







 本文介绍了支持向量机的基本理论,包括线性分类、核方法和算法,特别是硬边距与软边距的概念。通过鸢尾花数据集的应用,展示了SVM在非线性分类中的能力。SVM的优点在于使用核函数解决非线性问题和最大化间隔,但面临大规模数据训练的挑战。
本文介绍了支持向量机的基本理论,包括线性分类、核方法和算法,特别是硬边距与软边距的概念。通过鸢尾花数据集的应用,展示了SVM在非线性分类中的能力。SVM的优点在于使用核函数解决非线性问题和最大化间隔,但面临大规模数据训练的挑战。
一、支持向量机理论简介
支持向量机是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面
1.线性分类
线性可分性
在分类问题中给定输入数据和学习目标:X={X1,X2,…,XN},y={y1,…,yN},其中输入数据的每个样本都包含多个特征并由此构成特征空间:X=[x1,x2,…,xn],而学习目标为二元变量
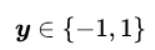
表示负类和正类
若输入数据所在的特征空间存在作为决策边界的超平面将学习目标按正类和负类分开,并使任意样本的点到平面距离大于等于1
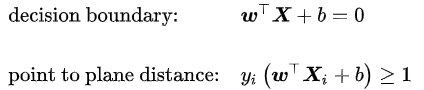
则称该分类问题具有线性可分性,参数w,b分别为超平面的法向量和截距。
满足该条件的决策边界实际上构造了2个平行的超平面作为间隔边界以判别样本的分类:
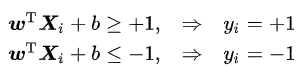
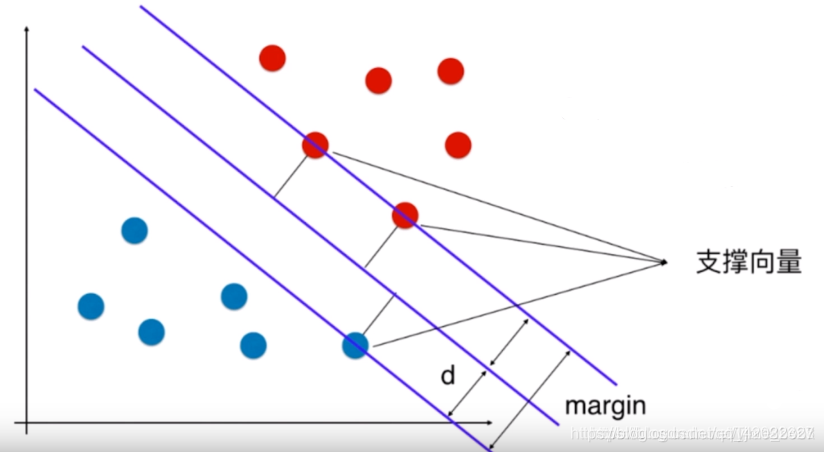
所有在上间隔边界上方的样本属于正类,在下间隔边界下方的样本属于负类。两个间隔边界的距离d=2/||w||被定义为边距(margin),位于间隔边界上的正类和负类样本为支持向量。
2.核方法
一些线性不可分的问题可能是非线性可分的,即特征空间存在超曲面将正类和负类分开。使用非线性函数可以将非线性可分问题从原始的特征空间映射至更高维的希尔伯特空间,从而转化为线性可分问题,此时作为决策边界的超平面表示如下:
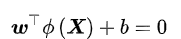
由于映射函数具有复杂的形式,难以计算其内积ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8306
8306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









