







神经网络
神经网络由多个layer(单层)组成,一层就是一个函数。
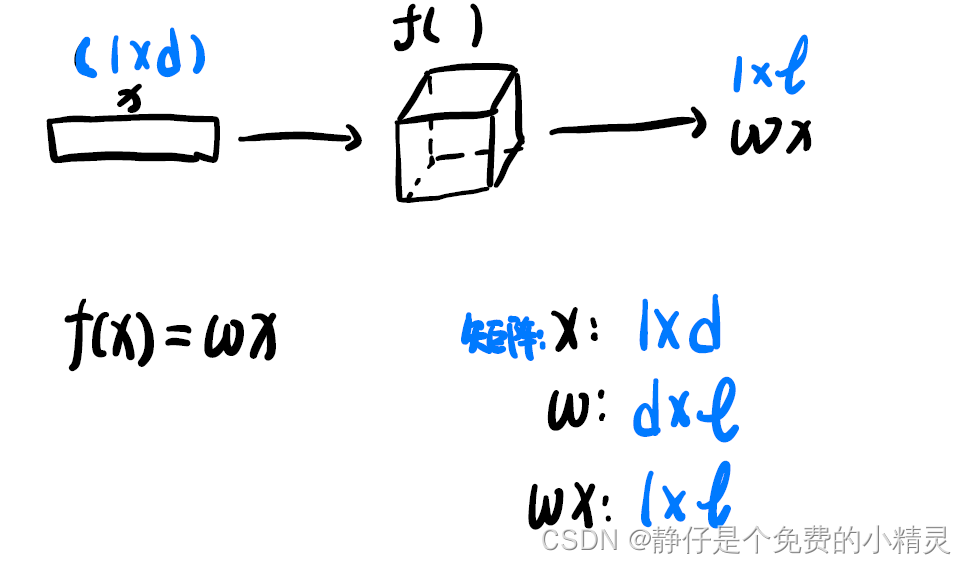
这是一个最简单的网络结构,
f
(
)
f()
f()就是一个layer 输入样本
x
x
x为一个
1
×
d
1\times d
1×d的矩阵,通过
f
(
)
f()
f()得到
1
×
l
1\times l
1×l的输出
w
x
wx
wx,其中
w
w
w是
d
×
l
d\times l
d×l的矩阵。
使用神经网络进行预测,
真实标签:
Y
Y
Y
预测标签:
Y
^
\hat{Y}
Y^
损失:loss =
∣
Y
^
−
Y
∣
2
=
(
w
x
−
Y
)
2
|\hat{Y}-Y|^{2}=(wx-Y)^{2}
∣Y^−Y∣2=(wx−Y)2
对
w
w
w求导:
d
L
d
w
=
2
(
w
x
−
y
)
x
\frac{d L}{d w}=2(w x-y) x
dwdL=2(wx−y)x
学习率:
l
r
lr
lr即learn rate,是一个经验值
学习率更新:
w
←
w
−
l
r
×
d
L
d
w
w \leftarrow w-lr\times \frac{d L}{d w}
w←w−lr×dwdL
停止迭代的方法:通常使用设置迭代次数,迭代多少次后就停止迭代
多示例网络
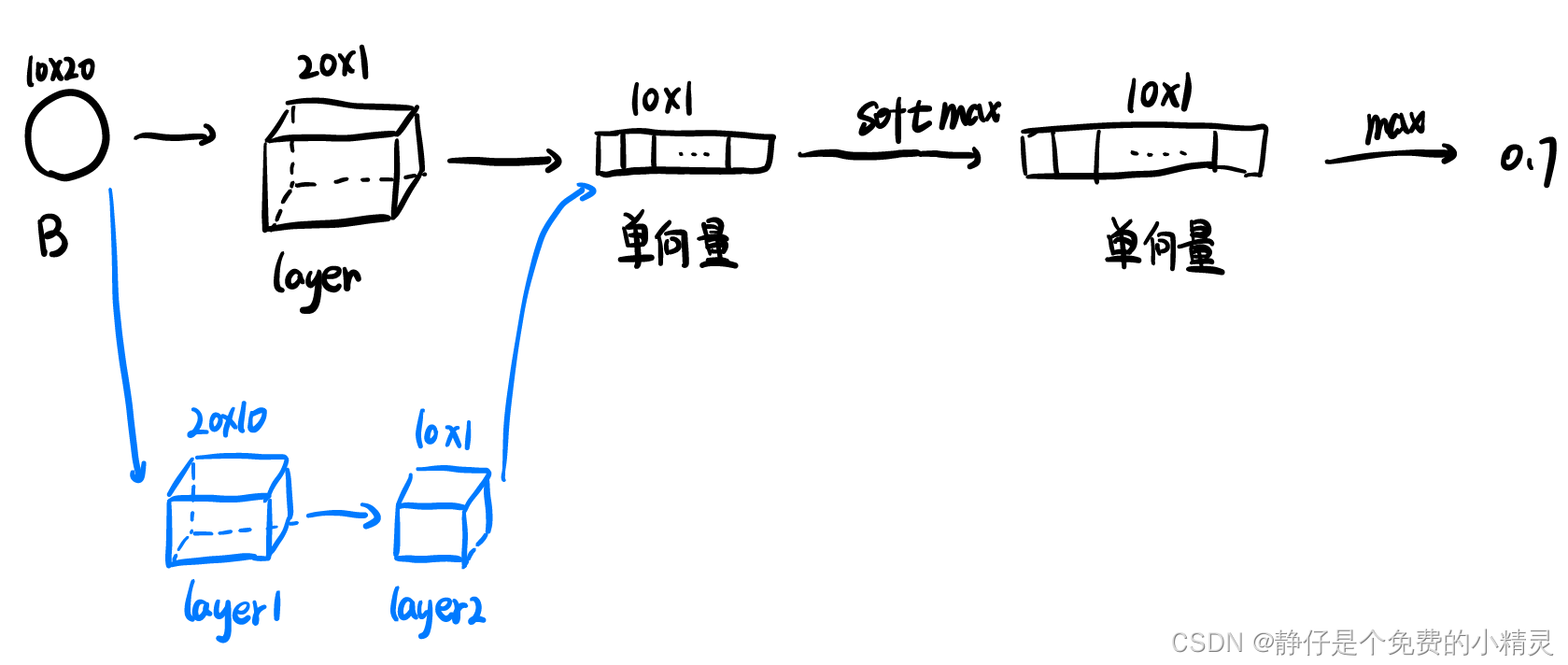
输入为一个包,通过layer将包处理为单项量,如图所示,可以使用一个layer(黑色),也可以使用两个网络(蓝色)。
注意力机制
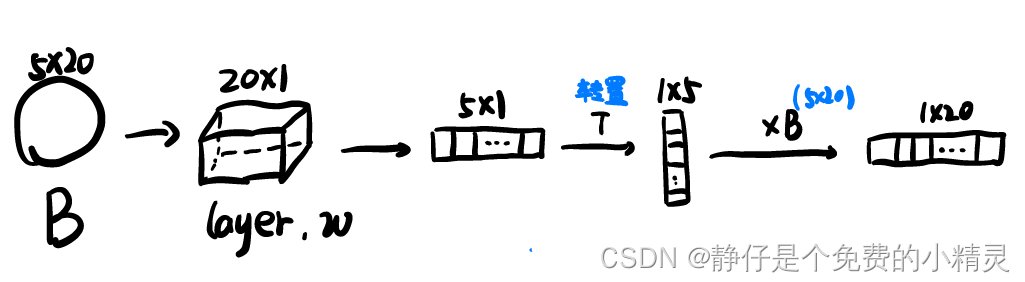
自注意力机制
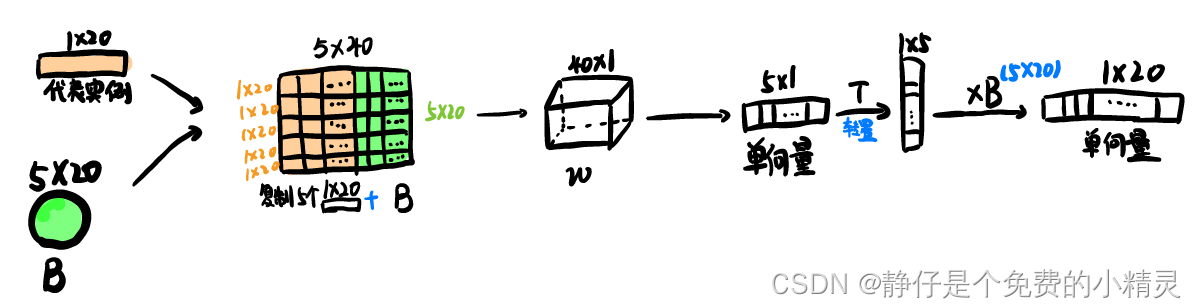
考虑到了一个包中代表实例域其它实例之间的关系
代表实例可以实从包
B
B
B中提取出来的,也就是自,可以使用多种不同的方式提取,视具体的算法而定。
BP神经网络
