









RAM-EHR: 基于多源知识检索增强的电子健康记录临床预测框架,实现AUROC提升3.4%、AUPR提升7.2%的医疗预测新方法
- 论文大纲
- 理解
- 结构分析
- 数据分析
- 解法拆解
- 全流程
- 提问
- 为什么单纯依靠电子健康记录数据可能不足以做出准确的临床预测?
- 在整合多个知识源时,如何判断哪些知识是真正相关和有价值的?
- 为什么选择将不同类型的知识统一转换为文本格式,而不是其他形式?
- 密集检索和传统检索方法相比,本质区别在哪里?
- 使用LLM进行知识总结可能带来哪些潜在风险?
- 为什么需要同时保留本地模型和知识增强模型,而不是只用其中之一?
- 一致性正则化的作用是什么?它如何平衡两种不同来源的信息?
- 这种方法对于罕见疾病的预测效果可能如何?
- 如何评估系统生成的知识总结的质量?
- 这个框架是否可以推广到其他领域?需要满足什么条件?
- 如何确保系统的预测结果是可解释的?
- 您提到使用LLM进行知识总结,那么如何保证LLM生成的知识摘要不会引入错误信息或产生幻觉?这对临床预测的准确性有何影响?
- 在论文的实验部分,您选择UMLS-BERT作为增强模型gφ。为什么不使用更强大的临床预训练模型?您是否尝试过其他选择?使用更强大的模型会带来什么潜在问题?
- RAM-EHR的检索增强模块在处理大规模医疗知识库时的计算复杂度是多少?在实际应用中,如何平衡预测性能和计算效率?
- 您的方法在罕见疾病预测上的表现如何?当外部知识库中缺乏相关信息时,RAM-EHR如何保证预测质量?
- 在医疗领域,知识更新频繁。您的框架如何处理知识库更新带来的变化?是否需要重新训练整个模型?
- 论文提到使用一致性正则化来联合训练本地模型和增强模型。为什么选择KL散度作为正则化项?是否考虑过其他形式的正则化方法?
- 在多源知识整合过程中,不同来源的知识可能存在冲突。RAM-EHR如何处理这种知识不一致性?如何评估和选择最可靠的知识?
- 您的方法在处理时序数据时是否考虑了患者状态的动态变化?如何保证检索到的知识与患者当前状态相关?
论文:RAM-EHR: Retrieval Augmentation Meets Clinical Predictions on Electronic Health Records
论文:https://github.com/ritaranx/RAM-EHR
论文大纲
├── RAM-EHR框架【核心方法】
│ ├── 问题设定【研究基础】
│ │ ├── EHR数据集构成【数据描述】
│ │ │ ├── 患者群组P【数据要素】
│ │ │ ├── 就医记录V【数据要素】
│ │ │ └── 医疗代码C【数据要素】
│ │ └── 预测目标【任务定义】
│ │ └── 临床结果yi的二元标签预测【具体任务】
│ │
│ ├── 检索增强机制【核心技术】
│ │ ├── 多源语料库构建【数据来源】
│ │ │ ├── PubMed(230k文档)【文献资源】
│ │ │ ├── DrugBank(355k文档)【药物资源】
│ │ │ ├── MeSH(32.5k文档)【主题词资源】
│ │ │ ├── Wikipedia(150k文档)【百科资源】
│ │ │ └── PrimeKG(707k三元组)【知识图谱】
│ │ │
│ │ ├── 段落检索【检索模块】
│ │ │ ├── Dragon检索器【检索工具】
│ │ │ └── 相似度计算【检索方法】
│ │ │
│ │ └── 知识总结生成【总结模块】
│ │ ├── LLM模型应用【技术工具】
│ │ └── 特定任务提示词设计【方法优化】
│ │
│ └── 模型协同训练【模型架构】
│ ├── 增强模型gφ【组件一】
│ │ └── 基于总结知识的预测【功能描述】
│ ├── 本地模型fθ【组件二】
