






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本篇分享论文
Self-Supervised Learning for Image Segmentation:A Comprehensive Survey
,自监督学习在图像分割中的全面综述。

论文地址:https://arxiv.org/pdf/2505.13584
图像分割与自监督学习背景
图像分割是将图像中像素按语义或实例划分的核心视觉任务,广泛应用于医学成像、智能交通、农业监控等领域。传统方法多依赖手工特征(如阈值、区域生长、GraphCut等)完成分割,但受限于特征表达能力。
深度学习时代兴起后,基于卷积神经网络(如FCN、U-Net、DeepLab等)的监督分割方法取得了显著进展,但需要大量像素级标注,标注成本高昂。为降低对标注的依赖,自监督学习(SSL)通过设计预设任务利用海量未标注数据学习有用特征表示,成为缓解标注瓶颈的有效范式。
SSL 在分类、检测和分割等下游任务中表现突出,尤其在语义分割任务上潜力巨大。因此,对现有SSL分割方法的综述有助于跟踪进展、启发新研究。
方法演进:传统、监督与自监督
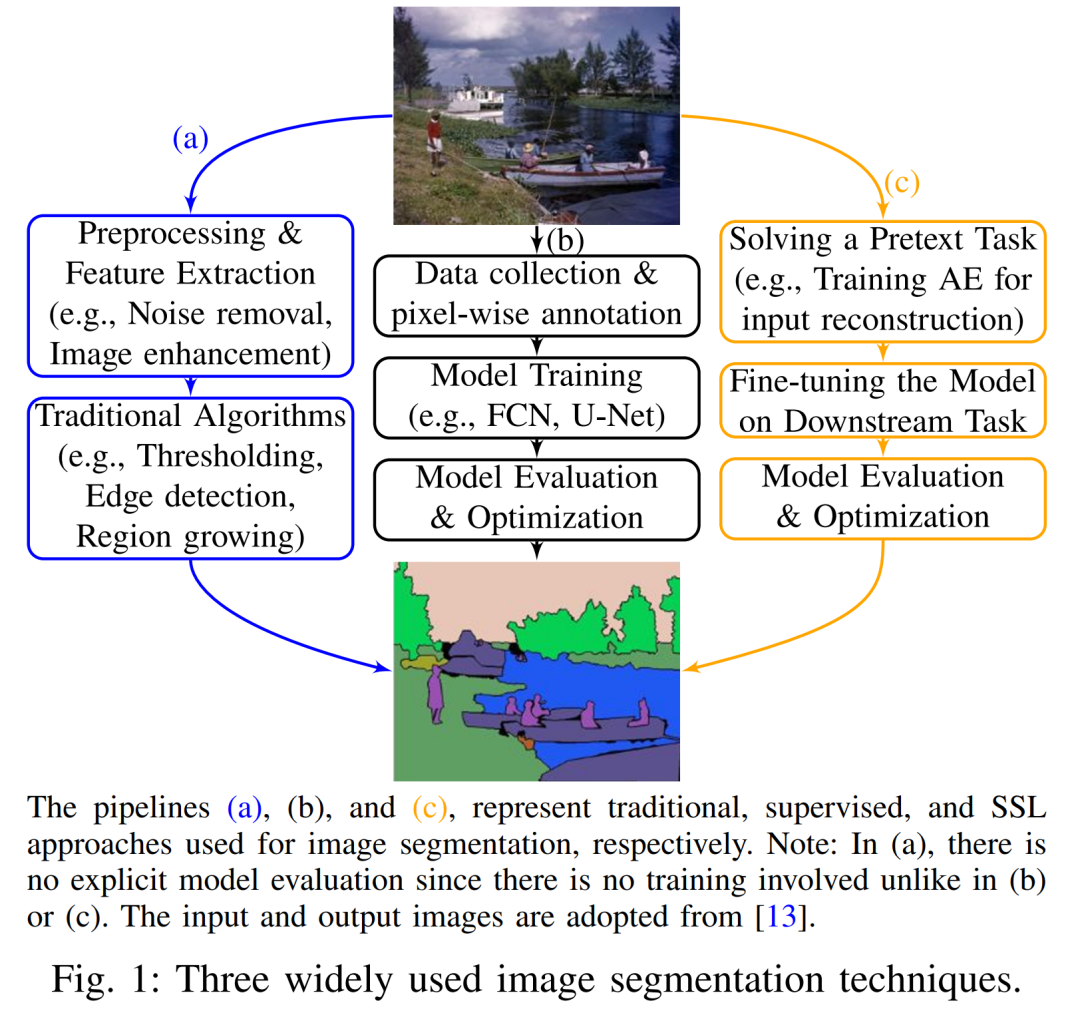
传统图像分割方法主要基于低级特征或统计假设,例如阈值分割、图像分割算法(如SLIC超像素)、能量最小化(GraphCut、随机游走)等。这些方法易受噪声影响,泛化能力有限。
随着深度学习兴起,端到端的监督分割方法迅速普及:FCN(全卷积网络)首次实现了像素级分割,U-Net 系列在医学分割中表现优越,DeepLab系列结合空洞卷积和CRF获得高精度结果等。这些方法依赖大量标注:监督学习“需要大量精确标注的数据才能取得良好的结果”。
