









提出背景
论文:CogMG: Collaborative Augmentation Between Large Language Model and Knowledge Graph
代码:https://github.com/tongzhou21/CogMG
视频:https://www.youtube.com/watch?v=WnkS0Qk_0OM&feature=youtu.be
大型语言模型(LLM)在问答(QA)应用中的使用越来越多。
这些模型能够生成引人入胜和连贯的回答,但它们也容易产生虚构的内容和事实错误。
这些问题可能来源于模型使用的数据、训练和推理阶段。
幸运的是,LLMs可以通过参考外部的知识源(如文档和知识图谱)来减轻这些虚构内容的产生。
知识图谱的作用
本文集中讨论如何利用知识图谱(KG),通过其结构化的数据和精确的事实信息,为大型语言模型(LLM)提供补充。
然而,在QA场景中,知识图谱的效用面临两大挑战:知识覆盖不完整和知识更新不对齐。
知识覆盖不完整
知识图谱虽然能涵盖大量信息,但在实践中,它们存储的知识并不总是全面的。
现有的方法主要集中在改进解析语言或在检索知识三元组时提高语义相关性,这些方法在知识图谱中预存了一些特定问题的知识。
但对于处理那些知识图谱中没有覆盖的查询,现有方法关注较少。
知识更新不对齐
目前更新知识图谱的方法主要有两种:从非结构化文本中提取知识三元组和通过分析现有节点之间的连接推断未见的链接。
这些方法虽然不断更新知识图谱,但由于缺乏目标和策略,未能完全解决新知识与实际用户需求之间的不对齐问题。
因此,知识图谱的更新没有充分考虑用户的实际需求。
为了解决上述两个挑战,本文提出了一个称为CogMG的框架,用于LLM和KG之间的协同增强。
当查询超出当前KG的知识范围时,鼓励LLM显式分解所需的知识三元组。
然后,基于LLM参数中编码的广泛知识进行补全,作为最终答案的参考。
显式识别必要的知识三元组有助于减轻虚构内容并突出知识图谱的不足。
此外,通过检索增强生成(RAG)与外部文档自动验证这些三元组,这些相关文档也可作为手动审查的参考。
在将三元组合并到知识图谱之前,持续且主动的知识更新过程使知识图谱逐步满足实际知识需求,从而提高LLM回答问题的事实性。
显式分解知识三元组和补全
当查询超出当前KG的知识范围时,鼓励LLM显式分解所需的知识三元组。
然后,基于LLM参数中编码的广泛知识进行补全,作为最终答案的参考。
显式识别必要的知识三元组有助于减轻虚构内容并突出知识图谱的不足。
假设一个用户查询“糖尿病患者如何调整饮食以控制血糖水平?”当前的知识图谱(KG)中没有最新的饮食调整建议。
- 查询问题:用户问“糖尿病患者如何调整饮食以控制血糖水平?”
假设知识图谱中缺乏最新的饮食调整建议,那么LLM会将查询问题分解成以下几个三元组,以便更好地理解和处理。
- 显式分解知识三元组:
- (糖尿病, 关联, 饮食调整)
- (饮食调整, 类型, 控制血糖)
- (控制血糖, 包括, 食物类型A)
- (控制血糖, 包括, 食物类型B)
由于知识图谱中缺乏相关信息,LLM将利用其内部编码的广泛知识来补全这些三元组。
这意味着LLM会根据其训练过程中学到的知识,生成一些可能的答案。
- 补全:基于LLM参数中的广泛知识,生成以下补全三元组:
- (糖尿病, 饮食调整, 低GI食品)
- (低GI食品, 包括, 全谷物)
- (低GI食品, 包括, 蔬菜)
- (低GI食品, 包括, 水果)
最终答案会参考这些补全后的知识三元组,回答:“根据最新的研究,糖尿病患者可以通过摄入低GI食品来调整饮食以控制血糖水平,这包括全谷物、蔬菜和水果。”
