










1、 为什么要做这个研究(理论走向和目前缺陷) ?
现有的3D目标检测还是效率低。
2、 他们怎么做这个研究 (方法,尤其是与之前不同之处) ?
以原生的雷达数据(柱面图)作为输入,这样可以使得输入是密集规则的数据,包含5个通道(分别是距离r, 高度z,方位角theta, 强度e,以及一个标记是否包含3D点的通道),对每个像素点预测概率分布(相对中心点在x和y方向的均值作为偏移,以及共用的方差),根据各个像素点预测结果进行聚类,产生的同一个cluster的像素点的预测结果共同决定这个cluster对应的3D。为是分布预测更简单,做了一些简化,假定所有的3D位于同一平面,且高度相同,x, y方向的方差共用。
3、 发现了什么(总结结果,补充和理论的关系)?
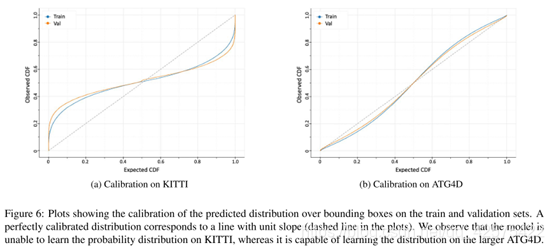
小数据集上KITTI效果不行,大数据集ATG4D(是KITTI160倍)效果不错。
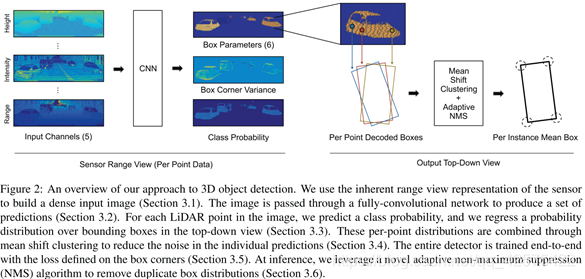
摘要:本文提出了LaserNet,用点云来做3D目标检测的高效网络。高效源于使用的是lidar原生的距离视角的数据,而这样的数据都是紧凑的。LaserNet用全卷积神经网络来预测3D box多峰分布,然后把这些3D box分布融合来为每个目标生成预测。
1、 引言
雷达传感器的距离视角(Range View)有点类似图像,而CNN在图像领域应用已经非常成功了。但是,现在点云数据大多都是先通过几何变换到3维空间成为3D点,然后再对3D点离散化为体素再进行处理。在距离视角下,点云数据是密集的,但是感知到的物体大小会随着距离变化而变化。在鸟瞰图视角,数据是稀疏的,但是物体的大小不随着距离变化而变化。另外,距离视角下的物体遮挡信息被保留下来,而鸟瞰图视角下的遮挡信息丢失了。
LaserNet不仅要预测一个3D框类别概率,还要预测检测框上的概率分布。
2、 相关研究
2.1 3D目标检测
一些使用了距离视角的数据的方法:VeloFCN,MV3D,但跟本文距离视角表达不太一样
2.2 概率目标检测(Probabilistic object detection)
一般做目标检测都是为每个3D框预测一个分类得分,但是这个得分往往包含着目标存在性和分类准确不确定性。进来还有一些方法以IOU损失来进行辩解框的回归。本文是预测边界框的概率分布而不仅仅是代表边界框角点的不确定。
3、 本文方法
3.1 输入表达
雷达本身产生的是一个距离柱面图,水平分辨率有旋转速度和激光脉冲频率决定,垂直分辨率由激光束决定,Velodyne 64E雷达产生的煮面图纵向分辨率是64,根据每个反射点的角度和距离可以计算出此点的(x, y, z)坐标。可能有多个3D点对应柱面图上的同一个像素点,只取最近的那个3D点来对应这个像素点,也有可能有有些像素点没有3D点对应,故添加了额外的一个通道标记每个像素点是否有3D点对应。输入共包含5个通道,分别是距离r, 高度z,方位角theta, 强度e,以及一个标记是否包含3D点的通道。
