







 本文介绍了自回归模型在机器学习中的应用,包括最大似然估计、RNN、基于掩码的模型如MADE和PixelCNN。这些模型用于概率分布的学习和高维数据生成,讨论了它们的优缺点以及在图像和音频领域的应用。WaveNet和PixelCNN通过特殊的卷积结构增强了模型的表达能力和感受野。
本文介绍了自回归模型在机器学习中的应用,包括最大似然估计、RNN、基于掩码的模型如MADE和PixelCNN。这些模型用于概率分布的学习和高维数据生成,讨论了它们的优缺点以及在图像和音频领域的应用。WaveNet和PixelCNN通过特殊的卷积结构增强了模型的表达能力和感受野。
Lecture2 Autoregressive Models
Lecture2的主要内容是自回归模型,主要包括:
- Motivation
- Histogram
- Neural Autoregressive models
- Parameterized distributions and maximum likelihood
- Autoregressive models
- RNN
- Masking-based models
Likelihood-based Model
基于似然的模型主要做的一件事情是:根据数据集 { x ( 1 ) , … , x ( n ) } \{x^{(1)},\dots,x^{(n)}\} { x(1),…,x(n)}学习一个概率分布 p d a t a p_{data} pdata。 学习到的 p d a t a p_{data} pdata应该满足:
- 我们可以得到任意sample x x x的概率密度 p ( x ) p(x) p(x)
- 我们可以从概率分布中采样出一个 x x x
但是我们所处理的数据通常都是高维的,例如一张 128 × 128 × 3 128\times128\times3 128×128×3的彩色图像,他的维度大约是 50000 50000 50000。因此我们还希望我们的模型具有以下几个特点:
- 训练过程高效
- 模型表达能力强、泛化性强
- 生成数据的质量高、速度快
- 压缩率高、速度快
Histogram
最简单粗暴的方法就是根据训练集画一个直方图,我们只需要知道每个特征有哪些不同的取值然后计算frequency当作probability即可
根据直方图模型,我们可以轻松的进行以下两个操作:
- Inference:给定一个 x x x,求 p ( x ) p(x) p(x)。可以直接看图说话
- Sampling:根据CDF生成 x x x。可以通过以下几步完成
- 首先计算出CDF: F i = ∑ j = 1 i p ( j ) i ∈ { 1 … k } F_{i}\ =\ \sum_{j=1}^{i}p(j)\ \ \ \ \ i\in \{1\dots k\} Fi = ∑j=1ip(j) i∈{ 1…k}, k k k是特征不同取值的数量
- 随机生成一个 0 0 0到 1 1 1之间的数 u u u
- 返回最小的 i i i满足 F i ≥ u F_i \ge u Fi≥u
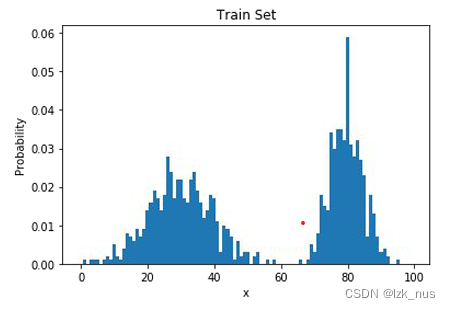
然而,直方图模型最显而易见的缺点就是它无法应用在高维数据上。另一个问题就是他的泛化能力差,毕竟直方图是完全按照训练集的数据分布进行拟合,因此是很明显的过拟合,模型的方差会很大。我们想要的分布应该是如下图这种:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hxpQ4d90-1672626993845)(L2 Autoregressive Model.assets/image-20221215083243305.png)]](https://i-blog.csdnimg.cn/blog_migrate/2cc7415f9850a76c368561488f7da06d.png)
Likelihood-based Generative Model
为了克服histogram有的问题,我们引入一个参数 θ \theta θ,让模型学习一个基于参数 θ \theta θ的概率分布 p θ ( x ) p_{\theta}(x) pθ(x)并且要求 p θ ( x ) p_{\theta}(x) pθ(x)和 p d a t a ( x ) p_{data}(x) pdata(x)越接近越好,这其实就是大多数ML模型在做的事情。
如何训练模型?我们需要定义一个损失函数,最优的参数应该满足最小化损失函数,即
θ ∗ = a r g m i n θ l o s s ( θ , x ( 1 ) , x ( 2 ) , … , x ( n ) ) \theta^{*}\ =\ argmin_{\theta}\ \ \ loss(\theta,x^{(1)}, x^{(2)},\dots,x^{(n)}) θ∗ = argminθ loss(θ,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7319
7319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









