






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达作者丨蛋酱、张倩、陈萍
来源丨机器之心
编辑丨极市平台
导读
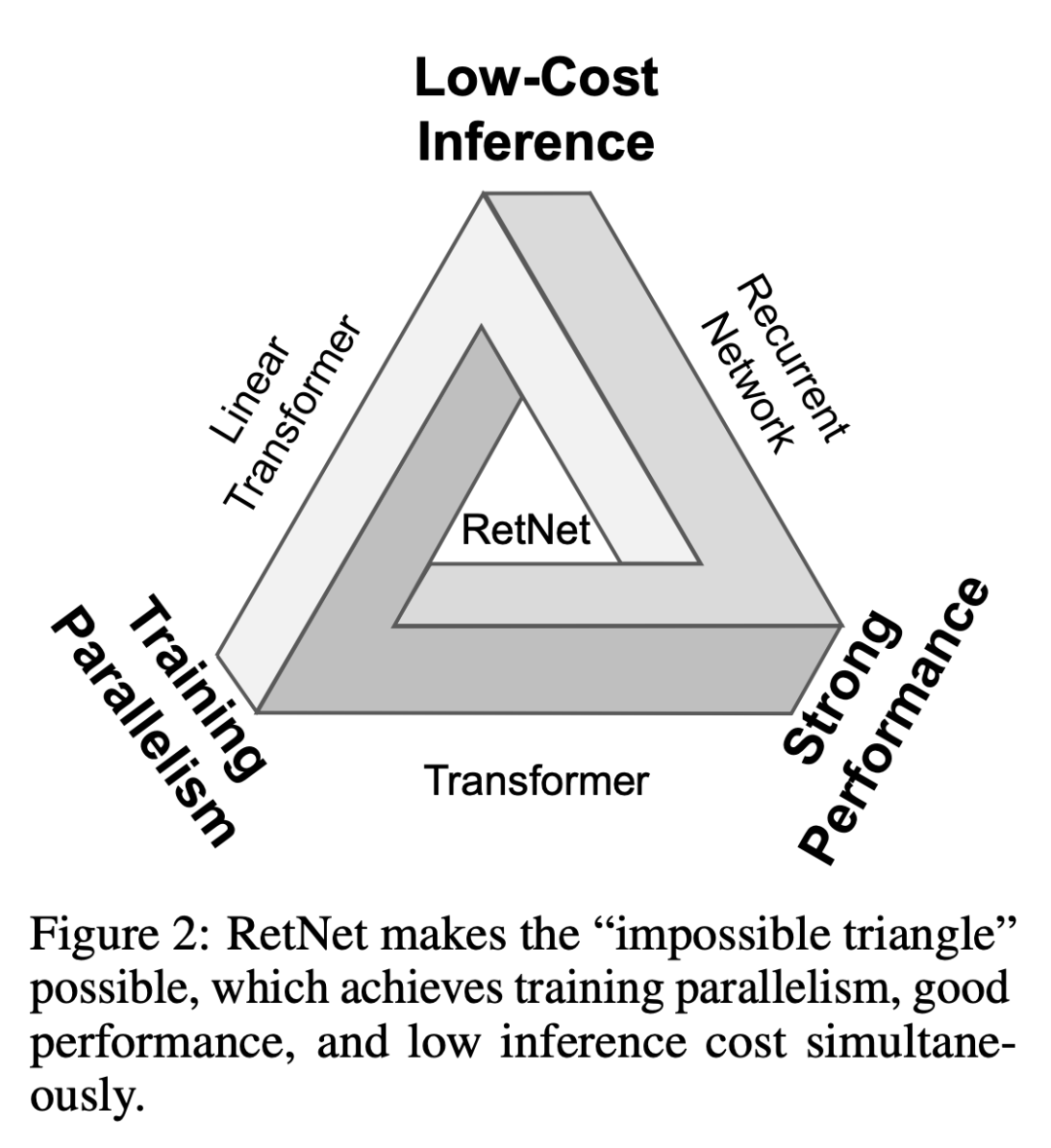
本文提出了 retentive 网络RetNet,同时实现了低成本推理、高效长序列建模、媲美 Transformer 的性能和并行模型训练,打破了「不可能三角」。
LLM 的成功,某种程度上要归功于 Transformer 架构在自然语言处理任务上的突破。该架构最初是为了克服循环模型的 sequential training 问题而提出的。这些年来,Transformer 已经成为 LLM 普遍采用的架构。
然而,Transformer 的训练并行性是以低效推理为代价的:每一步的复杂度为 O (N) 且键值缓存受内存限制,让 Transformer 不适合部署。不断增长的序列长度会增加 GPU 内存消耗和延迟,并降低推理速度。
研究者们一直在努力开发下一代架构,希望保留训练并行性和 Transformer 的性能,同时实现高效的 O (1) 推理。针对这个问题,此前的方法都没能同时实现这几点,至少与 Transformer 相比没有显示出绝对的优势。
现在,微软研究院和清华大学的研究者已经在这个问题上取得了重大突破。

论文链接:https://arxiv.org/pdf/2307.08621.pdf
在这项工作中,研究者提出了 retentive 网络(RetNet),同时实现了低成本推理、高效长序列建模、媲美 Transformer 的性能和并行模型训练,打破了「不可能三角」。