3.2 网络架构
网络架构如下图,网络是全卷积的,由3个层次组成。每层的卷积核个数分别是64,64,128 。
每层次包含一个特征提取模块和一些特征聚集模块。特征提取\聚合过程中,特征高度不变,长度不断下采样和上采样,最优一个1X1的卷积层来输出最后的用于编码输出的特征图。
3.3 预测
图像的每个点都预测类别概率,给定一个位于目标上的点,网络预测边界框上的概率分布,当目标比较远时,往往3D点比较稀疏或存在遮挡,这个概率分布可能会是多峰的。故用一个混合模型来(mixture)对概率分布进行建模,并训练网络预测一组均值和方差以及混合权重。
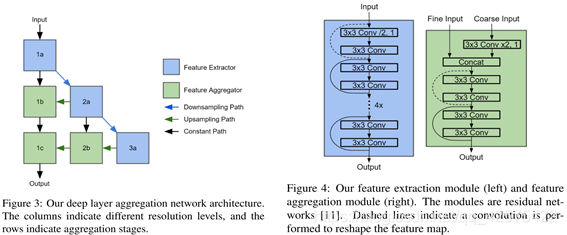
特征聚合模块和特征提取模块。
面向自动驾驶场景,假设所有的目标都位于同一水平面,且高度相同,故用水平面的4个角点参数化一个3D框,实际上不是预测4个角点,而是预测相对中心点的偏移(dx, dy),相对旋转角(wx, wy)=(cos w, sin w),以及3D框的长和宽(l, w)。用如下公式计算3D框的绝对坐标和角度:
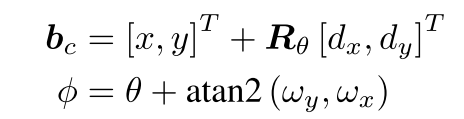
Rtheta是根据theta产生的旋转矩阵,然后就可以计算3D框的四个角点:
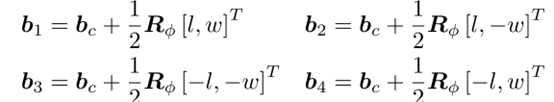
为了简化与概率分布过程,假设x和y维度上的方差是一样的,并且四个角点公用这个方差,实际预测的是标准差的log数。
3.4 均值漂移聚类
每个3D点都独立预测边界框分布,由于每个目标的里的3D点都预测的是相似的分布,而每个点都可能存在噪音,故通过对每个点的预测进行均值漂移聚类来减少噪音。因为所预测的分布是类别独立且多峰的,故在每个类别和每个混合模型的组件都分别进行均值漂移聚类。考虑到效率,均值漂移是在框的中心点计算的而非框的角点。
迭代更新均值过程:
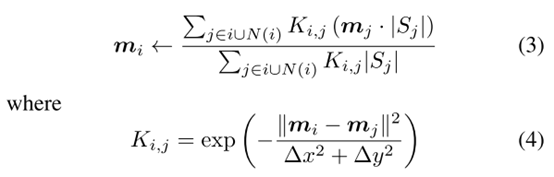
有点复杂,总之就是根据每个点预测的均值和方差聚类找同一个目标的3D点,作为一个cluster,每个cluster中的所有点预测的方差取均值,均值(每个点会预测x均值和y均值作为中心坐标偏移值)也取均值,作为这个cluster的方差和均值,也代表这个3D的中心偏移值和方差。
3.5 端到端训练
预测均值和方差的过程都是可微的,故整个网络可以端到端训练。
3.6 自适应NMS
以前的NMS没考虑预测的均值和方差,类别概率并不意味着边界框的质量,故以前的NMS在本文不适用。故提出自适应NMS算法,用预测的方差来确定一堆矿的IOU阈值,用框的物体性来作为其得分。
4 实验
两个数据集ATG4D和KITTI,ATG4D数据集是KITTI的160倍大!
4.1 在ATG4D和KITTI效果

5、讨论
大数据集ATG4D上效果好,小数据集上不行。

















 2643
2643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









