







这里写自定义目录标题
- 参考资料
- 比较和分类
- 基础知识
- 16.3 有模型学习
- 16.4 免模型学习
- 16.5 值函数近似
- 16.6 模仿学习
- 深度Q网络算法
- 策略梯度 Policy Gradients
- Actor-Critic
- 信赖域策略优化 (Trust Region Policy Optimization, TRPO)
- 重要性采样
- 广义优势估计(Generalized Advantage Estimation,GAE)
- 近端策略优化(proximal policy optimization,PPO)
- 深度确定性策略梯度 (Deep Deterministic Policy Gradient, DDPG)
- Soft Actor-Critic
- 目标导向的强化学习(goal-oriented reinforcement learning,GoRL)
- Pendulum by DDPG
参考资料
-
《机器学习》周志华
《机器学习》(西瓜书)公式详解
南瓜书PumpkinBook -
Reinforcement Learning: An Introduction
second edition
Richard S. Sutton and Andrew G. Barto
incompleteideas代码
张尚彤代码 -
动手学深度学习
Zhang, Aston and Lipton, Zachary C. and Li, Mu and Smola, Alexander J.
动手学深度学习 PyTorch版 bilibili -
动手学强化学习
张伟楠,沈键,俞勇
动手学强化学习代码
本书作者在上海交通大学致远学院和电子信息与电气工程学院为大三本科生开设强化学习课程。 -
蘑菇书
王琦,杨毅远,江季,Easy RL:强化学习教程,人民邮电出版社,2022.
Easy RL:强化学习教程
https://github.com/datawhalechina/easy-rl -
Spinning Up in Deep RL openai
Spinning Up in Deep RL openai中文 -
Tutorial: Deep Reinforcement Learning
David Silver, Google DeepMind
https://hunch.net/~beygel/deep_rl_tutorial.pdf
https://icml.cc/2016/tutorials/deep_rl_tutorial.pdf
我的笔记2020年简书
我的笔记2020年CSDN
比较和分类
表格转换工具
下表的算法全是model-free
| 算法 | 回合更新/单步更新 | on-policy / off-policy | Policy-Based / Value-Based | 策略 | 状态 | 动作 |
|---|---|---|---|---|---|---|
| Monte Carlo | 回合更新 | on-policy / off-policy | ||||
| Sarsa | 单步更新 | on-policy | Value-Based | 离散 | 离散 | |
| Q learning | 单步更新 | off-policy | Value-Based | 离散 | 离散 | |
| DQN | 单步更新 | off-policy | Value-Based | 连续 | 离散 | |
| Policy Gradients | 回合更新→单步更新 | on-policy | Policy-Based | 随机 | 连续 | |
