







一、 单细胞测序技术简介
**单细胞测序技术(single cell sequencing)**是指在单个细胞水平上,对基因组、转录组、表观组进行高通量测序分析的一项新技术,它能够弥补传统高通量测序的局限性,揭示单个细胞的基因结构和基因表达状态,反映细胞间的异质性。
我们经常看到的scRNA-seq其实就是single cell RNA-seq的缩写,即单细胞RNA测序,或叫单细胞转录组测序。
上图为单细胞发展的过程,横坐标为时间轴,纵坐标为单次研究中的细胞数。可以看出单细胞测序从2009年开始发展,起初也只能检测一个细胞,到目前已经能检测上万细胞,并且中间也不断出现一些新的技术。

二、单细胞测序优势
(1)解决样本量太少无法进行常规测序的问题
(2)解决细胞间异质性问题
(3)避免PCR扩增偏好性问题
关于单细胞测序的这三个优势,其中第二个提到的比较多,大部分关于单细胞测序的介绍都会提到。第一点很好理解,所以这里也只介绍一下第二点和第三点。
单细胞测序解决细胞间异质性的问题,也是单细胞的主要优势,因为它是基于单细胞水平的测序,所以它相对于之前的bulk RNA-seq,它能捕获每个细胞内的基因表达情况,而不只是一块组织或一个血样所有细胞内基因的平均值。
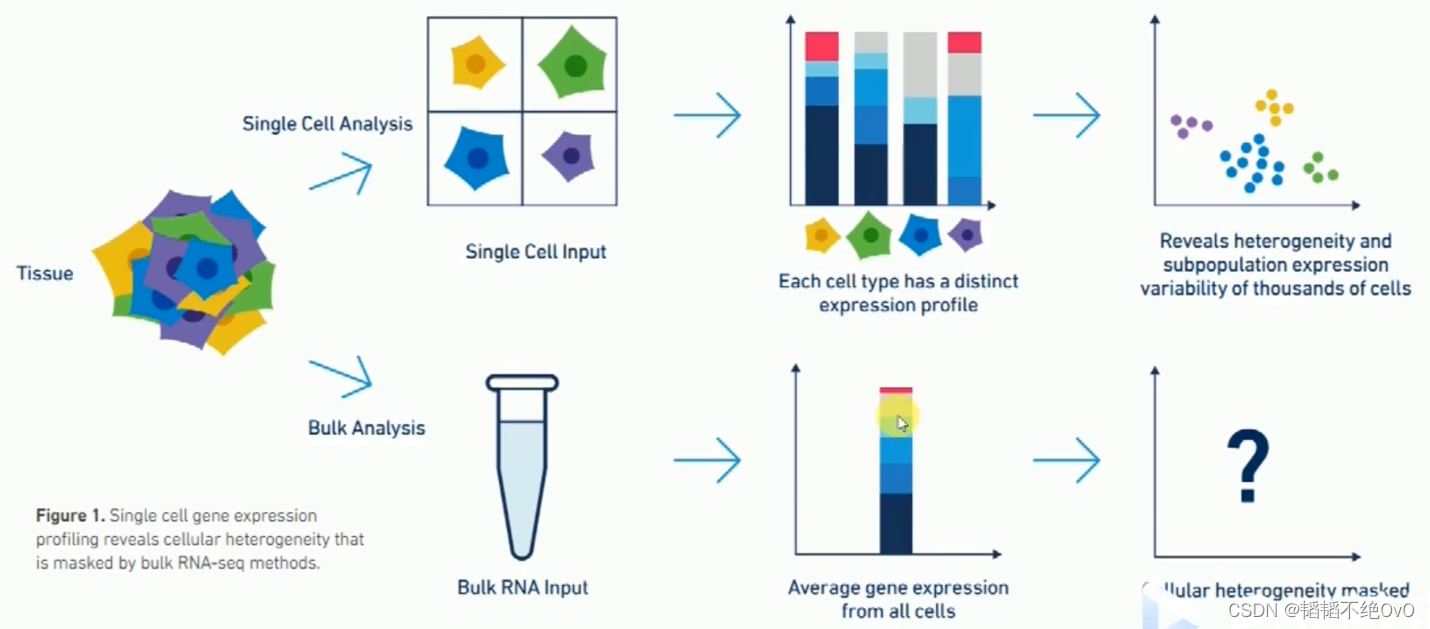