具体来说,RetNet 引入了一种多尺度 retention 机制来替代多头注意力,它有三种计算范式:并行、循环和分块循环表征。
首先,并行表征使训练并行化,以充分利用 GPU 设备。其次,循环表征法在内存和计算方面实现了高效的 O (1) 推理。部署成本和延迟可以显著降低,同时无需键值缓存技巧,大大简化了实现过程。此外,分块循环表征法能够执行高效的长序列建模。研究者对每个局部块进行并行编码以提高计算速度,同时对全局块进行循环编码以节省 GPU 内存。
论文进行了大量实验来对比 RetNet 和 Transformer 及其变体。实验结果表明,RetNet 在 scaling 曲线和上下文学习方面始终具有竞争力。此外,RetNet 的推理成本与长度无关。对于 7B 模型和 8k 序列长度,RetNet 的解码速度是带键值缓存的 Transformers 的 8.4 倍,内存节省 70%。
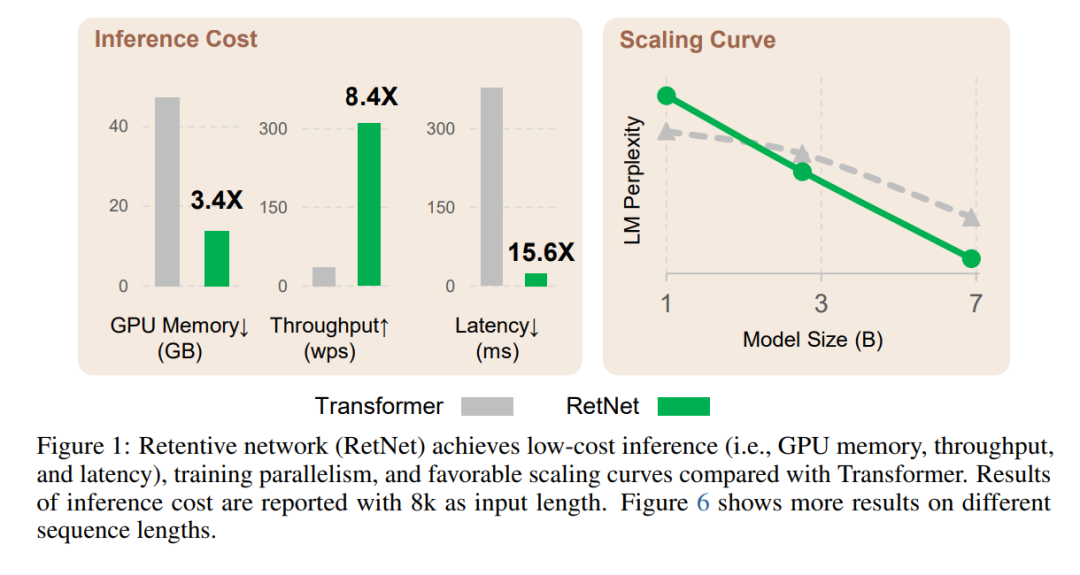
在训练过程中,RetNet 也能够比标准 Transformer 节省 25-50% 的内存,实现 7 倍的加速,并在高度优化的 FlashAttention 方面具有优势。 此外,RetNet 的推理延迟对批大小不敏感,从而实现了巨大的吞吐量。
这些令人惊艳的特质让不少研究者惊呼「好得不可思议」,甚至有人将其比作当初「M1 芯片」登场所带来的变革意义。看来,RetNet 有望成为 Transformer 的有力继承者。
不过,也有研究者提出疑问:这么优秀的表现是否意味着 RetNet 要在某些方面有所权衡?它能扩展到视觉领域吗?