| REINFORCE | 回合更新 | on-policy | Policy-Based | 随机 | 连续 | |
| Actor-Critic | 可以单步更新 | on-policy | Policy-Based / Value-Based | |||
| TRPO | on-policy | 随机 | ||||
| PPO | on-policy | 随机 | ||||
| DDPG | 单步更新 | off-policy | 确定 | 连续 | ||
| Soft Actor-Critic | off-policy | Policy-Based / Value-Based | 随机 |
on-policy算法的采样效率比较低。
actor会基于概率做出动作。
critic会对做出的动作给出动作的价值。
基础知识
智能体通过与环境的交互,使其做出的动作对应的决策得到的总奖励最大,或者说是期望最大。
当智能体在环境中得到当前时刻的状态后,其会基于此状态输出一个动作,这个动作会在环境中被执行并输出下一个状态和当前的这个动作得到的奖励。智能体在环境里存在的目标是最大化期望累积奖励。
以单智能体强化学习为例,具体的MDP数学模型M可以概括为M={S,A,R,P},其中,S,A,R和P分别表示智能体的状态集合、动作集合,奖励函数集合和状态转移概率集合。
强化学习任务对应了四元组 E= (X,A,P,R)
- 状态空间X
- 动作空间A
- 状态转移概率P:X×A×X→实数域
- 奖赏R:X×A×X→实数域
确定性策略:a=π(x),即在状态x下执行a动作;
随机性策略:P=π(x,a),即在状态x下执行a动作的概率。
π
(
a
∣
s
)
=
p
[
A
t
=
a
∣
S
t
=
s
]
\pi(a|s)=p[A_t=a|S_t=s]
π(a∣s)=p[At=a∣St=s]
强化学习在某种意义上可看作具有“延迟标记信息”的监督学习问题
K-摇臂赌博机
仅探索法:将尝试的机会平均分给每一个动作,即轮流执行,最终将每个动作的平均奖赏作为期望奖赏的近似值。
仅利用法:将尝试的机会分给当前平均奖赏值最大的动作。
欲累积奖赏最大,则必须在探索与利用之间达成较好的折中
ε-贪心法:基于一个概率来对探索和利用进行折中
以概率ε进行探索:πε(s) = 以均匀概率从A中选取动作
以概率1-ε进行利用:πε(s) = π(s) =
a
r
g
m
a
x
a
Q
(
s
,
a
)
argmax_{a} Q(s,a)
argmaxaQ(s,a),即选择当前最优的动作。
Softmax算法:基于当前每个动作的平均奖赏值来对探索和利用进行折中
τ趋于0时, Softmax 将趋于“仅利用”
τ趋于无穷大时, Softmax 将趋于“仅探索”
智能体的类型:Policy-Based / Value-Based
- 基于价值的智能体:
显式学习的是价值函数,隐式地学习智能体的策略(从学到的价值函数里面推算出来的)。
动作空间离散
当同时采用非线性近似、自举等策略时会有收敛问题 - 基于策略的智能体。
没有学习价值函数,直接学习策略。
动作空间连续
直接将策略参数化,通过策略搜索、策略梯度或者进化方法来更新参数以最大化回报
具有良好的收敛性 - 基于价值和策略的智能体:演员-评论员智能体:学习策略函数和价值函数以及两者的交互得到更佳的状态。
model-free / model-based
有模型学习是指根据环境中的经验,构建一个虚拟世界,同时在真实环境和虚拟世界中学习;
免模型学习是指不对环境进行建模,直接与真实环境进行交互来学习到最优策略。
有模型学习相比免模型学习仅仅多出一个步骤,即对真实环境进行建模。