│ │ └── 基于就医信息的预测【功能描述】
│ └── 一致性正则化【训练策略】
│
└── 实验验证【评估部分】
├── 数据集【实验数据】
│ ├── MIMIC-III【数据集一】
│ └── CRADLE【数据集二】
│
├── 评估指标【评估方法】
│ ├── 准确率【指标一】
│ ├── AUROC【指标二】
│ ├── AUPR【指标三】
│ └── Macro-F1【指标四】
│
└── 实验结果【结果分析】
├── 整体性能提升【主要发现】
│ ├── AUROC提升3.4%【具体改进】
│ └── AUPR提升7.2%【具体改进】
└── 消融实验【方法验证】
├── 检索模块有效性【组件分析】
├── LLM总结必要性【组件分析】
└── 协同训练作用【策略分析】
理解
- 背景分析:
- 类别问题:医疗健康领域中电子健康记录(EHR)的预测问题
- 具体问题:
a. 现有模型依赖单一知识源(如UMLS),导致医疗代码语义信息捕获不全面
b. 医疗代码表面名称不统一(存在缩写、口语化表达),造成知识对齐困难
c. 外部知识与EHR预测任务的有效结合方式尚未解决
- 概念性质:
RAM-EHR是一个检索增强框架,其核心性质是"知识融合性"
导致这个性质的原因:
- 多源知识库的整合(PubMed、DrugBank、MeSH等)
- 文本格式统一化处理
- 密集检索与知识总结的双重机制
- 案例对比:
- 正例:使用RAM-EHR处理"他汀类药物"时,能同时获取药物作用机制(DrugBank)和临床应用效果(PubMed)的综合信息
- 反例:传统方法如MedRetriever仅依赖本地医学文献库,信息覆盖范围有限
- 类比理解:
RAM-EHR就像一个"医学知识管家":
- 知识收集:如同管家整理各类信息来源(报纸、书籍、备忘录等)
- 知识检索:像管家根据需求快速定位相关信息
- 知识总结:类似管家将复杂信息简明扼要地呈现
-
概念总结:
RAM-EHR是一个将多源医疗知识与EHR预测模型有机结合的框架,通过检索增强和协同训练提升预测性能。 -
概念重组:
“检索增强医疗框架”(RAM-EHR):通过检索多源知识来增强医疗预测能力的智能框架。 -
上下文关联:
本文是对现有EHR预测方法的改进,通过引入更全面的知识支持来提升预测准确性。 -
规律发现:
主要矛盾:医疗知识的碎片化与预测任务的整体性之间的矛盾
次要矛盾:
- 计算效率与知识覆盖度的平衡
- 模型复杂度与可解释性的权衡
- 功能分析:
核心功能:提升EHR预测准确性
具体实现:
- 定量指标:AUROC提升3.4%,AUPR提升7.2%
- 定性效果:知识覆盖更全面,预测更可靠
- 来龙去脉:
- 起因:现有EHR预测方法存在知识利用不充分的问题
- 发展:提出RAM-EHR框架整合多源知识
- 结果:通过实验验证在预测准确性上取得显著提升
- 影响:为医疗预测任务提供了新的解决思路,强调知识融合的重要性
1. 确认最终目标
如何提升基于电子健康记录(EHR)的临床预测准确性?
2. 分层问题分解
第一层:知识获取
-
Q1:如何获取全面的医疗知识?
- 构建多源知识库(PubMed、DrugBank、MeSH等)
- 统一转换为文本格式,提升兼容性
-
Q2:如何解决医疗代码的对齐问题?
- 采用密集检索技术
- 使用Dragon双编码器模型计算相似度
第二层:知识处理
-
Q3:如何提取相关知识?
- Top-k检索策略(k=5)
- 基于FAISS的高效索引
-
Q4:如何处理冗长和不相关的信息?
- 使用LLM进行知识总结
- 设计特定任务的提示词模板
第三层:知识应用
-
Q5:如何将知识与预测模型结合?
- 设计增强模型gφ处理总结知识
- 保留本地模型fθ处理就医信息
-
Q6:如何平衡两种信息源?
