









1.方法简介
(1)论文参考地址
Zhang, Rongyu et al. “Unimodal Training-Multimodal Prediction: Cross-modal Federated Learning with Hierarchical Aggregation.” ArXiv abs/2303.15486 (2023): n. pag.
https://doi.org/10.48550/arXiv.2303.15486
(2)论文方法简介
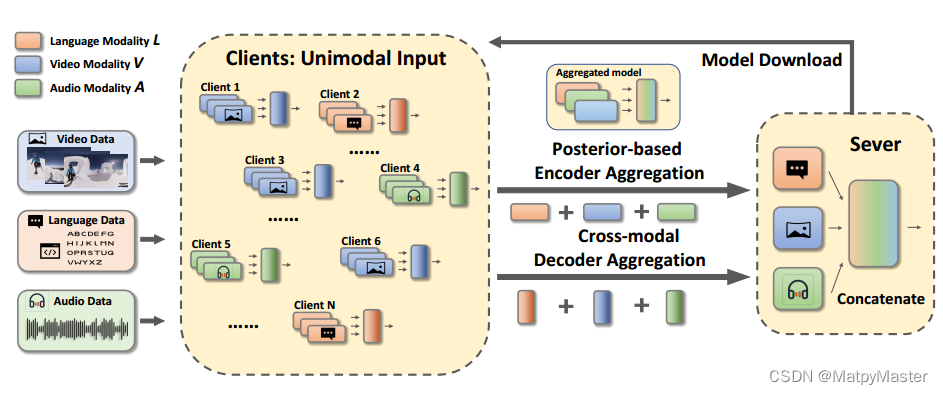
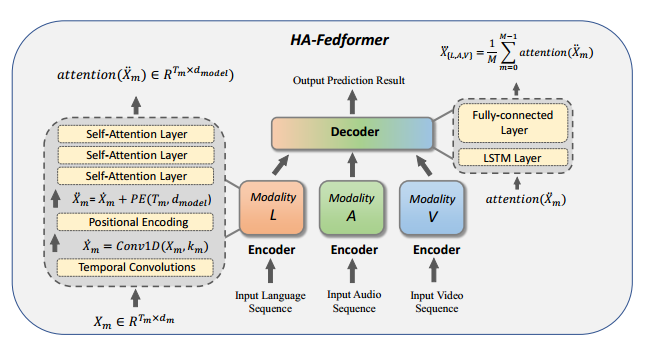
通过在多模态联邦学习的背景下提出单模态训练-多模态预测(UTMP)框架来弥合这一差距。设计了HA-Fedformer,这是一种基于变压器的新型模型,可以在客户端仅使用单模态数据集进行单模态训练,并通过聚合多个客户端的知识来进行多模态测试,以提高准确性。将特征提取层和预测层分开来处理分层聚合。具体来说,引入了一个基于Transformer的编码器用于特征提取和一个基于RNN的解码器用于预测。基于这些结构,我们提出了基于后验的编码器聚合(PbEA)和跨模态解码器聚合(CmDA),分别处理编码器和解码器参数。HAFedformer的整体架构如图所示。
2.数据集介绍
(1)下载地址
https://multibench.readthedocs.io/en/latest/start/datadownload.html
(2)模态介绍
CMU-MOSI数据集和CMU-MOSEI数据集的模态有3种(语言,视觉,声音),数据集使用的是已对齐原始raw数据特征。
(3)标签介绍
既有情感标注又有情绪标注。情感标注是对每句话的7分类的情感标注,作者还提供了了2/5/7分类的标注。情绪标注是包含高兴,悲伤,生气,恐惧,厌恶,惊讶六个方面的情绪标注。数据集是多标签特性,即每一个样本对应的情绪可能不止一种,对应情绪的强弱也不同,在[-3~3]之间。
(4)评价标准
均方误差(MSE)、平均绝对误差(MAE)、Pearson相关性(Corr)、二元精度(Acc-2)、F-Score(F1)和多级精度(Acc-7)范围从-3到3。对于除MAE以外的所有指标,相对较高的值表示较好的任务性能。本质上,提出了两种不同的方法来测量Acc-2和F1。在第一种,负类的标注范围为[-3,0),而非负类的标注范围为[0,3]。第二种,负类和正类的范围分别为[-3,0)和(0,3]。
3.代码示例
def init_argparse():
import argparse
parser = argparse.ArgumentParser(description="多模态联邦学习")
parser.add_argument("--path", type=str, default='data/MOSEI/mosei_raw.pkl', help="数据路径")
parser.add_argument("--epochs", type=int, default=300, help="训练轮数")
parser.add_argument("--batch_size", type=int, default=512, help="训练时的批大小")
parser.add_argument("--num_workers", type=int, default=0, help="子进程数量")
parser.add_argument("--data_type", type=str, default='mosei', help="要加载的数据类型")
parser.add_argument("--max_seq_len", type=int, default=50, help="最大序列长度")
parser.add_argument("--optimizer", type=str, default='AdamW', help="优化器")
parser.add_argument("--lr", type=float, default=0.001, help="学习率")
parser.add_argument("--weight_decay", type=float, default=1e-5, help="权重衰减")
parser.add_argument("--seed", type=int, default=1234, help="随机种子")
return parser4.运行结果
以CMU-MOSI和CMU-MOSEI为例,在测试集上的结果分别如下:
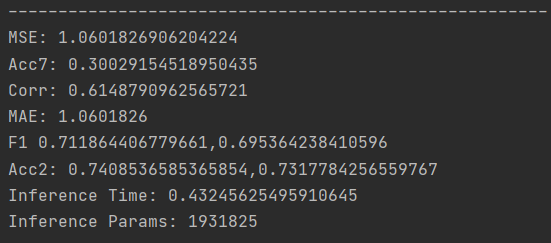
CMU-MOSI数据集
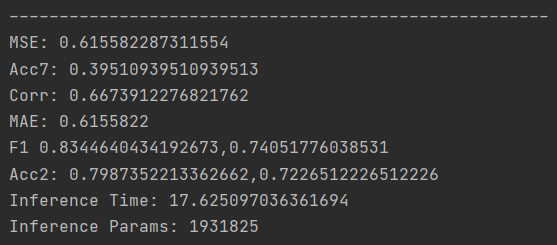
CMU-MOSEI数据集
5.完整代码获取
多模态情感分析——多模态联邦学习UTMP源码(2023ArXiv)
最后:
如果你想要进一步了解更多的相关知识,可以关注下面公众号联系~会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!



















 949
949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