接下来,让我们深入了解 RetNet 方法的细节。
Retentive 网络
RetNet 由 L 个相同的块堆叠而成,其布局与 Transformer 类似(即残差连接和 pre-LayerNorm)。每个 RetNet 块包含两个模块:多尺度retention(MSR)和前馈网络(FFN)。
给定输入序列 , RetNet 以自回归方式对序列进行编码。输入向量 首先被封装为 , 其中 是隐藏维度。然后, 计算上下文向量表征 。
Retention
RetNet 具有循环和并行双重形式的 retention 机制,因此能够并行地训练模型,同时循环地进行推理。
给定输入,将其投影为一维函数 v (n) = X_n - w_V。考虑一个序列建模问题,通过状态 s_n 映射 v (n) → o (n)。
为简单起见,让 v_n, o_n 表示 v (n),o (n)。此处以循环的方式对映射进行表述:
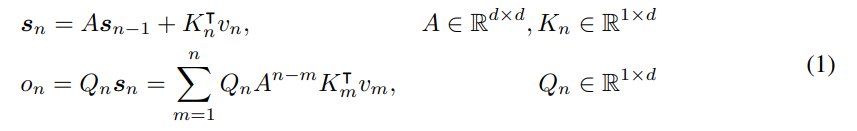
其中,将 v_n 映射到状态向量 s_n,然后实现线性变换,对序列信息进行循环编码。
接下来,使投影 Q_n, K_n 具有内容感知能力:

其中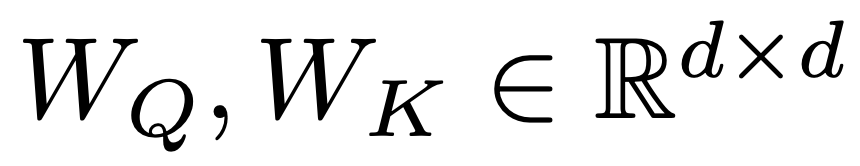 是可学习矩阵。
是可学习矩阵。
将矩阵 对角化, 其中 。然后得到 。通过将 吸收到 W_Q 和 中, 可以将方程 (1) 重写为
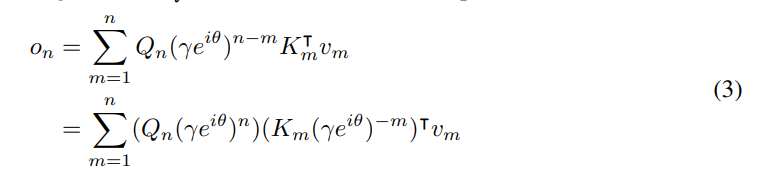
其中,称为 xPos,即为 Transformer 提出的相对位置嵌入。进一步将 γ 简化为标量,公式(3)则变为
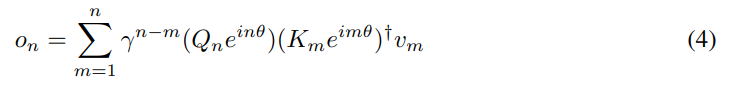
其中†为共轭转置。该公式很容易在训练实例中并行化。
总之,从公式 (1) 所示的循环建模开始,然后推导出公式 (4) 中的并行公式。将原始映射 v (n) →o (n) 视为向量,得到如下的 retention 机制:
1)Retention 的并行表征