相比之下,自监督学习通过构造无需人工标注的预设任务学习图像表示。SSL 预训练的网络可以在下游分割任务中快速迁移或微调,减少对标注的依赖。
由此形成了从传统手工方法 → 大规模监督分割 → 自监督表征学习的演进:自监督分割方法利用无标注数据缓解标注成本,为图像分割开辟了新路径。
图像分割的三个子任务及SSL策略

图像分割任务旨在为图像中每个像素赋予标签,示例如上图将桌面场景中的像素按语义区域进行了不同颜色编码。
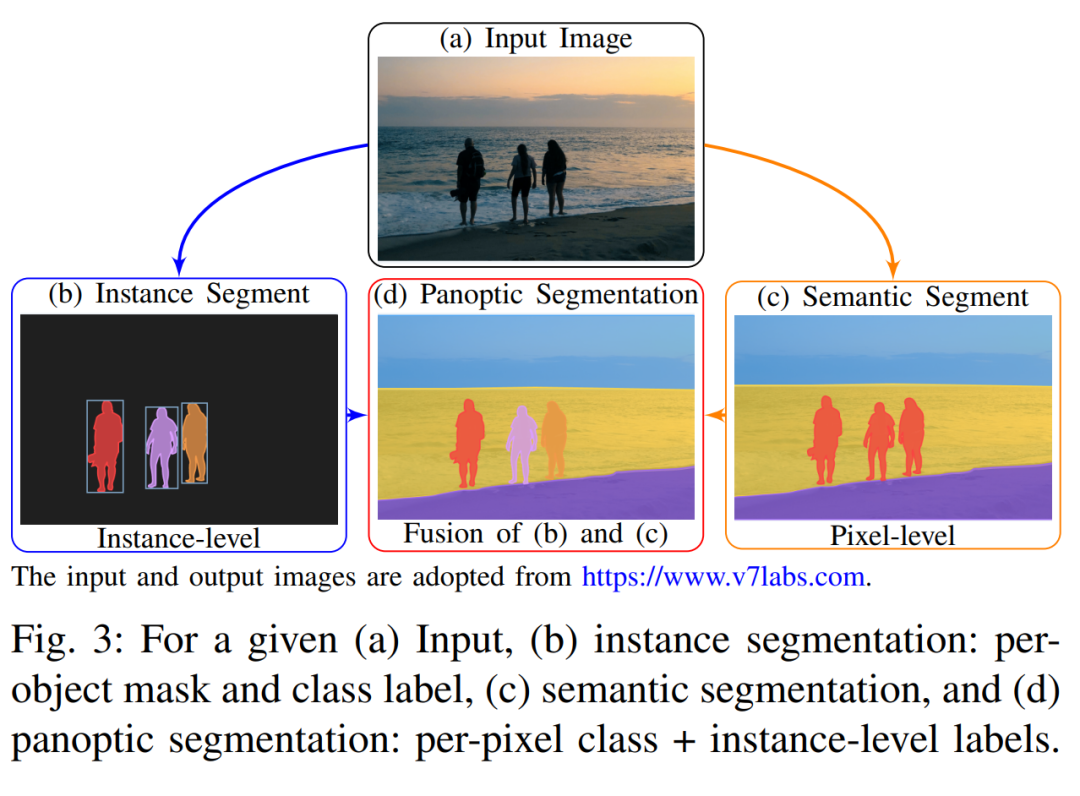
实例分割(Instance Segmentation)需要同时检测每个可数物体并生成对应掩码,对每个物体实例独立分割;
语义分割(Semantic Segmentation)则仅区分像素类别,为每个像素赋予类别标签,不区分实例;
全景分割(Panoptic Segmentation)将两者统一:对「可数物体(things)」执行实例分割,对「不可数区域(stuff)」执行语义分割。
Kirillov 等定义全景分割为统一输出完整场景分割的方法,并提出Panoptic Quality(PQ)度量同时评估这两类分割性能。
针对这三类任务,SSL策略主要集中在学习通用特征并适配不同分割需求。通常的做法是先用SSL任务对卷积骨干网络进行预训练,再在有或少量标注的分割数据上微调。对语义分割而言,通过像素级自监督任务(如CPC的密集预测、生成型补全等)可获得更精细的特征,有研究将局部对比学习(如PixelContrast、DenseCL等)应用于密集分割。
