









论文:MedTsLLM: Leveraging LLMs for Multimodal Medical Time Series Analysis
代码:https://github.com/flixpar/med-ts-llm
论文大纲
├── 1 研究动机【研究背景】
│ ├── 医疗数据的复杂性与异质性【问题背景】
│ │ ├── 非结构化文本【数据类型】
│ │ ├── 半结构化电子病历【数据类型】
│ │ └── 高频生理信号【数据类型】
│ └── 现有方法的局限性【技术挑战】
│ ├── 缺乏高质量标注数据【具体问题】
│ ├── 模态整合困难【具体问题】
│ └── 特征工程复杂【具体问题】
│
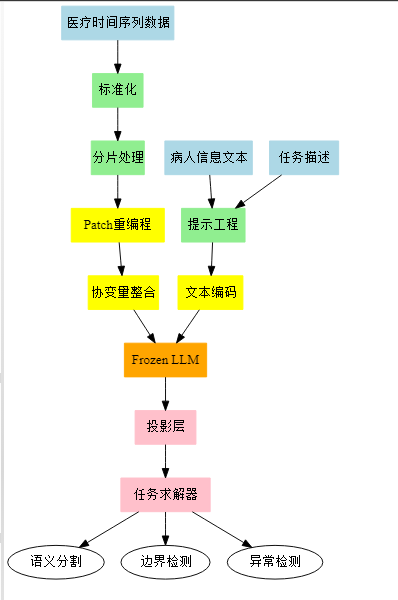
├── 2 MedTsLLM框架【技术方案】
│ ├── 提示生成模块【核心组件】
│ │ ├── 数据集描述【组件功能】
│ │ ├── 任务描述【组件功能】
│ │ ├── 数据统计信息【组件功能】
│ │ └── 患者个人信息【组件功能】
│ ├── 时间序列编码【核心组件】
│ │ ├── 补丁嵌入【处理方法】
│ │ └── 协变量合并策略【处理方法】
│ ├── 预训练LLM【核心组件】
│ └── 任务求解器【核心组件】
│ ├── 语义分割【功能模块】
│ ├── 边界检测【功能模块】
│ └── 异常检测【功能模块】
│
├── 3 技术创新【研究贡献】
│ ├── 多模态数据融合【创新点】
│ ├── 协变量处理方法【创新点】
│ ├── 个性化提示构建【创新点】
│ └── 新型时间序列任务【创新点】
│
└── 4 应用价值【实际意义】
├── 提升诊断效率【应用效果】
├── 辅助临床决策【应用效果】
└── 改善患者预后【应用效果】
理解
- 背景和问题:
- 类别问题:医疗数据分析中的时间序列处理问题
- 具体问题:
- 医疗数据异质性强(包括文本、病历、生理信号等)
- 高质量标注数据缺乏
- 多模态数据整合困难
- 缺乏统一的处理框架
- 概念性质:
- 性质:一个多模态医疗时间序列分析框架
- 原因:医疗数据的复杂性和现有方法的局限性推动了这种统一框架的产生
- 对比案例:
- 正例:将ECG数据与病历文本结合,提高心律失常检测准确率
- 反例:单独使用ECG波形数据进行分析,忽略患者病史信息,导致误判
- 类比理解:
MedTsLLM就像一个多语言翻译官:
- 翻译官懂多种语言 → MedTsLLM理解多种数据类型
- 综合语境理解含义 → 结合患者信息理解医疗数据
- 准确传达完整信息 → 提供准确的医疗分析结果
- 概念介绍与总结:
MedTsLLM是一个基于大语言模型的医疗时间序列分析框架,能够:
- 处理多模态医疗数据
- 执行语义分割、边界检测、异常检测等任务
- 提供个性化分析结果
-
概念重组:
"医疗时间序列大语言模型"是一个能将医疗数据时间化、序列化,并用语言模型理解和分析的智能系统。 -
上下文关联:
本框架是对传统医疗数据分析方法的突破性改进,通过整合LLM技术解决了多模态数据分析的难题。
- 规律发现:
原则:
- 多模态融合
- 个性化分析
- 任务通用性
主要矛盾:
- 医疗数据的异质性与分析需求的统一性之间的矛盾
次要矛盾:
- 计算资源消耗
- 模型复杂度
- 训练数据需求
- 功能分析:
核心功能:提供准确的医疗数据分析
具体表现:
- 定量指标:准确率、F1分数、IoU值等
- 定性效果:辅助临床决策、提高诊断效率
- 来龙去脉梳理:
- 起因:医疗数据分析需求与现有技术局限性的矛盾
- 发展:提出基于LLM的统一框架
- 结果:实现了多个医疗数据分析任务的高效处理
- 影响:为临床决策提供更可靠的数据支持,推动精准医疗发展
这个框架的创新之处在于它首次将LLM技术应用于医疗时间序列分析,并通过多模态融合提高了分析准确性。
1. 确认目标
如何构建一个统一的框架来处理多模态医疗时间序列数据?
