







1.1 概述
屏幕空间环境光遮蔽(SSAO)已经成为实时渲染中产生小范围环境光和接触阴影效果的事实标准。随着GPU市场热设计功率(TDP)范围的不断扩展,以及虚拟现实(VR)实时渲染的性能缩放需求,本文提出了一个框架,以可扩展的方式实现SSAO,旨在为更广泛的硬件和使用场景提供统一的实现。
1.2 问题陈述
现代PC和游戏主机中广泛采用SSAO算法、高质量阴影贴图和全局光照,往往会完全替代成本较低的解决方案,如光照贴图或各种阴影近似效果(例如动态物体下的 blob 阴影),但没有为低端硬件提供合适的替代方案。这是可以理解的,因为设计、确保一致性并维护多条完全独立的代码和艺术路径,以提供不同质量/性能水平的效果,既困难又昂贵。然而,常见的结果是,现代游戏中的低质量预设通常不包含以前在类似性能的图形硬件上标准的某些效果。
在本章节发布时,最常用的全分辨率SSAO技术只在大约30W TDP及以上的GPU上适用,这实际上排除了轻薄型笔记本电脑,以及许多在推荐或甚至最低规格下的VR场景。
使用低于全分辨率的SSAO(例如半×全或半×半)来覆盖最低端质量预设通常是唯一选择,但这种方法受限于质量问题,如别名伪影,这些问题需要单独处理。
自适应SSAO旨在提供在不同质量级别下的全分辨率AO效果,适用于TDP为15W的集成显卡到150W及以上的独立GPU,以及90Hz的VR渲染。渐进采样核足够灵活,允许在缩放范围内微调质量/性能的权衡。
1.3 ASSAO——高级概述
自适应屏幕空间环境光遮蔽(ASSAO)是标准SSAO的实现,经过调优以实现可扩展性和灵活性,能够在质量与性能之间进行权衡,因此适用于更广泛的硬件和使用场景,具有统一的设置和视觉一致性。AO实现基于类似于基于地平线的环境光遮蔽(Bavoil et al,2008)的固角度遮蔽模型,采用自定义新颖的采样核圆盘。性能和可扩展性优化基于可扩展环境遮蔽的深度缓冲区MIP映射预滤波(McGuire et al,2012),以及类似于Bavoil(2014)方法的2×2缓存友好的解交错处理版本。此外,渐进采样核允许轻松调节单个预设的性能,并为最高级实现提供可选的逐像素动态重要性采样方法。我们方法的主要过程(如图1.6所示)包括:
-
准备深度
- 将输入的深度缓冲区转换为线性空间,并进行2×2解交错,形成四个半×半视空间。
- 为所有四个半×半深度纹理创建MIP。
-
生成AO和边缘并应用智能模糊;对于每个四个半×半解交错片段循环四次。
- 使用前一步生成的当前深度片段和输入法线生成并输出AO和边缘到R8G8半×半纹理中。
- 应用边缘感知智能模糊。
-
将前一步的四个输出进行解交错,并在全分辨率输出渲染目标上应用最终的智能模糊。
低预设将跳过深度MIP和边缘生成,而最高/自适应预设则具有额外的基本AO过程以及第1.7节中详细介绍的其他更改。当输入法线不可用时(例如对于前向渲染器),将在第1步中从输入深度重建一个全分辨率法线缓冲区,并在第2步中使用它。有关性能数值的简要概览,请参考表1.8。

1.4 SSAO——快速复习
环境光遮蔽是用于在某些条件下生成小范围阴影的计算模型,主要(但不限于)用于环境光照。屏幕空间指的是仅使用深度和(可选)法线缓冲区作为输入进行计算。这意味着它是一个后处理过程,对渲染视锥外的场景以及透明或被遮挡的几何体一无所知,这是其基本的弱点。
