







《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
引言
在卷积神经网络 (CNN) 中,池化层是一种常见的层类型,通常添加在卷积层之后。池化层用于减少特征图的空间维度(即宽度和高度),同时保留深度(即通道数)。
- 池化层的工作原理是将输入特征图划分为一组不重叠的区域,称为
池化区域。然后,每个池化区域被转换为单个输出值,该输出值表示该区域中特定特征的存在。最常见的池化操作类型是最大池化和平均池化。 - 在最大池化中,每个池化区域的输出值只是该区域内输入值的最大值。这样做的效果是保留每个池化区域中最显著的特征,同时丢弃不太相关的信息。最大池化通常用于 CNN 中的物体识别任务,因为它有助于识别物体最显著的特征,例如其边缘和角落。
- 在平均池化中,每个池化区域的输出值是该区域内输入值的平均值。与最大池化相比,这样做可以保留更多信息,但也可能削弱最显著的特征。平均池化通常用于 CNN 中的图像分割和物体检测等任务,这些任务需要对输入进行更细粒度的表示。
在 CNN 中,池化层通常与卷积层结合使用,每个池化层都会减少特征图的空间维度,而卷积层则会从输入中提取越来越复杂的特征。然后将生成的特征图传递到全连接层,该层执行最终的分类或回归任务。
池化后维度计算
池化操作涉及在特征图的每个通道上滑动二维过滤器,并汇总过滤器覆盖区域内的特征。 对于具有nh X nw X nc 维度的特征图,池化层后获得的输出维度为 :
(nh - f + 1)/s X (nw - f + 1)/s X nc
各参数含义为:
-> nh -特征图的高度
-> nw -特征图的宽度
-> nc -特征图中的通道数
-> f -卷积核的大小
-> s -步幅长度
一种常见的 CNN 模型架构是将多个卷积层和池化层一个接一个地堆叠在一起。
1.为什么要使用池化层?
- 池化层用于减少特征图的维度。因此,它减少了需要学习的参数数量和网络中执行的计算量。
- 池化层总结了卷积层生成的特征图区域中存在的特征。因此,进一步的操作是对总结的特征而不是卷积层生成的精确定位的特征执行的。这使得模型对输入图像中特征位置的变化更具鲁棒性。
2.池化层的类型:
2.1最大池化
- 最大池化是一种池化操作,它从过滤器覆盖的特征图区域中选择最大元素。因此,最大池化层之后的输出将是包含前一个特征图最突出特征的特征图。