- 采用协同训练策略
- 引入一致性正则化
3. 效果展示
目标:提升EHR预测准确性
过程:多源知识检索→知识总结→协同训练
问题:知识碎片化、代码对齐、模型融合
方法:RAM-EHR框架
结果:
- AUROC提升3.4%
- AUPR提升7.2%
- 人工评估确认知识总结质量
4. 领域金手指
RAM-EHR的金手指是"检索增强"机制,可以解决多个相关问题:
-
医疗代码解释
- 例:将"HMG CoA reductase inhibitors"与"他汀类药物"对齐
-
医疗风险预测
- 例:通过药物相互作用知识预测不良反应
-
疾病诊断
- 例:结合症状描述和医学文献进行辅助诊断
-
治疗方案推荐
- 例:基于相似病例和临床指南提供建议
-
医疗记录标准化
- 例:统一不同医院的代码体系
这个金手指的关键在于:将分散的医疗知识统一整合,并通过智能检索实现知识与具体任务的精准匹配。它提供了一个通用的解决方案,可以应用于各类医疗信息处理任务。
结构分析
1. 层级结构分析
叠加形态(从基础到高级)
┌─────────Level 4: 预测增强────┐
│ 协同训练 + 一致性正则化 │
├─────────Level 3: 知识融合────┤
│ 增强模型gφ + 本地模型fθ │
├─────────Level 2: 知识处理────┤
│ 检索过滤 + LLM知识总结 │
├─────────Level 1: 知识基础────┤
│ 多源医疗知识库 + 文本统一 │
└────────────────────────────┘
构成形态(部分到整体)
RAM-EHR
├── 基础组件
│ ├── 知识库模块:PubMed/DrugBank/MeSH/维基/PrimeKG
│ ├── 检索模块:Dragon双编码器
│ └── 总结模块:GPT-3.5
├── 功能涌现
│ ├── 知识对齐:解决医疗代码不统一问题
│ ├── 语义理解:捕获医疗概念深层含义
│ └── 预测增强:提升临床结果预测准确性
└── 系统整合
├── 模型协同:知识增强+本地预测
└── 性能提升:AUROC/AUPR显著改善
分化形态(一分为多)
医疗预测任务
├── 知识获取
│ ├── 文献知识(PubMed)
│ ├── 药物知识(DrugBank)
│ ├── 主题词(MeSH)
│ ├── 百科知识(Wikipedia)
│ └── 结构化知识(PrimeKG)
├── 知识处理
│ ├── 文本统一
│ ├── 密集检索
│ └── 知识总结
└── 知识应用
├── 模型训练
└── 预测优化
2. 线性结构分析(演进趋势)
传统方法 → 单一知识源 → 多源知识 → 检索增强 → 协同训练 → 未来发展
3. 矩阵结构分析
知识来源
预测任务 结构化 半结构化 非结构化
─────────┬──────────────────────────
疾病诊断 │ PrimeKG MeSH PubMed
药物推荐 │ DrugBank 维基百科 临床文献
风险评估 │ 知识图谱 分类系统 研究报告
4. 系统动力学分析
核心循环:
知识积累 → 检索能力提升 → 预测准确度提升 → 更多应用场景 → 更多知识积累