2. 分析过程(目标-手段分析)
最终目标:研发一个能同时处理文本和时间序列数据的医疗分析系统
层层分解:
-
如何处理多模态输入?
- 设计提示生成模块,包含数据集描述、任务描述等
- 使用补丁嵌入方法处理时间序列
- 开发协变量合并策略处理多维数据
-
如何确保模型理解医疗上下文?
- 引入预训练LLM作为骨干网络
- 设计特定的提示模板包含患者信息
- 加入医疗领域知识到提示中
-
如何完成具体的分析任务?
- 开发三个专门的任务求解器:
- 语义分割:识别信号的不同阶段
- 边界检测:确定信号的关键点
- 异常检测:发现异常模式
- 开发三个专门的任务求解器:
3. 实现步骤
-
数据准备阶段:
- 收集多模态医疗数据
- 构建标准化的数据处理流程
-
模型构建阶段:
- 实现提示生成模块
- 开发时间序列编码器
- 整合预训练LLM
- 构建任务特定求解器
-
训练和评估阶段:
- 在多个医疗数据集上训练
- 与现有方法进行对比
- 进行消融实验
4. 效果展示
目标:构建统一的医疗时间序列分析框架
过程:通过多模态融合和任务特化设计
问题:处理异质性数据的挑战
方法:LLM结合特定任务求解器
结果:在多个任务上超越现有方法
数字:
- 语义分割:F1分数98.92%
- 异常检测:AUROC 98.52%
- 边界检测:IoU 0.89
5. 金手指分析
本文的金手指是"多模态融合+LLM技术",这一组合可以解决多种医疗数据分析问题:
应用案例:
-
ECG信号分析
- 结合病历文本提高心律失常检测准确率
- 通过患者历史改进波形分割质量
-
呼吸信号分析
- 融合多种生理信号提高呼吸紊乱检测
- 结合临床记录优化呼吸相位识别
-
其他潜在应用
- 睡眠监测数据分析
- 血压波形研究
- 多模态生理信号同步分析
这种方法的普适性在于它能够:
4. 自动整合多源数据
5. 充分利用上下文信息
6. 适应不同的医疗分析任务
7. 保持较高的准确性
结构分析
1. 层级结构分析
叠加形态(从基础到高级)
-
基础层:原始数据处理
- 时间序列数据预处理
- 文本数据标准化
- 数据对齐和同步
-
编码层:数据表示学习
- 补丁嵌入
- 提示生成
- 协变量处理
-
理解层:语义分析
- LLM文本理解
- 时间序列特征提取
- 多模态信息融合
-
应用层:任务执行
- 语义分割
- 边界检测
- 异常识别
构成形态(部分到整体)
核心能力:医疗时间序列分析
-
组件一:提示生成模块
- 数据集描述
- 任务描述
- 患者信息
涌现能力:上下文理解
-
组件二:时间序列编码器
- 补丁嵌入
- 重编程层
- 协变量策略
涌现能力:多维数据处理
-
组件三:LLM骨干网络
- 文本处理
- 特征提取
- 跨模态学习
涌现能力:知识迁移
分化形态(从一到多)
MedTsLLM
├── 数据处理能力
│ ├── 时间序列处理