然而,在许多场景中,SSAO已成为对全局光照的足够好近似,可以在当今的主机和PC硬件上实时实现,因此被广泛使用。它是增加视觉保真度并为虚拟世界场景增加深度的有效方式,通过近似墙壁缝隙、皮肤皱纹、物体与其他物体或表面接触时的阴影等。即使存在局限性,它仍然是实时渲染工具箱中的一个有效且重要的工具(图1.1)。
最近,它还与更先进的实时全局光照技术一起使用,这些技术通常由于性能限制而以显著较低的空间分辨率计算。在这种情况下,SSAO可以为较小尺度的场景细节提供额外的高频AO。它还经常被扩展,以提供更好的光照近似(例如SSDO [Ritschel et al,2009])或导出额外的光照信息以用于光照管线(例如,bent normal [Klehm et al,2011])。
尽管环境光遮蔽的概念已经存在了很长时间,但直到2007年左右才在实时应用中得到使用,最早的商业实现出现在《孤岛危机》游戏中(Mittring 2007),随后被其他游戏开发者采纳。自那时以来,它一直是一个活跃的研究领域,当前的尖端解决方案,如HBAO+,已经出现在许多PC和游戏主机游戏中。
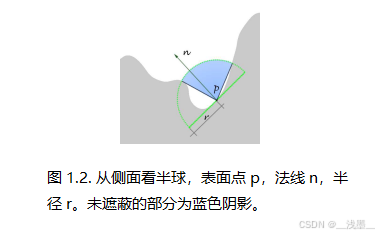
从最简单的角度来看,给定表面点的环境光遮蔽可以定义为在由表面法线定义的半球内的可见性函数的积分(图1.2)。在实际应用中,由于性能原因,可见性只进行近似计算,并在用户定义的距离(半径)内进行。屏幕空间实现中,输入数据(深度缓冲区和可选法线贴图)提供了用于评估遮蔽积分的场景近似。大多数游戏中使用的AO方法依赖于逐像素遮蔽近似,使用多点深度缓冲采样和处理核,尽管也有其他实现,如[Bunnell 2005](依赖于圆盘代理)或[Luft et al,2006](依赖于深度缓冲锐化掩模滤波器)。
在逐像素遮蔽近似类解决方案中有大量变种,如基于地平线的环境光遮蔽[Bavoil et al,2008]等。有关各种SSAO方法的更详细概述,请参阅 [Aalund 2012]。
1.5 扩展SSAO的可伸缩性
在本章节中,我们将介绍为实现可伸缩性目标而采取的具体步骤。需要特别说明的是,虽然我们的主要关注点是提供一个能够扩展的框架,但我们已经尽量简化了AO逻辑的替换方式(例如,可以在主着色器文件中替换SSAOTap()函数)或扩展为更复杂的效果(如SSDO [Ritschel et al. 2009])。我们将深入探讨围绕AO核心和逐步采样核(用于自适应重要性采样实现)搭建的框架。
1.5.1 朝着可伸缩性能的步骤
预算分配:
SSAO在GPU上的帧预算通常会控制在大约帧时间的10%以内(30FPS时为3.3ms,60FPS时为1.6ms)[Kaplanyan 2010, Donzallaz and Sousa 2011, McGuire et 2011]。因此,在VR场景下,90Hz的预算应保持在1ms以内。
SSAO算法曾在Playstation 3和Xbox 360级别的硬件上使用,虽然为了保持预算,它们通常是在1280×720分辨率下以半分辨率(例如640×720)进行计算。这个趋势也出现在PC游戏中,如《战地:叛逆连队2》和《战地3》等。然而,这种简化的低分辨率方法会导致明显的锯齿和时间性伪影(例如闪烁现象),因此需要进一步处理。现在,优化过的全分辨率方法(如HBAO+)在许多现代游戏中被广泛采用。
我们也专注于全分辨率的方法,但目标是显著扩展可伸缩范围。
起点—简化的参考算法:
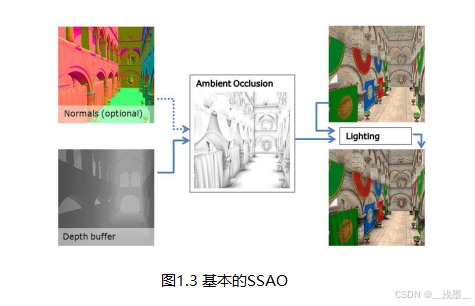
