






论文信息

摘要
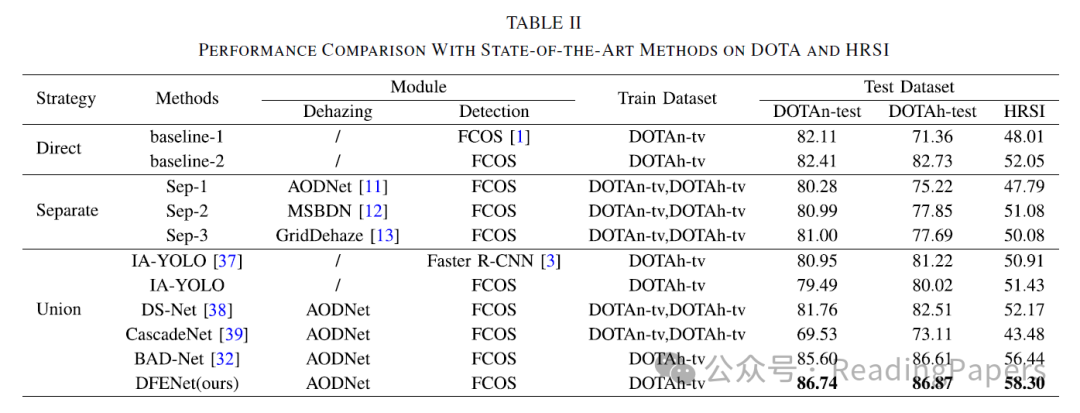
目前,大量工作集中在航空目标检测上,并取得了良好的结果。尽管这些方法在传统数据集上取得了有希望的结果,但在恶劣天气条件下捕获的低质量图像中定位对象仍然具有挑战性。目前,结合航空目标检测和雾天条件的方法有限,并且很少有基于真实雾天天气的航空图像的公开可用数据集。为此,我们提出了一个数据集HRSI,真实世界中的雾天遥感图像,主要分为三类:机场、大型车辆和船只。HRSI中的所有图像都来自真实的雾天条件。此外,我们提出了一个目标检测模型DFENet,适用于雾天的雾天遥感图像的去雾特征增强模型。DFENet由两个分支和一个去雾模块组成。两个分支结构有助于充分学习雾天和去雾特征。为了避免去雾模块引起的噪声影响,我们还设计了一个雾预测模块(HPM)来预测图像中包含雾的信息。我们引入了交叉融合模块(CFM),以利用雾的信息指导两个分支的特征融合。通过利用雾的信息,DFENet可以动态调整两个分支中的特征权重,避免去雾模块产生的噪声影响。与传统目标检测方法相比,DFENet不仅在雾天条件下具有良好的性能,而且也提高了晴朗条件下的性能。我们在DOTA、HRSI和Foggy-DOTA上测试了DFENet,证明DFENet在雾天条件下表现更好。
关键词
航空目标检测
雾天目标检测
弱监督
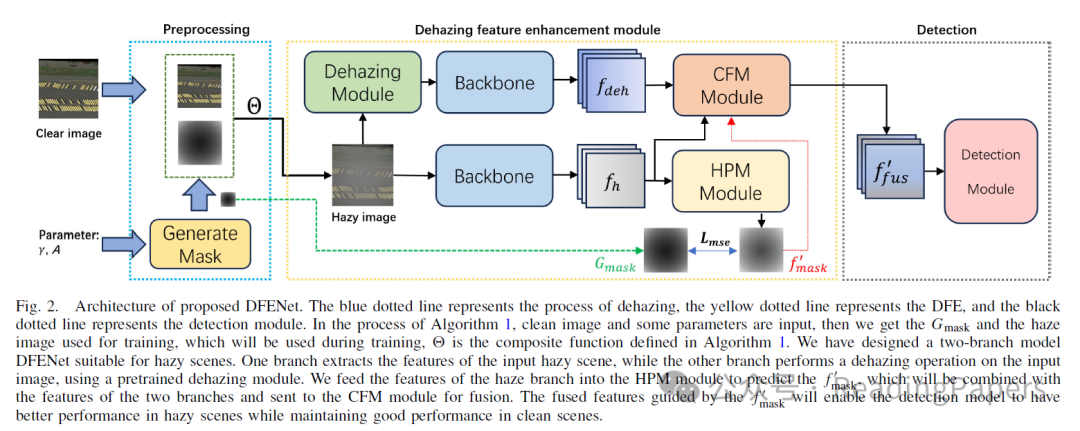
方法
A. 雾掩模
大气散射模型[36]通常用于量化雾天和清晰图像之间的关系,许多方法利用大气散射模型生成模糊图像,其公式如下:
其中 是雾天图像, 表示场景辐射率(清晰图像)。 是全局大气光, 是介质传输图,定义为
其中 表示大气的散射系数, 是场景深度
