






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达本文转载自:我爱计算机视觉
一、论文信息
论文标题:Self-Supervised Scalable Deep Compressed Sensing(自监督可变采样率的深度压缩感知)
论文作者:Bin Chen(陈斌), Xuanyu Zhang(张轩宇), Shuai Liu(刘帅), Yongbing Zhang†(张永兵), and Jian Zhang†(张健)(†通讯作者)
作者单位:北京大学深圳研究生院、清华大学深圳国际研究生院、哈尔滨工业大学(深圳)
发表刊物:International Journal of Computer Vision (IJCV)
发表时间:2024年8月13日
正式版本:https://link.springer.com/article/10.1007/s11263-024-02209-1
ArXiv版本:https://arxiv.org/abs/2308.13777
开源代码:https://github.com/Guaishou74851/SCNet
二、任务背景
作为一种典型的图像降采样技术,自然图像压缩感知(Compressed Sensing,CS)的数学模型可以表示为,其中是原始图像真值(Ground Truth,GT),是采样矩阵,是观测值,是噪声。定义压缩采样率为。
图像CS重建问题的目标是仅通过观测值和采样矩阵来复原出GT 。基于有监督学习的方法需要搜集成对的观测值和GT数据,以训练一个重建网络。然而,在许多现实应用中,获得高质量的GT数据需要付出高昂的代价。
本工作研究的问题是自监督图像CS重建,即在仅给定一批压缩观测值和采样矩阵的情况下,训练一个图像重建网络。现有方法对训练数据的利用不充分,设计的重建网络表征能力有限,导致其重建精度和效率仍然不足。
三、主要贡献
技术创新点1:一套无需GT的自监督图像重建网络学习方法。
如图1(a)所示,在训练过程中,我们将每组观测数据随机划分为两个部分和,并输入重建网络,得到两个重建结果和。我们使用以下观测值域损失函数约束网络产生符合“交叉观测一致性”的结果:
进一步地,如图1(b)所示,为了增强网络的灵活性和泛化能力,使其能够处理任意采样率和任意采样矩阵的重建任务,我们对和进行随机几何变换(如旋转、翻转等),得到数据增广后的和,然后使用以下图像域损失函数约束网络,使其符合“降采样—重建一致性”:
其中和、和,以及和分别是随机生成的采样矩阵、噪声和采样率。
最终,结合以上两个损失函数,我们定义双域自监督损失函数为。
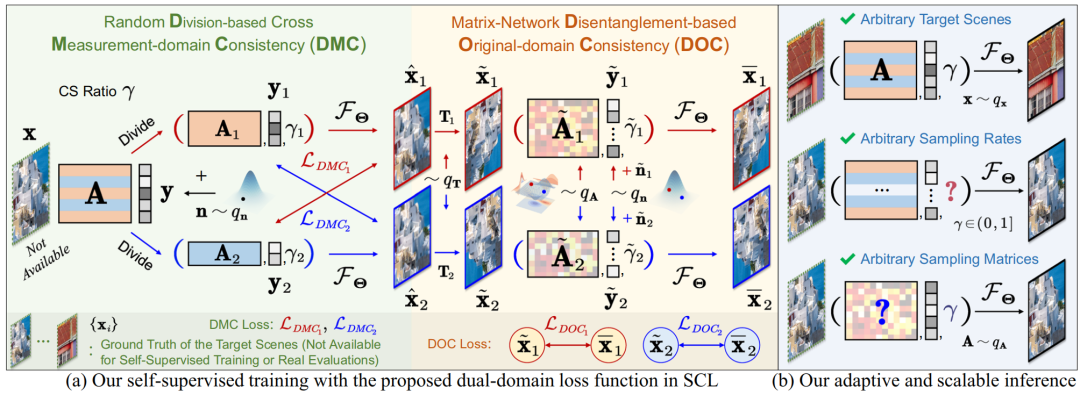 图1:提出的损失函数。
图1:提出的损失函数。
在训练阶段,我们使用以无需GT的自监督方式,学习一个支持任意采样率和采样矩阵的重建网络;在测试阶段,除了可以直接使用训练好的网络重建图像外,也可以使用在单个或多个测试样本上微调网络,以进一步提升重建精度。
技术创新点2:一个基于协同表示的图像重建网络。
