






DDPM–去噪扩散模型代码详解
1.简述
这篇文章不打算写关于扩散模型原理的东西,网上不管是逐行推导还是原理讲解讲的好的都很多,至少肯定比我讲的强,这篇文章主要是写一下关于扩散模型的pytorch实现,因为在最开始入坑时候自己这一点上吃了不少亏,原理听懂了手上转化不成实际的代码,一些实现还附加了很多其他模块导致也看不太懂,所以准备写一下这篇文章,尽可能的详细一些讲解扩散模型的代码结构和函数功能的实现。
2.代码结构
在这里使用的代码将DDPM封装成了一个GaussianDiffusion类,这个类里面包括前向的加噪训练过程和反向的采样过程,整体代码如下所示
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from copy import deepcopy
from functools import partial
from tqdm import tqdm
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def extract(a, t, x_shape):
"""
从a中提取t位置的数据并且reshape成x_shape的形状返回
:return:
"""
b, *_ = t.shape
out = a.gather(-1, t)
return out.reshape(b, *((1,) * (len(x_shape) - 1)))
class EMA():
"""EMA 优化器"""
def __init__(self, decay):
self.decay = decay
def update_average(self, old, new):
if old is None:
return new
return old * self.decay + (1 - self.decay) * new
def update_model_average(self, ema_model, current_model):
for current_params, ema_params in zip(current_model.parameters(), ema_model.parameters()):
old, new = ema_params.data, current_params.data
ema_params.data = self.update_average(old, new)
def get_model(Model, device, **kwargs):
"""
:param Model: 网络模型
:param device: 设备
:param kwargs: 网络参数
:return:
"""
model = Model(**kwargs).to(device)
return model
class GaussianDiffusion(nn.Module):
def __init__(self,
model, input_shape, input_channels, betas, device, num_class=None, loss_type="l2", ema_decay=0.9999,
ema_start=2000, ema_update_rate=1):
"""
:param model: Network
:param input_shape: img_size / data_size
:param input_channels: channels
:param betas:
:param device:
:param num_class:
:param loss_type: l1 or l2
:param ema_decay:
:param ema_start:
:param ema_update_rate:
"""
super().__init__()
self.model = model
self.device = device
self.ema_model = deepcopy(model)
self.ema = EMA(decay=ema_decay)
self.ema_decay = ema_decay
self.ema_start = ema_start
self.ema_update_rate = ema_update_rate
self.step = 0
self.input_shape = input_shape
self.input_channels = input_channels
self.num_class = num_class
# l1或l2 loss
if loss_type not in ['l1', 'l2']:
raise ValueError('loss_type must be either l1 or l2')
self.loss_type = loss_type
self.num_timesteps = len(betas)
alphas = 1.0 - betas
alphas_cumprod = np.cumprod(alphas)
# 将alpas转换成tensor
to_torch = partial(torch.tensor, dtype=torch.float32, device=device)
# betas [0.0001, 0.00011992, 0.00013984 ... , 0.02]
self.register_buffer("betas", to_torch(betas))
# alphas [0.9999, 0.99988008, 0.99986016 ... , 0.98]
self.register_buffer("alphas", to_torch(alphas))
# alphas_cumprod [9.99900000e-01, 9.99780092e-01, 9.99640283e-01 ... , 4.03582977e-05]
self.register_buffer("alphas_cumprod", to_torch(alphas_cumprod))
# sqrt(alphas_cumprod)
self.register_buffer("sqrt_alphas_cumprod", to_torch(np.sqrt(alphas_cumprod)))
# sqrt(1 - alphas_cumprod)
self.register_buffer("sqrt_one_minus_alphas_cumprod", to_torch(np.sqrt(1 - alphas_cumprod)))
# sqrt(1 / alphas)
self.register_buffer("reciprocal_sqrt_alphas", to_torch(np.sqrt(1 / alphas)))
self.register_buffer("remove_noise_coeff", to_torch(betas / np.sqrt(1 - alphas_cumprod)))
self.register_buffer("sigma", to_torch(np.sqrt(betas)))
def update_ema(self):
self.step += 1
if self.step % self.ema_update_rate == 0:
if self.step < self.ema_start:
self.ema_model.load_state_dict(self.model.state_dict())
else:
self.ema.update_model_average(self.ema_model, self.model)
@torch.no_grad()
def remove_noise(self, x, t, y, use_ema=True):
"""
从xt中获取xt-1
:param x: xt
:param t: 当前时间步
:param y: None
:param use_ema: 是否使用ema
:return: xt-1
"""
if use_ema:
return (
(x - extract(self.remove_noise_coeff, t, x.shape) * self.ema_model(x, t, y)) *
extract(self.reciprocal_sqrt_alphas, t, x.shape)
)
else:
return (
(x - extract(self.remove_noise_coeff, t, x.shape) * self.model(x, t, y)) *
extract(self.reciprocal_sqrt_alphas, t, x.shape)
)
@torch.no_grad()
def sample(self, batch_size, device, y=None, use_ema=True):
"""
从ddpm里sample最终结果并返回
:param batch_size: 这里好像只能设为1
:param device: 采样使用cpu或者gpu
:param y: None
:param use_ema: 是否使用ema
:return: 从ddpm中采样的结果 [B, N, C]
"""
if y is not None and batch_size != len(y):
raise ValueError('sample batch size different from length of given y')
x = torch.randn(batch_size, self.input_shape, self.input_channels, device=device)
for t in tqdm(range(self.num_timesteps - 1, -1, -1), desc="Sampling: ", total=self.num_timesteps):
t_batch = torch.tensor([t], device=device).repeat(batch_size) #[B, 1]
x = self.remove_noise(x, t_batch, y, use_ema=use_ema)
if t > 0:
x += extract(self.sigma, t_batch, x.shape) * torch.randn_like(x)
return x.cpu().detach()
@torch.no_grad()
def sample_diffusion_sequence(self, batch_size, device, y=None, use_ema=True):
"""
:param batch_size:
:param device:
:param y:
:param use_ema:
:return: (num_steps, (B, N, C))
"""
if y is not None and batch_size != len(y):
raise ValueError("sample batch size different from length of given y")
x = torch.randn(batch_size, self.input_shape, self.input_channels, device=device)
diffusion_sequence = [x.cpu().detach()]
for t in range(self.num_timesteps - 1, -1, -1):
t_batch = torch.tensor([t], device=device).repeat(batch_size)
x = self.remove_noise(x, t_batch, y, use_ema)
if t > 0:
x += extract(self.sigma, t_batch, x.shape) * torch.randn_like(x)
diffusion_sequence.append(x.cpu().detach())
return diffusion_sequence
def perturb_x(self, x, t, noise):
"""从x0获取加噪的xt的噪声图"""
return (
extract(self.sqrt_alphas_cumprod, t, x.shape) * x +
extract(self.sqrt_one_minus_alphas_cumprod, t, x.shape) * noise
)
def get_losses(self, x, t, y):
"""
:param x: 随机噪声图
:param t: 时间步
:param y: None
:return:
"""
noise = torch.randn_like(x)
perturbed_x = self.perturb_x(x, t, noise)
estimated_noise = self.model(perturbed_x, t)
if self.loss_type == "l1":
loss = F.l1_loss(estimated_noise, noise)
elif self.loss_type == "l2":
loss = F.mse_loss(estimated_noise, noise)
return loss
def forward(self, x, y=None):
B, N, C = x.shape
device = x.device
t = torch.randint(0, self.num_timesteps, (B,), device=device)
return self.get_losses(x, t, y)
3.功能模块
在实现GaussianDiffusion之前,首先需要两个功能模块,一个是extract模块,另一个是EMA模块。
extract模块是用来在一个torch张量中提取目标位置的数据,然后reshape成x_shape的形状,也就是在DDPM公式中类似前向和反向过程中xt的系数和xt-1的系数这种,我们在训练前就直接制作生成好了相关的系数,在实际训练和采样过程中只需要按照对应位置提取即可。
def extract(a, t, x_shape):
"""
从a中提取t位置的数据并且reshape成x_shape的形状返回
:return:
"""
b, *_ = t.shape
out = a.gather(-1, t)
return out.reshape(b, *((1,) * (len(x_shape) - 1)))