为了更好地理解性能瓶颈,我们从基本的SSAO实现开始(见图1.3),它使用一个全分辨率的单通道像素着色器,输入深度和法线,并输出环境光遮蔽(AO)项。它可以提供最终质量,但代价非常高,因此它更适合作为参考和性能优化的起点。
在这种实现方式下,单个像素着色器有少量固定的(不可伸缩的)设置执行成本(如加载中心深度和法线、计算半径和采样模式旋转等),但主要的工作是遍历深度样本并计算遮蔽效果。采样次数越多(即采样和AO的计算次数),质量和执行成本也会相应增加(见表1.1和图1.4)。
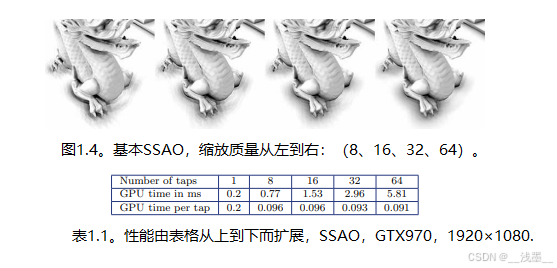
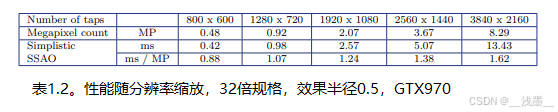
这种方法的优势在于它能方便地通过提供的性能来增加质量:执行成本随着采样次数的增加而线性增长(尽管视觉质量的提升并非线性)。但是,在此阶段还有两个其他变量显著影响性能:分辨率和深度采样核在屏幕上的大小。通过测试增加分辨率的影响,我们发现每像素成本几乎增加了2倍(见表1.2)。
非线性增长的原因是深度纹理采样缓存效率的丧失。通过修改算法来从源纹理的小子集进行采样(例如,将纹理坐标乘以一个小值,如0.01),我们可以发现执行成本与像素数线性相关。
另一个由于纹理采样缓存效率低下的影响是,调整效果半径(这也会改变采样核的大小)会使成本增加3倍(见表1.3)。
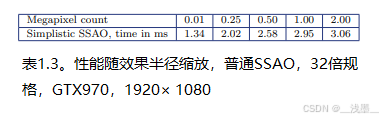
成本增加的原因相同:随着采样核的增大,样本之间的空间关联性变差,导致纹理缓存效率降低。由于采样核的大小依赖于半径设置和视距深度,这意味着执行成本也会根据场景内容和相机位置的不同而显著变化。
这暴露了简化算法版本的内在低效,并指向了第一个可伸缩性障碍——更好地利用纹理缓存层次结构。过去,已经使用了两种不同的方法来缓解这个问题,与其他SSAO技术不同,ASSAO依赖于同时使用这两种方法。
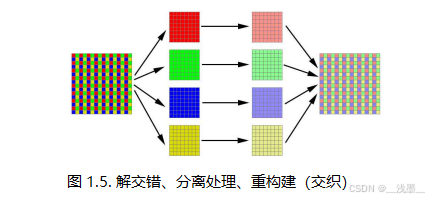
解交错处理:
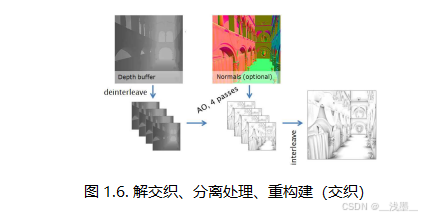
解交错渲染最早由[Keller and Heidrich 2001]提出,并在[Bavoil and Jansen 2013]等人中用于SSAO。实际上(见图1.5),我们将深度采样模式分成四个独立的模式,每个模式限定在2×2子网格中的一个像素内。这样,我们可以将深度缓冲区分割成四个四分之一大小的缓冲区,并独立地为每个缓冲区计算AO项,从而将每通道内存占用减少到原来的四分之一。然后,在最后将结果合并(见图1.6)。
通过将简化的SSAO升级到一个简单的2×2解交错方法,性能得到了显著提高,见表1.4。
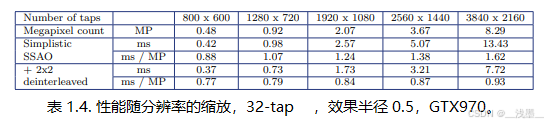
采用2×2解交错后,我们发现,像素间的执行时间差异从较低分辨率和最高分辨率之间的85%增幅,降到21%。为了完全消除剩下的21%效率损失,我们尝试使用4×4解交错方法;虽然它完全消除了缓存一致性瓶颈,但我们发现4×4方法也带来了一些不期望的副作用:
- 在2×2版本中,深度缓冲区的解交错增加了固定成本,但这一成本通过将深度值转换为视空间的过程得以摊销,这一步骤在主AO通道中仍然需要使用。而在4×4版本中,这部分成本并没有完全摊销,因此增加了固定开销,降低了低端扩展范围内的整体性能(例如低/中质量预设,AO采样较少时)。
- 重建(交错)对4×4版本而言更加复杂,进一步增加了固定成本,减少了低端的伸缩性。