- 这可以使用 keras 中的 MaxPooling2D 层实现,如下所示:
代码#1:使用 keras 执行最大池化
import numpy as np
from keras.models import Sequential
from keras.layers import MaxPooling2D
# define input image
image = np.array([[2, 2, 7, 3],
[9, 4, 6, 1],
[8, 5, 2, 4],
[3, 1, 2, 6]])
image = image.reshape(1, 4, 4, 1)
# define model containing just a single max pooling layer
model = Sequential(
[MaxPooling2D(pool_size = 2, strides = 2)])
# generate pooled output
output = model.predict(image)
# print output image
output = np.squeeze(output)
print(output)
- 输出:
[[9. 7.]
[8. 6.]]
2.2平均池化
- 平均池化计算过滤器覆盖的特征图区域中元素的平均值。因此,最大池化给出了特征图特定块中最突出的特征,而平均池化给出了块中存在的特征的平均值。
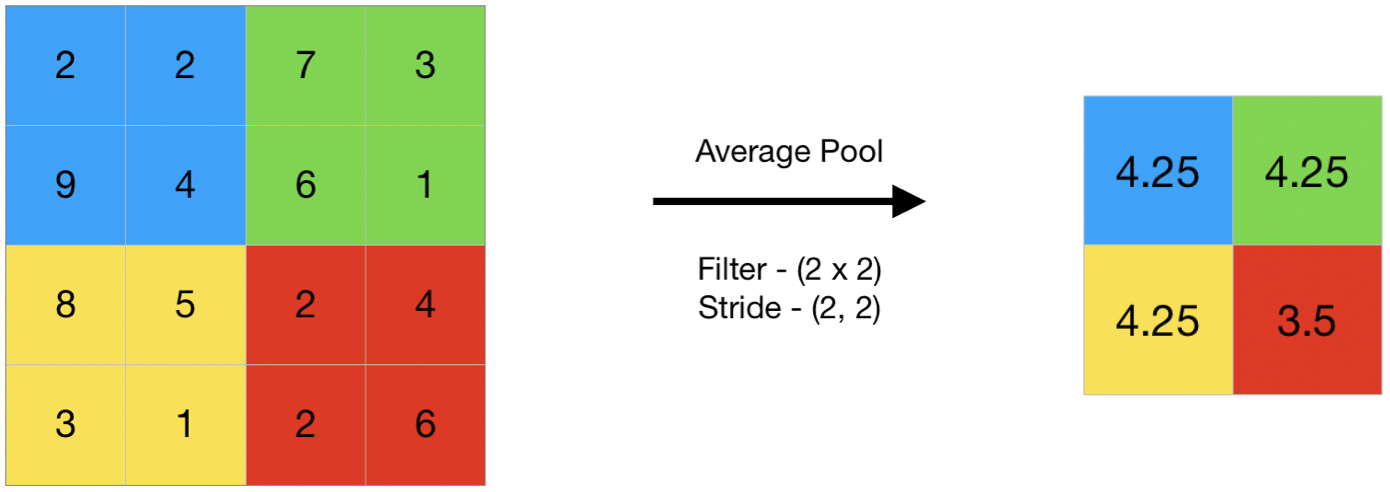
- 代码 #2:使用 keras 执行平均池化
import numpy as np
from keras.models import Sequential
from keras.layers import AveragePooling2D
# define input image
image = np.array([[2, 2, 7, 3],
[9, 4, 6, 1],
[8, 5, 2, 4],
[3, 1, 2, 6]])
image = image.reshape(1, 4, 4, 1)
# define model containing just a single average pooling layer
model = Sequential(
[AveragePooling2D(pool_size = 2, strides = 2)])
# generate pooled output
output = model.predict(image)
# print output image
output = np.squeeze(output)
print(output)
输出:
[[4.25 4.25]
[4.25 3.5]]
2.3全局池化
全局池化将特征图中的每个通道缩减为单个值。因此,nh x nw x nc特征图缩减为1 x 1 x nc特征图。这相当于使用尺寸为nh x nw的过滤器,即特征图的尺寸。
此外,它可以是全局最大池化或全局平均池化。
代码 #3:使用 keras 执行全局池化
import numpy as np
from keras.models import Sequential
from keras.layers import GlobalMaxPooling2D
from keras.layers import GlobalAveragePooling2D
# define input image
image = np.array([[2, 2, 7, 3],
[9, 4, 6, 1],
[8, 5, 2, 4],
[3, 1, 2, 6]])
image = image.reshape(1, 4, 4, 1)
# define gm_model containing just a single global-max pooling layer
gm_model = Sequential(
[GlobalMaxPooling2D()])
# define ga_model containing just a single global-average pooling layer
ga_model = Sequential(
[GlobalAveragePooling2D()])
# generate pooled output
gm_output = gm_model.predict(image)
ga_output = ga_model.predict(image)
# print output image
gm_output = np.squeeze(gm_output)
ga_output = np.squeeze(ga_output)
print("gm_output: ", gm_output)
print("ga_output: ", ga_output)
输出:
gm_输出:9.0
ga_输出:4.0625
池化层的优缺点
池化层的优点:
- 降维:池化层的主要优点是它们有助于降低特征图的空间维度。这降低了计算成本,并通过减少模型中的参数数量来帮助避免过度拟合。
- 平移不变性:池化层对于实现特征图中的平移不变性也很有用。这意味着图像中物体的位置不会影响分类结果,因为无论物体的位置如何,都会检测到相同的特征。
- 特征选择:池化层也可以帮助从输入中选择最重要的特征,因为最大池化选择最显著的特征,而平均池化保留更多的信息。
池化层的缺点:
- 信息丢失:池化层的主要缺点之一是它们会从输入特征图中丢弃一些信息,这对于最终的分类或回归任务非常重要。
- 过度平滑:池化层也可能导致特征图的过度平滑,从而导致丢失一些对于最终分类或回归任务很重要的细粒度细节。
- 超参数调整:池化层还引入了超参数,例如池化区域的大小和步长,需要对其进行调整才能实现最佳性能。这可能很耗时,并且需要一定的模型构建专业知识。

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~


















 32万+
32万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