如图 3a 所示,Retention 层定义为:
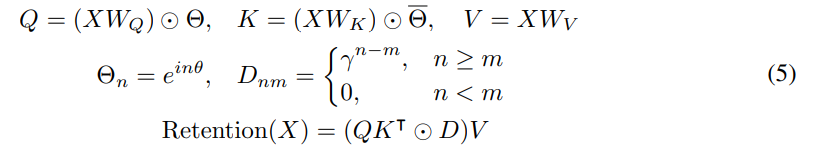
与自注意力类似,并行表征使得能够使用 GPU 高效地训练模型。
2)Retention 的循环表征
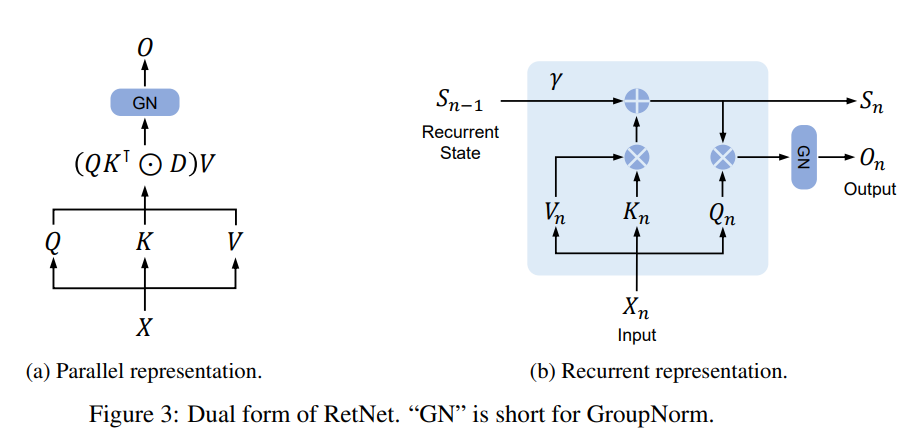
如图 3b 所示,所提出机制也可以写成循环神经网络(RNN),这有利于推理。对于第 n 个时间步,循环得到的输出为
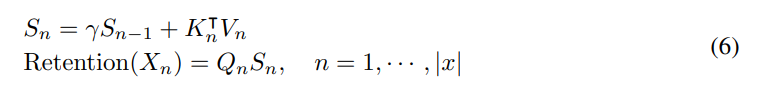
这里的 Q, K, V, γ 和公式 5 相同。
3)Retention 分块循环表征
并行表征和循环表征的混合形式可以加速训练,特别是对于长序列。此处将输入序列划分为若干小块。在每个块内,按照并行表征(公式(5))进行计算。相反,跨块信息则按照循环表征(公式(6))进行传递。具体来说,让 B 表示块长度。通过以下方式计算第 i 个分块的 retention 输出:
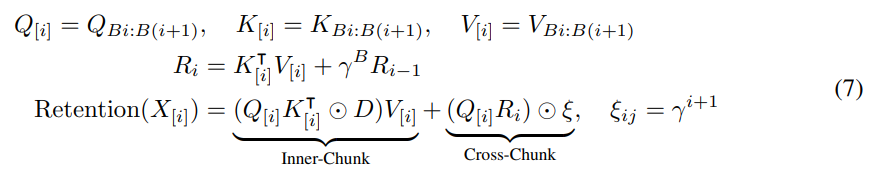
其中 [i] 表示第 i 个数据块,例如。
门控多尺度 Retention
在每个层中,研究者使用 h = d_model/d 个 retention 头,其中 d 是头的维度。这些头使用不同的参数矩阵 W_Q、W_K、W_V ∈ R^(d×d)。此外,多尺度 retention(MSR)为每个头分配不同的 γ。为了简化,研究者将 γ 设置为在不同层之间相同并保持固定。另外,他们添加了一个 swish 门 [RZL17] 来增加层的非线性性。形式上,给定输入 X,研究者将该层定义为:
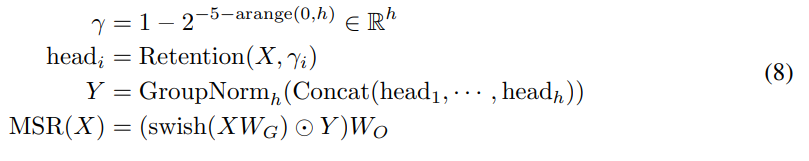
其中,为可学习参数,GroupNorm [WH18] 对每个头的输出进行归一化,遵循 [SPP^+19] 中提出的 SubLN。注意,这些头使用多个 γ 尺度,这会带来不同的方差统计结果。所以研究者分别对头的输出进行归一化。
