







Muon优化器:让大规模语言模型训练更高效
——解读Moonshot AI最新研究成果
为什么需要新的优化器?
近年来,大型语言模型(LLM)的发展突飞猛进,但训练这些模型的成本却高得惊人。传统的优化器如AdamW虽然稳定,但在计算效率和模型性能上仍有提升空间。现有的优化算法往往面临两大挑战:
- 扩展性问题:小规模模型表现优秀的优化器,在扩展到数十亿参数时可能失效。
- 计算成本:训练万亿量级Token的模型需要消耗海量算力,优化器的效率直接影响训练成本。
Moonshot AI团队的最新论文《Muon is Scalable for LLM Training》提出了一种基于矩阵正交化的优化器——Muon,成功解决了上述问题,并在实验中展现出比AdamW高2倍的计算效率。
Muon的核心创新
Muon的核心思想是通过梯度动量正交化,确保参数更新方向的多样性,避免模型陷入局部最优。具体技术亮点如下:
1. 权重衰减与更新尺度调整
- 权重衰减:原版Muon未引入权重衰减,导致训练后期参数幅值过大,影响模型性能。论文通过引入类似AdamW的权重衰减机制,有效控制了参数增长。
- 更新一致性:Muon的更新幅度与参数矩阵的形状有关。例如,形状为[A, B]的矩阵,其更新幅度理论值为
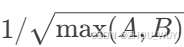
。通过调整学习率,Muon实现了不同形状矩阵的更新幅度一致,显著提升了训练稳定性。
2. 分布式高效实现
Muon结合ZeRO-1和Megatron-LM的并行策略,提出分布式Muon:
- 内存优化:仅需AdamW一半的显存占用。
- 通信优化:通过分块计算和bf16精度降低通信开销,实际通信负载仅为AdamW的1.25倍。
3. 牛顿-舒尔茨迭代加速
通过5次牛顿-舒尔茨迭代,Muon以较低成本实现了梯度正交化的近似计算,兼顾了精度与效率。
实验结果:性能与效率双赢
论文通过大量实验验证了Muon的优势:
1. 计算效率提升
- 扩展定律实验:在相同性能下,Muon的训练计算量(FLOPs)仅为AdamW的52%。
- 训练稳定性:引入权重衰减后,Muon在过训练阶段仍保持更低的验证损失。
2. 模型性能突破
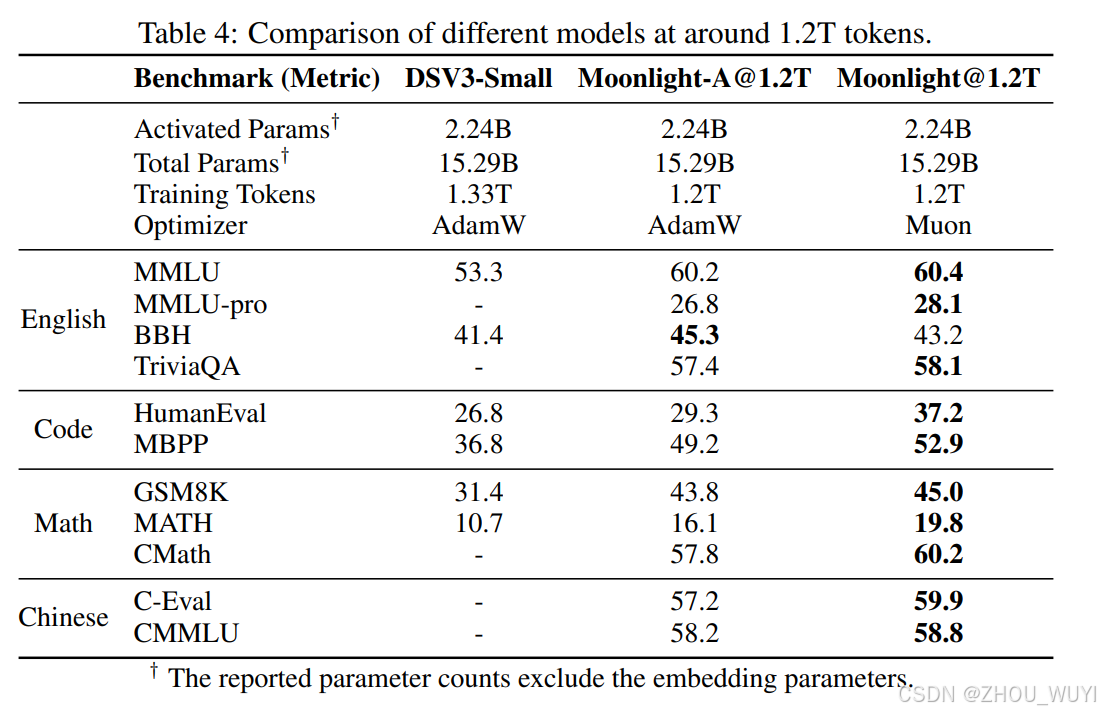
团队基于Muon训练了16B参数的MoE模型Moonlight,使用5.7T Token数据,结果显著优于同类模型:
- 数学与代码任务:在GSM8K和HumanEval上,Moonlight比AdamW训练的基线模型提升约10%。
- Pareto前沿:Moonlight以更少训练成本达到更高性能,超越DeepSeek-V3-small、Llama3等模型。
3. 频谱多样性分析
通过奇异值熵(SVD Entropy)分析,Muon优化后的权重矩阵频谱更分散,表明其能探索更多优化方向,尤其有利于混合专家(MoE)模型的专家选择。
开源与未来方向
Moonshot AI开源了分布式Muon实现、Moonlight模型检查点及训练中间结果,助力社区进一步研究。未来方向包括:
- 将Muon扩展至所有参数类型(如嵌入层),取代混合使用Adam的现状。
- 探索更广义的Schatten范数约束,提升优化灵活性。
- 解决预训练与微调的优化器不匹配问题,释放现有AdamW预训练模型的潜力。
总结
Muon通过矩阵正交化和分布式优化设计,为LLM训练提供了高效、稳定的新选择。其开源实现和实验数据不仅验证了技术可行性,更为后续研究提供了宝贵资源。在AI模型规模持续膨胀的今天,此类工作对降低训练成本、加速AGI发展具有重要意义。
论文链接:Moonlight.pdf
“优化器的每一小步,都是AGI的一大步。”

















 656
656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