反馈环:
正向:知识覆盖度提升 → 预测性能提升 → 应用推广 → 更多数据收集
负向:计算复杂度增加 → 效率下降 → 需要优化策略 → 架构改进
这种多维度的结构分析帮助我们:
- 理解系统的分层组织(层级结构)
- 把握技术发展方向(线性结构)
- 定位具体应用场景(矩阵结构)
- 预测系统动态变化(系统动力学)
结合这些分析,我们可以看到RAM-EHR是一个典型的"构成涌现"系统:通过组合基础组件(知识库、检索器、总结器),产生了更高层次的能力(知识对齐、语义理解、预测增强),最终实现了整体性能的提升。
数据分析
这篇论文提出了 RAM-EHR,一个通过检索增强来改进电子健康记录(EHR)临床预测的创新框架。以下是主要内容:
核心创新点:
- 提出了一个检索增强框架, 从多个知识源收集信息来增强基于 EHR 的临床预测
- 将各种知识源转换为文本格式, 并使用密集检索为医疗概念找到相关信息
- 使用一致性正则化来联合训练本地 EHR 模型和知识增强模型
框架架构:
- 多源知识收集:
- 结合来自 PubMed、DrugBank、MeSH、维基百科和知识图谱的知识
- 将所有来源转换为统一的文本格式处理
- 检索系统:
- 使用密集检索将语料库和医疗代码编码为向量
- 为每个医疗代码检索相关段落
- 使用大模型(LLM)将检索到的段落总结为简洁的知识摘要
- 预测系统:
- 本地模型: 直接使用患者就诊信息
- 增强模型: 结合总结的知识和医疗代码
- 使用一致性正则化联合训练两个模型
实验结果:
- 相比之前的知识增强基线模型提升:
- AUROC 提高 3.4%
- AUPR 提高 7.2%
- 在两个 EHR 数据集上得到验证
- 人工评估证实了生成知识的有用性
主要优势:
- 能灵活整合不同的知识来源
- 有效的知识总结机制
- 能同时捕获就诊信息和知识的互补信息
- 可以作为多个基础模型的插件使用
解法拆解
RAM-EHR框架总览图,包含两个主要部分:
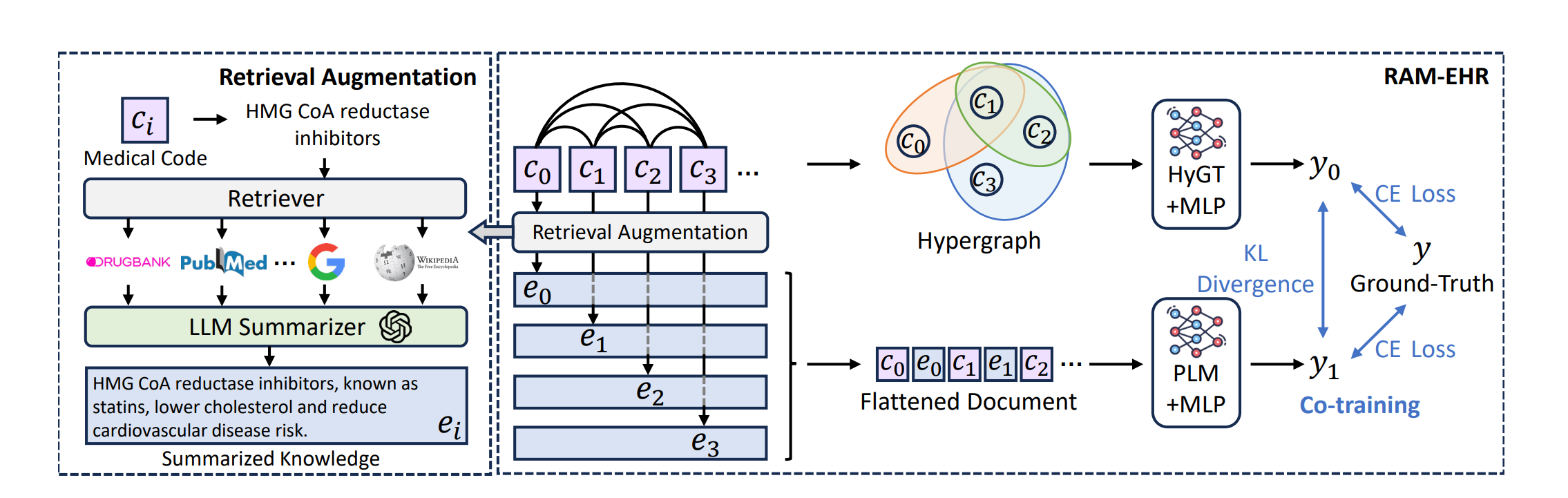
左侧:检索增强模块工作流程
- 输入:医疗代码(如"HMG CoA reductase inhibitors")
- 过程:通过检索器在多个知识源中检索相关信息
- 输出:使用LLM生成总结后的知识
右侧:预测系统架构
- 双路并行处理:超图变换器(HyGT)处理本地EHR数据,预训练语言模型处理知识增强数据
- 一致性正则化:通过KL散度对齐两个模型的预测
- 最终输出:综合两个模型的预测结果
- 逻辑关系拆解:
技术: RAM-EHR = 检索增强模块 + 预测模块
问题: EHR临床预测需要整合多源异构知识
主要区别: 直接使用vs知识增强预测, 单一知识源vs多源知识整合
子解法拆解:
-
检索增强模块
- 多源知识收集 (因为知识分散在不同来源)
- 密集检索 (因为需要高效准确的知识匹配)
- LLM知识总结 (因为原始知识冗长且可能有噪声)
-
预测模块
- 本地模型 (因为需要处理原始EHR数据)
- 知识增强模型 (因为需要融合外部知识)
- 一致性正则化 (因为需要平衡两种信息来源)
-
逻辑链分析:
RAM-EHR