如图2所示,我们设计的重建网络首先通过一个卷积层从观测值、采样矩阵与采样率中提取浅层特征,并依次注入可学习的图像编码和位置编码。接着,使用多个连续的深度展开网络模块对特征进行增强,每个模块对应于近端梯度下降算法的一个迭代步骤。最后,重建结果由一个卷积层和一个梯度下降步骤产生。
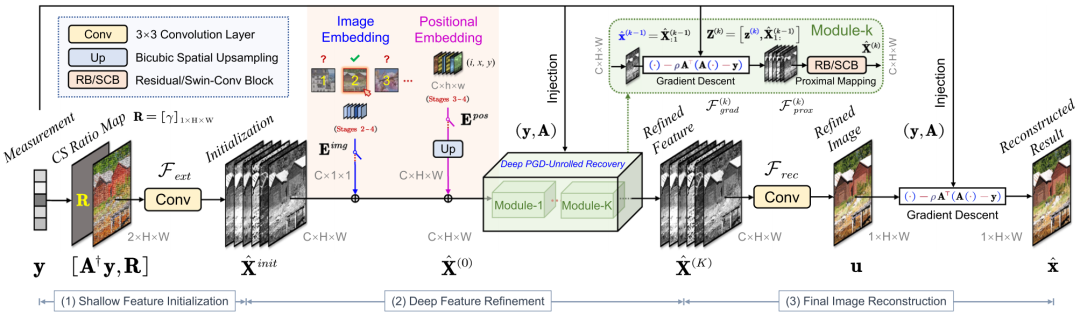 图2:提出的图像重建网络。
图2:提出的图像重建网络。
我们设计的重建网络结合了迭代优化算法的显式结构设计启发与神经网络模块的隐式正则化约束,能够自适应地学习待重建图像的深度协同表示,展现出强大的表征能力,在重建精度、效率、参数量、灵活性和可解释性等方面取得了良好的平衡。
四、实验结果
得益于提出的双域自监督损失函数与基于协同表示的重建网络,我们的方法在多个测试集(Set11、CBSD68、Urban100、DIV2K、我们构建的数据集)、多种数据类型(模拟/真实数据、1D/2D/3D数据)以及多个任务(稀疏信号恢复、自然图像压缩感知、单像素显微荧光计算成像)上均表现出优异的重建效果。同时,我们的方法展现出了对训练时未见过的采样矩阵与采样率的出色泛化能力。
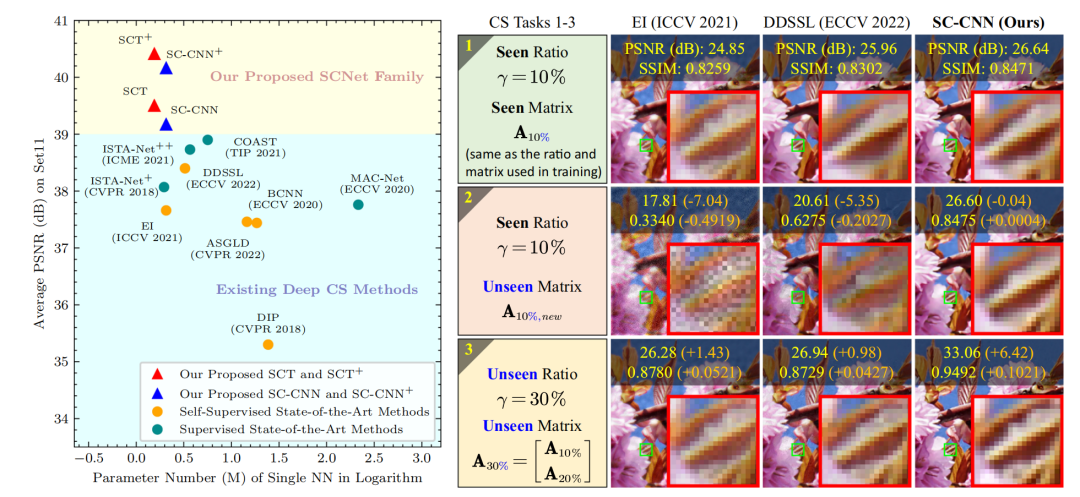 图3:我们的方法与现有其他方法的对比结果。
图3:我们的方法与现有其他方法的对比结果。
更多方法细节、实验结果与原理分析可参考我们的论文。
五、实验室简介
视觉信息智能学习实验室(VILLA)由张健助理教授于2019年创立并负责,专注于AI计算成像与底层视觉、可控内容生成与安全、三维场景理解等研究领域,已在Nature系列子刊Communications Engineering、SPM、TPAMI、IJCV、TIP、NeurIPS、ICLR、CVPR、ICCV和ECCV等高水平国际期刊和会议上发表了50余篇论文。
在计算成像与底层视觉方面,张健助理教授团队的代表性成果包括优化启发式深度展开重建网络ISTA-Net、COAST、ISTA-Net++,联合学习采样矩阵压缩计算成像方法OPINE-Net、PUERT、CASNet、HerosNet、PCA-CASSI,以及基于信息流增强机制的高通量广义优化启发式深度展开重建网络HiTDUN、SODAS-Net、MAPUN、DGUNet、SCI3D、PRL、OCTUF、D3C2-Net。团队还提出了基于自适应路径选择机制的动态重建网络DPC-DUN和用于单像素显微荧光计算成像的深度压缩共聚焦显微镜DCCM,以及生成式图像复原方法Panini-Net、PDN、DEAR-GAN、DDNM,受邀在信号处理领域旗舰期刊SPM发表专题综述论文。本工作提出的自监督重建网络学习方法SCNet进一步减少了训练重建网络对高质量GT数据的依赖。
更多信息可访问VILLA实验室主页(https://villa.jianzhang.tech/)或张健助理教授个人主页(https://jianzhang.tech/)。
(供稿人:陈斌,北京大学博士生)
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
















 1365
1365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









