




Motivation
-
SuperGlue用绝对位置编码的方式,并且只在第一层将位置编码与视觉编码融合,但经过多次的特征聚合操作,模型更倾向于学习几何结构关系(视觉),很难在最后的特征中保留空间信息。
- Transformer结构的计算复杂度与关键点数量存在二次方增长关系,SuperGlue基于全量的特征点叠加多层注意力结构的方式,需要耗费大量计算资源,处理的效率也比较低。
LightGlue Architecture
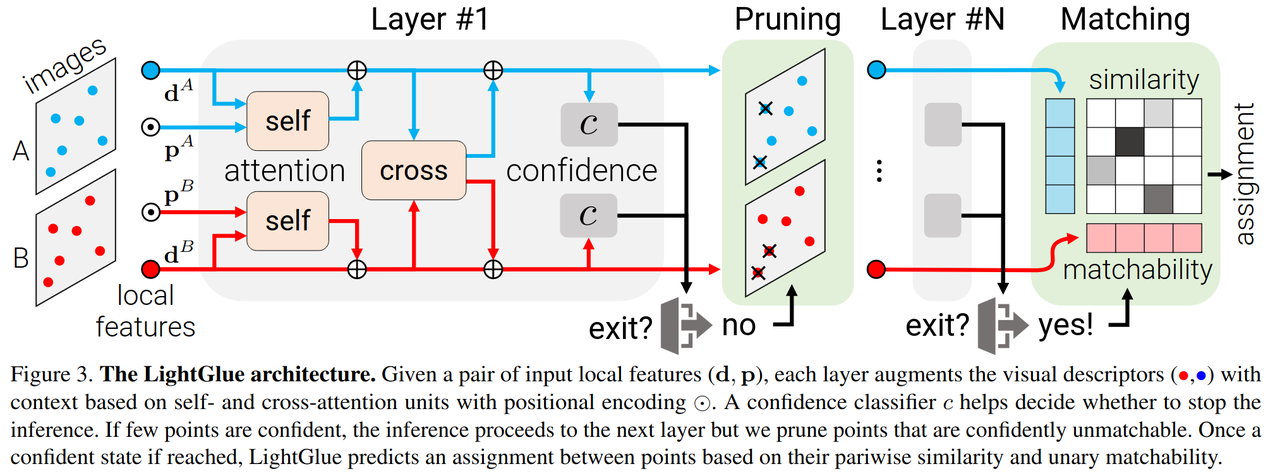
一种结合相对位置编码的注意力结构和动态评估匹配置信度机制的方法:相对位置旋转编码能够更频繁更显性的利用位置信息,提前退出以及特征点剪枝机制,可以移除不可靠的特征点,减少冗余计算,加快推理速度。
Positional Encoding
使用相对位置的旋转编码(RoPE),将注意力的内积计算用相对位置关系重新建模,这种位置编码的方式让注意力计算不仅依赖于视觉特征还依赖它们的相对位置,更频繁更显性的利用位置信息,只作用在自注意力机制中。
绝对位置编码:
其中,是依赖于
位置的编码向量。
相对位置编码:
其中,是依赖于
和
位置的编码向量。
相对位置的旋转编码(RoPE):
其中,是MLP对位置向量的编码结果。
Adaptive depth and width
在训练时如SuperGlue采用全量特征点构建注意力结构,但在推理时采用动态评估的方式自适应的缩减注意力模块的深度和宽度,节省推理资源,加快推理速度。
置信度分类器:独立的结构,与主体网络结构分开训练,用于动态评估匹配点对的置信度,用来支持提前退出机制以及特征点剪枝,移除不可靠的特征点,减少冗余计算,加快推理速度。
提前推出机制:判断匹配成功的特征点数量是否满足阈值,及时停止推理。
特征点剪枝:判断与dustbin匹配点对的置信度,并将高置信度特征点移除,不参与后续迭代
References
代码: https://github.com/cvg/LightGlue
论文: https://arxiv.org/pdf/2306.13643
会议:ICCV 2023

















 1393
1393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