这个图依然可以说明上述问题,Bulk RNA-seq它是把所有细胞都混在一起直接测定的,所以它只能获得所有细胞内基因的平均值,对于获得的任何一个基因的表达值,都是在所有细胞的均值。而单细胞测序是首先把每个细胞进行一个分离,从而捕获每个细胞的表达情况,它是获得了每个基因在每个细胞内的表达情况,所以它的下游可以进行更加精细的分析。
关于第三点优势,单细胞测序避免PCR扩增偏好性的问题。我们知道很多情况下的测序都是需要进行PCR扩增的,但是扩增有一个问题,就是在扩增的时候不同核酸序列在同样的条件下扩增程度是不一样的。有些核酸序列容易被扩增,有些核酸序列不容易被扩增,导致在同样时间同样条件下可能获得不一样的扩增倍数,所以扩增后的核酸序列丰度与扩增前是有一定的差异的。单细胞测序能够避免PCR扩增偏好性,并不是在扩增本身有了技术变革,而是因为它所计算的不是扩增后的核酸序列的相对丰度,而是计算了扩增前核酸序列的实际数值。
三、单细胞测序原理
(1)10X Genomics单细胞测序原理
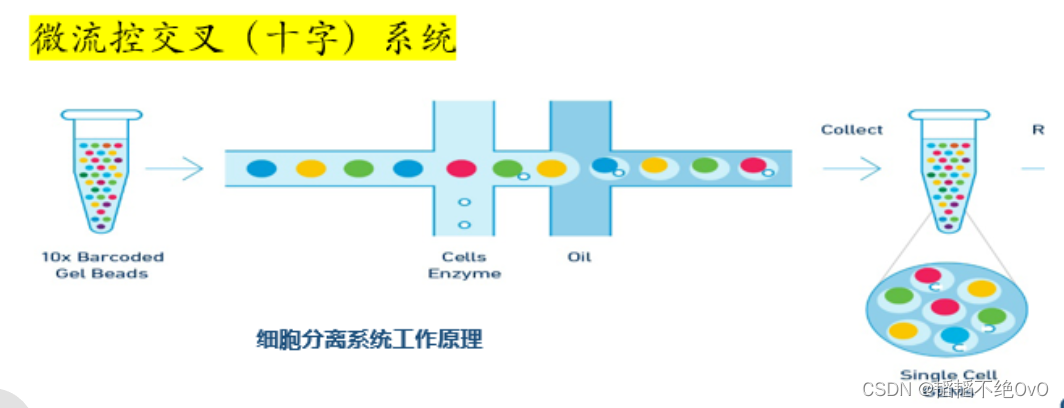
上图是10X单细胞测序的原理图。首先要说明的是,单细胞测序和Bulk RNA-seq测序的区别,并不是测序本身的区别,它们同样是基于二代测序技术进行的测序,它们的区别主要是体现在前期对细胞的处理上。
