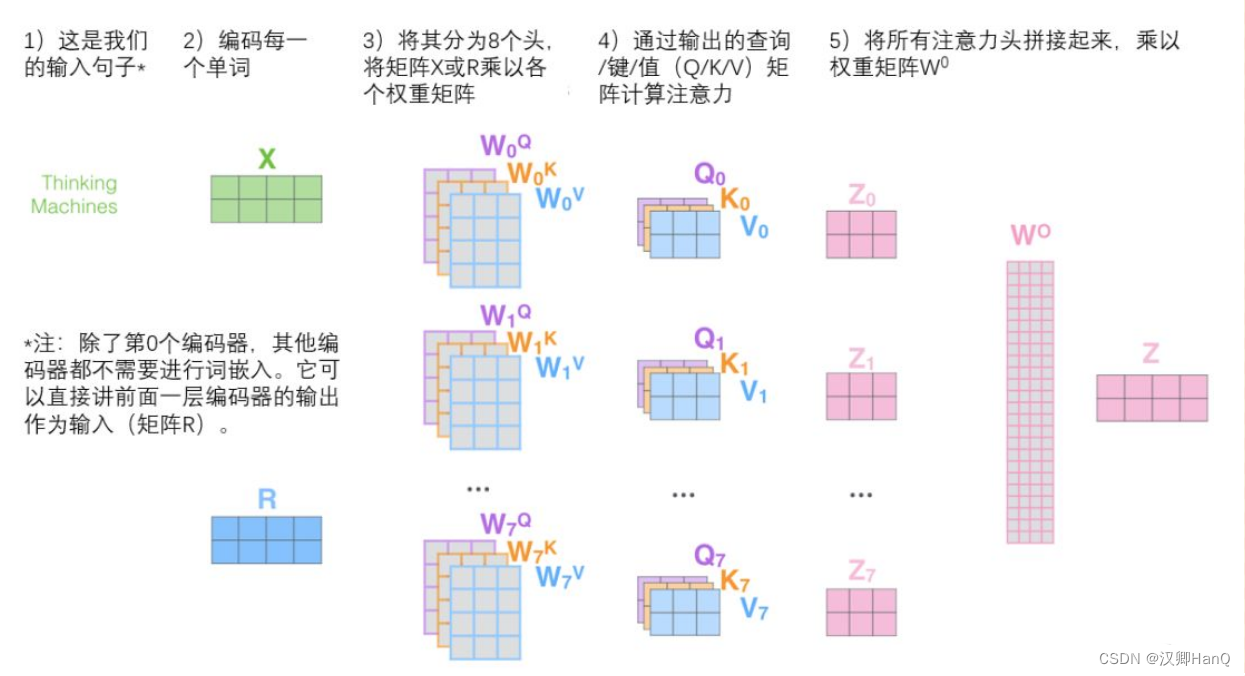
- 定义多组W,生成多组Q,K,V
- 定义h组参数,对应h组W,再分布进行Self-Attention,得到Z0-Z7
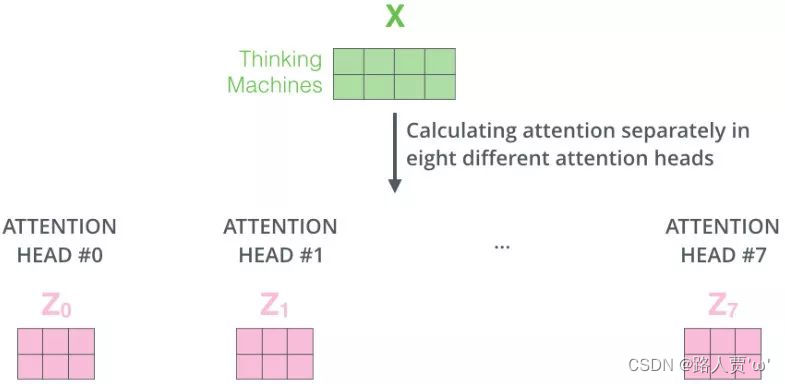
- 将多组输出拼接后乘W0降维

图片来源:注意力机制到底在做什么,Q/K/V怎么来的?一文读懂Attention注意力机制 - 知乎
六.通道注意力机制-Channel Attention
6.1通道注意力机制-Channel Attention
通道注意力是显示再模型不同通道之间的相关性。通过网络学习的方式来自动获取到每个特征通道的重要程度,最后再为每个通道赋予不同的权重系数,从而来强化重要的特征抑制非重要的特征。
其目的在于让输入的图像更有意义,通过网络计算出输入图像各个通道的重要性(权重),从而提高特征表示的能力
6.2常用注意力机制
- SENet
- ECA
- CBAM
七.空间注意力机制-Spatial Attention
不是图像中所有的区域对任务的贡献都是同样重要的,只有任务相关的区域才是需要关心的,比如分类任务的主体,空间注意力模型就是寻找网络中最重要的部位进行处理。空间注意力旨在提升关键区域的特征表达,本质上是将原始图片中的空间信息通过空间转换模块,变换到另一个空间中并保留关键信息,为每个位置生成权重掩膜(mask)并加权输出,从而增强感兴趣的特定目标区域同时弱化不相关的背景区域。
















 681
681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









