









论文:MEDAGENTS: Large Language Models as Collaborators for Zero-shot Medical Reasoning
代码:https://github.com/gersteinlab/MedAgents
提出背景
- 背景和问题:
- 广泛背景:大语言模型(LLM)在医疗领域应用受限
- 具体问题:
1)医疗训练数据相比通用文本数据量有限
2)需要大量专业领域知识和推理能力,但简单的prompt方法容易产生幻觉
- MEDAGENTS的本质特征:
- 本质:一个多专家协作的医疗推理框架
- 特点:通过让LLM扮演不同专家角色进行多轮讨论,提升医疗领域表现
- 创新:采用zero-shot设置,无需额外训练就能应用
- 对比案例:
- 正例:通过让LLM扮演心脏科、精神科等不同专科医生角色,共同分析一个病例
- 反例:直接让单个LLM回答医疗问题,容易产生幻觉和错误判断
-
类比理解:
就像真实医院中的多学科会诊——不同专科医生从各自专业角度提供意见,最后达成共识诊断方案。MEDAGENTS模拟了这个过程。 -
主要步骤:
1)召集领域专家
2)提出个人分析
3)总结分析报告
4)协作讨论直到达成一致
5)最终决策 -
通俗解释:
MEDAGENTS是一个"医疗智能助手",通过让AI扮演不同专科医生进行团队会诊,集思广益得出更可靠的医疗判断。 -
它解决了LLM在医疗领域应用的两大挑战:通过多专家协作增强了领域专业知识,通过结构化推理减少了幻觉。
-
关键发现:
主要矛盾:如何提升LLM在医疗领域的可靠性
解决方法:多专家协作推理框架 -
功能分析:
核心功能:提升医疗判断准确性
实现方式:多专家角色扮演+结构化推理流程 -
总结:
这是一个创新的医疗AI框架,通过模拟多学科会诊过程,在无需额外训练的情况下提升了LLM在医疗领域的表现。
规律发现
核心模式提取
- 问题模式
LLM在医疗领域的两大挑战:
专业性不足 = 数据量少 + 知识获取难
可靠性不足 = 简单prompt + 幻觉倾向
- 解决方案模式
MEDAGENTS核心机制:
多专家协作 = 角色扮演 × 结构化流程
其中:
- 角色扮演:不同专科医生视角
- 结构化流程:分析→总结→讨论→共识
- 创新模式
无需额外训练 = Zero-shot设置 + 已有知识激活
其中:
已有知识激活 = 角色定位 + 专业分工
- 效果提升模式
性能提升 = 知识互补 + 错误校正 + 共识机制
其中:
- 知识互补:多专家视角
- 错误校正:交叉验证
- 共识机制:投票表决
压缩后的核心公式
MEDAGENTS = 多专家协作(角色扮演 + 结构化流程) + Zero-shot设置
这个压缩模型揭示了论文的核心创新:
- 通过角色扮演激活LLM潜在的专业知识
- 用结构化流程保证推理可靠性
- 依靠多专家协作提升整体表现
- 实现零样本(zero-shot)应用
这种压缩不仅保留了关键信息,更揭示了MEDAGENTS的设计逻辑和创新规律。
每个组成部分都有其必要性,共同构成了一个完整的解决方案。
数据分析
让我用这四个步骤分析论文中的数据归纳推理过程:
1. 数据收集
论文收集了多个医疗数据集:
- MedQA:美国医疗执照考试题
- MedMCQA:印度医学入学考试题
- PubMedQA:医学论文摘要问答
- MMLU:6个医学相关子任务
测试规模:
- 300个随机样本
- 每个数据集进行5次重复实验
2. 数据规律挖掘
发现的关键规律:
性能表现:
- GPT-3.5:准确率64.1%(MedQA),59.3%(MedMCQA)
- GPT-4:准确率83.7%(MedQA),74.8%(MedMCQA)
- 5次重复实验结果稳定,方差小
错误分析:
- 77%:领域知识问题(缺乏/误用) 缺乏领域知识(45%)、领域知识错误检索(32%)
- 15%:一致性错误
- 8%:推理链错误
这三类错误的应对方案:
-
领域知识问题(77%):
“通过持续学习和知识库扩充来增强模型的医学专业知识储备” -
一致性错误(15%):
“设计更严格的验证机制,确保模型在相似情况下保持判断的一致性” -
推理链错误(8%):
“优化推理框架,加强中间步骤的合理性检验”
这些解决方案就像是医生的进修计划:首要是扩充专业知识,其次是培养稳定的判断力,最后是提升诊断推理能力。每个方面都很重要,但投入的资源要按比例分配。
-
领域知识问题(77%):
“专业知识储备不足或应用不当,就像一个实习医生既缺乏经验又容易误判。” -
一致性错误(15%):
“在不同时间或场景下对相同问题给出矛盾答案,就像医生今天说是感冒,明天又说是过敏。” -
推理链错误(8%):
“推理过程逻辑跳跃或得出错误结论,就像把正确的症状和错误的诊断联系起来。”
这种错误分布显示:核心问题不是推理能力,而是专业知识的掌握和运用。这就像一个医生,基本的临床思维没问题,但缺乏足够的专业知识和经验来做出准确判断。
3. 数据相关性分析
发现的关键关联:
已知数据 → 未知数据的映射:
专家数量 → 性能表现
- 问题专家:最优数量=5
- 选项专家:最优数量=2
领域多样性 → 性能表现
- 6个不同领域:64.1%
- 6个相同领域:59.2%
- 领域差异越大,性能越好
4. 数学模型建立
论文建立了MEDAGENTS框架模型:
模型公式:
Final_Decision = F(Experts_Analysis, Report_Summary, Consensus)
其中:
Experts_Analysis = Σ(Expert_i_Opinion), i∈[1,n]
Report_Summary = G(Experts_Analysis)
Consensus = H(Experts_Votes)
当且仅当 All_Votes = "Yes"
参数优化:
n_question = 5 (问题专家数量)
n_option = 2 (选项专家数量)
max_attempts = 5 (最大讨论轮数)
这个分析揭示了MEDAGENTS的关键发现:
- 专家数量存在最优值
- 领域多样性对性能有正向影响
- 讨论轮数有上限要求
- 系统性能具有可重复性
这种数据驱动的分析不仅验证了框架的有效性,也为未来改进提供了量化依据。
综合调研
- 一般是怎么办的?(主流方案)
- 现有方案主要分为两类:
- 传统方案:微调已有大模型(如MedAlpaca)或训练专用模型(BioMedGPT)
- 新兴方案:使用检索增强(RAG)或外部工具增强知识
- PDF中介绍的MedAgents提出了一个新思路:通过多专家协作来提升模型的医疗推理能力
- 最正确的选项是什么?(科学理解)
- 从论文的实验结果和分析来看,关键问题在于:
- 专业知识储备(77%的错误)远比推理能力(8%的错误)更重要
- 需要一个可解释、可靠的推理过程,而不是简单的答案生成
- 最佳路径应该是:
- 构建专业的医疗知识体系
- 设计严格的验证机制
- 保持推理过程的可解释性
- 为什么有人坚持错误选项?(系统性问题)
- 存在几个系统性误区:
- 过分关注模型规模,而忽视了专业知识的质量
- 简单套用通用领域的方法,没有针对医疗场景的特殊性
- 追求短期效果,忽视了医疗决策的严谨性要求
- 这些问题的根源在于:
- 医疗数据获取困难
- 专业知识验证成本高
- 对医疗错误的容忍度过高
解法拆解
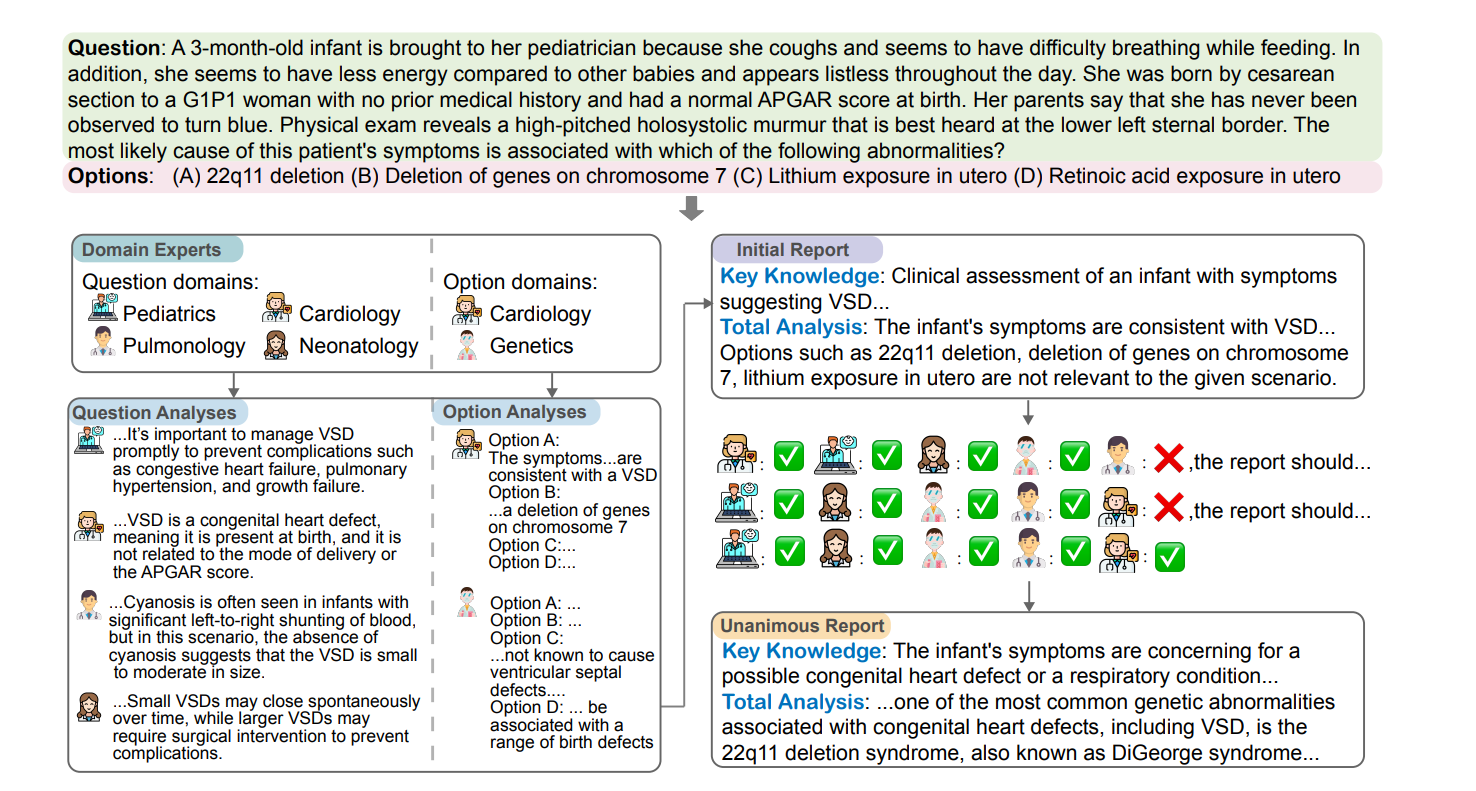
这张图展示了MEDAGENTS框架处理一个儿科医疗诊断问题的完整流程。让我详细解析:
- 问题描述:
- 一个3个月大的婴儿出现咳嗽、进食时呼吸困难
- 精神不振、无力
- 存在高音调的全收缩期杂音
- 无发绀(未变蓝)
- 需要判断最可能的病因
- 域专家聚集(左上):
- 儿科专家
- 心脏病专家
- 肺科专家
- 新生儿科专家
- 问题分析(左下):
- 专家们分析VSD(心室间隔缺损)的症状和特征
- 讨论并发症和治疗方案
- 评估疾病严重程度
- 选项分析(右侧):
分析四个可能原因:
- A:22q11缺失
- B:7号染色体缺失
- C:锂暴露
- D:维甲酸暴露
- 专家讨论和投票(中间):
- 显示专家们对分析报告的投票
- 使用对勾和叉表示同意与否
- 最终报告(右下):
得出结论:最可能的原因是22q11缺失综合征(DiGeorge综合征),这是一种与先天性心脏缺陷相关的遗传异常。
这个案例很好地展示了MEDAGENTS如何通过多专家协作的方式,系统地分析医疗问题并达成共识性结论。框架通过结构化的讨论和投票机制,确保了诊断过程的严谨性和可靠性。
- 逻辑关系拆解
目的:提升医疗大模型在零样本场景下的问答准确性
问题:医疗大模型存在专业知识缺乏、推理不可靠等问题
解法:多专家协作框架(MedAgents)
子解法拆解:
-
专家聚集(因为需要多领域专业知识)
- 之所以用专家聚集,是因为医疗问题通常涉及多个专科领域
- 示例:心脏病诊断需要心内科、影像科等多个专家意见
-
分析提议(因为需要独立专业判断)
- 之所以用分析提议,是因为每个专家从自身领域给出专业见解
- 示例:心内科专家分析心电图,影像科专家分析CT扫描
-
报告总结(因为需要信息整合)
- 之所以用报告总结,是因为需要综合各方意见形成初步判断
- 示例:综合各科室意见形成初步诊断报告
-
协作协商(因为需要达成共识)
- 之所以用协作协商,是因为需要通过讨论消除分歧
- 示例:各科室专家讨论直到达成统一诊断意见
-
决策制定(因为需要最终判断)