通过这种方式,LLM不仅能够回答用户的问题,还能在回答过程中识别和弥补知识图谱中的不足,提供更有价值的信息。
AI 搜索 + LLM 更适合处理最新疗法。
检索增强生成(RAG)和知识更新
此外,通过检索增强生成(RAG)与外部文档自动验证这些三元组,这些相关文档也可作为手动审查的参考。
在将三元组合并到知识图谱之前,持续且主动的知识更新过程使知识图谱逐步满足实际知识需求,从而提高LLM回答问题的事实性。
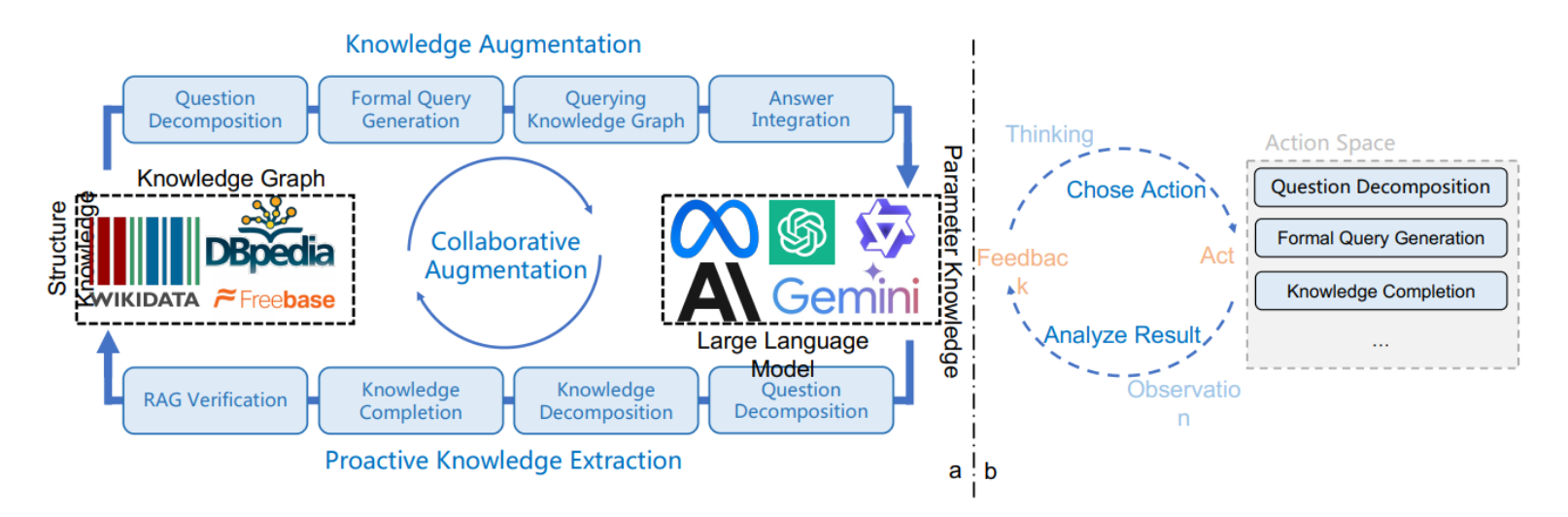
框架设计

左图部分:展示了协同增强框架的整体设计,包括LLM和知识图谱(KG)的协同工作。
-
知识增强:
- 问题分解:将用户问题分解成子问题。
- 正式查询生成:生成查询知识图谱的正式语言。
- 查询知识图谱:使用生成的正式语言查询知识图谱。
- 答案整合:将知识图谱查询结果整合成最终答案。
-
主动知识提取:
- 知识分解:将知识图谱查询结果分解成具体的知识单元。
- 知识补全:利用LLM进行知识补全。
- RAG验证:通过检索增强生成(RAG)技术验证补全的知识。
- 知识图谱更新:将验证后的知识更新到知识图谱中。
右图部分:展示了CogMG使用的代理框架,包括LLM的规划和调用工具的过程,每个模块设计为可插拔以确保通用性。
CogMG框架的单次迭代包括三个步骤:
(1)查询知识图谱:大型模型利用推理和规划能力分解查询,生成正式的查询语句以查询知识图谱。
(2)处理结果:如果成功返回结果,则整合人类偏好的详细答案。如果不成功,则明确识别和分解所需的三元组,然后将其整合到答案中。
(3)图谱演化:利用外部知识验证和修改,纳入未命中的三元组到知识图谱中。
1. 查询知识图谱
对于一个知识密集型的问题,我们首先通过将相应的正式查询分解为自然语言中的子步骤来启动方法。
这种分解有助于阐明查询知识图谱所需的必要且普遍的逻辑,确保我们的方法在各种KG架构中的通用性。
然后,LLM调用一个正式语言解析工具来执行查询。
该工具接收逻辑上分解的步骤(以自然语言为输入),将其翻译成针对目标知识图谱的正式查询语言,并返回查询结果。
2. 处理结果
在接收到来自KG的查询结果后,LLM利用其理解和推理能力来组织最终答案。
如果查询执行遇到错误,LLM会根据分解的步骤划分出未知组件的必要知识三元组。
假设这些三元组的补全能够提供回答问题所需的知识。
随后,利用模型参数中编码的知识来完成这些三元组。然后,模型根据这些事实生成最终答案。
需要注意的是,这个补全步骤适用于任何级别的LLM能力。
显式的必要知识不仅可以减轻当前输出中由于累积效应而产生的幻觉效果,还可以识别图谱中的知识空白,从而促进图谱知识覆盖的增强。
记录下这些不完整的知识三元组及其补全,以便将其纳入图谱或进一步验证。
3. 知识图谱演化
LLM内部编码的参数知识的高通用性和广泛覆盖可以补充KG中更为专业的知识。
LLM补全的这些三元组可以直接添加到KG中。
然而,LLM在处理罕见的、长尾的和领域特定的知识时存在困难,其知识陈述缺乏鲁棒性。
我们提供了手动干预的选项,管理员可以选择(1)将补全的三元组直接纳入知识图谱,(2)在添加之前手动调整它们,或(3)根据外部知识源自动验证它们。
为了自动验证和修正这些三元组,CogMG在非结构化语料库中搜索相关文档,并在文档与三元组之间进行事实比较。
这些文档可以来自领域特定的文本、通用百科全书或快速更新的搜索引擎,不仅增强了知识的事实准确性,还为手动审查提供了可解释的参考。
基于这些外部来源的见解,模型调整提议的知识三元组,使其适合手动纳入知识图谱。
-
查询知识图谱:
- 用户问:“最近有什么新药物可以治疗糖尿病?”