EMA是一种平滑模型的技术,我也不懂原理,反正用着牛逼就完了
class EMA():
"""EMA 优化器"""
def __init__(self, decay):
self.decay = decay
def update_average(self, old, new):
if old is None:
return new
return old * self.decay + (1 - self.decay) * new
def update_model_average(self, ema_model, current_model):
for current_params, ema_params in zip(current_model.parameters(), ema_model.parameters()):
old, new = ema_params.data, current_params.data
ema_params.data = self.update_average(old, new)
4.模型初始化
GaussianDiffusion的模型在初始化时候有以下几个传入的参数
def __init__(self,
model, input_shape, input_channels, betas, device, num_class=None, loss_type="l2", ema_decay=0.9999,
ema_start=2000, ema_update_rate=1):
在这里面
model:就是用来预测噪声的神经网络,这个网络只需要返回一个和图片数据形状相同的噪声图即可
input_shape: 你输入数据的形状,比如图片是(B, H, W, C)的话,这里就是(H, W)
input_channels: 就是上面一点提到的C,一般是一个常数
betas: 就是DDPM论文里提到的betas
device:你要用的训练设备,不过我体感cpu基本跑不动,肯定是要上卡训练的
num_class:做按类别生成用的,只训练生成模型的话无条件生成默认就行
loss_type:损失计算的方法选择
ema_start, ema_update_rate: ema相关,不用管
对于初始化这个过程,最重要的就是buffer的register,也就是形成上面提到的那几个“系数”的张量,对应的就是这段代码,他根据你传入的beta值来计算alpha相关的值,然后后面直接用就行
alphas = 1.0 - betas
alphas_cumprod = np.cumprod(alphas)
# 将alpas转换成tensor
to_torch = partial(torch.tensor, dtype=torch.float32, device=device)
# betas [0.0001, 0.00011992, 0.00013984 ... , 0.02]
self.register_buffer("betas", to_torch(betas))
# alphas [0.9999, 0.99988008, 0.99986016 ... , 0.98]
self.register_buffer("alphas", to_torch(alphas))
# alphas_cumprod [9.99900000e-01, 9.99780092e-01, 9.99640283e-01 ... , 4.03582977e-05]
self.register_buffer("alphas_cumprod", to_torch(alphas_cumprod))
# sqrt(alphas_cumprod)
self.register_buffer("sqrt_alphas_cumprod", to_torch(np.sqrt(alphas_cumprod)))
# sqrt(1 - alphas_cumprod)
self.register_buffer("sqrt_one_minus_alphas_cumprod", to_torch(np.sqrt(1 - alphas_cumprod)))
# sqrt(1 / alphas)
self.register_buffer("reciprocal_sqrt_alphas", to_torch(np.sqrt(1 / alphas)))
self.register_buffer("remove_noise_coeff", to_torch(betas / np.sqrt(1 - alphas_cumprod)))
self.register_buffer("sigma", to_torch(np.sqrt(betas)))
5. update_ema
def update_ema(self):
self.step += 1
if self.step % self.ema_update_rate == 0:
if self.step < self.ema_start:
self.ema_model.load_state_dict(self.model.state_dict())
else:
self.ema.update_model_average(self.ema_model, self.model)
没什么好说的一个函数,ema就这么用,抄就完了
6. perturb_x
def perturb_x(self, x, t, noise):
"""从x0获取加噪的xt的噪声图"""
return (
extract(self.sqrt_alphas_cumprod, t, x.shape) * x +
extract(self.sqrt_one_minus_alphas_cumprod, t, x.shape) * noise
)
这一步是计算加噪过程中xt时刻的带噪声图,也就是
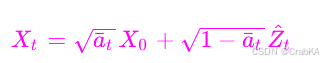
这个公式里计算的Xt,把这个图和时间t的time_embedding相加然后送进神经网络去预测t-1时刻的噪声图,然后和一个标准噪声做loss,就是DDPM的训练过程了。
关于输入
x:就是原本的图片
t:时间步t, 是一个(0,num_steps)的随机值,输入形状为tensor(1)
7.get_loss() forward()
这两个函数没啥好讲的,一个是计算loss,另一个是前向函数,利用get_loss()和perturb_x()来获取训练的Loss
def get_losses(self, x, t, y):
"""
:param x: 随机噪声图
:param t: 时间步
:param y: None
:return:
"""
noise = torch.randn_like(x)
perturbed_x = self.perturb_x(x, t, noise)
estimated_noise = self.model(perturbed_x, t)
if self.loss_type == "l1":
loss = F.l1_loss(estimated_noise, noise)
elif self.loss_type == "l2":
loss = F.mse_loss(estimated_noise, noise)
return loss
def forward(self, x, y=None):
B, N, C = x.shape