retention 的伪代码如图 4 所示。

Retention Score 归一化
研究者利用 GroupNorm 的尺度不变性来提高 retention 层的数值精度。具体而言, 在 GroupNorm 中乘以一个标量值不会影响输出和反向梯度, 即 GroupNorm (a head_i) = GroupNorm (head_i)。研究者在公式(5)中实现了三个归一化因子。首先, 他们将 QK^T 归一化 为 。其次, 他们将 替换为 。第三,他们用 表示 retention scores , 将其归一化为 。然后, retention 输出变为 。由于尺度不变的特性, 上述技巧不会影响最终的结果, 同时稳定了正向和反向传递的数值流动。
Retention 网络总体结构
对于一个 L 层的 retention 网络, 研究者堆叠多尺度 retention (MSR) 和前馈网络 (FFN) 来构建模型。形式上, 输入序列 通过一个词嵌入层被转换为向量。研究者使用打包后的嵌入
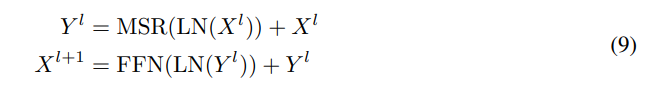
其中,LN (・) 为 LayerNorm [BKH16]。FFN 部分计算为 FFN (X) = gelu (XW_1) W_2,其中 W_1、W_2 为参数矩阵。
训练:研究者在训练过程中使用了并行(公式 5)表示和块循环(公式 7)表示。序列或块内的并行有效地利用了 GPU 来加速计算。更有利的是,块循环对于长序列训练特别有用,这在 FLOPs 和内存消耗方面都是有效的。
推理:在推理过程中,研究者采用了循环表示(公式 6),这非常适合自回归解码。O (1) 的复杂度减少了内存占用和推理延迟,同时实现了相当的结果。
与以往方法的联系和区别
表 1 从不同角度对 RetNet 与以往的方法进行了比较。对比结果与图 2 所示的「不可能三角」相呼应。此外,RetNet 对于长序列具有线性记忆复杂性,因为它采用了分块循环表示。
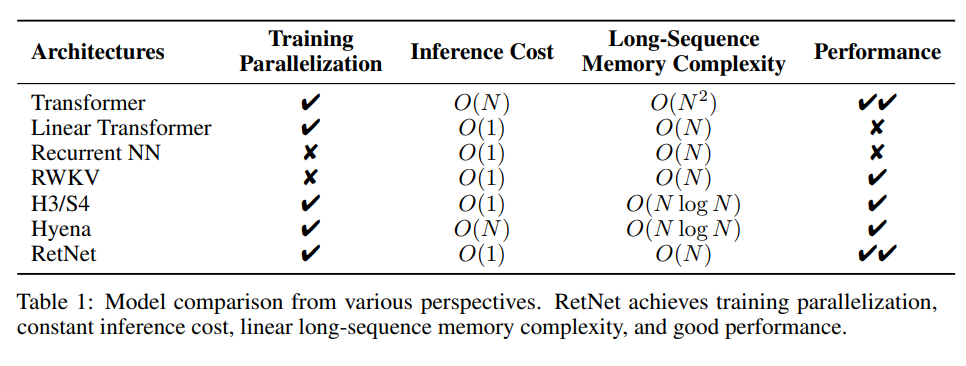