- 之所以用决策制定,是因为需要基于共识给出最终答案
- 示例:基于统一意见确定最终治疗方案
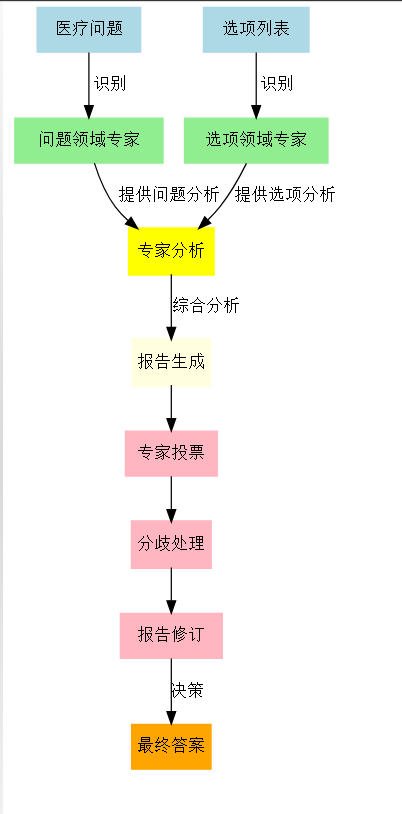
- 逻辑链分析
MedAgents决策树:
├── 专家聚集
│ ├── 问题领域专家识别
│ └── 选项领域专家识别
├── 分析提议
│ ├── 问题分析
│ └── 选项分析
├── 报告总结
│ ├── 关键知识提取
│ └── 综合分析生成
├── 协作协商
│ ├── 意见投票
│ ├── 分歧识别
│ └── 报告修订
└── 决策制定
└── 最终答案选择
- 隐性特征分析
发现的隐性特征:
- 专业知识激活:模型通过角色扮演激活潜在的专业知识
- 跨域整合:不同专家意见的权重分配和整合机制
- 共识达成:专家间意见分歧的调和过程
- 潜在局限性
- 模型基础:依赖基础模型的医学知识质量
- 专家数量:专家数量的增加可能导致决策效率降低
- 知识更新:难以及时整合最新医学进展
- 应用场景:可能不适用于需要快速决策的紧急医疗情况
- 计算成本:多轮专家讨论会增加计算资源消耗
这个分析揭示了MedAgents框架虽然创新地解决了医疗大模型的一些核心问题,但其实现和应用仍面临一些实际挑战。
全流程分析
多题一解:
- 共用特征:医疗专业知识和推理需求
- 共用解法:多专家协作框架
- 适用场景:需要多领域专业知识综合判断的医疗问题
一题多解:
- 特征1:领域知识缺失 -> 解法:专家知识激活
- 特征2:推理链断裂 -> 解法:多轮讨论验证
- 特征3:答案不一致 -> 解法:共识机制
优化建议:
-
专家选择优化:
- 原方案:固定数量专家
- 优化后:动态调整专家数量和类型
-
分析流程优化:
- 原方案:串行分析
- 优化后:并行分析+关键点同步
-
决策机制优化:
- 原方案:简单多数投票
- 优化后:加权投票系统
问题专家、选项专家
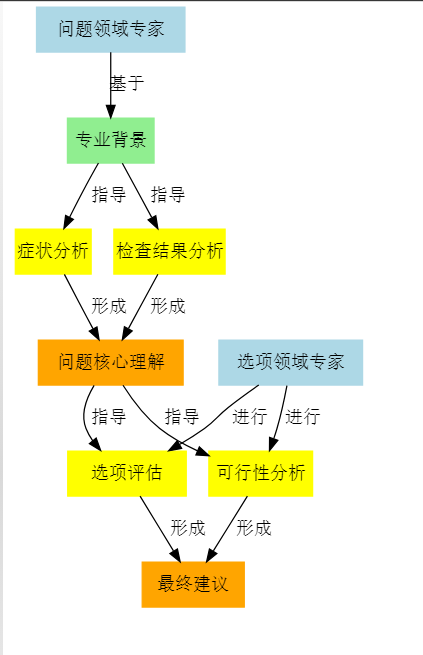
- 从问题领域专家提供分析:
- 专家根据各自专业背景分析问题
- 心脏病例中,心内科专家分析心脏症状
- 影像科专家分析CT扫描结果
- 内分泌科专家分析代谢指标
- 目的是从各自专业角度理解问题的核心
- 从选项领域专家提供分析:
- 专家分析每个选项的可能性
- 药物选择题中,药理学专家分析药物作用
- 基因专家分析基因相关选项
- 病理专家分析疾病机制相关选项
- 目的是评估每个选项的合理性和适用性
为什么选项专家,不是XX科医生?
问题领域专家和选项领域专家的设计区别:
- 问题领域专家 (临床科室专家)
- 特点:基于临床科室划分
- 原因:
- 问题通常描述的是患者的症状和体征
- 需要从临床诊疗角度理解病情
- 模拟实际医院的科室会诊模式
- 例子:
- 心内科 -> 心脏症状
- 影像科 -> CT/MRI结果
- 内分泌科 -> 代谢指标
- 选项领域专家 (基础医学专家)
- 特点:基于基础医学学科划分
- 原因:
- 选项往往涉及疾病机制、治疗原理
- 需要从基础医学角度评估选项
- 确保选项的科学依据
- 例子:
- 药理学专家 -> 药物作用机制