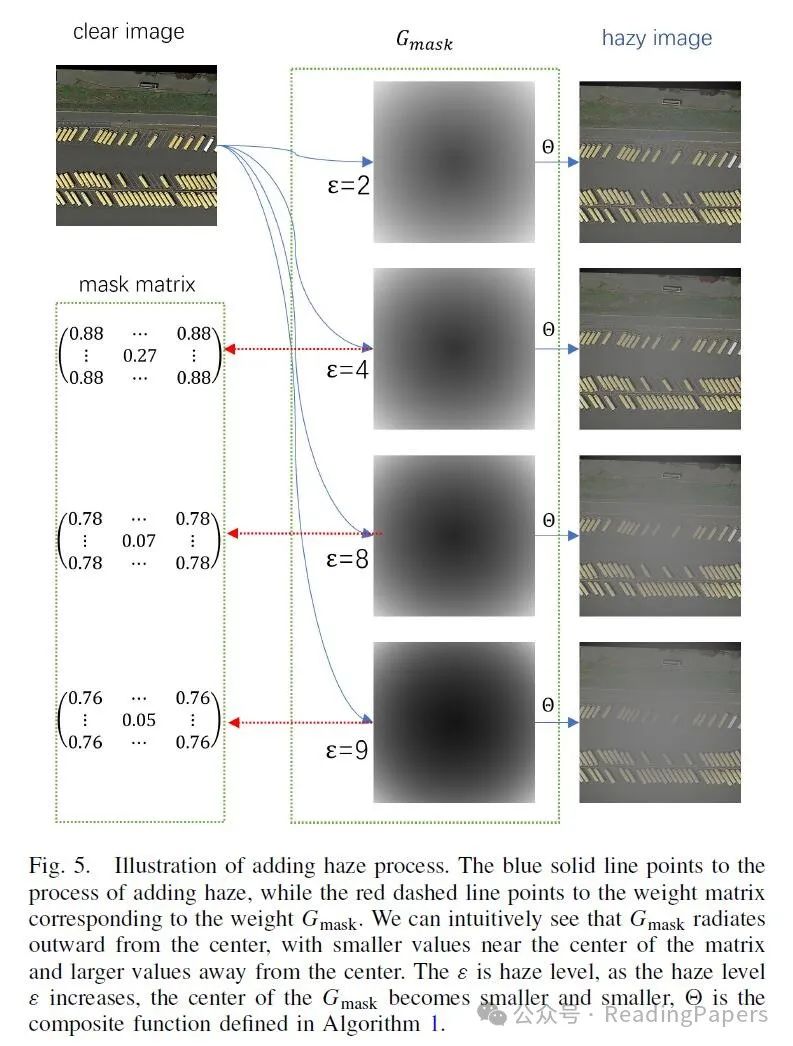
其中 是我们设置的基本散射系数, 是雾天级别,用于控制雾的浓度。通过控制不同的 值,我们可以获得对应不同雾浓度的
我们从上述公式中获得了对应不同浓度雾天天气场景的雾掩模 。基于此,我们从算法1中获得了雾掩模和复合雾天图像,这些雾掩模将在后续模块中使用。


B. 雾预测模块
基于大气散射模型,雾天图像可以被视为干净图像与雾层的融合。我们希望通过模型学习雾的信息,包括雾的位置信息和雾的浓度信息。首先,将模糊图像通过主干网络和FPN层处理以获得多层特征 ,其中 表示不同的层次。如图3所示,我们选择 和 ,它们分别包含图像的低级语义特征和高级语义特征。我们将 和 一起送入HPM模块,如图3所示, 和 各自通过一个卷积层,然后上采样 以获得 。我们将 和 在通道维度上进行连接以获得 。最后,我们对获得的 进行三次卷积操作,并用sigmoid激活以获得 。
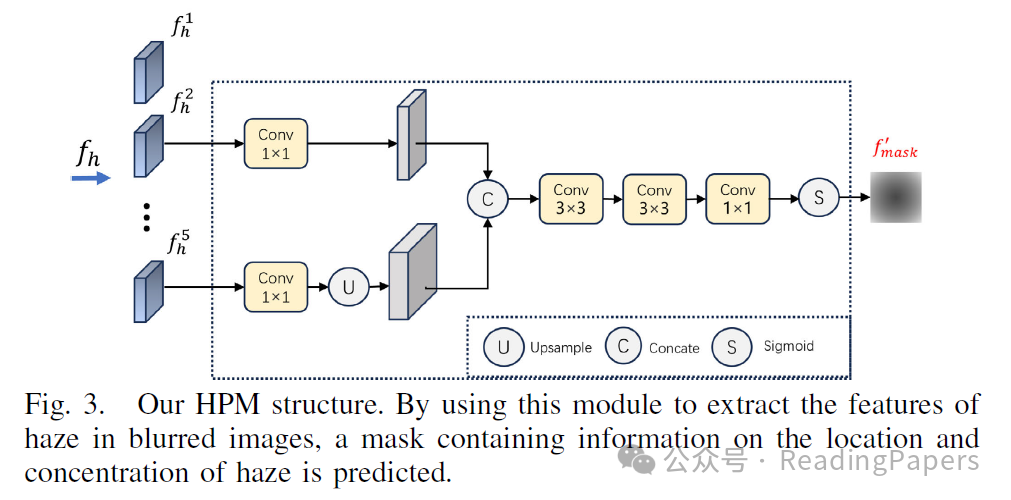
C. 交叉融合模块
我们设计了一个注意力模块来接收来自两个分支的深度特征。当去雾模块获得的特征丢失了原始图像的大量细节时,模型的性能将严重下降。为此,我们设计了一个交叉燃料模块,对雾密度高的区域给予较低的权重。此时,融合特征将更多地依赖于干净图像的特征。我们希望通过加权注意力平衡清晰和模糊图像之间的关系。如图4所示,我们将从HPM获得的 作为我们的雾注意力,在训练阶段我们使用真实的标签 而不是 。首先,我们融合从主干网络获得的两个特征,其公式如下:
其中 由添加雾算法获得的雾掩模引导,可以充分反映雾浓度的分布。当雾浓度较高时, 更依赖于 ,当雾浓度较低时, 更依赖于 。我们尝试以这种方式动态整合 和 ,以便模型可以避免去雾模块的噪声影响,即使输入图像中没有雾。 将发送到一个3×3卷积以获得初始融合特征 ,我们通过以下公式获得 :