Transformer:retention 的并行表示与 Transformers [VSP^+17] 有着相似的思路。最相关的 Transformer 变体是 Lex Transformer [SDP^+22],它实现了 xPos 作为位置嵌入。如式 (3) 所示,retention 的推导与 xPos 一致。与注意力相比,retention 消除了 softmax 并使循环公式成为可能,这非常有利于推理。
S4:与式 (2) 不同,如果 Q_n 和 K_n 是 content-unaware 的,则公式可简并为 S4 [GGR21],其中
Linear Attention:变体通常使用各种 kernel来取代 softmax 函数。然而,线性注意力难以有效地编码位置信息,导致模型性能下降。此外,研究者从头开始重新检查序列建模,而不是以近似 softmax 为目标。
AFT/RWKV:Attention Free Transformer (AFT) 简化了点积对元素运算的关注,并将 softmax 移动到关键向量。RWKV 用指数衰减取代 AFT 的位置嵌入,并循环运行模型进行训练和推理。相比之下,retention 保留了高维状态来编码序列信息,有助于提高表达能力和性能。
xPos/RoPE:与为 Transformers 提出的相对位置嵌入方法相比,公式(3)呈现出与 xPos [SDP^+22] 和 RoPE [SLP^+21] 类似的表达式。
Sub-LayerNorm:如公式(8)所示,retention 层使用 Sub-LayerNorm [WMH^+22] 对输出进行归一化。由于多尺度建模导致不同头的方差不同,研究者将原始的 LayerNorm 替换为 GroupNorm。
实验结果
该研究进行了大量的实验来评估 RetNet,包括语言建模任务、下游任务上零样本、少样本学习性能,此外,研究者还比较了 RetNet 训练和推理的速度、内存消耗和延迟等指标。
与 Transformer 的比较