│ │ ├── 单变量
│ │ └── 多变量
│ └── 文本处理
│ ├── 结构化文本
│ └── 非结构化文本
│
├── 分析能力
│ ├── 模式识别
│ ├── 异常检测
│ └── 边界识别
│
└── 应用场景
├── 心电图分析
├── 呼吸监测
└── 生命体征分析
2. 线性结构分析(发展趋势)
- 单一模态 → 多模态融合
- 固定模型 → 适应性架构
- 通用分析 → 专业医疗
- 独立任务 → 统一框架
- 离线处理 → 实时分析
3. 矩阵结构分析(定位分析)
数据类型
任务 │ 时间序列 │ 文本 │ 混合数据
─────┼──────────┼──────┼──────────
分割 │ ★ │ ○ │ ★★
边界 │ ★★ │ ○ │ ★
异常 │ ★ │ ★ │ ★★
★★:特别适用 ★:适用 ○:不适用
4. 系统分析(复杂关系)
输入数据 ──────┐
↓
患者信息 ──→ 提示生成 ──→ LLM处理 ──→ 任务求解 ──→ 分析结果
↑ ↑ ↑
医疗知识 ──────┘ 特征提取 ────┘ └── 验证反馈
组合分析发现:
- MedTsLLM是一个多层次、递进式的系统
- 各组件之间存在紧密的交互关系
- 系统具有良好的扩展性和适应性
- 框架设计遵循从简单到复杂的演化规律
这种多维度的结构分析帮助我们更好地理解系统的:
- 组成部分(层级结构)
- 发展方向(线性结构)
- 应用范围(矩阵结构)
- 内部关联(系统分析)
全流程
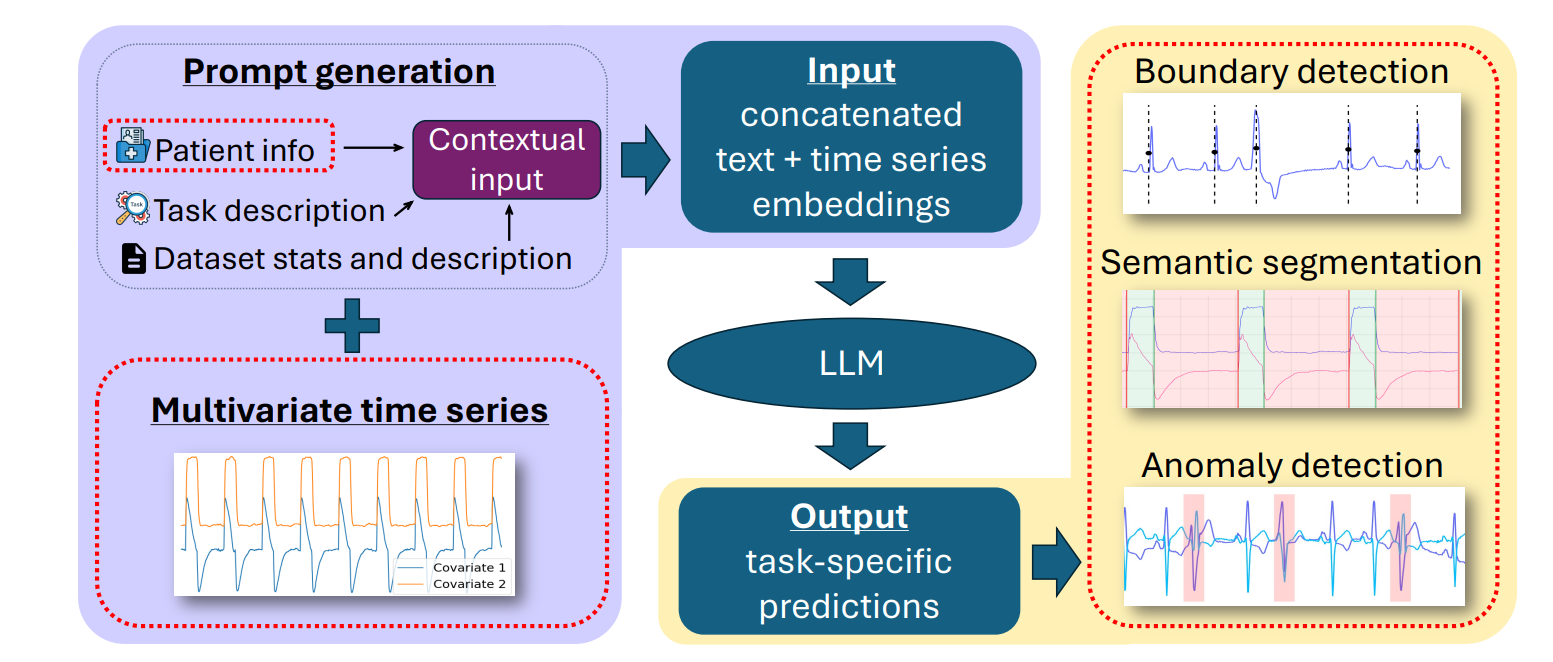
这是一个高层次的框架概述图,展示了MedTsLLM的主要组件:
- 输入部分:包括上下文输入(数据集描述、病人信息、任务描述)和多维时间序列数据
- 中间处理:将文本和时间序列数据转换为嵌入向量并连接
- 预训练LLM:处理连接后的嵌入向量
- 输出部分:根据不同任务(边界检测、语义分割、异常检测)生成特定预测
- 用红色虚线标出了该框架的创新贡献部分
- 输入输出举例:
输入:
- 医疗时间序列数据:如ECG波形、呼吸机波形数据
- 病人信息:年龄、性别、用药记录、临床注释等
- 任务描述:如"检测ECG中的异常波形"
输出(根据不同任务):
- 语义分割:将呼吸波形分割为吸气和呼气阶段
- 边界检测:标记出ECG中每个心跳的起始点
- 异常检测:识别出不规则的心律波形
实际医疗应用举例:
- 呼吸机监测:
- 输入:呼吸压力和流量波形、病人基本信息
- 处理:分析波形模式,结合病人状态
- 输出:识别出正常/异常呼吸模式,辅助医生调整参数
- 心电图分析:
- 输入:ECG波形数据、病人病历
- 处理:波形分段、特征提取、异常检测
- 输出:标记出P波、QRS波群等,检测心律失常
- 优化分析:
多题一解:
- 共用特征:医疗时间序列数据的周期性、连续性特征