- 基因专家 -> 遗传学原理
- 病理专家 -> 疾病发展机制
这种设计的优势:
-
完整覆盖医学知识体系:
- 临床医学(问题分析)
- 基础医学(选项分析)
-
互补性强:
- 临床专家提供实践经验
- 基础专家提供理论支持
-
模拟真实医疗决策:
- 临床医生处理具体病例
- 会诊时常需咨询基础医学专家
这就解释了为什么选项领域专家不是具体科室的医生,而是基础医学专家 - 因为这样的设计能更好地评估选项背后的科学原理和合理性。
类比医院会诊制度
第一步:确认源案例
- 新任务:改进医疗大模型的零样本场景问答能力
- 参考对象:医院多学科会诊制度
- 具体操作:医院在处理复杂病例时的多学科专家会诊流程
第二步:框架提取
| 医院会诊具体行为 | 框架本质 | MedAgents执行方案 |
|---|---|---|
| 根据病情确定需要哪些科室专家参与会诊 | 专业知识覆盖面的确定 | 基于问题和选项识别所需专业领域,动态选择专家角色 |
| 各科室专家独立进行检查和诊断 | 独立专业判断的形成 | 每个领域专家基于自身专业知识进行独立分析 |
| 专家们集中讨论,交换意见 | 跨领域知识的交叉验证 | 实现专家间的意见交流,相互验证和补充 |
| 形成初步诊疗意见 | 综合信息形成初步结论 | 生成初步分析报告,总结各方观点 |
| 主治医师主持讨论,统一意见 | 分歧解决和共识达成 | 通过投票和修订机制达成最终一致意见 |
| 形成最终诊疗方案 | 做出最终决策 | 基于共识生成最终答案 |
| 记录完整会诊过程 | 保证决策过程可追溯 | 保存完整的分析和讨论过程 |
第三步:方案设计
- 具体场景实现:
- 构建五步骤框架:专家聚集→分析提议→报告总结→协作协商→决策制定
- 设计专家角色定义机制
- 开发协作和共识达成流程
- 结合资源条件:
- 利用大模型的角色扮演能力
- 基于已有医学知识进行专业分析
- 设计可扩展的框架结构
- 快速行动计划:
第一阶段(1个月):
- 实现基础专家角色定义
- 建立简单的分析流程
- 开发基础共识机制
第二阶段(2-3个月):
- 完善专家协作机制
- 优化分析报告生成
- 改进决策制定流程
第三阶段(3-6个月):
- 实现动态专家调整
- 开发并行分析能力
- 建立完整评估体系
这个分析展示了如何通过类比医院会诊制度,提取出可用于改进医疗大模型的框架,并设计出具体可行的实施方案。关键是理解并迁移核心机制,而不是简单模仿表面流程。
论文大纲
├── 1 研究背景【领域现状】
│ ├── LLMs进展【技术发展】
│ │ ├── 跨领域泛化能力【技术优势】
│ │ └── 基于大规模语料训练【技术基础】
│ └── 医疗领域挑战【问题陈述】
│ ├── 领域特定术语【专业性障碍】
│ └── 专业知识推理【技术瓶颈】
│
├── 2 主要问题【核心障碍】
│ ├── 医疗训练数据受限【数据层面】
│ │ ├── 数据成本高【获取难度】
│ │ └── 隐私保护要求【合规性】
│ └── 专业知识应用困难【应用层面】
│ ├── 知识获取成本高【资源限制】
│ └── 简单提示不足【方法局限】
│
├── 3 解决方案【技术框架】
