






论文名称:《A Text-Centered Shared-Private Framework via Cross-Modal Prediction
for Multimodal Sentiment Analysis》
相关工作:
根据使用的特征粒度分为两类工作,一类是基于句子级别特征的多模态特征融合方法。基于句子级别特征的多模态特征融合方法的好处是可以基于全局特征进行预测,但是缺点是忽略了不同模态的局部特征之间的对齐关系。
因此,另一类方法是基于词级别特征的多模态特征融合方法。一开始的强制对齐。强制对齐,耗时费力。后来,出现了跨模态注意力机制进行隐式的跨模态特征对齐,其相对于显式的特征对齐来说有两点好处,第一点是将特征对齐蕴含在融合网络中,无需进行显式的特征对齐。第二点是经过显式对齐后,一个文本特征仅能跟少量的一小段时间内的特征进行交互,限制了特征交互的范围。而利用隐式的跨模态特征交互可以与整个句子的特征进行交互。基于此考虑,Tsai 等人基于 Transformer 架构实现了多模态 Transformer,该模型无需显式的特征对齐,并可以捕捉到细粒度的特征交互。
动机:
以往多模态融合研究都是三个模态一视同仁,然后隐式地对不同模态之间的交互进行建模。
我们认为更深入的研究不同模态对于目标任务的贡献以及显式的分析和建模不同模态特征之间的关系将会帮助模型更有效的进行多模态特征融合。
并且,我们提出了两点观察,第一点是,多模态情感分析中文本模态占据主要地位,以往实验结果表明当去掉文本模态后模型结果相比去去掉其它模态产生了巨大的下降。第二点是,相对于文本模态来说,其他模态提供了两类信息,一类信息是共享语义,共享语义没有提供文本模态外的信息,但可以增强相应的语义,并使得模型更加鲁棒。另一类信息是私有语义,私有语义提供了文本之外的语义信息,并可以使得模型预测更加准确。
基于这两点观察,我们提出了一种基于跨模态预测的以文本为中心的共享私有框架。在该框架中,我们利用跨模态预测任务来分辨共享特征以及私有特征,并设计了以文本为中心的多模态特征融合机制对多模态特征进行特征融合。
如何实现设计
方法主要包含两部分,一部分是共享特征与私有特征鉴别(想法1),另一部分是对共享特征和私有特征进行特征融合(想法2)。
想法1来源:观察其他论文中,总结出文本模态在多模态起着至关重要的的作用。
想法1:设计一个跨模态预测任务,通过训练文本-视觉和文本-声学两个跨模态预测模型,获得非文本模态的共享特征和私有特征。
实施步骤:
如何定义私有特征、共享特征和跨模态预测?
私有特征:该特征包含的信息没有包含在文本特征中。在跨模态预测模型中是指通过文本特征难于预测出来的特征,即预测时损失函数值比较高的时间步的特征。