- 4×4方法在使用不同的随机采样核时不够灵活,限制了质量扩展方面的灵活性。
- 4×4方法不适合在解交错缓冲区上执行高质量的边缘感知智能模糊,这迫使我们先进行交错,再在全分辨率上进行模糊处理。而在2×2版本中,我们可以直接在解交错的切片上执行更快、更适合缓存的智能模糊。
因此,我们选择了2×2解交错方法,但同时添加了另一种解决方案,以实现最佳的缓存效率。
深度MIP纹理:
[McGuire et al, 2012]提出的另一种方法是扩展缓存效率。其思路是将深度缓冲区预先过滤为MIP级别,并在采样时使用MIP映射。
float closestD = min( min( depths.x, depths.y ),min( depths.z, depths.w ) );
float4 weights = saturate( (depths - closestD.xxxx) * weightCalcMul.xxxx + weightCalcAdd.xxxx );
float smartAvg = dot( weights, depths ) / dot( weights, float4( 1.0, 1.0, 1.0, 1.0 ) );
//清单1.1 加权平均深度滤波器
我们首先将深度缓冲区解交错成四个部分,然后为每个解交错后的深度缓冲区切片创建MIP级别。在生成MIP级别时,我们使用基于半径的加权平均方法来下采样深度,这种方法通过有效计算半径内最接近样本的算术均值,得到了主观上看起来更好的效果,并且比旋转网格子采样等其他方法更具时间稳定性(如[McGuire et al, 2012]中所述)。我们使用的半径与AO效果的半径相同(见代码清单1.1)。
代码中的变量depths是一个包含四个深度输入的float4,weightCalcMul和weightCalcAdd是预先计算的常量,用于根据效果半径计算线性[0, 1]的权重(该权重也用于AO样本加权)。smartAvg是最终的输出。
计算每个采样点的深度纹理采样MIP级别
为了计算每个采样点的深度纹理MIP级别,我们使用以下公式:
![]()
其中:
ps是内核的屏幕大小,以像素为单位,在AO着色器中以每像素频率计算。sk是每个采样点相对于内核中心的偏移量,存储在采样核数组中。它是离线计算的:log2(sampleLength) + random(-0.4, +0.4),并存储在样本坐标数组中,在AO着色器中按样本加载。gk是全局偏移常量,在质量和性能之间找到最佳的权衡值。

常量gk对应于[McGuire et al,2012]中的常量q0,其中提到:“较低的值会导致相邻像素的多个采样点映射到相同的纹理元素,从而使样本方差增大,并表现为时间闪烁现象。较高的值会降低性能,因为工作区域无法完全适配到缓存中。”
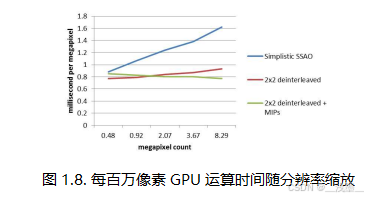
这种时间闪烁和正确性损失是我们不单独依赖深度MIP方法的主要原因。然而,当与2×2解交错采样结合使用时,我们可以使用显著更高的gk值,避免大部分时间上的伪影,同时仍然保持最佳的缓存效率——从而实现质量和性能的最佳平衡。最终我们可以看到,通过将2×2解交错渲染与深度MIP方法结合使用,我们几乎消除了所有场景中的纹理采样瓶颈(见表1.5和图1.8)。
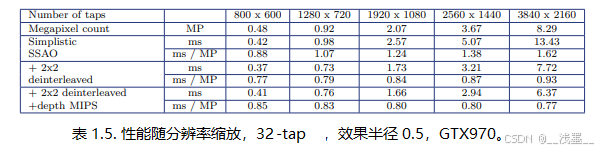
随着AO效果半径的变化,成本保持稳定(见表1.6和图1.9)。