免模型学习通常属于数据驱动型方法,需要大量的采样来估计状态、动作及奖励函数,从而优化动作策略。
免模型学习的泛化性要优于有模型学习,原因是有模型学习需要对真实环境进行建模,并且虚拟世界与真实环境之间可能还有差异,这限制了有模型学习算法的泛化性。
强化学习的使用场景
多序列决策问题
对应的模型未知:需要通过学习逐渐逼近真实模型的问题。
具有马尔可夫性:当前的动作会影响环境的状态
可学习条件:所有状态是可重复到达的条件
深度学习和强化学习
深度学习中的损失函数的目的是使预测值和真实值之间的差距尽可能小
强化学习中的损失函数的目的是使总奖励的期望尽可能大。
无监督学习、监督学习、强化学习
| 无监督学习 | 监督学习 | 强化学习 |
|---|---|---|
| 不需要有标签样本 | 需要有标签样本 | 不需要有标签样本 |
| 样本一样满足独立同分布条件 | 序列数据,样本之间通常具有强相关性 | |
| 有正确的标签,模型可以通过标签修正自己的预测来更新模型 | 完全根据环境的“反馈”更新对自己最有利的动作 | |
| 奖励的延迟 |
无监督学习直接基于给定的数据进行建模,寻找数据或特征中隐藏的结构,一般对应聚类问题;
强化学习需要通过延迟奖励学习策略来得到模型与目标的距离(可以通过奖励函数进行定量判断),可以将奖励函数视为正确目标的一个稀疏、延迟形式。
强化学习的基本特征:
- 有试错探索过程,即需要通过探索环境来获取对当前环境的理解。
- 智能体的动作会影响它从环境中得到的反馈。
- 智能体会从环境中获得延迟奖励。
- 训练过程中时间非常重要,因为数据都是时间关联的,而不是像监督学习中的数据大部分是满足独立同分布的。
16.3 有模型学习
有模型学习:状态空间、动作空间、转移概率以及奖赏函数都已经给出
预测(prediction)和控制(control)是马尔可夫决策过程里面的核心问题。
预测(评估一个给定的策略)的输入是马尔可夫决策过程 <S,A,P,R,γ> 和策略π,输出是价值函数Vπ。
控制(搜索最佳策略)的输入是马尔可夫决策过程 <S,A,P,R,γ>,输出是最佳价值函数(optimal value function)V∗和最佳策略(optimal policy)π∗。
16.3.1 策略评估
折扣累积回报: G t = R t + 1 + γ R t + 2 + ⋯ = ∑ k = 0 ∞ γ k R t + k + 1 G_t=R_{t+1}+\gamma R_{t+2}+\cdots =\sum_{k=0}^{\infty}{\gamma^kR_{t+k+1}} Gt=Rt+1+γRt+2+⋯=∑k=0∞γkRt+k+1
状态值函数(V):Vπ(x),即从状态x出发,使用π策略所带来的累积奖赏;
υ
π
(
s
)
=
E
π
[
G
t
∣
S
t
=
s
]
=
E
π
[
∑
k
=
0
∞
γ
k
R
t
+
k
+
1
∣
S
t
=
s
]
\upsilon_{\pi}\left(s\right)=E_{\pi}\left[{G_t|S_t=s}\right] =E_{\pi}\left[\sum_{k=0}^{\infty}{\gamma^kR_{t+k+1}|S_t=s}\right]
υπ(s)=Eπ[Gt∣St=s]=Eπ[∑k=0∞γkRt+k+1∣St=s]
状态值函数V表示执行策略π能得到的累计折扣奖励:
V
π
(
s
)
=
E
[
R
(
s
0
,
a
0
)
+
γ
R
(
s
1
,
a
1
)
+
γ
2
R
(
s
2
,
a
2
)
+
γ
3
R
(
s
3
,
a
3
)
+
…
∣
s
=
s
0
]