│ ├── MedAgents框架【核心设计】
│ │ ├── 多专家协作【框架特征】
│ │ └── 零样本场景【应用场景】
│ └── 实现流程【具体步骤】
│ ├── 专家聚集【初始阶段】
│ ├── 分析提议【分析阶段】
│ ├── 报告总结【整合阶段】
│ ├── 协作协商【讨论阶段】
│ └── 决策制定【决策阶段】
│
├── 4 专家类型【角色划分】
│ ├── 问题领域专家【临床专家】
│ │ ├── 心内科专家【症状分析】
│ │ ├── 影像科专家【检查解读】
│ │ └── 内分泌科专家【代谢评估】
│ └── 选项领域专家【基础专家】
│ ├── 药理学专家【药物机制】
│ ├── 基因专家【遗传分析】
│ └── 病理专家【病理机制】
│
└── 5 错误分析【问题统计】
├── 领域知识问题(77%)【知识缺陷】
├── 一致性错误(15%)【逻辑矛盾】
└── 推理链错误(8%)【推理缺陷】
├── 2 方法【MEDAGENTS框架的五个阶段】
│ ├── 专家聚集【组织不同领域的专家】
│ │ ├── 输入【临床问题和选项】
│ │ ├── 处理【根据问题和选项选择相关领域的专家】
│ │ └── 输出【组成的专家小组】
│ ├── 分析提议【专家对问题和选项进行分析】
│ │ ├── 输入【来自专家聚集阶段的输出】
│ │ ├── 处理【各领域专家提供的独立分析】
│ │ └── 输出【汇总的分析结果】
│ ├── 报告总结【整合所有分析形成报告】
│ │ ├── 输入【分析提议阶段的输出】
│ │ ├── 处理【提取关键知识和总体分析来编制报告】
│ │ └── 输出【初步报告】
│ ├── 协作咨询【通过多轮讨论修正和完善报告】
│ │ ├── 输入【报告总结阶段的输出】
│ │ ├── 处理【不同专家之间的讨论和修改建议】
│ │ └── 输出【经过一致同意的最终报告】
│ └── 决策制定【基于最终报告做出决策】
│ ├── 输入【协作咨询阶段的输出】
│ ├── 处理【利用最终报告作为依据进行决策】
│ └── 输出【最终决策结果】
创意视角
- 组合创新
-
临床专家 + 基础专家:
- 创新点:加入研究型医生角色
- 优势:既懂临床实践又精通基础研究
- 效果:提升专业知识深度和准确性
-
并行决策 + 序列验证:
- 创新点:多专家同时分析,按序验证结果
- 优势:提高效率同时保证准确性
- 效果:平衡速度和质量
- 拆开创新
-
专家角色细分:
- 创新点:将专家角色按更细粒度划分
- 例如:治疗专家、诊断专家、预后专家
- 效果:提高专业性和针对性
-
决策流程模块化:
- 创新点:将五步流程细分为可独立优化的模块
- 优势:便于针对性改进和优化
- 效果:提高系统灵活性
- 转换创新
- 角色动态转换:
- 创新点:专家可根据问题特点转换角色
- 优势:增加系统适应性
- 效果:提高资源利用效率
- 借用创新
-
法庭辩论模式:
- 创新点:引入正反方辩论机制
- 优势:通过对抗性讨论深入挖掘问题
- 效果:提高结论可靠性
-
学术审稿流程:
- 创新点:采用多轮同行评议机制
- 优势:系统化的验证和改进过程