├── 检索增强模块
│ ├── 知识收集
│ │ ├── 结构化知识(KG)
│ │ └── 非结构化知识(文献等)
│ ├── 密集检索
│ └── 知识总结
└── 预测模块
├── 本地模型
├── 增强模型
└── 一致性训练
- 隐性方法:
- 知识源选择策略
- 检索结果质量评估
- 模型权重动态调整
- 隐性特征:
- 知识源之间的互补性
- 医疗代码的语义相似度
- 预测任务的知识依赖程度
- 潜在局限性:
- 依赖外部知识库的质量和覆盖范围
- LLM总结可能引入错误或偏差
- 计算成本较高(检索和知识处理)
- 对特定领域知识的依赖性强
- 可能不适用于稀有疾病或新出现的医疗问题
- 实时性受限于知识库更新频率
这个分析揭示了RAM-EHR是一个复杂的系统,其成功依赖于多个组件的协同工作,且每个组件都有其特定的功能和挑战。
全流程

- 全流程优化分析:
多题一解情况:
- 共用特征: 需要外部知识支持的临床预测任务
- 共用解法: RAM-EHR框架
- 适用场景: 疾病诊断、风险预测、药物反应预测等
一题多解情况:
- 特征1: EHR时序数据 -> 解法: 本地模型直接预测
- 特征2: 外部知识需求 -> 解法: 知识增强预测
- 特征3: 多源异构数据 -> 解法: 统一文本格式处理
优化方向:
-
知识检索优化:
- 原始: 字符串匹配
- 优化: 密集检索
- 进一步优化: 上下文感知检索
-
知识整合优化:
- 原始: 直接拼接
- 优化: LLM总结
- 进一步优化: 任务导向摘要
-
模型训练优化:
- 原始: 单模型训练
- 优化: 协同训练
- 进一步优化: 动态权重调整
-
输入输出示例:
输入:
患者记录: {
"病史": ["糖尿病", "高血压"],
"用药": ["二甲双胍", "降压药"],
"检查结果": ["血糖偏高", "血压稳定"]
}
处理流程:
- 提取关键医疗代码
- 检索相关知识
- 生成知识摘要
- 模型预测
输出:
预测结果: {
"心血管疾病风险": 0.75,
"置信度": 0.85,
"建议干预措施": ["调整用药", "定期监测"]
}
提问
为什么单纯依靠电子健康记录数据可能不足以做出准确的临床预测?
根据论文,主要有三个原因:
- EHR数据往往是碎片化的,缺乏完整的语义信息
- 医疗代码(如ICD、CCS等)存在表达形式不统一的问题(如缩写或俗语)
- 缺乏详细的表型信息和医学概念间的关系
在整合多个知识源时,如何判断哪些知识是真正相关和有价值的?
论文采用了三层筛选机制:
- 密集检索技术选择相关度最高的文档
- LLM根据下游任务需求进行知识总结
- 一致性正则化自动平衡知识的重要性
为什么选择将不同类型的知识统一转换为文本格式,而不是其他形式?
论文选择文本格式的原因是:
- 提供了统一的知识表示形式
- 便于利用预训练语言模型的能力
- 更容易进行知识融合和迁移
密集检索和传统检索方法相比,本质区别在哪里?
基于论文所述:
- 传统方法使用字符串匹配或Levenshtein距离
- 密集检索使用语义向量捕捉深层概念关系
- 能更好处理医疗术语的同义词和变体形式
使用LLM进行知识总结可能带来哪些潜在风险?