实例分割任务则可能结合区域级的SSL任务,例如利用对比学习或伪标签生成来学习实例级特征。全景分割需要兼顾语义与实例信息,当前主要依赖从SSL获得的强大特征表示,再通过多任务网络输出对应分割结果。
总的来看,SSL方法在分割任务中一般作为特征提取层的预训练手段,其输出特征为后续分割头提供更好的初始条件,从而提高分割准确度和数据效率。
自监督预训练任务分类
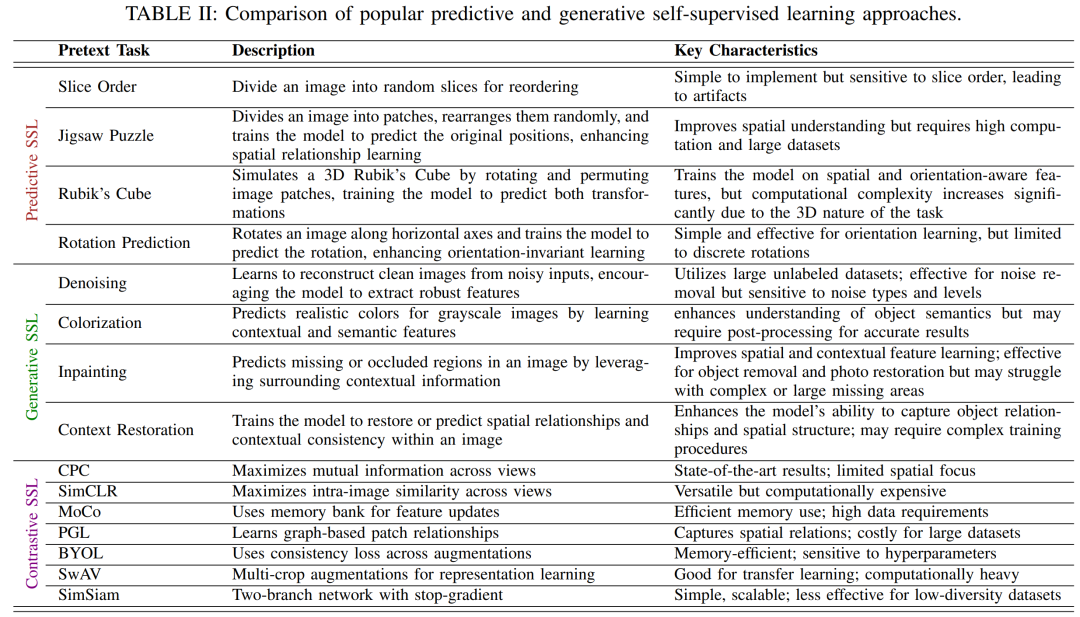
自监督预训练任务大致分为三类:预测型(Predictive)、生成型(Generative)和对比学习(Contrastive)。每类包含多种代表性任务及相应损失函数:
预测型方法
通过预测图像某种属性或重排来学习表示,通常使用交叉熵损失。代表性任务包括:
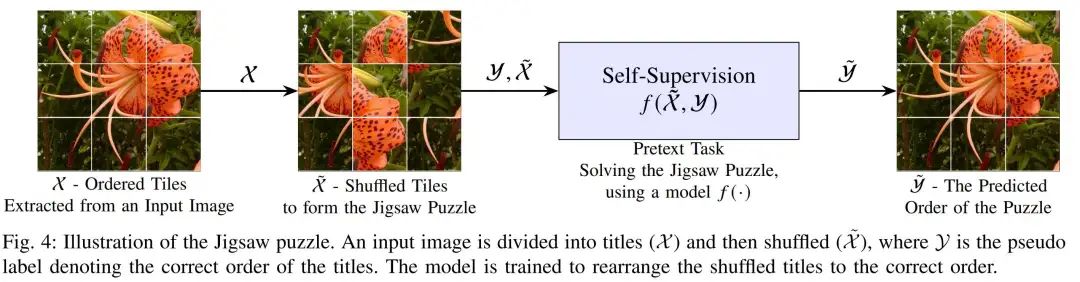
拼图(Jigsaw):将图像划分为多个补丁并随机打乱顺序,模型学习还原正确顺序。Noroozi 等设计了Context-Free Network(Unsupervised learning of visual representations by solving jigsaw puzzles,ECCV 2016),对每个打乱的九宫格图像块进行处理,使模型学习物体部件与空间关系。损失为预测每个补丁的正确位置的交叉熵。
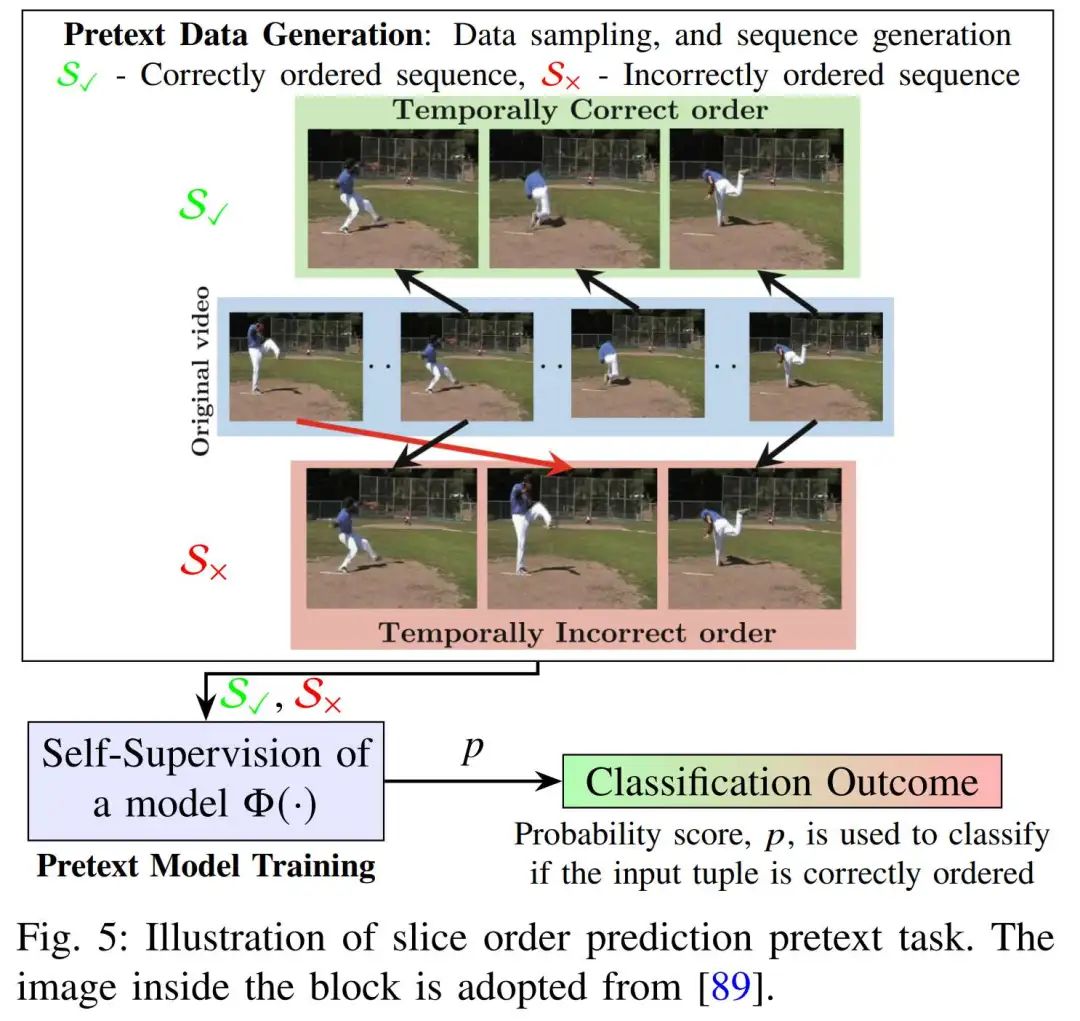