我们从上图可以看出,10X的单细胞测序需要经过一个双十字系统,经过这个系统才能达到单细胞水平的捕获。在图最左边是带有标记的凝胶微珠,在这个系统中凝胶微珠沿着横向通道向右流动。在第一个十字交叉的地方,放进去细胞悬液和酶,这里的细胞是提前制备的单细胞的悬液。在第一个十字位置,凝胶微珠和细胞及相关酶相遇,一起向右流动。在第二个十字位置,与油相遇,形成一个个包裹着凝胶微珠和细胞的油珠,一起到右边的位置,被收集起来。这样一个细胞和一个凝胶微珠在一起,并处在独立的空间内。
当这样包裹一个细胞和一个凝胶微珠的油珠被收集之后,细胞就会在酶的作用下破裂,释放出细胞内的RNA,这些RNA就会连接到凝胶微珠上。那为什么释放出来的RNA会连接到凝胶微珠上呢?我们看下边这个图。
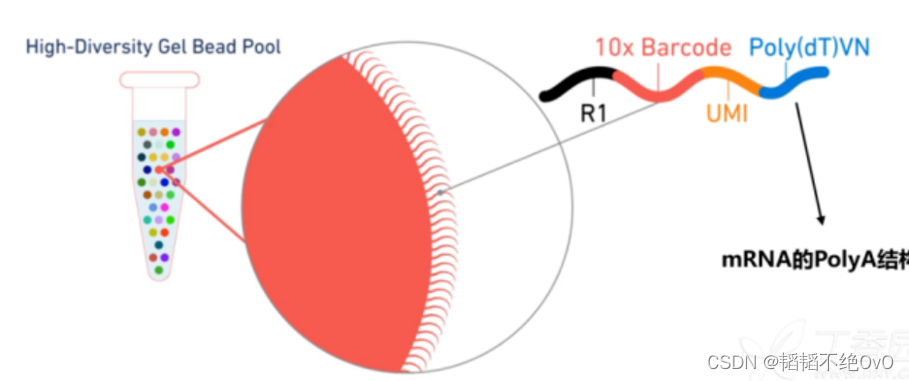
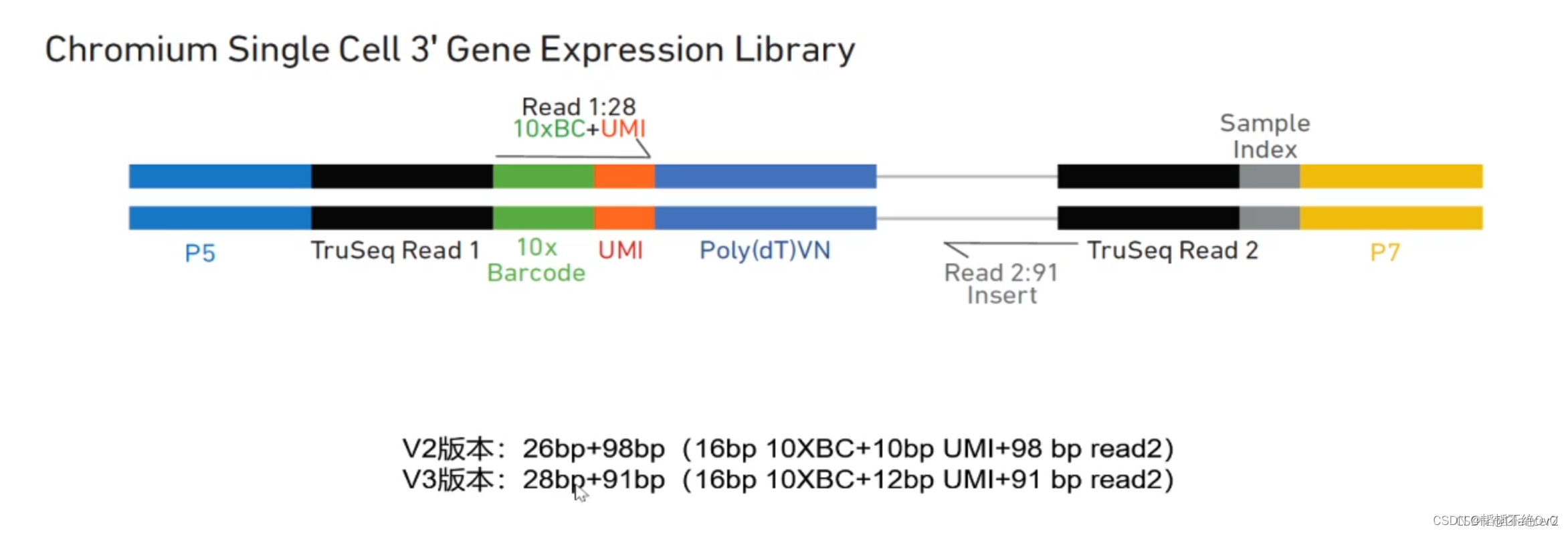
原来在凝胶微珠表面覆盖了一层短的核酸序列,这些短的核酸序列都是由4部分构成:R1、10X Barcode、UMI和Poly(dT)VN。其中Poly(dT)VN部分是富集T(胸腺嘧啶)的序列,我们知道在RNA的3’末端有一个polyA的尾巴,所以当RNA被释放出来的时候,它的polyA尾巴刚好和凝胶微珠上的poly(dT)VN序列结合,一个RNA连接到凝胶微珠上的一个序列。每个Gel Beads 上都会有多段特殊序列,是预先制备的,我们以红色框选中的一段序列说明。
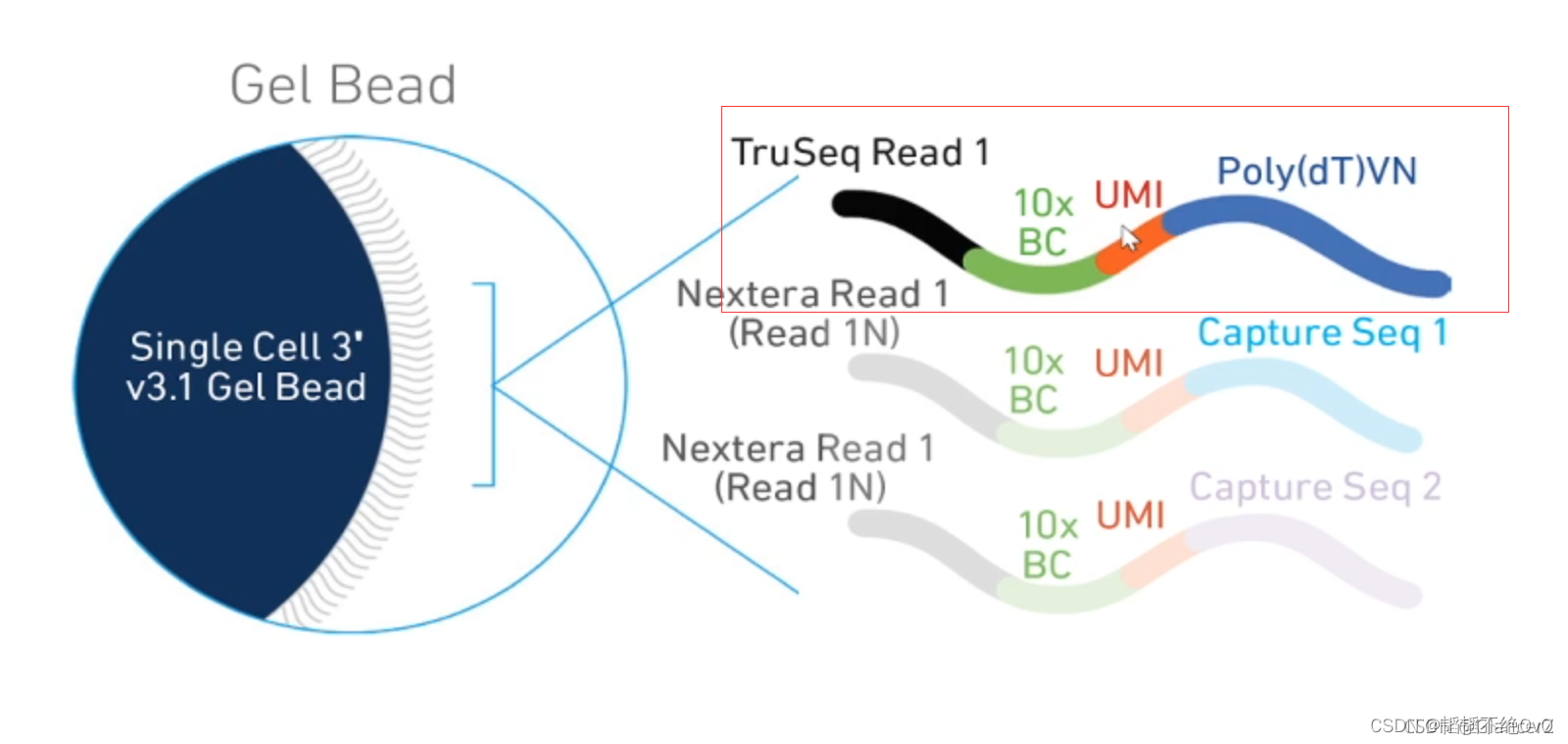