V^π(s) = E[R(s_0,a_0)+γR(s_1,a_1)+γ^2R(s_2,a_2)+γ^3R(s_3,a_3)+…|s=s_0]
Vπ(s)=E[R(s0,a0)+γR(s1,a1)+γ2R(s2,a2)+γ3R(s3,a3)+…∣s=s0]
V
π
(
s
)
=
R
(
s
,
a
)
+
γ
∑
s
′
∈
S
p
(
s
′
∣
s
,
π
(
s
)
)
V
π
(
s
′
)
V^{\pi}(s)=R(s, a)+\gamma \sum_{s^{\prime} \in S} p\left(s^{\prime} | s, \pi(s)\right) V^{\pi}\left(s^{\prime}\right)
Vπ(s)=R(s,a)+γ∑s′∈Sp(s′∣s,π(s))Vπ(s′)
状态-动作值函数(Q):Qπ(x,a),即从状态x出发,执行动作a后再使用π策略所带来的累积奖赏。
q
π
(
s
,
a
)
=
E
π
[
G
t
∣
S
t
=
s
,
A
t
=
a
]
=
E
π
[
∑
k
=
0
∞
γ
k
R
t
+
k
+
1
∣
S
t
=
s
,
A
t
=
a
]
q_{\pi}\left(s,a\right)=E_{\pi}\left[{G_t|S_t=s,A_t=a}\right] =E_{\pi}\left[\sum_{k=0}^{\infty}{\gamma^kR_{t+k+1}|S_t=s,A_t=a}\right]
qπ(s,a)=Eπ[Gt∣St=s,At=a]=Eπ[∑k=0∞γkRt+k+1∣St=s,At=a]
状态动作值函数Q(s,a)表示在状态s下执行动作a能得到的累计折扣奖励:
Q
π
(
s
,
a
)
=
E
[
R
(
s
0
,
a
0
)
+
γ
R
(
s
1
,
a
1
)
+
γ
2
R
(
s
2
,
a
2
)
+
γ
3
R
(
s
3
,
a
3
)
+
…
∣
s
=
s
0
,
a
=
a
0
]
Q^π(s,a) = E[R(s_0,a_0)+γR(s_1,a_1)+γ^2R(s_2,a_2)+γ^3R(s_3,a_3)+…|s=s_0,a=a_0]
Qπ(s,a)=E[R(s0,a0)+γR(s1,a1)+γ2R(s2,a2)+γ3R(s3,a3)+…∣s=s0,a=a0]
Q
π
(
s
,
a
)
=
R
(
s
,
a
)
+
γ
∑
s
′
∈
S
p
(
s
′
∣
s
,
π
(
s
)
)
Q
π
(
s
′
,
π
(
s
′
)
)
Q^{\pi}(s, a)=R(s, a)+\gamma \sum_{s^{\prime} \in S} p\left(s^{\prime} | s, \pi(s)\right) Q^{\pi}\left(s^{\prime}, \pi\left(s^{\prime}\right)\right)
Qπ(s,a)=R(s,a)+γ∑s′∈Sp(s′∣s,π(s))Qπ(s′,π(s′))
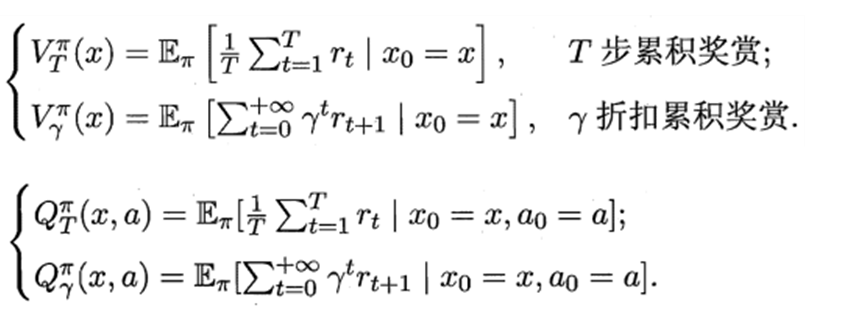
递归形式:Bellman 等式
状态值函数的Bellman方程:
υ
(
s
)
=
E
[
G
t
∣
S
t
=
s
]
=
E
[
R
t
+
1
+
γ
R
t
+
2
+
⋯
∣
S
t
=
s
]
=
E
[
R
t
+
1
+
γ
(
R
t
+
2
+
γ
R
t
+
3
+
⋯
)
∣
S
t
=
s
]
=
E
[
R
t
+
1
+
γ
G
t
+
1
∣
S
t
=
s
]
=
E
[
R
t
+
1
+
γ
υ
(
S
t
+
1
)
∣
S
t
=
s
]