- 共用解法:基于LLM的多模态特征融合架构
- 适用场景:需要结合结构化时序数据和非结构化文本的医疗分析任务
一题多解:
- 协变量整合策略:串联、交错、平均等不同方式
- 任务求解器设计:根据具体任务(分割/检测/异常)采用不同的输出层结构
优化方向:
- 输入端:改进提示工程,更好整合病人信息
- 特征提取:优化Patch重编程策略
- 模型结构:探索更高效的协变量融合方式
- 输出端:针对具体医疗任务优化任务求解器
核心模式
核心压缩:
医疗数据 = 时序数据 + 文本数据
MedTsLLM = LLM骨干网络 + 时序编码器
关键创新点:
1. Patch重编程: 时序数据 -> LLM词向量空间
2. 协变量策略: 多维时序数据的特征融合
3. 提示工程: 结构化+非结构化医疗信息整合
三大任务统一框架:
输入统一: {时序波形, 病人信息} -> LLM
输出差异: 投影层 -> {分割/边界/异常}
设计了有效的协变量合并策略,更好地捕捉多变量之间的关系
通过 patch reprogramming 层将时间序列映射到 LLM 的嵌入空间
性能提升来源:
- LLM预训练知识
- 多模态信息融合
- 任务特定优化
找到的关键模式:
- 数据模式:
- 医疗数据中时序和文本是天然配对
- 多维生理信号间存在协同关系
- 模型模式:
- 使用LLM作为统一特征提取器
- 通过编码对齐实现模态融合
- 任务模式:
- 三类医疗时序分析任务本质相通
- 共享特征提取但保持输出端灵活性
通过识别和利用这些模式, MedTsLLM实现了:
- 架构简化: 统一的多任务框架
- 计算优化: 共享LLM特征提取
- 性能提升: 充分利用预训练知识
这个压缩版本保留了原论文的核心创新和关键思路, 同时通过提炼模式使其更容易理解和应用。
数据分析
第一步,收集数据:
研究人员收集了以下几类数据:
- 医疗设备的时间序列数据:
- 呼吸机波形(压力和流量)
- 心电图信号
- 呼吸信号
- 临床背景数据:
- 患者人口统计学信息
- 病史记录
- 临床记录
- 诊断报告
- 用药信息
第二步,寻找规律:
他们发现了几个重要的规律:
- 生理信号中的规律性模式,如心跳和呼吸周期
- 表明医疗问题的异常模式
- 信号不同组成部分之间的关系(如心电图中的 P 波、QRS 波群)
- 显示信号随时间变化的时间模式
第三步,相关性分析:
研究人员发现了重要的相关性:
- 不同生理信号之间的相关性(如心肺互动)
- 信号模式与临床结果之间的相关性
- 患者特定信息与信号特征之间的相关性
- 文本医疗背景与信号解释之间的相关性
第四步,建立模型:
他们创建了 MedTsLLM 这个数学/计算模型:
- 使用大语言模型同时处理结构化的时间序列数据和非结构化的临床文本
- 通过"补丁重编程层"将时间序列数据与文本嵌入对齐
- 通过各种协变量合并策略处理多个数据流
