






1.任务介绍
在做情感分析任务是,一般是通过纯文本进行判断的,或者通过语音来判断,现结合语音、文本双模态来进行情感分析。
2.建立模型
from keras.layers import *
from mult_emtion.my_atten import Attention
import keras
from keras.optimizers import Adam
audio_length = 1600 # 输入语音长度,不够16s的0补齐
audio_features_length = 200 # 输入语音特征长度
# 文本输入
input_text = Input(shape=(100, ), name='text_input') # (, 100)
embed = Embedding(10000, 128)(input_text) # (, 100, 128)
lstm_out1 = Bidirectional(LSTM(64, return_sequences=True))(embed) # (, 100, 64)
# 音频输入
input_audio = Input(shape=(audio_length, audio_features_length), name='input_audio') # (, 1600, 200)
lstm_out2 = Dense(64, activation='relu')(input_audio) # 先进行全连接网络承接输入特征
lstm_out2 = Bidirectional(LSTM(64, return_sequences=True))(lstm_out2) # (, 1600, 64)
# 融合
att_out = Attention(8, 16)([lstm_out1, lstm_out2, lstm_out2])
att_out = concatenate([lstm_out1, att_out])
att_out = Dropout(0.05)(att_out)
# MLP
out = Bidirectional(LSTM(64, return_sequences=True))(att_out)
out = MaxPooling1D(pool_size=4)(out)
out = Flatten()(out)
out = Dense(64, activation='relu')(out)
out_put = Dense(9, activation='softmax')(out)
model = keras.models.Model([input_audio, input_text], out_put)
# model = keras.models.Model(input_audio, out_put)
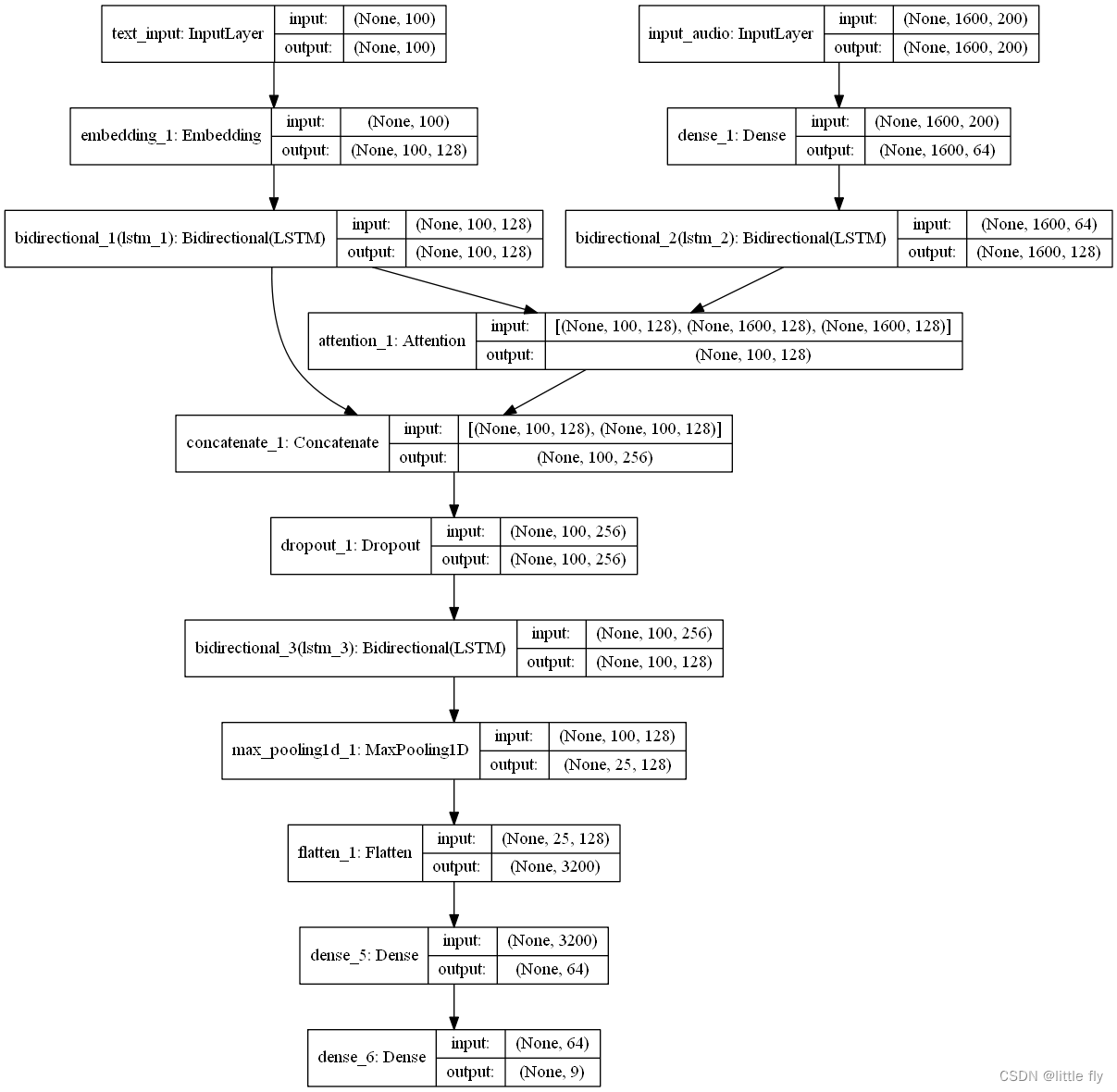
keras.utils.plot_model(model, 'data/model.png', show_shapes=True)
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=Adam(2e-4), # 用足够小的学习率
metrics=['accuracy'],
)
模型架构图















 639
639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