Read1是上游引物。
10xBarcode是一段16nt的核苷酸序列(序列空间350万),在每一个Gel Beads中的Barcode序列都是一致的,在后面Barcode与细胞融合形成水凝珠之后,可以保证一个细胞的所有基因序列都带着相同的Barcode序列,也就可以认定这些序列来自同一个细胞。所以我们通常说Barcode序列是用来标记细胞的。
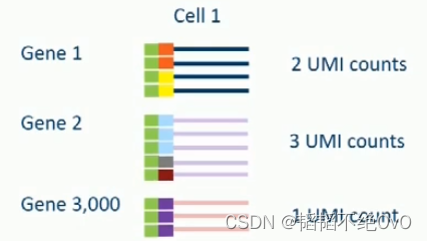
UMI是一段12nt的核苷酸序列(序列空间100万),但与Barcode序列不同的是,一个Gel Beads中UMI序列是不同的。UMI序列的空间很大,远多于需要检测的原始细胞的mRNA数量,(即使一种mRNA有多条,也是达不到UMI的序列空间的)。所以每一条mRNA都会带上一个独特的UMI。
UMI的作用是绝对定量,因为每个mRNA的扩增效率是不一样的,即使两个初始的mRNA表达量一致,在多轮扩增之后,我们也会误认为他们差异表达。UMI通过初始的标记,让我们可以统计扩增后UMI的种类就可以知道原始的表达量了。
PolyT用来匹配PolyA,以捕获mRNA。















 9036
9036











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