\upsilon(s)=E[G_t|S_t=s] \\ =E[R_{t+1}+\gamma R_{t+2}+\cdots |S_t=s] \\ =E[R_{t+1}+\gamma(R_{t+2}+\gamma R_{t+3}+\cdots)|S_t=s] \\ =E[R_{t+1}+\gamma G_{t+1}|S_t=s] \\ =E[R_{t+1}+\gamma\upsilon(S_{t+1})|S_t=s]
υ(s)=E[Gt∣St=s]=E[Rt+1+γRt+2+⋯∣St=s]=E[Rt+1+γ(Rt+2+γRt+3+⋯)∣St=s]=E[Rt+1+γGt+1∣St=s]=E[Rt+1+γυ(St+1)∣St=s]
状态动作值函数的Bellman方程:
q
π
(
s
,
a
)
=
E
π
[
G
t
∣
S
t
=
s
,
A
t
=
a
]
=
E
π
[
R
t
+
1
+
γ
q
(
S
t
+
1
,
A
t
+
1
)
∣
S
t
=
s
,
A
t
=
a
]
q_{\pi}(s,a)=E_{\pi}[G_t|S_t=s,A_t=a]\\ =E_{\pi}[R_{t+1}+\gamma q(S_{t+1},A_{t+1})|S_t=s,A_t=a]
qπ(s,a)=Eπ[Gt∣St=s,At=a]=Eπ[Rt+1+γq(St+1,At+1)∣St=s,At=a]
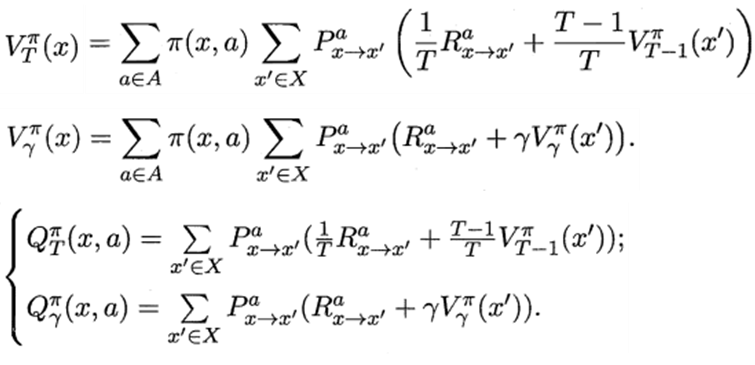
16.3.2 策略改进
最优策略:使得值函数对所有状态求和的值最大的策略
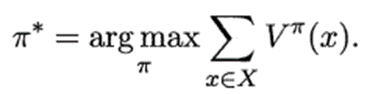
最优值函数:最优策略对应的值函数
策略改进:
π
′
(
s
)
=
argmax
a
∈
A
Q
π
(
s
,
a
)
\pi^{'}(s)=\underset{a∈A}{\operatorname{argmax}} Q^{\pi}(s, a)
π′(s)=a∈AargmaxQπ(s,a)
π ∗ ( s ) = argmax a Q ∗ ( s , a ) \pi^{*}(s)=\underset{a}{\operatorname{argmax}} Q^{*}(s, a) π∗(s)=aargmaxQ∗(s,a)
16.3.3 策略迭代
策略迭代:不断迭代进行策略评估和策略改进,直到策略收敛、不再改变为止

策略迭代有两个循环,一个是在策略估计的时候,为了求当前策略的价值函数需要迭代很多次;另一个是外面的大循环,即策略评估、策略提升。
16.3.3 值迭代
值迭代:不断迭代进行策略评估,直到值函数收敛、不再改变为止

直接估计最优价值函数,因此没有策略提升环节。
16.4 免模型学习
在原始策略上使用ε-贪心策略
ε-贪心法:基于一个概率来对探索和利用进行折中
以概率ε进行探索:πε(s) = 以均匀概率从A中选取动作
以概率1-ε进行利用:πε(s) = π(s) =
a
r
g
m
a
x
a
Q
(
s
,
a
)
argmax_{a} Q(s,a)
argmaxaQ(s,a),即选择当前最优的动作。
on-policy off-policy
the target policy: the policy being learned about
the behavior policy: the policy used to generate behavior
In this case we say that learning is from data “off” the target policy, and the overall process is termed off-policy learning.