- LLM将查询分解为知识三元组:
- (糖尿病, 最新治疗方法, 新药物)
- (新药物, 名称, 药物C)
- (药物C, 功效, 降糖)
- 调用正式语言解析工具,查询知识图谱。如果KG中没有相关信息,则进入下一步。
-
处理结果:
- 如果查询不成功,LLM明确识别所需的知识三元组并进行补全:
- (糖尿病, 最新治疗方法, 药物C)
- (药物C, 功效, 降糖)
- (药物C, 临床试验, 通过)
- 根据这些补全三元组,生成最终答案。
- 如果查询不成功,LLM明确识别所需的知识三元组并进行补全:
-
知识图谱演化:
- 使用RAG技术检索外部文档,验证和修正这些三元组。
- 比较文档与三元组之间的事实,根据外部来源调整知识三元组。
- 管理员可以选择直接添加、手动调整或进一步验证这些三元组。
经过验证和补全,最终答案为:
“最近的新药物C已经被批准用于治疗糖尿病,并在临床试验中显示出显著的降糖效果。”
CogMG 实现
我们微调了一个开源的LLM来实现CogMG,并开发了一个在线系统来展示和评估我们提出的协同增强框架。
3.1 模型和组件
LLM能够独立计划和调用工具。我们采用了ReAct的代理框架来适应CogMG模块化和通用化的理念。
我们使用了Wikidata的一个子集作为知识图谱,KoPL作为查询引擎,KQA-Pro数据集作为微调数据集的骨干。
KQA-Pro包含自然语言问题及其对应的KoPL查询、SPARQL查询和黄金答案。
为了确保代理在各种场景中表现出预期行为,我们构建了定制的SFT数据集进行微调或利用上下文学习来提示模型。
Qwen-14B-Chat 负责所有SFT数据生成和代理骨干。
值得注意的是,我们的框架适用于各种知识图谱和LLM。接下来我们将逐个场景介绍我们的解决方案。
问题分解
利用分解步骤作为问题和正式语言之间的中介,明确问题解决逻辑并增强对不同问题表达的鲁棒性。
我们手动编写了几个查询步骤的自然语言解释,根据相应的KoPL函数调用获得问题和自然语言解释之间的并行数据案例。
通过这些并行示例,我们提示LLM在整个数据集中生成子步骤,并获得50k对数据。
这些数据被保留用于构建代理行为SFT数据集。
正式查询生成
使用并行数据可以快速训练一个解析查询步骤自然语言解释到KoPL正式程序的模型。
由于解析过程对模型能力要求相对较低,我们微调了一个7B模型来创建一个专用的知识图谱查询工具模型。
查询知识图谱
我们包装了KoPL引擎的执行,在出错时统一返回“失败”,以便于模型的决策和识别。
查询工具通过解析模型处理分解步骤输入,预测KoPL查询程序,并返回知识图谱查询结果。
答案整合
KQA Pro提供的黄金答案在词级别上简洁精准,但与人类偏好的详细解释存在差距。
因此,我们为推理模型提供了来自知识图谱执行的问答对,指导它为数据集中的每个问题生成更全面的解释性回答。答案整合场景是代理行为的一部分。
知识分解
我们显式地分解正式查询的目标三元组,以明确回答问题所需的事实。
这一步对于手动注释一些查询语句为不完整三元组是必不可少的,未知事实部分用问号表示,然后使用这些样本作为示例,让模型推断所有数据的三元组分解。
由于KoPL程序中的标签名精确,我们在三元组推理期间添加了标签名约束,如果生成了非标准标签名,则重新生成三元组。
所有的知识分解数据用于模拟处理知识图谱未涵盖的问题。
知识补全
我们直接指导模型执行知识补全任务,参考手动编写的示例。
为了适应整个ReAct代理框架并确保模块化,我们将知识补全部分封装为一个工具,输入问题和相应的不完整知识三元组,输出这些三元组与参数知识的映射。
检索增强生成验证
由于经过一般指令调优和偏好对齐的LLM熟悉RAG,我们利用提示工程请求模型基于检索到的相关文档、不完整三元组以及相应的参数知识补全生成知识三元组的修正。
我们采用Wikipedia作为检索语料库,每256个标记分成一个块。
