






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达论文一
Why do deep convolutional networks generalize so poorly to small image transformations?
卷积神经网络CNN极大提高了计算机视觉的性能,带来了计算机视觉的革命,但众所周知,只要输入图片稍微改一个像素、平移一个像素,CNN的输出就会发生巨大的变化,所以很容易招到对抗攻击。
1.论文核心内容
现代深度卷积神经网络在图像中的小目标发生平移后对其类别的判断会产生非常大的误差,这与人们设计深度卷积网络的初衷并不一致。
网络层数越深,这种错误越容易发生。
这种错误的发生是由于现代卷积神经网络的架构设计没有遵从经典的采样定理以致于泛化能力不能得到保证。
通用的图像数据集中的统计误差使得CNN难以学习到其中的变换不变性(invariant to these transformations)。
结论:CNNs的泛化能力不如人类。现代深度神经网络对于平移,旋转,缩放等变换并不具有不变性,且和下采样操作和数据集中的偏差有关系。
2.CNN的不足之处
深度卷积神经网络(CNN)对计算机视觉带来的革新是天翻地覆的,尤其是在物体识别领域。和其他机器学习算法一样,CNN成功的关键在于归纳偏差的方法,不同架构的选择影响着偏差的具体计算方式。在CNN中,卷积和池化这两个关键操作是由图像不变性驱动的,这意味如果我们对图像做位移、缩放、变形等操作,它们对网络提取特征没有影响。
如下图所示,三种变换分别是平移,缩放和自然运动状态的微小差异,但是预测结果的变化却非常大。在最上方的输入中,他们只是将图像从左到右依次下移了一像素,就使模型评分出现了剧烈的波动;在中间的输入中,图像被依次放大,模型的评分也经历了直线下降和直线上升;而对于最下方的输入,这三张图是从BBC纪录片中选取的连续帧,它们在人类眼中是北极熊的自然运动姿态,但在CNN“眼中”却很不一样,模型评分同样遭遇“滑铁卢”。
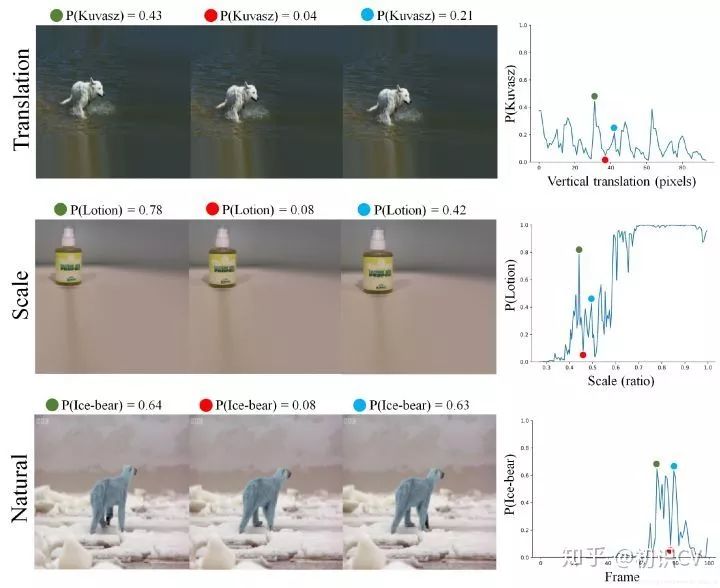
三种变换分别是平移,缩放和自然运动状态。左侧图像是模型的输入,右侧折线图是模型评分,使用的模型是InceptionResNet-V2 CNN
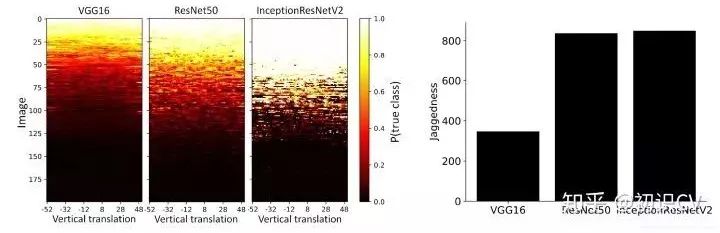
下图是更加具体的实验:图A的纵坐标是200张图像,它用颜色深浅表示模型识别结果的好坏,其中非黑色彩表示模型存在能对转变后的图像正确分类的概率,全黑则表示完全无法正确分类。图B中采用一个指标“jaggedness”(一个像素平移后网络预测分类结果正确的次数),结果显示更深层的网络具有更大的“jaggedness”和更好的测试准确率,不变性不是很强。
举个例子:正常输入是一维数字序列 00110011
shift为0时的Maxpooling如下:
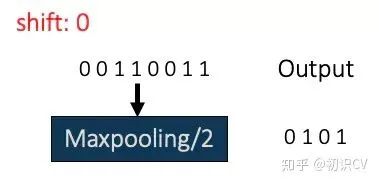
向左平移1时的Maxpooling:

只平移1个像素,Maxpooling结果就发生了巨大差异。下采样是CNN平移不变性丢失的罪魁祸首。
3.原因:不满足采样定理
论文中的原文说:我们不能简单地把系统中的平移不变性寄希望于卷积和二次采样,输入信号的平移不意味着变换系数的简单平移,除非这个平移是每个二次采样因子的倍数。
现代CNN中普遍包含二次采样(subsampling)操作,它是我们常说的下采样层,也就是池化层、stride。它的本意是为了提高图像的平移不变性,同时减少参数,但它在平移性上的表现真的很一般。
考虑到现在CNN通常包含很多池化层,它们的二次采样因子会非常大,以InceptionResnetV2为例,这个模型的二次采样因子是45,所以它保证精确平移不变性的概率有多大?只有 
4.为什么CNN不能从数据中学习平移不变性?
上面论证了CNN在架构上无法保证平移不变性,而且观察得知,它只能从大量数据中学到部分不变性,论文认为是这些通用数据集中存在一定的摄影师偏差,使得神经网络无需学会正式的平移不变性。宏观来看,只要不是像素级别的编码,世界上就不存在两张完全一样的图像,所以神经网络是无法学到严格的平移不变性的,也不需要去学习。
论文二
Making Convolutional Networks Shift-Invariant Again
论文一中已经分析了CNN不能从数据中学习平移不变性,根本原因就在于下采样(不满足采样定理),无论是Max Pooling,Average Pooling,还是Strided-Convolution,只要是步长大于1的下采样,均会导致平移不变性的丢失。
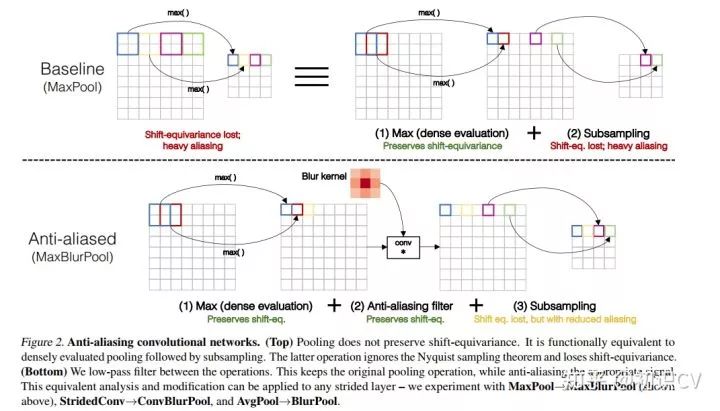
本文通过合理安排抗混叠滤波器的位置和频率,在不去掉最大值池化等的前提下降低混叠效应,使网络具有不变性特点。将loss pass filter插入到cnn中,在下采样之前进行,以防止走样。

主要思想是比较巧妙地将最大值池化进行了分解:(1)密集最大值选择(2)降采样。然后在两者中间插入一个低通滤波器(二维图像就是卷积运算)。其中,第一步的Max操作是通过密集滑窗进行的,因此具有平移变化性,而后面的降采样不具备平移敏感性。
参考
Why do deep convolutional networks generalize so poorly to small image transformations? https://arxiv.org/pdf/1805.12177.pdf
Making Convolutional Networks Shift-Invariant Again https://arxiv.org/pdf/1904.11486v1.pdf
作者:知乎-初识CV
地址:https://www.zhihu.com/people/AI_team-WSF
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~














 2601
2601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