共享特征:该特征包含与文本特征相关的信息。在预测过程中,要把某一时间步特征预测准确则需要注意力机制注意到与所要生成特征相关的信息上,因此我们认为如果预测一个特征时,对于某一文本特征权重较高,则认为该特征为这一文本特征的共享特征。
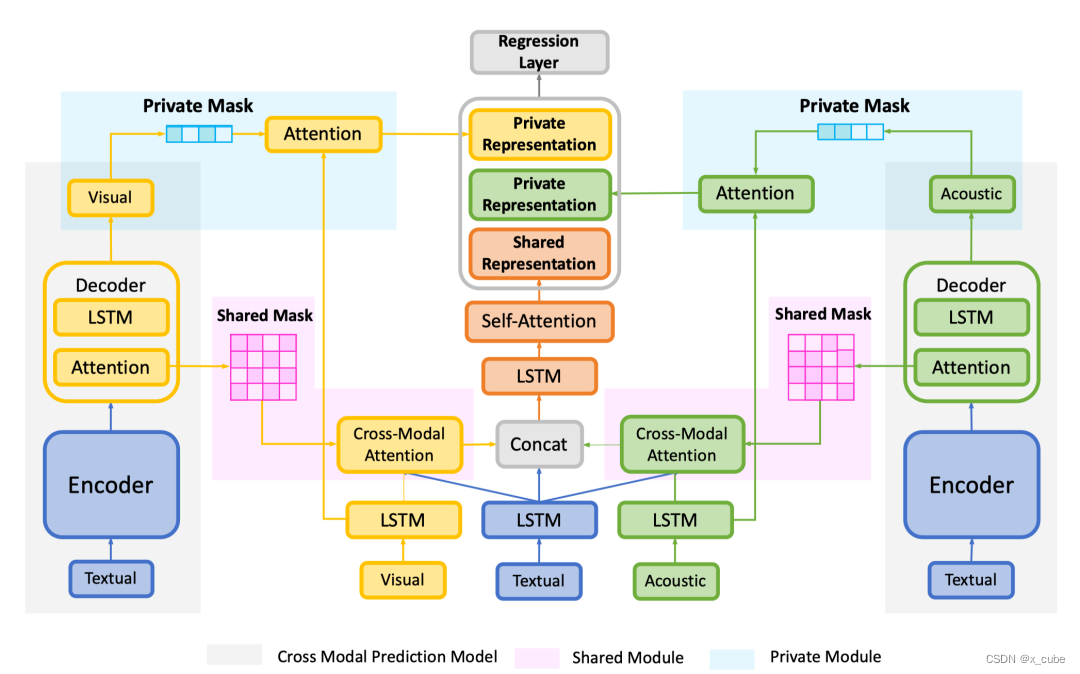
跨模态预测模型:跨模态预测模型的输入是文本特征,输出是音频/图像特征。使用带attention的Seq2Seq,训练文本-视觉和文本-语音模型,我们使用所获得的模型来区分共享特征和私有特征,并将结果记录为共享掩码和私有掩码,这些掩码将被传递给情感回归模型。
共享掩码:基于预测模型想输出非文本特征,就应该更加关注包含更多共享语义输入文本特征这个假设,设计了共享掩码。对权重排序最大的K个为1,其他为0。 最终得到时序smask。
私有掩码:私有语义的表示方法。私有语义很难以被文本模态预测。
训练预测模型损失值e,排序得到最大的K个为1,否则为0。得到pmask,私有掩码将由回归模型使用,迫使模型关注私有特征。
想法2来源:另外两种模态可以增强语义,使情感分析模型更加健壮。这个算合理推测。
想法2:我们设计了一个情感回归模型来融合文本特征和两类特征。
实施步骤:
输入层:LSTM,获取话语级文本特征。首先提取帧级的视觉或听觉特征,然后对它们进行平均以获得最终特征,这些特征被称为话语级特征。融合后得到多模态表征。
共享模块:为了利用非文本模态特征中的共享信息来增强词语的表征。我们提出了掩码跨模态网络,它可以利用跨模态预测模型获得的共享掩码来关注非文本共享特征。
对文本-语音和文本-视觉进行注意力计算,并且使用smask进行点乘从而增强词语表征。然后将计算后的三者进行拼接后用attention融合,最终得到共享表示。
私有模块:为了使模型能够捕捉非文本模态中包含的独特信息。
计算的时候并没有使用激活函数,而是直接线性计算,求分数的时候也是求和,并未点积。
回归层:具有ReLU激活功能的二层网络实现。
总结:
为了区分这两种语义,我们设计了一个跨模态预测任务,并将结果记录为共享掩码和私有掩码。我们进一步提出一个回归模型,利用共享模块和私有模块来融合文本特征和两个非文本特征。
一类信息是共享语义,利用该类信息可以加强文本中相应的语义,使得模型更加的鲁棒。另一类信息是私有语义,利用该类信息补充文本语义,进一步使得模型预测更加的准确。
实验结果表明,区分共享和私有的非文本语义,并对文本语义和两个非文本语义之间的交互进行显式建模,比将每个非文本特征作为一个整体来处理更有利于多模态情感分析。分析表明,回归模型可以从更好的跨模态预测模型中获得更多的收益,这也表明跨模态预测过程只需要使用未标记数据就可以产生有用的监督信号。















 884
884











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