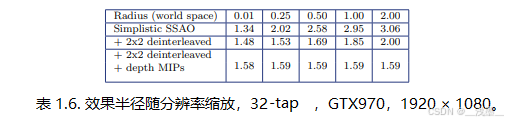
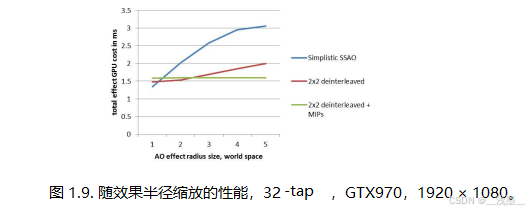
使用深度MIP和2×2解交错渲染的另一个好处是,在某些情况下可以轻松关闭深度MIP,例如,在较低分辨率和低质量预设下,MIP纹理预过滤和采样MIP级别计算的固定开销高于通过更优化的缓存访问节省的性能。这有助于在不同的硬件、分辨率和质量预设之间提供最佳性能。
随机采样和智能模糊
为了在合理性能下获得良质量的SSAO效果,需要使用随机渲染方法。这种方法允许将AO项在相邻像素之间共享,牺牲一些高频细节。我们使用带有缩放变换的采样盘旋转,并应用重建模糊处理以去除结果中的噪声(见图1.10)。

为了防止在重建模糊过程中,效果在空间上分离的表面之间泄漏,我们使用基于深度的(见清单1.2)以及(可选的)基于法线的边缘检测(HLSL着色器代码见清单1.3)。如果没有这一操作,效果会扩散到前景/背景物体上,降低清晰度并产生不希望的阴影或光晕(见图1.11)。

// inputs are neighboring viewspace z-s from the current 2x2
// deinterleaved slice (cZ, leftZ, rightZ, topZ, bottomZ)
{
// delta from center Z
float4 edges = float4(leftZ, rightZ, topZ, bottomZ) - cZ;
// slope-adjustment
float4 edgesSA = edges.xyzw + edges.yxwz;
edges = min( abs( edges ), abs( edgesSA ) );
// 0 means edge, 1 means no edge (free to blur across)
edgesLRTB = saturate( ( 1.3 - edges / (cZ * 0.04) ) );
}
// 清单1.2。基于深度的边缘检测的着色器代码
边缘(见图1.12)是在2×2解交错切片中,基于相邻值计算的,这意味着在全分辨率深度上有一个2像素的偏移,以便与在每个切片域内进行的智能模糊匹配。虽然这不会导致边缘泄漏,但它在边缘旁留下了一个未模糊的1像素间隙。这个问题在最后的全分辨率重建和模糊处理过程中得到了缓解,该过程也是感知边缘的。

// inputs are neighboring normals s from the current 2x2
// deinterleaved slice (normC, normL, normR, normT, normB)
{
const float t = 0.1; // dot threshold
float4 normEdges;
normEdges.x = saturate( ( dot( normC, normL ) + t ) * 2.0 );
normEdges.y = saturate( ( dot( normC, normR ) + t ) * 2.0 );
normEdges.z = saturate( ( dot( normC, normT ) + t ) * 2.0 );
normEdges.w = saturate( ( dot( normC, normB ) + t ) * 2.0 );
// apply to depth-based edges (0 means edge, 1 means no edge)