我们通过BM25构建文档索引,通过拼接的知识三元组和原始问题进行搜索,并选择前十个块作为外部知识参考。
对于整个ReAct代理框架,我们构建了两条代理计划和调用工具的路线,区分是否知识图谱中包含必要的知识。
利用构建的并行训练数据,我们构建了SFT数据的两个思考-行动-观察执行路线,考虑到上述每个场景。
代理使用总共100k行为SFT数据进行调优。
3.2 系统和用例
知识增强生成
用户可以在底部的对话框中输入并提交知识密集型问题。
代理LLM负责处理这些问题,并按预定义路线进行处理。
思考-行动-观察模式将在相应的下拉标签中实时显示。
当知识图谱无法支持问答过程时,模型将分解知识并调用自身进行知识补全,然后提供最终答案,如图2左侧所示。
同时,这些知识三元组将记录在数据库中。
知识管理
在我们的系统的知识管理部分,我们设计了一个交互界面来显示知识图谱尚未涵盖的所有待处理实例。
界面展示了查询的来源、突显的知识缺口、模型基于内部参数完成这些知识的结果。
管理员可以选择(1)直接将新完成的知识整合到知识图谱中,或者(2)通过RAG进一步验证。
在界面中的下拉标签中可以访问相关文档和修改结果,便于进行严格的验证过程。
一旦验证完成并进行必要的调整,管理员可以将精炼的知识无缝添加到图谱中。
这个过程不仅确保了知识图谱的持续扩展和完善,还利用了管理员的专业知识来验证模型生成的知识。
通过集成这些人机协作的验证步骤,我们的系统增强了知识图谱的可靠性和准确性,使其成为回答实际问题的更强大资源。
3.3 实验
我们进一步设计并进行了实验,以证明CogMG框架的有效性。
从KQA Pro数据集中抽取问题,我们测试了以下场景:
(1)直接回答:仅使用骨干LLM回答,不利用知识图谱;
(2)CogMG不使用知识:删除图谱中的相关知识,使用参数补全知识回答;
(3)CogMG更新:更新所有相关知识,利用图谱查询结果回答。
由于准确匹配难以反映实际答案的正确性,我们手动评估了50个问题的正确性。
表1显示了这三种场景下的准确性。
实验结果表明,仅使用LLM直接回答问题由于缺乏精确的事实知识,准确性较低。
此外,利用模型的知识澄清和补全可以缓解一些幻觉并提高准确性。
最后,在利用协同增强框架更新知识图谱后,后续查询的准确性得到了提高。
总结
CogMG 框架拆解
解决知识覆盖不完整和知识更新不对齐的问题,以增强大型语言模型(LLM)和知识图谱(KG)的协同能力。
-
知识分解
- 子解法:将查询分解为知识三元组
- 特征:因为可以明确识别和定位查询中所需的具体知识单元
- 之所以用知识分解子解法,是因为:
- 这样可以有效地将复杂的查询简化为更易处理的部分
- 有助于发现知识图谱中的知识缺口
-
知识补全
- 子解法:利用LLM参数中的知识补全三元组
- 特征:因为可以利用LLM的广泛知识库来填补知识图谱中的空白
- 之所以用知识补全子解法,是因为:
- LLM可以根据其训练数据生成合理的知识补全
- 提供了在知识图谱中不存在的最新信息
-
检索增强生成(RAG)
- 子解法:通过检索外部文档来验证和补全知识
- 特征:因为可以确保补全知识的准确性和可靠性
- 之所以用检索增强生成子解法,是因为:
- 外部文档提供了额外的验证层
- 增强了知识的事实性和权威性
-
知识图谱更新
- 子解法:将验证后的知识三元组更新到知识图谱中
- 特征:因为可以动态地扩展和更新知识图谱
- 之所以用知识图谱更新子解法,是因为:
- 确保知识图谱始终包含最新和最相关的信息
- 提高知识图谱的覆盖率和实用性
通过将查询分解为知识三元组、利用LLM补全知识、通过检索增强生成验证知识,并最终更新知识图谱,CogMG框架能够有效地回答用户的问题,并动态地增强知识图谱的内容和准确性。

















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