BP神经网络是一种典型的非线性算法。由输入层,输出层和若干隐含层构成。
如图(a)所示,当只有一个隐含层时,这样的神经网络属于传统的浅层神经网络,如图(b)所示,当有多个隐含层时,这样的神经网络属于深度学习的神经网络。

BP神经网络的核心步骤如下图所示:
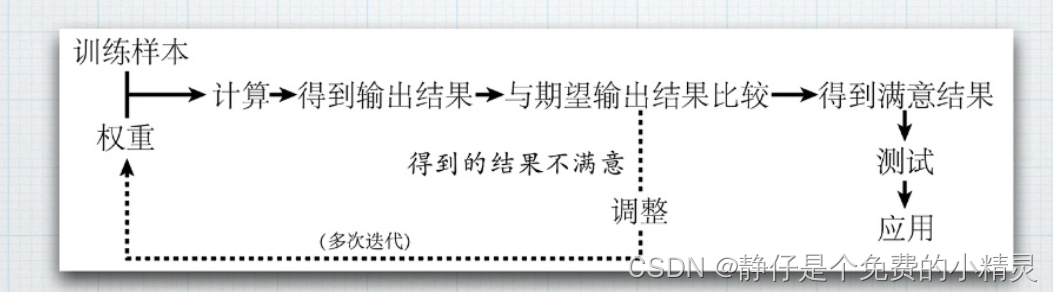
Neural Networks for Multi-Instance Learning
摘要
详细介绍了一种BP-MIP神经网络算法,该算法是从流行的BP算法中派生出来的,它采用了一种新的损失函数来捕捉多实例学习的性质,即已知训练包的标签而不是训练实例的标签。在真实和人工基准多实例数据上的实验表明,BP-MIP的性能与一些成熟的多实例学习方法相当。
损失函数
损失函数作用:优化神经网络的参数。
通过神经网络将实际值与预测值进行匹配,再经过损失函数就可以计算出损失。然后,我们使用梯度下降法等优化方法来优化网络权重,以使损失最小化。这就是我们训练神经网络的方式。
本文主要基于BP提出了适用于多示例数据的损失函数BP-MIP:
E
=
∑
i
=
1
N
E
i
=
∑
i
=
1
N
1
2
(
max
1
≤
j
≤
M
j
O
i
j
−
d
i
)
2
E=\sum_{i=1}^{N} E_{i}=\sum_{i=1}^{N} \frac{1}{2}\left(\max _{1 \leq j \leq M_{j}} O_{i j}-d_{i}\right)^{2}
E=i=1∑NEi=i=1∑N21(1≤j≤MjmaxOij−di)2
其中
E
i
E_{i}
Ei表示第
i
i
i个包的损失,
O
i
j
O_{ij}
Oij表示网络对实例
B
i
j
B_{ij}
Bij标签的预测值,
d
i
d_{i}
di表示包
B
i
B_i
Bi的实际标签,即期望输出的预测值。
网络结构
黑色和蓝色分别代表本文提出的两种网络结构,
代码复现
实验
以musk数据集为例:
前馈神经网络由一个输出单元、一个隐层和166个(musk的特征数)输入单元组成,采用BP-MIP算法进行训练。功能单元的激活函数为sigmoid激活函数。学习率设置为0.05。隐藏单位的数量从20到100不等,间隔为20,而训练epoch从50到1000不等,间隔为50。
在两个数据集上都执行一次遗漏测试。即一个包用于测试,而其他包用于训练神经网络。重复该过程,使数据集中的每个包都被用作测试包一次。取平均结果作为最终结果。
sigmiod激活函数
g
(
x
)
=
1
1
+
e
−
x
g(x)=\frac{1}{1+e^{-x}}
g(x)=1+e−x1
横轴为
x
x
x纵轴为
g
(
x
)
g(x)
g(x),sigmoid图像如下
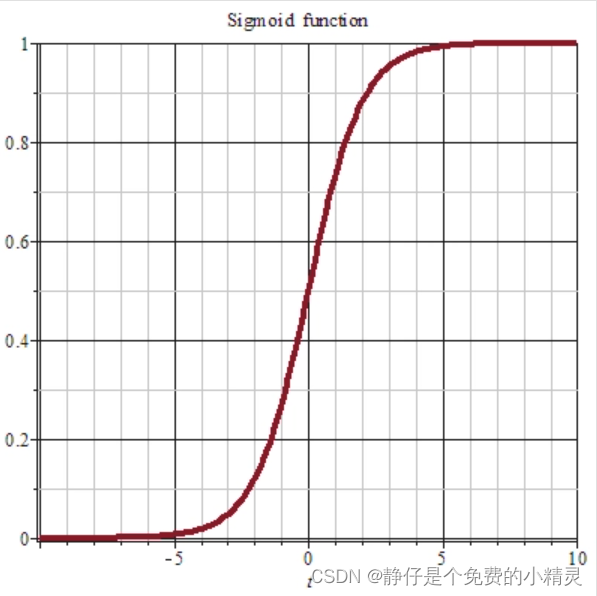
sigmoid函数的功能就是把一个数压缩至
(
0
,
1
)
(0,1)
(0,1)之间。当
x
x
x是非常大的正数时,
g
(
x
)
g(x)
g(x)会趋近于1,而
x
x
x是非常小的负数时,
g
(
x
)
g(x)
g(x)会趋近于0。
激活函数的作用:
1、激活函数的主要作用是改变之前数据的线性关系。如果网络中全部是线性变换,则多层网络可以通过矩阵变换,直接转换成一层神经网络。所以激活函数的存在,使得神经网络的“多层”有了实际的意义,使网络更加强大,增加网络的能力,使它可以学习复杂的事物,复杂的数据,以及表示输入输出之间非线性的复杂的任意函数映射。主要解决了线性模型的表达、分类能力不足的问题。
2、执行数据的归一化。将输入数据映射到某个范围内,再往下传递,这样做的好处是可以限制数据的扩张,防止数据过大导致的溢出风险。比如说sigmoid就可以把输出数据映射到(0,1)区间内。比如说sigmoid函数将激活后输出为0.9,就可以解释为预测90%的概率为正样本。















 721
721











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