edgesLRTB *= normEdges;
};
// 清单1.3。加权平均深度滤波器
需要注意的是,最终的边缘值并不是二进制的,而是位于[0, 1]范围内的。这些分数值用于平滑边缘感知模糊的过渡,避免由于相机或场景物体的移动而产生锐利的过渡和时间伪影。这些边缘值在主AO着色器中计算一次,并以压缩的两位每边缘格式与遮蔽项一起存储。
模糊的锐度可以通过全局设置进行微调,以在减少时间别名和减少AO渗漏/光晕效应之间找到平衡。
实际的智能模糊分两次执行:
- 在多通道着色器中,智能模糊对每个解交错的AO缓冲区独立进行(见着色器代码中的
PSSmartBlur)。 - 最后,在全分辨率重建/应用着色器中进行一次(见着色器代码中的
PSApply)。
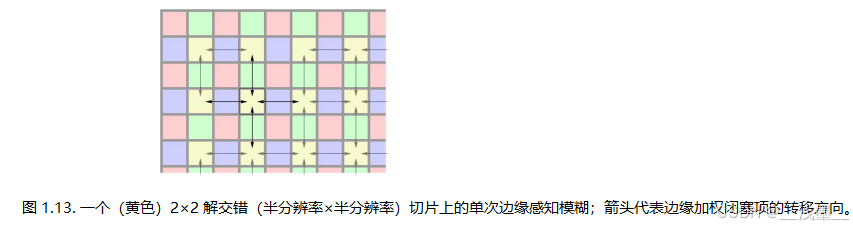
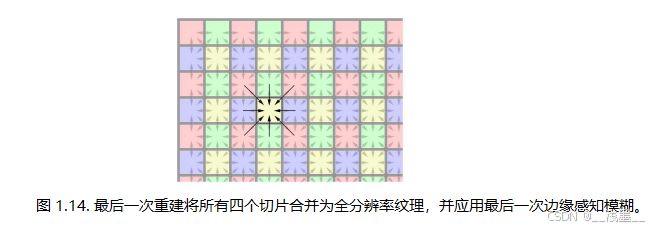
如前所述,边缘检测和边缘感知模糊是独立对四个解交错的AO结果进行的,这在相邻像素的水平和垂直线之间留下了1像素的处理间隙。为了解决这个问题,最后的全分辨率重建通道包括额外的边缘感知模糊,弥补了这个间隙。这也意味着除了最后的模糊处理通道,所有其他模糊处理都得益于在2×2解交错域内工作的更高缓存效率。在这个通道中,实际上每个像素只需要四个纹理样本(使用双线性滤波)(见图1.13)。最终,图1.14展示了一个简化的步骤图,说明了所涉及的步骤。
低质量预设是边缘感知模糊的例外——出于性能原因,不计算边缘,而是使用简单的模糊处理。


1.6 采样核
不同质量预设的最大区别在于每个像素使用的采样次数。在我们展示的版本中,低质量使用6次深度采样,中等质量使用12次,高质量使用24次深度采样。
最初,我们为每个质量预设使用了一个独立的泊松盘,但这会导致不同质量预设之间的视觉差异较大,这与我们提供一致的设置和视觉外观的目标相悖。并且这也意味着算法无法轻松地在不同预设之间调整性能目标。为了克服这一问题,我们开发了一个采样盘,将每个附加样本的影响进行排序,这样每增加一个样本就能提高质量,而不会造成过大的视觉差异(如图1.16所示)。这个渐进式采样盘使得我们能够通过简单地调整每个预设的采样次数来改变质量,同时视觉变化是渐进的。这也为根据每像素的重要性启发式方法动态调整每个像素的采样次数提供了可能性。
1.7 自适应SSAO
使用重要性启发式方法来提高SSAO效果质量的思想最早在[Bavoil and Sainz 2009]中提出,其中通过低分辨率的SSAO过程来确定是否需要进行随后的高分辨率过程。我们并没有采用低分辨率的过程,而是进行了一个标准的全分辨率基础AO过程,使用有限数量的采样,然后基于基础过程中的方差计算重要性图(图1.17),并在需要的地方添加更多的样本。
这种方法增加了显著的固定开销,因此只有在需要超出高预设的质量时才有益。它还增加了基于输入的执行开销波动,我们通过使用自适应限制常量来计算屏幕上额外样本的总数,设定一个上限,从而限制这种波动。最高(自适应)预设中包含的步骤如下(与高预设的差异以斜体表示):

- 深度缓冲区去交错和深度MIP生成
- 使用每像素14个样本的低质量基础AO过程
- 基于先前步骤中相邻像素值之间的方差,计算重要性图
- 对重要性图进行模糊处理,并汇总额外所需的总屏幕样本数(使用InterlockedAdd)