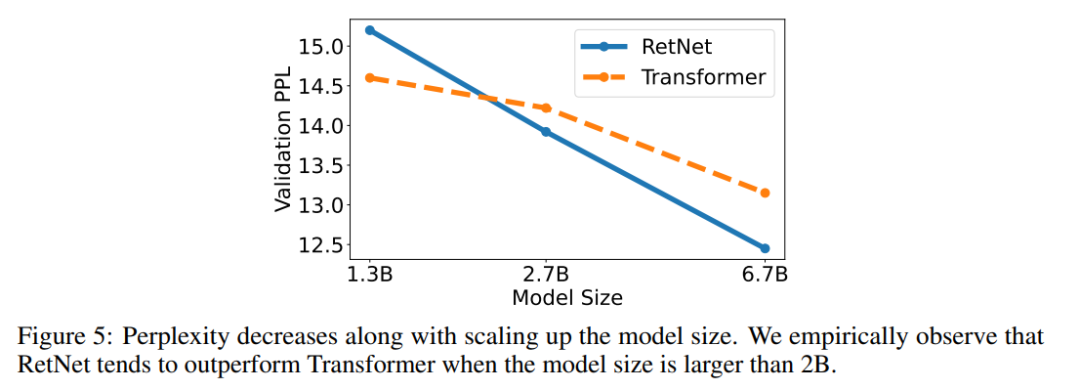
语言建模任务。图 5 报告了基于 Transformer 和 RetNet 的语言模型在验证集上的困惑度(perplexity)结果。实验给出了 13 b、2.7B 和 6.7B 三种模型尺寸的缩放曲线。表明,RetNet 取得了与 Transformer 可比较的结果。
更重要的是,这一结果还表明了 RetNet 在大小扩展方面更具优势。除了性能优势外,实验中 RetNet 的训练也非常稳定。RetNet 是 Transformer 的有力竞争对手。研究者根据经验发现,当模型规模大于 2B 时,RetNet 开始超越 Transformer。
该研究还在各种下游任务上对语言模型进行了比较。他们使用 6.7B 大小的模型进行了零样本和 4 个样本学习的评估,如表 3 所示。表中展示的关于准确率的数字与图 5 中呈现的语言建模困惑度一致。在零样本学习和上下文学习设置中,RetNet 在性能上与 Transformer 相当。
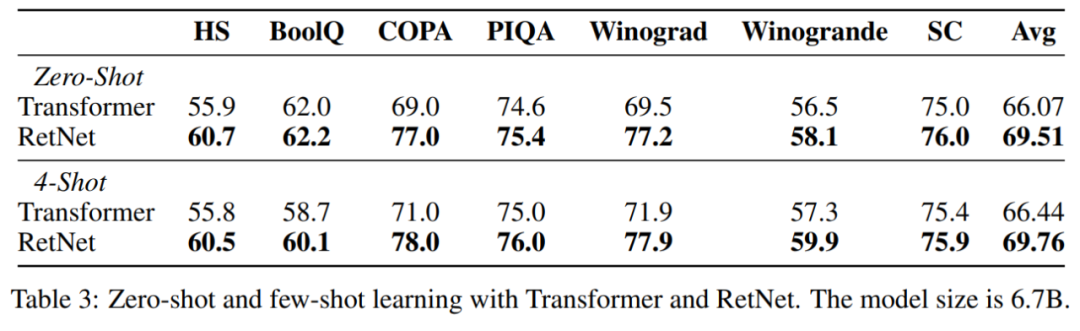
训练成本
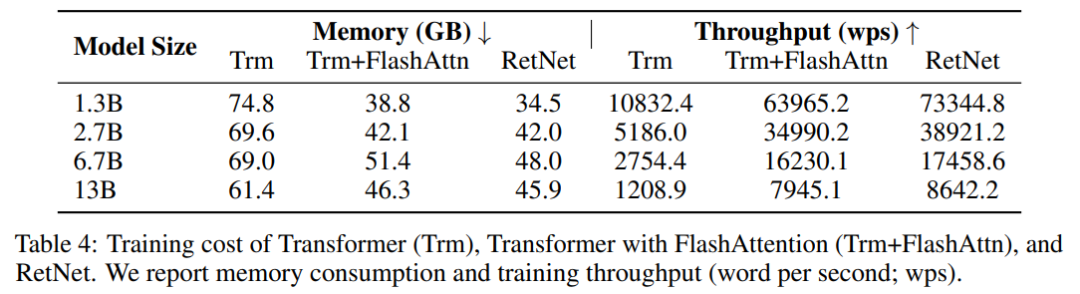
表 4 比较了 Transformer 和 RetNet 在训练速度和内存开销方面的结果,其中训练序列长度为 8192。此外,该研究还将其与 FlashAttention 进行了比较。
实验结果表明,在训练过程中,RetNet 比 Transformer 更节省内存,并且具有更高的吞吐量。 即使与 FlashAttention 相比,RetNet 在速度和内存成本方面仍然具有竞争力。此外,由于不依赖于特定的内核,用户可以轻松高效地在其他平台上训练 RetNet。例如,研究者可以在具有良好吞吐量的 AMD MI200 集群上训练 RetNet 模型。
推理成本
图 6 比较了 Transformer 和 RetNet 在推理过程中的内存成本、吞吐量和延迟。实验中使用了 A100-80GB GPU 评估了 6.7B 模型。图 6 显示,RetNet 在推理成本方面优于 Transformer。