device = x.device
t = torch.randint(0, self.num_timesteps, (B,), device=device)
return self.get_losses(x, t, y)
8. remove_noise
这个函数是采样过程的核心,也就是通过xt计算xt-1的函数,在DDPM原理中,就是这个
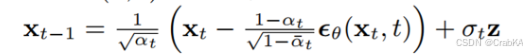
公式的计算过程
@torch.no_grad()
def remove_noise(self, x, t, y, use_ema=True):
"""
从xt中获取xt-1
:param x: xt
:param t: 当前时间步
:param y: None
:param use_ema: 是否使用ema
:return: xt-1
"""
if use_ema:
return (
(x - extract(self.remove_noise_coeff, t, x.shape) * self.ema_model(x, t, y)) *
extract(self.reciprocal_sqrt_alphas, t, x.shape)
)
else:
return (
(x - extract(self.remove_noise_coeff, t, x.shape) * self.model(x, t, y)) *
extract(self.reciprocal_sqrt_alphas, t, x.shape)
)
9. sample(), sample_diffusion_sequence
这两个函数就是一个函数,都是从模型中采样结果的函数,区别就是第一个返回的是单独的一张结果图片的np数组,第二个返回的是从t到0整个生成流程逐渐去噪的生成效果,这里我用了一个tqdm来可视化生成过程,实现一个大概类似这样的效果。

@torch.no_grad()
def sample(self, batch_size, device, y=None, use_ema=True):
"""
从ddpm里sample最终结果并返回
:param batch_size: 这里好像只能设为1
:param device: 采样使用cpu或者gpu
:param y: None
:param use_ema: 是否使用ema
:return: 从ddpm中采样的结果 [B, N, C]
"""
if y is not None and batch_size != len(y):
raise ValueError('sample batch size different from length of given y')
x = torch.randn(batch_size, self.input_shape, self.input_channels, device=device)
for t in tqdm(range(self.num_timesteps - 1, -1, -1), desc="Sampling: ", total=self.num_timesteps):
t_batch = torch.tensor([t], device=device).repeat(batch_size) #[B, 1]
x = self.remove_noise(x, t_batch, y, use_ema=use_ema)
if t > 0:
x += extract(self.sigma, t_batch, x.shape) * torch.randn_like(x)
return x.cpu().detach()
@torch.no_grad()
def sample_diffusion_sequence(self, batch_size, device, y=None, use_ema=True):
"""
:param batch_size:
:param device:
:param y:
:param use_ema:
:return: (num_steps, (B, N, C))
"""
if y is not None and batch_size != len(y):
raise ValueError("sample batch size different from length of given y")
x = torch.randn(batch_size, self.input_shape, self.input_channels, device=device)
diffusion_sequence = [x.cpu().detach()]
for t in range(self.num_timesteps - 1, -1, -1):
t_batch = torch.tensor([t], device=device).repeat(batch_size)
x = self.remove_noise(x, t_batch, y, use_ema)
if t > 0:
x += extract(self.sigma, t_batch, x.shape) * torch.randn_like(x)
diffusion_sequence.append(x.cpu().detach())
return diffusion_sequence
10.小结
整个扩散模型的实现大概也就是上面的几个部分了,训练用的框架我放在下面github连接里了,其他代码都比较简单,都是线性逻辑往下顺的代码,基本对着敲一遍就能懂,不懂的也不用懂,照着抄就完了,这里没放神经网络模型,在实现神经网络模型时候只要注意一点,把时间步embedding一下加进输入的x里就行了,别的也没什么需要注意的,都是定死的东西,和ddpm本身关系也不大
DDPM_Train_Frame
11.补充一些
这里算是给真正完全刚接触ddpm的朋友写的吧,一些训练上的注意细节和技巧
1.DDPM的训练成本真的很大,我个人用来跑点云任务,500个steps的生成,基本要跑上万个epoch才能有不错的采样结果,考虑如果数据集稍稍大一点,卡一般的话,其实自己来跑挺不现实的,玩一玩实验的话老老实实跑32x32就好了
2.关于Loss,DDPM前期的loss下降会很快,但感觉和生成质量关系不大,基本上都要跑稳定Loss一段时间才能拿到好的生成结果,所以loss不动也不用担心,老老实实放那让他自己跑着去吧
3.关于条件生成和一些回归,补全任务,我也不知道怎么搞,要是有人懂这个的话麻烦教教我,谢谢。
4.数据本身对最后生成结果感觉影响很大,有些数据就是很好训练,有些数据就是很难训练,至于为啥,不知道
5.关于网络结构上,官方的那个UNet实现起来还挺麻烦的,其实可以直接写一个三成MLP之类的,生成几个图像数据集上3232或者6464之类的小图网络本身是足够的
6.DL学到现在大概也有大半年了,最大的感觉就是,原理很好找,无论是教学讲解还是类似的东西都很多写的也很好,一个看不懂换一个,总归到最后只要愿意看都能看懂,最麻烦的是训练经验之类的,各种数据集选择,网络层数,超参数之类的设置,不花大把时间去试真的很难做到心里有数。

















 2746
2746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