切片顺序预测(Slice Order Prediction):切片顺序预测是一种典型的预测型自监督任务,主要应用于处理具有体积信息的图像数据(如CT、MRI等3D医学图像)或视频序列。在该任务中,模型被训练用于判断一组图像切片或帧是否处于正确的顺序,从而迫使网络学习时序或空间结构特征,代表如Misra(Shuffle and learn: unsupervised learning using temporal order verification,ECCV 2016)的工作。
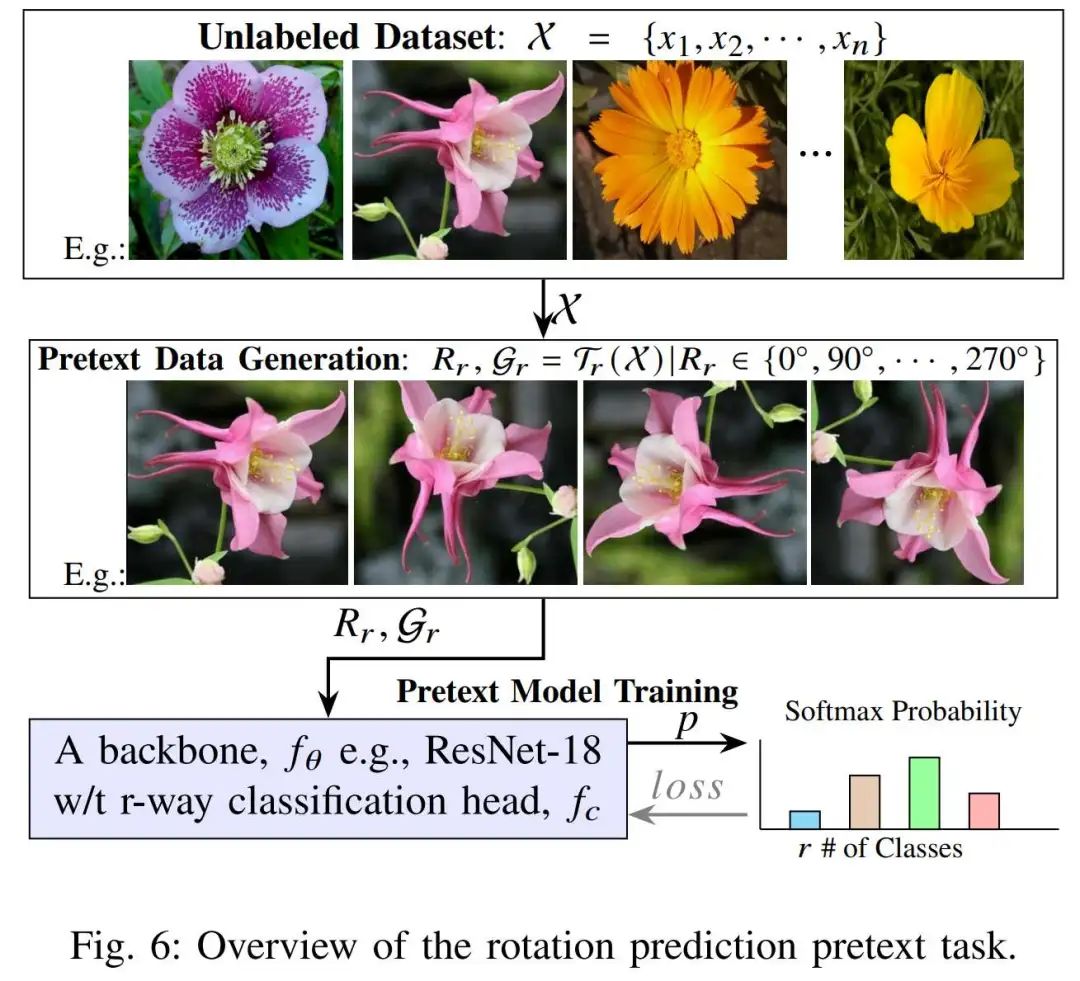
旋转预测(Rotation):Gidaris 等(Unsupervised representation learning by predicting image rotations,ICLR 2018)提出对图像随机旋转0°、90°、180°、270°后让网络预测角度标签。该简单任务强制网络学习几何和语义特征,训练使用4类交叉熵损失,实验表明能显著提升特征质量。
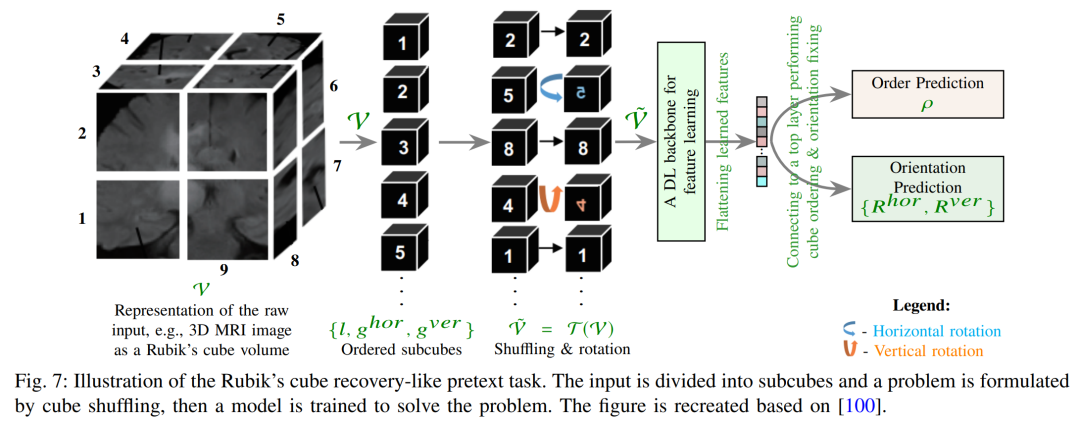
魔方重排(Rubik’s Cube):Zhuang 等(Selfsupervised feature learning for 3d medical images by playing a rubik's cube,MICCAI 2019)将3D医学体数据视为「魔方」,对体素网格块进行重排,并训练网络恢复原始体块顺序。此任务可扩展2D拼图思想,尤其适合医学体数据。后来版本(Rubik’s Cube++)通过同时预训练上采样和下采样模块改进效果。损失一般为预测每块正确位置的分类损失。
生成型方法
通过生成或恢复图像内容来学习表示,多采用像素级重建损失(如均方误差)或对抗损失。常见任务有:
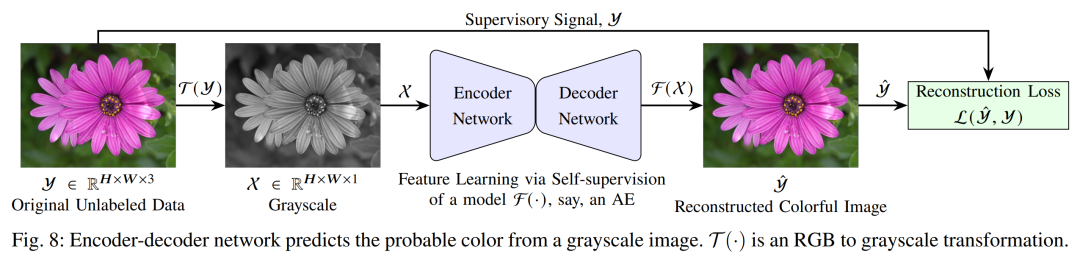
图像上色:将彩色图像转为灰度输入,让网络预测色彩。Zhang 等(Colorful image colorization,ECCV 2016)将颜色量化为离散类别并使用交叉熵回归,生成具有多样性的彩色化效果。实验表明,色彩化作为预训练任务可学习到丰富的语义信息。
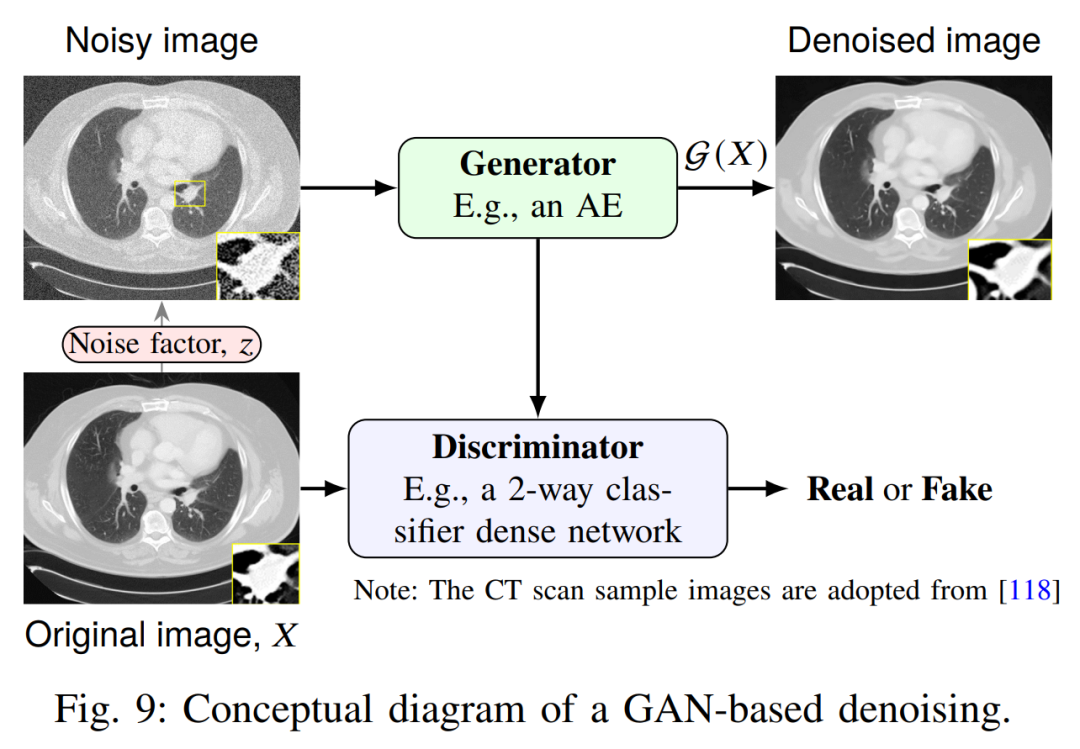
图像去噪:使用去噪GAN或者自动编码器(Denoising Autoencoder,DAE),即对输入图像加入噪声后,训练网络重构无噪图像。Vincent 等将此思想堆叠在深层网络中,利用均方差(MSE)损失提高表示鲁棒性。
图像补全(Inpainting):Pathak 等提出在图像上遮盖一块区域,要求生成缺失部分,类似拼图填空。训练时可使用像素重建损失和对抗损失,使生成区域既与上下文一致又语义合理。Context Encoders 等验证了此任务学习到的特征具备语义结构知识(Context encoders: Feature learning by inpainting,CVPR 2016)。
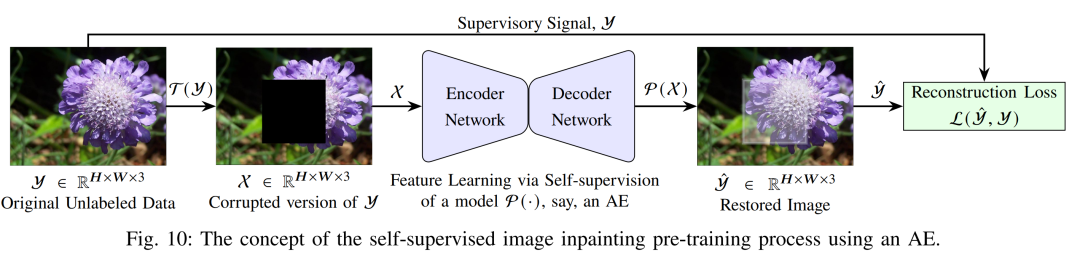
上下文还原(Context Restoration):旨在迫使模型从扰乱后的图像中学习重建其原始结构,从而获得对图像整体语义与结构布局的理解。与图像补全(inpainting)不同,上下文还原不对图像进行随机遮盖或填充空洞,而是通过交换图像中的两个非重叠区域,从而打乱其上下文,再训练模型恢复原貌。