- 执行三个具体任务:
- 语义分割
- 边界检测
- 异常检测
这个模型的表现优于现有方法,表明它成功捕捉到了医疗数据中的基本模式和关系。研究人员在多个医疗领域和数据集上验证了他们的模型,证明了其通用性。
这个分析遵循了从原始数据收集,通过模式发现和相关性分析,最终发展出一个可用于未来预测和分析的数学/计算模型的归纳推理过程。
解法拆解
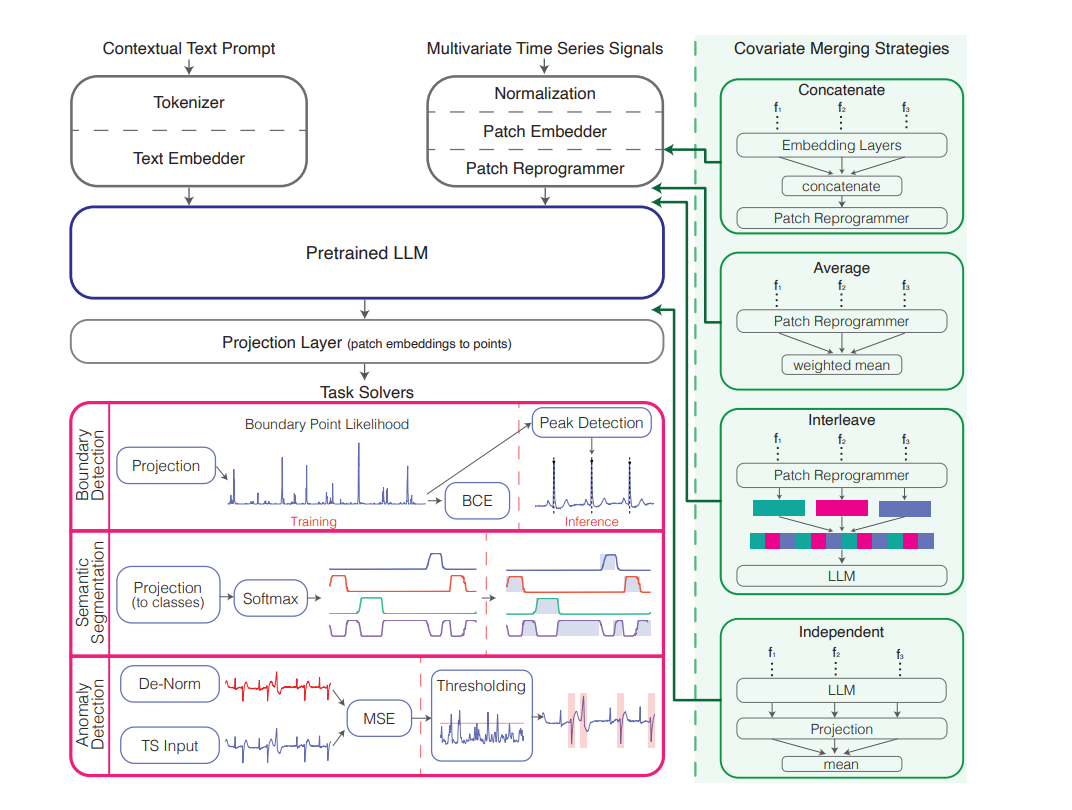
这是一个非常详细的技术架构图,分为几个主要部分:
-
输入处理流程:
- 文本部分:通过tokenizer和嵌入层处理
- 时间序列部分:通过归一化和patch嵌入处理
-
协变量合并策略(右侧绿色部分):
- Concatenate:直接连接不同协变量
- Average:对协变量进行加权平均
- Interleave:交错排列不同协变量
- Independent:独立处理每个协变量
-
任务处理器(粉色部分):
- 边界检测:使用边界点似然度和峰值检测
- 语义分割:使用投影和softmax分类
- 异常检测:使用去归一化和MSE计算
-
处理流程示例:
- 训练阶段的数据流
- 推理阶段的预测生成
- 逻辑拆解:
技术架构 = 文本编码器 + 时间序列编码器 + LLM 骨架 + 任务求解器
子解法拆解:
a) 文本编码处理
- 使用 prompt 生成模块,因为需要整合多种信息(数据集描述、任务描述、统计信息、病人信息)
- 使用标准的 tokenizer 和嵌入层,因为需要与预训练 LLM 兼容
b) 时间序列处理
- 使用 patch 分块策略,因为需要将连续信号转换为离散表示
- 使用 reprogramming 层,因为需要对齐时间序列和文本的嵌入空间
c) 多变量融合策略
- 提供四种协变量合并方法(concatenate、average、interleave、independent),因为不同场景下变量间关系不同
- 使用可学习的权重,因为不同变量的重要性可能不同
d) 任务特定处理
- 语义分割:point-wise 分类
- 边界检测:likelihood 评分 + 峰值检测
- 异常检测:重构误差阈值
-
逻辑结构:
是一个网络结构,主要分为两条并行路径(文本处理、时间序列处理),然后在 LLM 中融合,最后通过特定任务处理器输出结果。 -
隐性方法:
- Patch 大小和步长的选择策略
- 多变量融合策略的动态选择机制
- 任务特定阈值的自适应调整
- 隐性特征:
- 时间序列的局部相关性(影响 patch 设计)
- 变量间的交互模式(影响融合策略选择)
- 任务特定的模式(如呼吸周期、心跳特征等)
- 潜在局限性:
- 计算成本较高,需要大量 GPU 资源
- 对训练数据质量和数量要求较高
- 模型可解释性有限
- 可能不适用于实时处理场景
- 对特定医疗领域的适应性需要验证