其中Conv1D是1-D卷积, 是逐元素乘法, 表示Sigmoid激活函数。通过通道注意力模块,我们可以进一步减少冗余通道并抑制特征中的噪声。 将被送入检测器进行回归和分类。
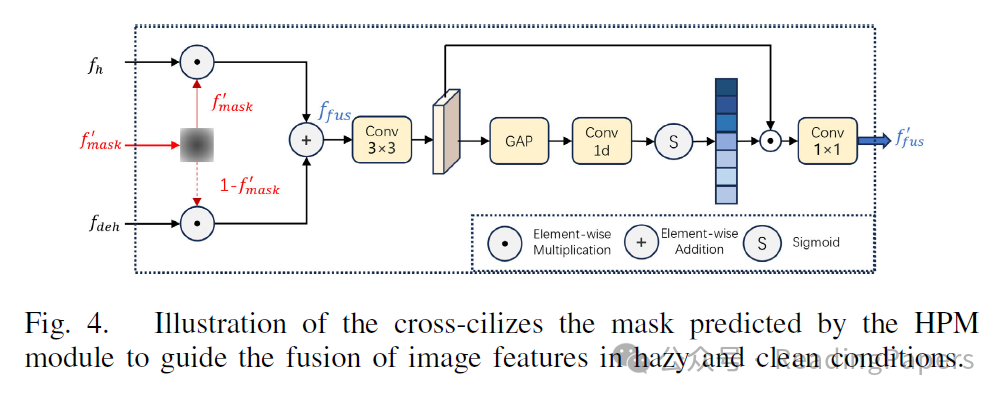
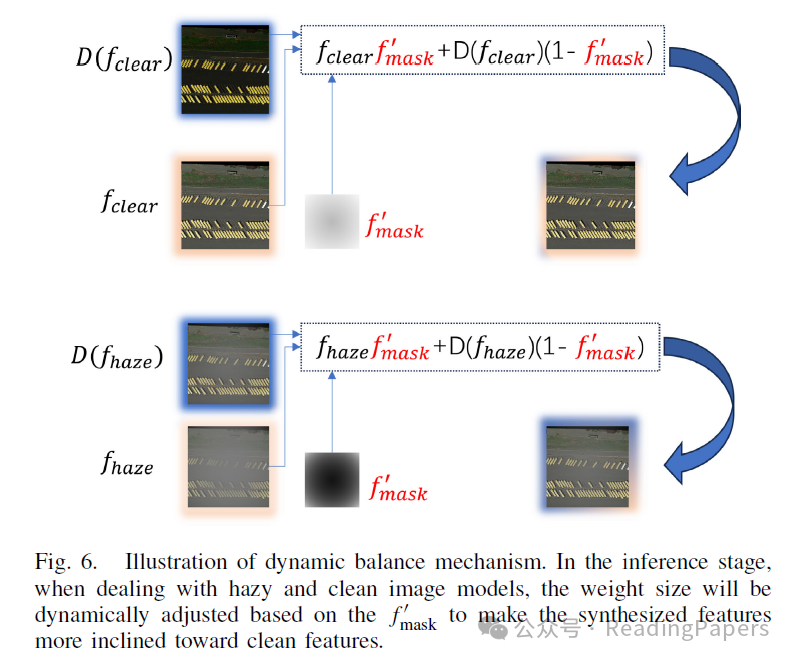
D. 动态平衡机制
我们在算法1中获得了 ,它是一个介质传输图,可以间接反映算法添加的雾的分布, 表示添加到当前图像中的雾的深度, 越大, 中心位置的权重越小。在训练过程中,每个输入的雾天图像对应一个独特的 。在图5中,我们可以看到 的权重从中心位置逐渐向外辐射。在训练过程中,我们可以使用 引导模型学习 的分布,而在推理过程中,模型可以通过HPM预测对应输入图像的 。在推理过程中,我们根据HPM预测的 平衡输入图像和去雾图像之间的特征融合。并根据以下公式合成特征:
其中 是去雾模块, 表示输入图像特征和去雾图像特征的融合特征。在图6中,我们可以看到输入雾天图像时获得的融合特征 会导致HPM预测的 权重较小, 将更倾向于去雾后的图像特征。当输入图像是清晰图像时,模型预测的 权重较大, 倾向于更倾向于清晰图像本身的特征,从而减少去雾后的清晰图像特征的影响。
G. 雾天遥感数据集
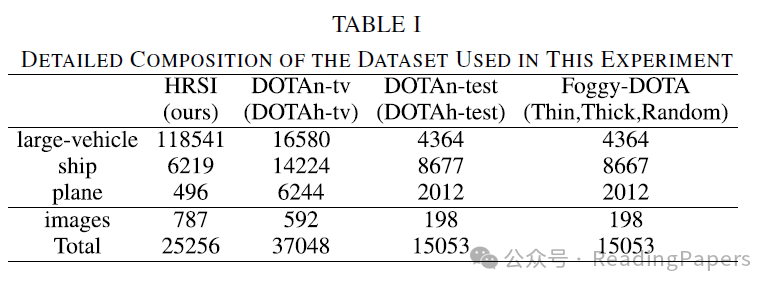