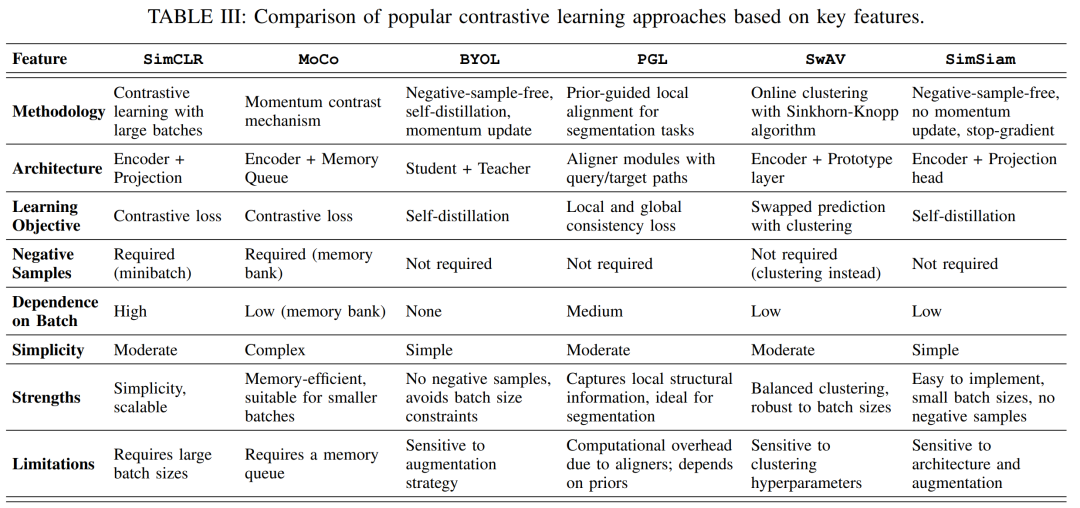
对比学习方法
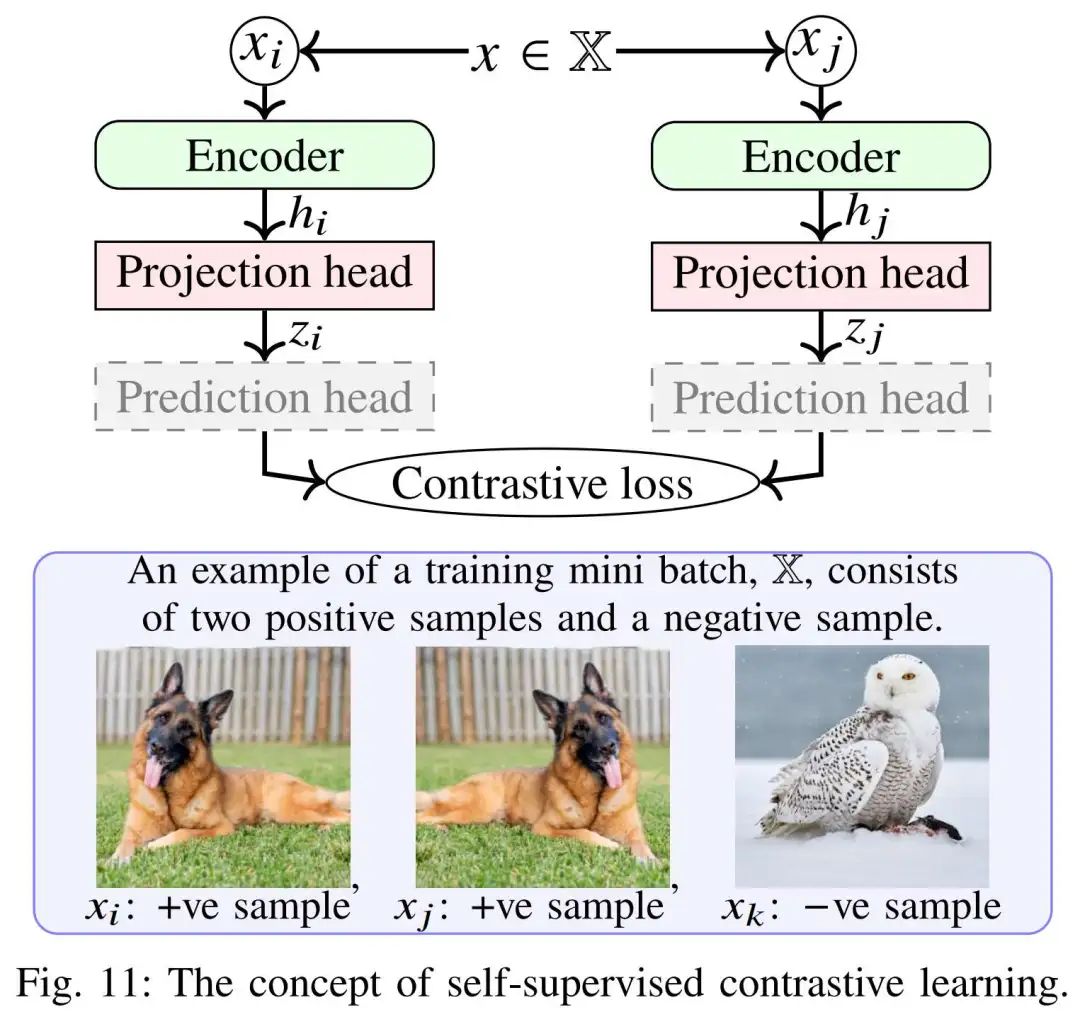
通过拉近(正例)和推远(负例)样本对的特征距离来学习表示,多用 InfoNCE 等对比损失。典型方法有:
对比预测编码(CPC):Oord 等提出在高维数据中预测未来特征表示。基本思想是:对图像或序列的不同片段编码后,利用自回归模型在潜在空间预测未来特征。为使预测可解,采用对比损失(InfoNCE)区分正确预测与随机负样本。对CPC的改进将其用于图像分割:针对图像空间划分重叠块并学习上下文预测,通过Dense/Local方案实现像素级表示学习。
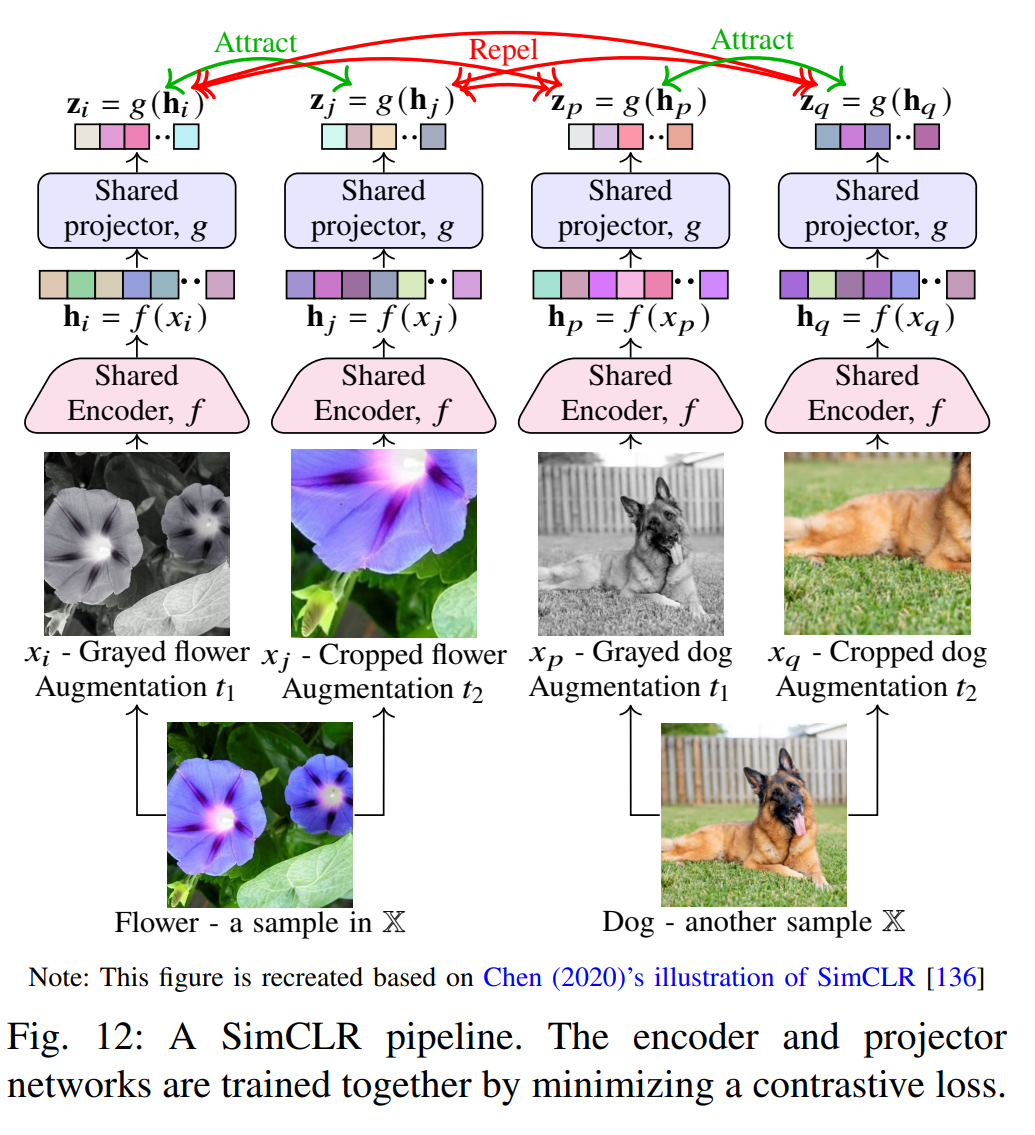
SimCLR:Chen 等提出了一个简化的对比学习框架。SimCLR 对同一图像施加两种随机强变换生成正样本对,其它不同图像构成负样本。使用交叉对比损失最大化正样本对特征相似度。实验表明,通过组合合理的增强策略和较大批次,对比学习可以在ImageNet上获得与监督训练相当的特征质量。
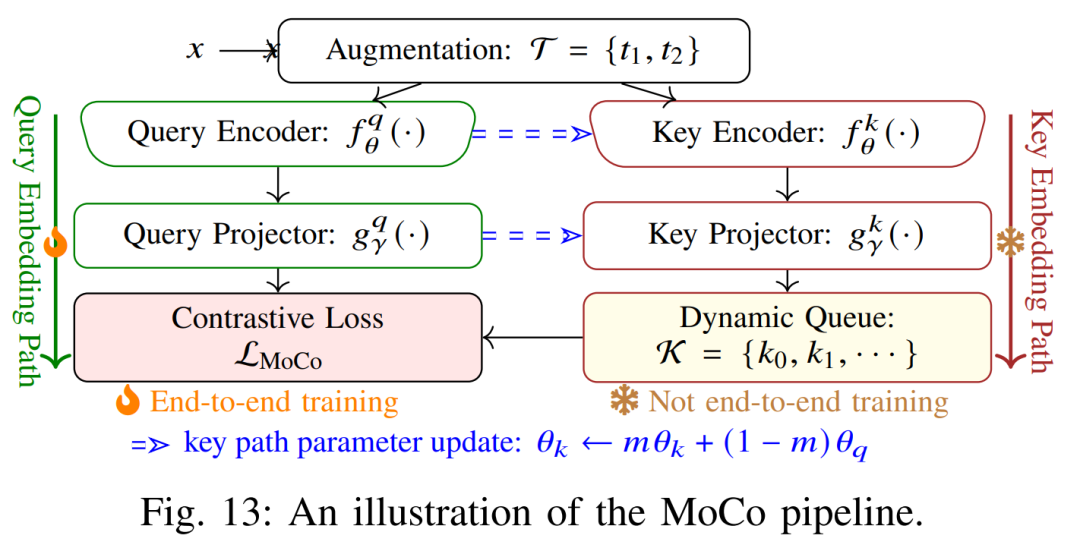
MoCo/BYOL/SwAV 等:尽管本综述侧重三类任务,上述方法后续涌现了动量对比(MoCo)、自举对比(BYOL)、SwAV(交换视图聚类)等改进,它们均围绕实例对比或聚类学习进一步提升表示能力,但核心思想仍是最大化相似视图间一致性。
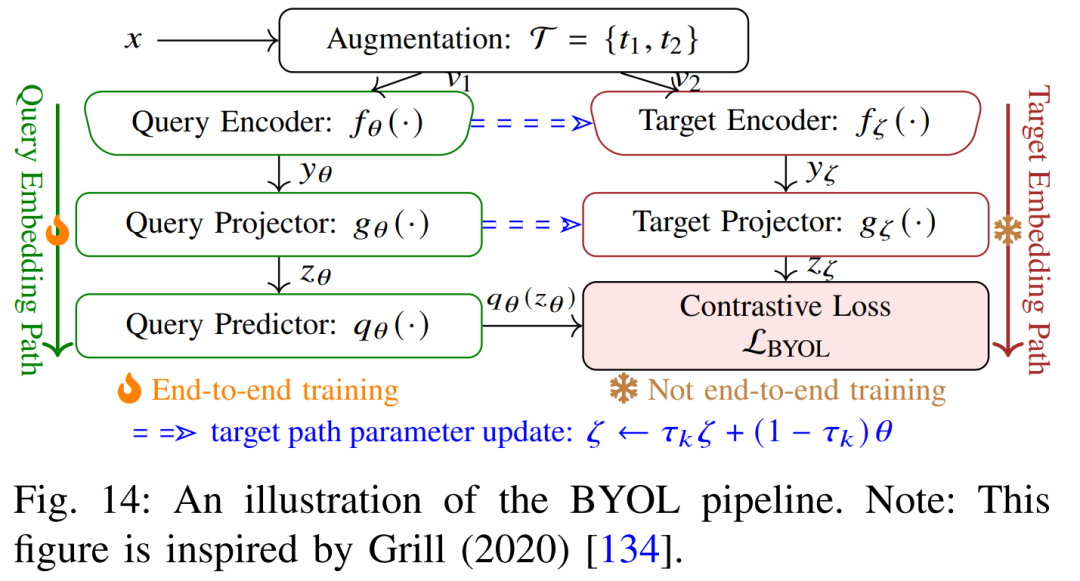