目标策略:正在被学习的策略。要学习的智能体。代理和环境交互过程中所选择的动作
行为策略:被用来产生行为的策略。与环境交互的智能体。计算评估函数的过程中选择的动作
同策略(on-policy):行为策略是目标策略
要学习的智能体和与环境交互的智能体相同
智能体直接采用正在优化的策略函数收集训练数据,即利用自身在特定时间内产生的连续决策轨迹更新当前的DNN参数。
异策略(off-policy):行为策略不是目标策略。
要学习的智能体和与环境交互的智能体不相同
智能体在收集训练数据时采用与正在优化的策略函数不一致的策略。
智能体在训练过程中可以不断和环境交互,得到新的反馈数据。
on-policy算法:直接使用这些反馈数据
off-policy算法:先将数据存入经验回放池中,需要时再采样。
离线强化学习(offline reinforcement learning):在智能体不和环境交互的情况下,仅从已经收集好的确定的数据集中,通过强化学习算法得到比较好的策略。
on-policy算法的缺点:只能更新参数一次,然后就要重新采样数据, 才能再次更新参数。这显然是非常花时间的
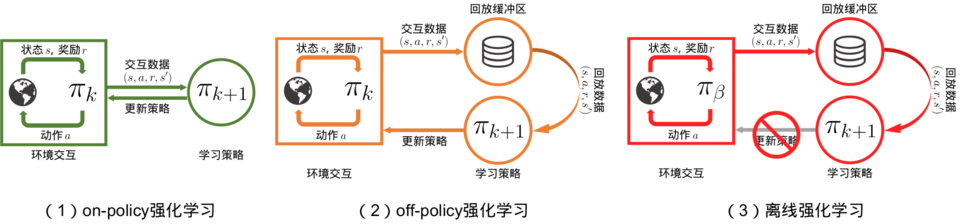
异策略off-policy:ReplayBuffer内可以存放“由不同策略”收集得到的数据用于更新网络
同策略on-policy:ReplayBuffer内只能存放“由相同策略”收集得到的数据用于更新网络
16.4.1 蒙特卡罗强化学习
蒙特卡罗强化学习:通过采样来进行策略评估。
多次“采样”,然后求取平均累积奖赏来作为期望累积奖赏的近似
由于采样必须为有限次数,因此该方法更适合于使用 步累积奖赏的强化学习任务。
估计状态-动作值函数

同策略(on-policy)蒙特卡罗强化学习算法:被评估和被改进的都是同一个策略
异策略(off-policy)蒙特卡罗强化学习算法:仅在评估时使用ε-贪心策略,而在改进时使用原始策略
蒙特卡罗强化学习算法没有充分利用强化学习任务的 MDP 结构
16.4.2 时序差分学习
蒙特卡罗强化学习算法在一个完整的采样轨迹完成后再对所有的状态-动作对进行更新。
实际上这个更新过程能增量式进行。
时序差分(Temporal Difference ,简称 TD )学习则结合了动态规划与蒙特卡罗方法的思想,能做到更高效的免模型学习。
Sarsa算法:同策略算法(on-policy):行为策略是目标策略
每次更新值函数需知道前一步的状态(state)x、前一步的动作(action)a、奖赏值(reward)R、当前状态(state)x’、将要执行的动作(action)a’:
Q
(
s
,
a
)
←
Q
(
s
,
a
)
+
α
[
R
+
γ
Q
(
s
′
,
a
′
)
−
Q
(
s
,
a
)
]
,
γ
∈
[
0
,
1
)
Q(s,a)←Q(s,a)+\alpha[R+\gamma Q\left(s^{\prime}, a^{\prime}\right)-Q(s,a)],\gamma∈[0,1)
Q(s,a)←Q(s,a)+α[R+γQ(s′,a′)−Q(s,a)],γ∈[0,1)
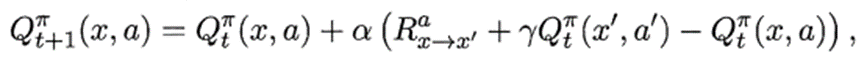
更新步长α越大,则越靠后的累积奖赏越重要。
π(s) =
a
r
g
m
a
x
a
Q
(
s
,
a
)
argmax_{a} Q(s,a)
argmaxaQ(s,a)

on policy 同策略
在选择动作执行的时候采取的策略 = 在更新Q表的时候采取的策略
行为策略 行动策略是ε-greedy策略
目标策略 评估策略是ε-greedy策略
Q-learning算法:异策略算法(off-policy):行为策略不是目标策略
每次更新值函数需知道前一步的状态(state)x、前一步的动作(action)a、奖赏值(reward)R、当前状态(state)x’
Q值表:state为行,action为列,reward为元素
Q
(
s
,
a
)
←
Q
(
s
,
a
)
+
α
[
R
+
γ
max
a
′
Q
(
s
′
,
a
′
)
−
Q
(
s
,
a
)
]
,
γ
∈
[
0
,
1
)
Q(s,a)←Q(s,a)+\alpha[R+\gamma \max _{a^{\prime}} Q\left(s^{\prime}, a^{\prime}\right)-Q(s,a)],\gamma∈[0,1)
Q(s,a)←Q(s,a)+α[R+γmaxa′Q(s′,a′)−Q(s,a)],γ∈[0,1)
学习率*(Q的真实值 - Q的估计值)
如果学习率越大,那么新估计值代替旧估计值的程度也越大

off-policy 异策略
在选择动作执行的时候采取的策略 ≠ 在更新Q表的时候采取的策略
行为策略 行动策略是ε-greedy策略
目标策略 更新Q表的策略是贪婪策略
Q-learning的目标策略不管行为策略会产生什么动作。
Q-learning的目标策略默认下一个动作就是 Q 值最大的那个动作,并且默认按照最佳的策略去优化目标策略,所以它可以更大胆地去寻找最优的路径,它表现得比 Sarsa 大胆得多。
Q学习算法是非常激进的,其希望每一步都获得最大的奖励;
Sarsa算法则相对来说偏保守,会选择一条相对安全的迭代路线。
异策略算法的这个循环可以拆开成2个部分:与环境交互(执行动作,获得奖励和观察状态)和学习(用动作,奖励,状态更新Q),从而实现离线学习。
离线学习的行为策略一直没更新,训练效果应该也不好?