- 缺乏对时间序列长期依赖关系的显式建模
问题
为什么传统的时间序列分析方法在处理医疗数据时会面临挑战?
- 医疗数据的异质性和多维度特性(不同类型的生理信号、文本记录等)
- 需要复杂的特征工程和数据对齐
- 难以整合非结构化数据(如临床笔记)和结构化数据
- 缺乏对领域特定知识的理解
MedTsLLM是如何克服医疗数据分析中的多模态问题的?
- 使用patch reprogramming层将时间序列数据与LLM的嵌入空间对齐
- 通过自然语言提示整合文本和临床信息
- 开发了多种协变量合并策略来处理多维时间序列
- 利用LLM预训练获得的知识来理解不同模态的数据
对比传统机器学习方法,LLM在医疗时间序列分析中带来了哪些独特优势?
- 能够利用预训练获得的医学领域知识
- 可以自然地整合非结构化文本信息
- 不需要针对特定任务进行复杂的特征工程
- 具有更好的泛化能力,可以处理不同类型的医疗数据
prompt工程在这个框架中扮演什么角色?为什么要包含病人特定信息?
- 包含数据集描述、任务描述、统计信息和病人特定信息
- 病人特定信息能够提供重要的临床背景
- 帮助模型更好地理解任务要求
- 实验表明合适的prompt可以显著提升模型性能
协变量合并策略的选择对模型性能有何影响?
- 提出了concatenate、average、interleave和independent四种策略
- Interleave和concatenate策略通常表现最好
- 不同策略在计算开销和信息保留上有权衡
- 策略选择需要考虑具体应用场景和数据特点
为什么要选择边界检测、语义分割和异常检测这三个任务?它们的临床意义是什么?
- 边界检测:帮助识别心跳、呼吸等生理周期
- 语义分割:区分不同生理阶段(如吸气呼气)
- 异常检测:及时发现异常生理状态
这些任务对临床决策和患者监护具有重要意义
模型的可解释性如何?这对临床实践有何影响?
- 论文承认这是一个限制
- 建议未来工作开发更透明的解释方法
- 对于基础任务,性能可能比可解释性更重要
- 可以考虑通过文本输出提供解释
计算资源需求和模型规模之间如何权衡?
- 使用较小的LLM可以显著减少计算需求
- 冻结LLM主干减少训练开销
- 可以探索量化等优化方法
- 需要平衡性能和效率
该框架如何保证对不同类型医疗数据的泛化性?
- 在多个医疗数据集上验证
- 设计通用的数据处理框架
- 利用LLM的领域知识迁移能力
- 提供灵活的协变量处理策略
未来该框架可能面临哪些挑战和改进方向?
- 提高模型可解释性
- 降低计算资源需求
- 扩展到更多医疗领域
- 整合更多EHR数据
- 添加预测等新功能
- 解决标注数据稀缺问题

















 1082
1082

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









