







1 方法简介
在本设计中采用了Transformer-LSTM和Attention模块分别对文本、音频和图像特征进行建模,并通过Tensor Fusion Network (TFN) 实现最终的特征融合,以下将详细介绍模型的架构及核心模块的原理。
文本特征处理:结合Transformer编码器和双向LSTM对文本序列建模。
音频和图像特征增强:通过SEAttention分别对音频和图像特征进行增强。
多模态特征融合:通过交叉注意力和TFN对三种模态的特征进行联合建模与融合。
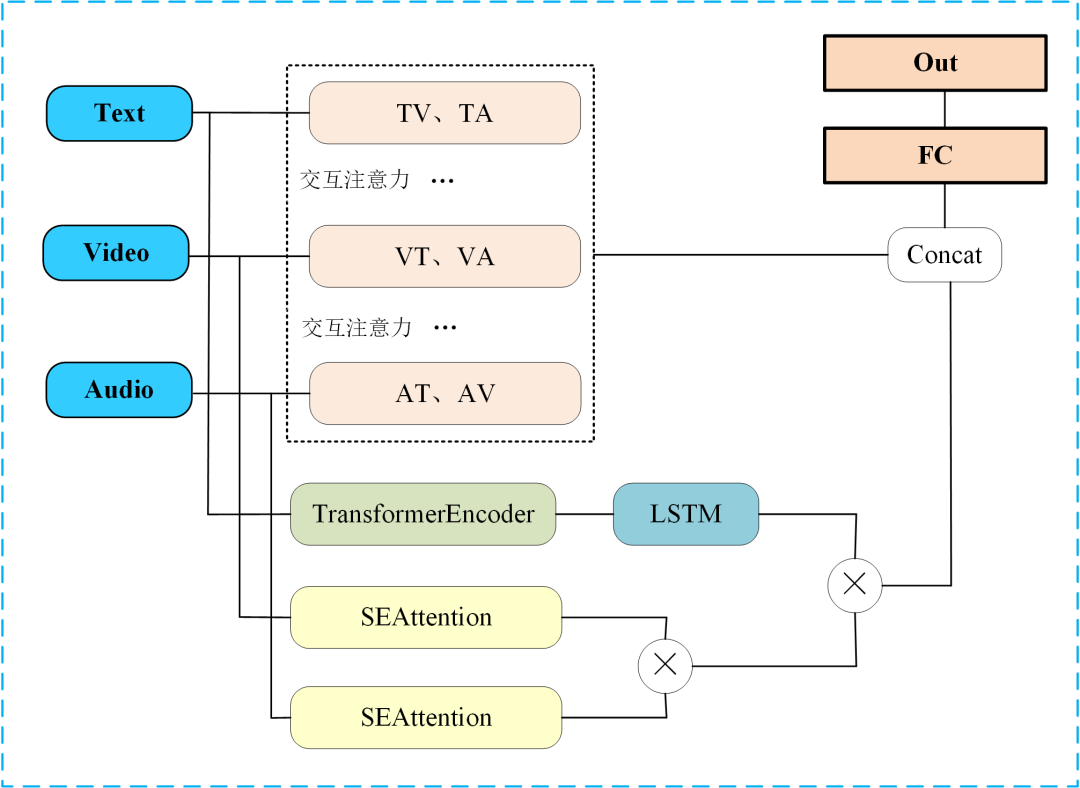
(1)文本特征处理
文本数据具有序列性和上下文相关性,Transformer和LSTM的结合能够有效捕获全局依赖和时间序列信息。Transformer编码器是模型的第一部分,负责从输入序列中提取全局特征。其核心是自注意力机制和前馈网络。Transformer通过自注意力机制捕获序列中每个位置的全局依赖关系。核心公式如下:
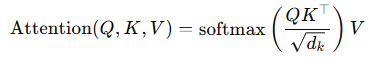
Transformer的全局建模能力可以捕获长期依赖,但其序列建模能力有限。为此,引入双向LSTM进一步提取时间
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 978
978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