- 自适应质量AO过程,在低质量基础AO结果的基础上,使用最多50个额外样本来扩展,样本数根据重要性图进行调整,且屏幕上总样本数受自适应限制常量的限制
- 智能模糊处理
- 最终的交错和智能模糊
因此,自适应预设会有基于输入的波动,但确保始终低于可在运行时更改的预设限制。为了最小化在每像素AO样本数变化时的时间不稳定性,除了使用渐进式采样盘外,我们还始终渐进地混合最后几个样本。
为了衡量自适应采样方法的有效性,我们将其与使用固定样本数的版本进行比较。在自适应预设中,我们降低自适应限制,直到屏幕上样本总数达到上限——通过这种方式,我们知道自适应版本不会因为输入的变化而变得更昂贵;在性能上,这是自适应方法的最坏情况。使用的输入(Sponza中庭,AO半径为1.2)时,我们在限制值为0.45时达到了上限。
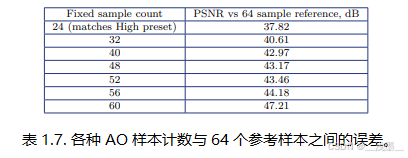
然后,我们测量自适应(0.45限制)和64固定样本AO之间的峰值信噪比,得到了43.53 dB。
为了找到与固定预设相当的样本数,我们在使用相同64样本参考的情况下测量不同样本数下的PSNR。我们发现(表1.7)固定52样本的版本与0.45自适应限制设置的自适应版本在PSNR为43.17时最为接近。
然后,我们在GTX 1080显卡上,使用4K(3840 × 2160)分辨率进行成本测量,固定52样本的AO花费了5.46毫秒,而自适应AO则为5.05毫秒。在这个最坏情况下,自适应方法比固定样本数的版本节省了约8%的成本。如果我们将相机旋转并主要观察墙面(AO较少),我们就得到了大致的最佳情况,自适应方法的成本为3.28毫秒,比固定52样本版本节省了约40%的时间。
因此,我们得出结论:自适应方法对于扩展高预设以上的质量非常有用,特别是在场景的并非所有部分(如天空、水面或平坦表面)预计会产生AO,或者当需要在运行时根据“自适应限制”调整效果开销时。
1.8 将所有内容整合在一起
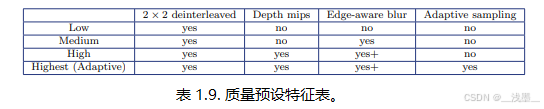
我们的最终实现具有四个质量/性能预设,从低预设开始,禁用了大部分功能,每个后续的级别会在质量上有所增加,但成本也大约增加50%,其中第三个(高)预设的成本大致与HBAO+相当(见表1.8)。
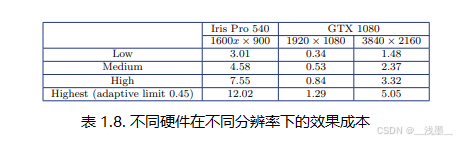
在1920 × 1080分辨率下,使用提供的法线时,视频内存使用为22MB。每个预设可以通过调整着色器中的AO采样次数进一步微调,以满足所需的性能,支持的值范围从3到32。请参见主着色器文件中的g_numSamples变量。
1.9 未来工作
我们计划通过使用自动生成器来优化渐进式采样盘,寻找与最佳参考相比的最小误差。
关于时间超采样,我们目前的实现通过提供容易调整采样盘旋转和缩放的能力,暂时支持时间超采样,但尚未在TAA/TSS环境中进行测试。
目前提供的代码中不支持MSAA,但未来有计划加入该功能。
当前实现支持使用放大的视锥体进行渲染,旨在避免屏幕角落的伪影。我们避免了在提供的裁剪矩形外部进行不必要的计算。
参考文献
Aalund, F. P. 2012. A comparative study of screen-space ambient occlusion methods. Bachelor’s thesis. http://frederikaalund.com/ a-comparative-study-of-screen-space-ambient-occlusion-methods.