据我们所知,目前世界上公开可用的雾天遥感图像数据集很少。因此,我们提出了一个包含796张图像的HRSI数据集,大小从512×512到4000×4000不等,包括各种卫星放大倍数、方向和形状的图像。所有图像都因雾天条件差而模糊。对于特别模糊的图像,我们有多名注释者共同判断。我们在HRSI数据集中主要注释了三个类别:大型车辆、船只和飞机。这三个类别是主要的交通工具类别。对于飞机类别,我们主要选择机场的客机。对于船只类别,我们主要选择运河里的货船和邮船。对于大型车辆,我们主要选择卡车、公共汽车和卡车。我们主要从汽车站、码头、河流和机场收集图像。所有图像的像素到实际地图的比例是93:0.71(像素:米)和93:1.78(像素:米)。在浏览了大量遥感图像之后,我们进行了严格的筛选,主要选择由雾天场景引起的退化图像,大部分对象都是模糊或被雾遮挡。对于难以辨认的对象,我们已经适当地丢弃了一些。对于模糊的对象,多名工作人员将共同注释。此外,图7展示了HRSI的其他细节。在注释框方面,我们选择了与DOTA相同的OBB注释,OBB回归有五个值(x、y、w、h、a),而HBB回归有四个值(x、y、w、h),其中x和y代表边框的中心点位置,w和h代表边框的长度和宽度,a代表边框的旋转角度。OBB比常规HBB多一个角度信息,飞机、船只和卡车的形状主要是常规矩形,遥感图像中的对象具有高密度特征。直接使用非角度边框将导致边框重叠更大。因此,我们使用与DOTA一样的倾斜边框进行注释,这已被证明优于遥感图像领域的HBB型注释框,更适合遥感方向的目标检测任务。HRSI数据集的具体组成可以在表I和图8中找到我们提出的HRSI样本。


实验


声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与我们联系,我们将在第一时间回复并处理。


















 756
756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









