







&Title

&Summary
之前的网络结构FPN和SSD,通常使用多个layer的不同空间精度预测不同规模的目标,简言之,高精度图预测小目标;作者发现没有必要使用多个layer来预测不同规模的人脸,关键是要均衡不同规模的正样例和负样例的数量,作者就提出了分组采样方法(a group sampling method),该方法基于不同规模(scale)将所有anchor分为若干组,确保在训练过程中每组的采样数量都是相同的。在使用过程中使用最后一层的FPN作为feature。(常见方法多关心类别间的不均衡,没有留意过样例的均衡性,因而该想法比较新颖)
Contributions
- 我们观察到跨尺度的锚分布而不是多尺度的特征表示是进行多层预测时的关键因素,这挑战了我们对FPN的理解;
- 我们进一步仔细研究影响检测性能的因素,并确定现有基于锚的探测器的关键问题:锚在不同尺度上是不平衡的;
- 我们提出了一个简单直接的解决方案来解决该问题,并且所提出的解决方案在检测性能上取得了明显的效果。
&Research Objective
均衡不同规模的正样例和负样例的数量
&Problem Statement

图3中网络结构包含5个卷积块,其中conv2(C2),conv3(C3),conv4(C4),conv5(C5)分别进行1*1的卷积进行变通道数后,和上采样操作后,对不同特征层进行特征融合;anchor scale为{16,32,64,128},aspect ratio = 1,最终的输出特征图分别为{P2,P3,P4,P5}。
使用图3比较了5种不同类型的检测器:
- RPN:C4作为预测层,所有anchor除以尺度16(titled with stride 16 pixels)
- FPN:{P2,P3,P4,P5}作为检测层,anchor scale为{16,32,64,128},特征步长为{4,8,16,32};
- FPN-finest-stride:所有的anchor都是出自P2,特征步长为{4,8,16,32},anchor scale为{16,32,64,128};
- FPN-finest:所有的anchor都是出自P2,每个anchor的步长为4;
- FPN-finest-sample:和FPN-finest参数设定相同,另外使用了分组采样方法均衡不同规模的训练样例。
具体参数细节查看图1


通过以上5个不同检测器的对比实验得出结论如下:
-
使用多个layer的feature(对于预测小目标)作用不大:查看图1中的(b)和(c),二者的区别在于FPN使用多层layer,而FPN-finest-stride使用单层layer。查看表1,发现二者AP值几乎相同。这里实验证明FPN之所以有效,并不是预测的特征层数量增加导致的,而是深层和浅层的特征融合。其实这点也体现在SSD上,SSD也是基于多个特征层进行预测,但是没有做高层和浅层的特征融合,所以SSD对小尺寸目标检测效果不怎么好,结合Figure2,FPN和FPN-finest-stride在样例分布上几乎相同。
-
规模(scale)不均衡分布影响较大:通过比较FPN-finest-stride和FPN-finest,FPN-finest设定的步长都是4。(Table 1)FPN-finest在Easy和medium上面的ap值是优于FPN-finest-stride;(Figure 2)FPN-finest中拥有更多大anchor,当步长是16时,FPN-finest的样本量少于FPN-finest-stride的样本量,可以明显发现在Hard目标预测时,FPN-finest-stride在Hard目标预测结果ap值明显更好;
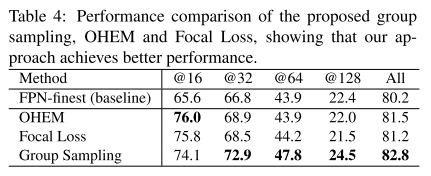
通过以上的实验分析,作者提出使用分组采样进行样本量规模均衡,实验结果中样本均衡后如Figure2中的图e一样,当样本均衡后,相应模型表现与其他四种方法相比较,效果最好(Table1中的FPN-finest-sampling)。
&Method(s)
anchor matching strategy


Group Sampling(分组采样)

Training Process
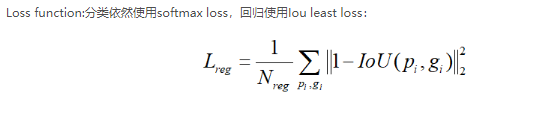
&Evaluation
The effect of the number of training samples

结论:
- 随着训练样本N的数量增加,性能也得到提升。
- 当N=2048时,性能提升得到饱和。
The effect of the proposed loss
通过实验发现作者的方法在ROC曲线上性能最好。
&Thinks
- 作者从独特的视角进行观察,找到小目标检测不到的根本原因,以及相应的解决方法,最终得到分组采样算法和lease square IoU loss函数;















 1735
1735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