Bavoil, L., and Jansen, J. 2013. Particle shadows & cache-efficient postprocessing. In Proceedings of GDC 2013.https://developer.nvidia.com/sites/default/files/akamai/gamedev/docs/BAVOIL ParticleShadowsAndCacheEfficientPost.pdf,.
Bavoil, L., and Sainz, M. 2009. Multi-layer dual-resolution screen-space ambient occlusion. In SIGGRAPH 2009: Talks, ACM, New York, SIGGRAPH ’09, 45:1–45:1.
Bavoil, L., Sainz, M., and Dimitrov, R. 2008. Image-space horizon-based ambient occlusion. In ACM SIGGRAPH 2008 Talks, ACM, New York, SIGGRAPH ’08, 22:1– 22:1.
Bavoil, L., 2014. Deinterleaved texturing for cache-efficient interleaved sampling. https://developer.nvidia.com/sites/default/files/akamai/gameworks/samples/ DeinterleavedTexturing.pdf.
Bunnell, M. 2005. Dynamic ambient occlusion and indirect lighting. In GPU Gems 2, M. Pharr, Ed. Addison-Wesley, 223–233.
Donzallaz, P., and Sousa, T., 2011. Lighting in crysis. http://www.gdcvault.com/ play/1014915/Lighting-in-Crysis.
Kaplanyan, A., 2010. CryENGINE 3: Reaching the speed of light. http://www. crytek.com/cryengine/presentations/CryENGINE3-reaching-the-speed-of-light. Crytek
Keller, A., and Heidrich, W. 2001. Interleaved sampling. In Proceedings of the 12th Eurographics Workshop on Rendering Techniques, Springer-Verlag, London, 269–276.
Klehm, O., Ritschel, T., Eisemann, E., and Seidel, H.-P. 2011. Bent Normals and Cones in Screen-space. In Vision, Modeling, and Visualization (2011), The Eurographics Association, Aire-la-Ville, Switzerland, P. Eisert, J. Hornegger, and K. Polthier, Eds., 177–182.
Luft, T., Colditz, C., and Deussen, O. 2006. Image enhancement by unsharp masking the depth buffer. ACM Trans. Graph. 25, 3, 1206–1213.
McGuire, M., Osman, B., Bukowski, M., and Hennessy, P. 2011. The alchemy screen-space ambient obscurance algorithm. In Proceedings of the ACM SIGGRAPH Symposium on High Performance Graphics, ACM, New York, HPG ’11, 25–32. McGuire, M., Mara, M., and Luebke, D. 2012. Scalable ambient obscurance. In Proceedings of the Fourth ACM SIGGRAPH / Eurographics Conference on HighPerformance Graphics, Eurographics Association, Aire-la-Ville, Switzerland, EGGHHPG’12, 97–103.
Mittring, M. 2007. Finding next gen: Cryengine 2. In ACM SIGGRAPH 2007 Courses, ACM, New York, SIGGRAPH ’07, 97–121.
Ritschel, T., Grosch, T., and Seidel, H.-P. 2009. Approximating dynamic global illumination in image space. In Proceedings of the 2009 Symposium on Interactive 3D Graphics and Games, ACM, New York, I3D ’09, 75–82.

















 213
213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