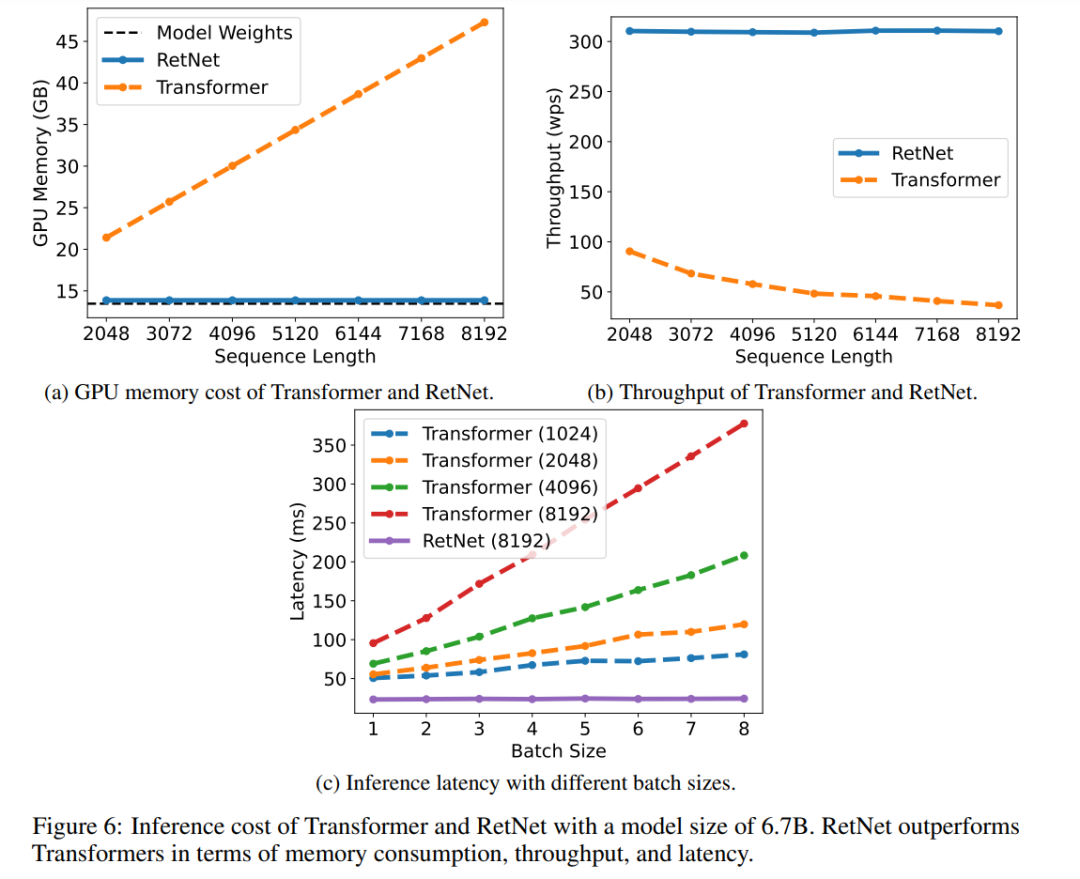
内存:如图 6a 所示,由于 KV(键和值)缓存,Transformer 的内存成本呈线性增长。相比之下,RetNet 的内存消耗即使对于长序列也保持一致。
吞吐量:如图 6b 所示,随着解码长度的增加,Transformer 的吞吐量开始下降。相比之下,RetNet 通过利用 Retention 的循环表征,在解码过程中具有更高的吞吐量,并且与长度无关。
延迟:延迟是部署中的重要指标,它极大地影响用户体验。图 6c 报告了解码延迟。实验结果显示,增加批次大小会使 Transformer 的延迟变大。此外,Transformer 的延迟随着输入长度的增加而增加得更快。为了使延迟可接受,研究者不得不限制批次大小,这会损害 Transformer 的整体推理吞吐量。相比之下,RetNet 的解码延迟优于 Transformer,并且在不同的批次大小和输入长度下几乎保持不变。
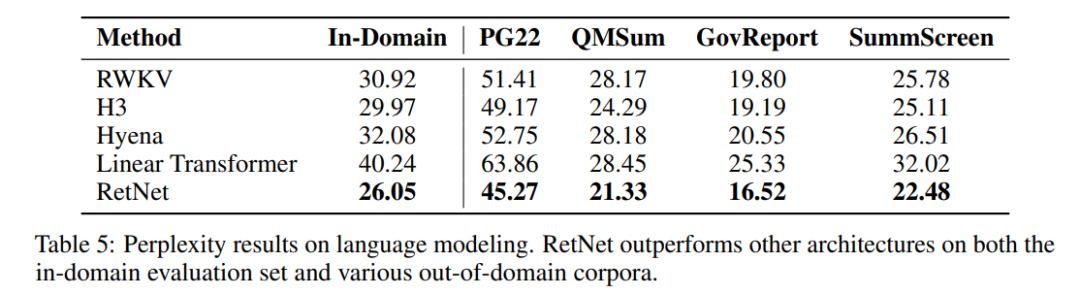
与 Transformer 变体比较
下表表明,RetNet 在不同的数据集上优于先前的方法。RetNet 不仅在领域内语料库上取得更好的评估结果,还在几个领域外数据集上获得更低的困惑度。这种优越的性能使得 RetNet 成为 Transformer 的有力继任者。
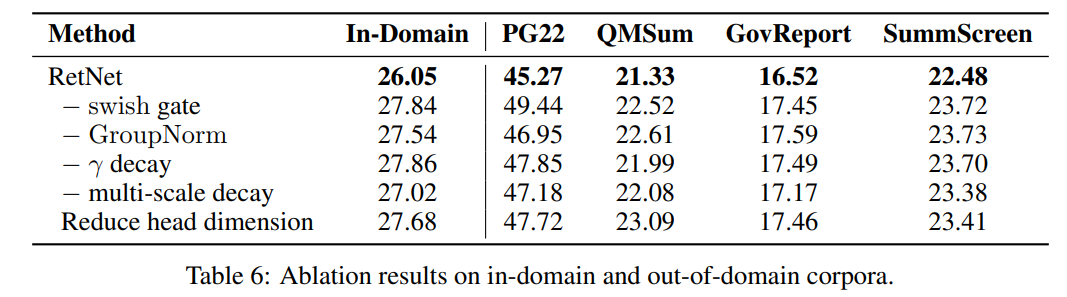
消融实验
下表列出了 RetNet 的各种设计选择,并在表 6 中报告了语言建模结果。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~














 1057
1057











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