- 效果:提升分析质量
- 联想创新
-
免疫系统模式:
- 创新点:模拟人体免疫系统的多层防御机制
- 优势:建立多重验证屏障
- 效果:降低错误率
-
股市交易机制:
- 创新点:引入投票权重动态调整
- 优势:基于历史准确率调整专家影响力
- 效果:优化决策质量
- 反向思考创新
-
错误优先:
- 创新点:首先假设所有答案都是错误的
- 优势:通过排除法找到正确答案
- 效果:提高分析严谨性
-
反向专家:
- 创新点:设置专门的质疑专家角色
- 优势:系统性挑战每个结论
- 效果:增强验证机制
- 问题创新
- 元问题分析:
- 创新点:增加问题分析专家角色
- 优势:深入理解问题本质
- 效果:提高答案针对性
- 错误驱动创新
-
错误模式库:
- 创新点:建立历史错误分类数据库
- 优势:通过错误案例学习改进
- 效果:预防常见错误
-
自我纠错机制:
- 创新点:每个专家都必须指出自己可能的偏见
- 优势:提高决策透明度
- 效果:减少主观偏差
- 感情创新
-
病人视角整合:
- 创新点:添加病人体验专家角色
- 优势:考虑治疗方案的人文因素
- 效果:提高方案可行性
-
医患关系模拟:
- 创新点:模拟真实医患沟通场景
- 优势:增强答案的实用性和人性化
- 效果:提高临床适用性
- 模仿创新
-
模拟会诊升级:
- 创新点:引入预备会诊和后续追踪
- 优势:完整覆盖诊疗过程
- 效果:提高诊断准确性
-
教学查房模式:
- 创新点:集成教学功能
- 优势:通过案例积累提升系统能力
- 效果:持续改进系统性能
- 类比创新
- 蜂群决策模型:
- 创新点:模拟蜜蜂群体决策机制
- 优势:高效的集体智慧系统
- 效果:提高决策效率
- 印象型思维创新
-
直觉诊断层:
- 创新点:增加基于临床直觉的快速判断机制
- 优势:捕捉经验医生的"第六感"
- 效果:提高诊断速度和准确性
-
可视化决策:
- 创新点:将诊断过程转化为可视化流程
- 优势:直观展示专家思维路径
- 效果:提高系统可解释性
- 自我对话创新
-
反思机制:
- 创新点:每个决策后进行自我质询
- 优势:强制系统检查决策合理性
- 效果:减少草率决策
-
场景推演:
- 创新点:模拟不同情况下的决策结果
- 优势:预测可能的风险和后果
- 效果:提高决策稳健性
- 以终为始创新
-
结果导向框架:
- 创新点:从理想治疗结果反推诊断流程
- 优势:确保诊断与治疗目标一致
- 效果:提高治疗有效性
-
风险预控:
- 创新点:预先设定风险控制目标
- 优势:在诊断过程中主动防范风险
- 效果:提高患者安全性
- 思维风暴创新
-
开放式专家讨论:
- 创新点:允许专家提出非常规解决方案
- 优势:突破传统诊疗思维限制
- 效果:发现创新治疗方案
-
集体智慧整合:
- 创新点:综合不同专业背景的创新想法
- 优势:产生跨学科创新方案
- 效果:提高诊疗创新性
- 最渴望联结创新
-
医生渴望:
- 创新点:整合医生最需要的辅助功能
- 例如:自动文献检索、相似病例推荐
- 效果:提高系统实用性和接受度
-
患者渴望:
- 创新点:加入患者最关心的分析维度
- 例如:治疗风险评估、康复周期预测