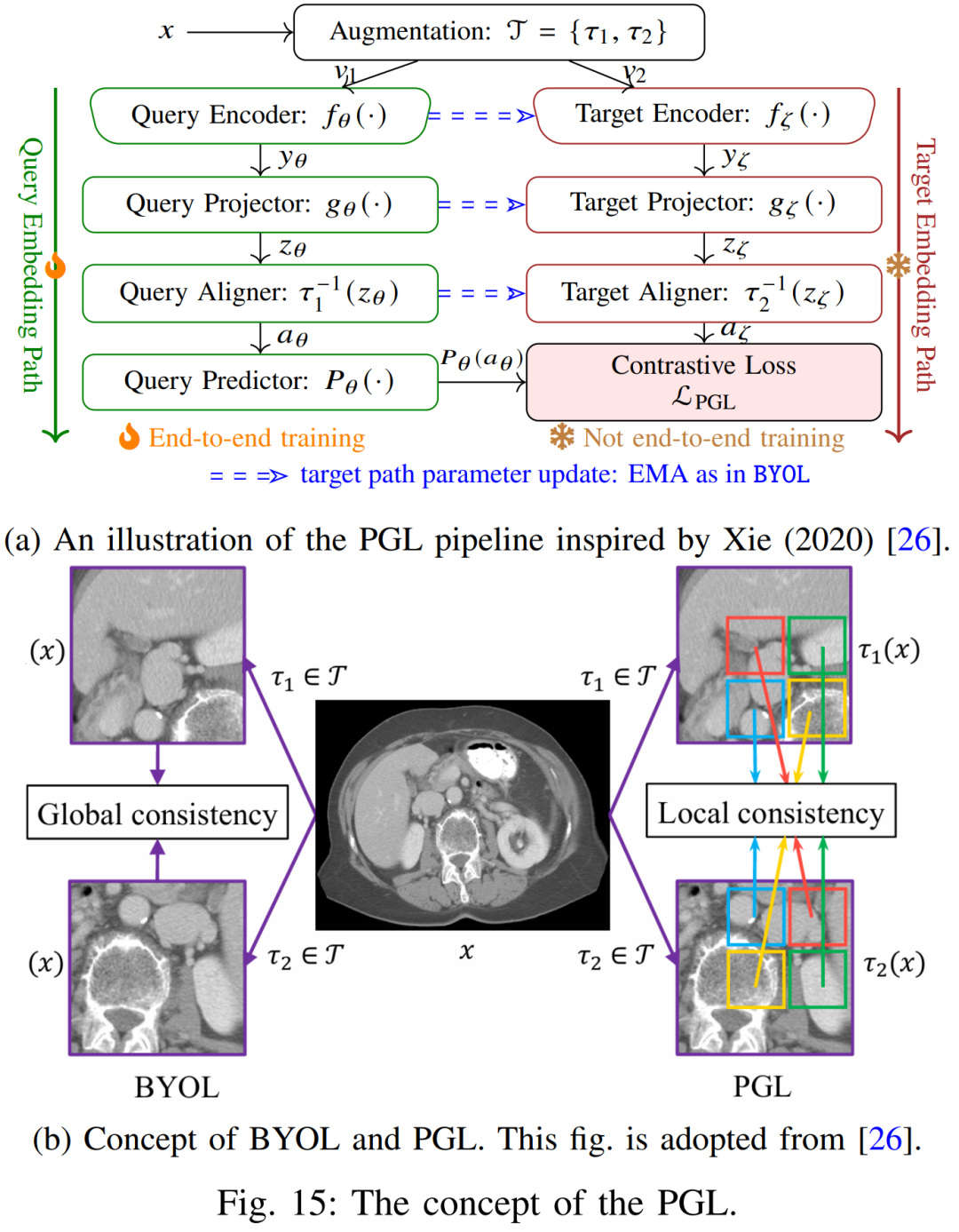
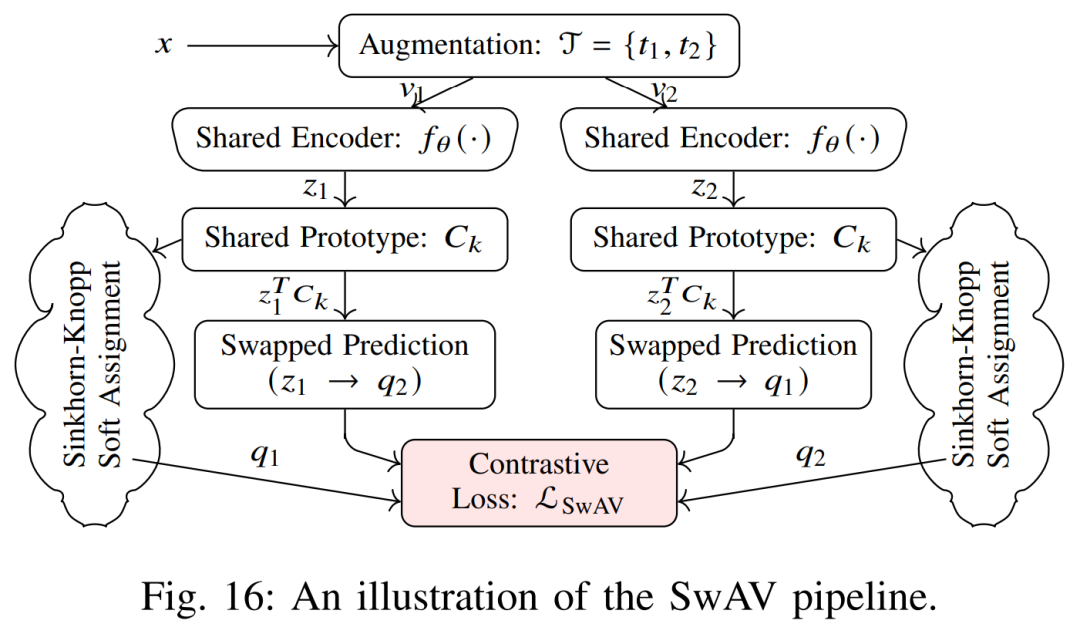
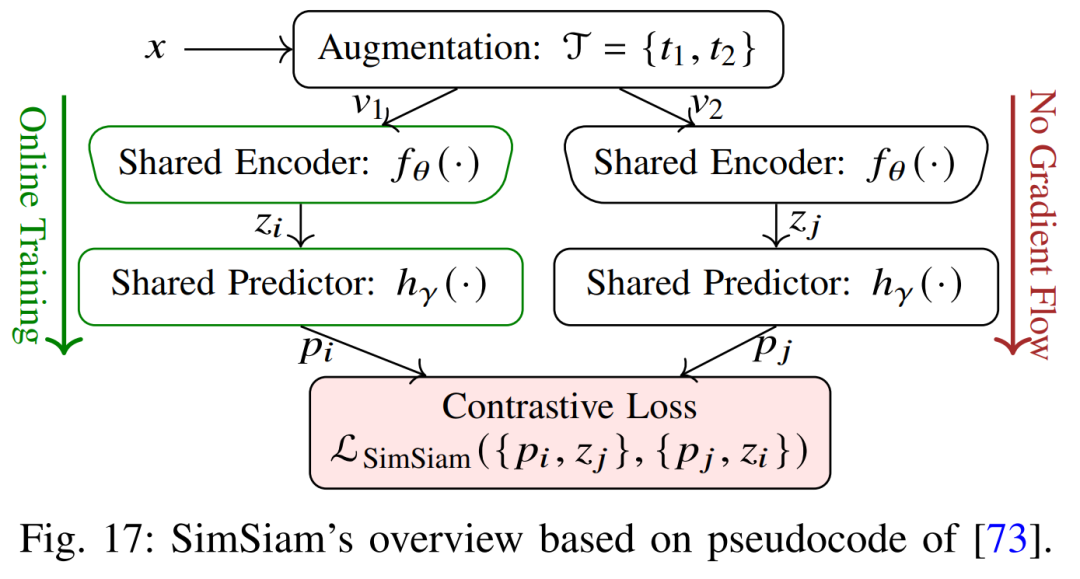
以上自监督任务各有特点:预测型任务通过明确定义的几何/位置目标逼网络捕捉图像结构;生成型任务通过图像重建和补全激励网络捕捉像素级语义与纹理;对比学习则侧重学习判别性特征以区分样本。常见损失包括分类交叉熵、L2重建误差、信息熵式对比损失等。它们已在分类、目标检测等领域取得成功,也被应用于分割预训练中,例如使用CPC/SimCLR预训练后再微调分割网络。
基准数据集与评估指标
SSL分割算法常用的基准数据集与评估流程沿袭传统分割研究。典型语义分割数据集包括PASCAL VOC型(20类目标+背景),Cityscapes型(19类城市场景),ADE20K(150类场景),它们的性能通常以平均交并比(mean IoU)衡量。

Cityscapes数据集官网明确使用Jaccard指数(IoU=TP/(TP+FP+FN))作为像素级分割的主要评价指标。实例分割任务一般使用COCO评测指标,即对生成的掩码计算AP(Average Precision),综合不同IoU阈值的平均精度(mAP)评估检测与分割质量。全景分割评测则使用PQ指标,将每个类的实例匹配后计算检测质量(Panoptic Quality)。此外,一些应用还引入其他指标,如加权IoU(iIoU)评估对小物体分割的精度。
实验流程通常为:用未经标注或少量标注的图像进行SSL预训练,再在有标注的分割数据集上微调网络,最后在测试集上报告上述指标。