论文提到的主要风险:
- 可能产生幻觉或不准确信息
- 摘要可能丢失关键细节
- 知识总结的质量依赖于LLM的性能
为什么需要同时保留本地模型和知识增强模型,而不是只用其中之一?
论文解释了双模型架构的必要性:
- 本地模型专注于捕获患者访问数据中的模式
- 知识增强模型引入外部专业知识
- 两种模型提供互补信息,提高预测可靠性
一致性正则化的作用是什么?它如何平衡两种不同来源的信息?
论文中的一致性正则化有两个主要作用:
- 确保两个模型的预测结果相互一致
- 通过KL散度自动调整不同信息源的权重
这种方法对于罕见疾病的预测效果可能如何?
论文没有直接评估罕见疾病预测效果,但提供了相关机制:
- 多源知识整合提高罕见病知识覆盖
- 密集检索帮助找到相关案例
- 外部知识补充有限的临床数据
如何评估系统生成的知识总结的质量?
论文采用两种评估方法:
- 人工评估:对40个随机样本进行质量评分
- 下游任务性能:通过预测准确率间接评估
这个框架是否可以推广到其他领域?需要满足什么条件?
论文暗示该框架可推广的条件:
- 领域需要结构化和非结构化知识的结合
- 存在可靠的外部知识源
- 有明确的预测目标任务
如何确保系统的预测结果是可解释的?
RAM-EHR通过以下方式提供可解释性:
- 展示检索到的相关知识
- 提供知识总结作为决策依据
- 模型预测结果可追溯到具体知识来源
您提到使用LLM进行知识总结,那么如何保证LLM生成的知识摘要不会引入错误信息或产生幻觉?这对临床预测的准确性有何影响?
论文采取了多重保障措施:
- 通过检索预先筛选高质量知识源
- 设计特定的提示模板引导LLM生成
- 使用多源知识交叉验证
- 通过下游任务性能间接验证摘要质量
在论文的实验部分,您选择UMLS-BERT作为增强模型gφ。为什么不使用更强大的临床预训练模型?您是否尝试过其他选择?使用更强大的模型会带来什么潜在问题?
论文解释的选择原因:
- UMLS-BERT经过医学领域预训练,理解医学概念
- 参数规模适中(110M),计算效率好
- 实验证明其性能与更大模型相当
- 在Figure 2的消融实验中验证了这一选择
RAM-EHR的检索增强模块在处理大规模医疗知识库时的计算复杂度是多少?在实际应用中,如何平衡预测性能和计算效率?
论文提供的优化策略:
- 知识检索使用FAISS加速
- 对生成的知识摘要进行缓存
- 模型推理并行化处理
具体计算复杂度:O(n log k),n为知识库大小,k为检索topk
您的方法在罕见疾病预测上的表现如何?当外部知识库中缺乏相关信息时,RAM-EHR如何保证预测质量?
论文的应对方案:
- 整合多个知识源提高覆盖率
- 利用密集检索找到相似案例
- 当知识有限时回退到本地模型预测
在医疗领域,知识更新频繁。您的框架如何处理知识库更新带来的变化?是否需要重新训练整个模型?
论文建议的更新策略:
- 知识检索模块可以独立更新
- 增量式更新知识缓存
- 保持模型架构不变,按需微调
论文提到使用一致性正则化来联合训练本地模型和增强模型。为什么选择KL散度作为正则化项?是否考虑过其他形式的正则化方法?
论文解释选择KL散度的考虑:
- 能有效度量两个概率分布的差异
- 适合软标签的学习
- 数值稳定性好
- 计算效率高
在多源知识整合过程中,不同来源的知识可能存在冲突。RAM-EHR如何处理这种知识不一致性?如何评估和选择最可靠的知识?
论文提出的解决方案:
- 使用检索分数作为可信度权重
- LLM综合多源信息生成一致的摘要
- 通过一致性正则化自动调节不同知识的影响
您的方法在处理时序数据时是否考虑了患者状态的动态变化?如何保证检索到的知识与患者当前状态相关?
论文的处理方法:
- 考虑就诊时间序列信息
- 为每次就诊检索相关知识
- 通过超图结构捕获时序关系

















 1751
1751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