- 效果:提高诊疗方案的接受度
- 空隙填补创新
-
临床决策空隙:
- 创新点:补充传统会诊中容易忽视的环节
- 例如:罕见病筛查、药物相互作用分析
- 效果:提高诊断全面性
-
知识更新空隙:
- 创新点:实时整合最新医学研究进展
- 例如:自动更新临床指南、新药信息
- 效果:保持知识时效性
- 再定义创新
-
专家角色再定义:
- 创新点:将专家定义为知识验证者而非生产者
- 优势:更好利用AI的知识整合能力
- 效果:提高决策效率
-
诊断流程再定义:
- 创新点:从线性流程改为网状协作模式
- 优势:允许更灵活的专家互动
- 效果:提高系统适应性
- 软化创新
-
渐进式决策:
- 创新点:将硬性决策转变为软性建议
- 优势:留给人类医生更多判断空间
- 效果:减少决策压力
-
弹性专家体系:
- 创新点:允许专家角色的动态切换
- 优势:增加系统灵活性
- 效果:提高资源利用效率
- 附身创新
-
名医思维模拟:
- 创新点:模拟顶级专家的诊断思维模式
- 优势:复制优秀诊疗经验
- 效果:提高诊断质量
-
患者视角体验:
- 创新点:从患者角度评估方案可行性
- 优势:增加人性化考虑
- 效果:提高方案接受度
- 配角创新
-
护理专家视角:
- 创新点:加入护理执行难度评估
- 优势:考虑治疗方案的实操性
- 效果:提高方案可行性
-
医技支持角色:
- 创新点:整合医技人员的专业意见
- 优势:完善检查方案设计
- 效果:提高诊断准确性
- 刻意创新
-
极端场景测试:
- 创新点:故意设置极端医疗情况
- 优势:测试系统边界能力
- 效果:提高系统稳定性
-
矛盾观点强化:
- 创新点:刻意放大专家意见分歧
- 优势:深入探讨争议点
- 效果:提高结论可靠性
- 联想创新扩展
-
跨学科联想:
- 创新点:引入工程学、心理学等领域思维
- 优势:拓展问题解决思路
- 效果:产生创新解决方案
-
自然系统启发:
- 创新点:借鉴生态系统的自组织特性
- 优势:优化专家协作机制
- 效果:提高系统效率
-
综合评估标准
对以上所有创新点进行评估,基于以下标准: -
实现可行性:
- 技术难度
- 资源需求
- 实施周期
- 预期效果:
- 准确性提升
- 效率提升
- 用户接受度
- 创新价值:
- 解决关键问题
- 独特性
- 扩展潜力
最佳创新点推荐:
- 错误模式库 + 动态专家调整
- 原因:直接解决主要问题(77%知识错误) – 缺乏领域知识(45%)、领域知识错误检索(32%)
- 可行性高:基于现有框架扩展
- 效果可测:有明确的评估指标
- 多层验证机制 + 弹性专家体系
- 原因:提高系统可靠性
- 灵活性强:适应不同场景
- 扩展性好:可持续优化
- 知识更新空隙补充 + 实时临床指南整合
- 原因:保持知识时效性
- 实用性强:直接服务临床
- 价值明确:解决实际需求
这些创新点组合既保持了原有框架的优势,又在关键环节进行了有针对性的改进,可以显著提升系统的整体性能。

















 915
915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