挑战与未来方向
尽管SSL已显著提升了分割预训练效果,但仍面临若干挑战。
首先,许多对比学习方法(如CPC)倾向学习局部纹理特征,对长程上下文捕捉较弱。CPC等方法过分聚焦局部块预测易过拟合低级模式,在需要整体场景理解的任务中表现有限。
其次,计算开销大:对比损失需要大量负样本,密集SSL方法如像素对比计算开销高。生成式预训练(如GAN、AE)虽然可获全局上下文,但其重建损失在学习高层语义上有时不够区分度。此外,数据和任务差异也是难点:2D自然图像上的SSL策略在3D医学或其他域上直接应用存在性能下降,需要根据数据属性设计新的预设任务。
最后,对比学习中负样本挖掘、歧义样本处理等问题,以及语义分割中特有的类别不平衡、细节保护等,也为SSL研究提出了新的要求。
未来研究方向包括:设计更贴近分割任务需求的自监督任务,例如结合几何/语义信息的多任务SSL或加入少量弱标签的半监督训练;探索Transformer等新架构下的SSL(例如ViT与自监督分割结合);利用多模态(RGB-D、光谱)数据进行对齐式SSL;发展新的无监督分割评价指标和大规模无标签数据集;以及将对比与生成方法有机结合,实现更有效和高效的表示学习。随着SSL理论和技术的深入,预计会出现更多跨领域、跨任务的自监督分割方案。
最新 AI 进展报道
请联系:amos@52cv.net
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~



















 5717
5717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