蒙特卡洛和时序差分
动态规划:有模型。可以凭借已知转移概率推断出后续的状态情况
蒙特卡洛方法和时序差分方法:免模型。对于后续状态的获知也都是基于试验的方法;
时序差分方法和动态规划方法的策略评估,都能基于当前状态的下一步预测情况来得到对于当前状态的价值函数的更新。
TD(1):蒙特卡洛方法,即考虑 T−1 个后续状态直到整个试验结束。
TD(0):时序差分方法,即只考虑下一个状态;
蒙特卡洛方法利用当前状态之后每一步的奖励而不使用任何价值估计
时序差分算法只利用一步奖励和下一个状态的价值估计。
蒙特卡洛方法:需要与环境交互,产生一整条马尔可夫链并直到最终状态才能进行更新。
时序差分方法:不需要等到试验结束后才能进行当前状态的价值函数的计算与更新
蒙特卡洛方法:无偏(unbiased),方差大
方差大,因为每一步的状态转移都有不确定性,而每一步状态采取的动作所得到的不一样的奖励最终都会加起来,这会极大影响最终的价值估计;
价值估计偏差小:进行了完整的采样来获取长期的回报值
价值估计方差大:因为收集了完整的信息,原因在于其基于试验的采样得到,和真实的分布有差距,不充足的交互导致较大方差。
时序差分算法:有偏,方差小
方差小,因为只关注了一步状态转移,用到了一步的奖励。使用了自举,实现了基于平滑的效果
有偏,因为用到了下一个状态的价值估计而不是其真实的价值。
只考虑了前一步的回报值,其他都是基于之前的估计值
多步时序差分:无偏且方差小
多步时序差分可以结合二者的优势
多步sarsa
Sarsa(0):Sarsa 是一种单步更新法, 在环境中每走一步, 更新一次自己的行为准则。等走完这一步以后直接更新行为准则
Sarsa(1):走完这步, 再走一步, 然后再更新
Sarsa(n):如果等待回合完毕我们一次性再更新呢, 比如这回合我们走了 n 步
Sarsa(lambda):有了一个 lambda 值来代替我们想要选择的步数
lambda 是脚步衰减值, 是一个在 0 和 1 之间的数
当 lambda 取0, 就变成了 Sarsa 的单步更新
当 lambda 取 1, 就变成了回合更新, 对所有步更新的力度都是一样
当 lambda 在 0 和 1 之间, 取值越大, 离宝藏越近的步更新力度越大
16.5 值函数近似
直接对连续状态空间的值函数进行学习
值函数能表达为状态的线性函数
线性值函数近似 Sarsa 算法
线性值函数近似 Q-learning算法
16.6 模仿学习
模仿学习
应用场景:奖励函数并未给定,或者奖励信号极其稀疏
模仿者的任务:利用专家提供的一系列状态动作对进行训练,无须奖励信号就可以达到一个接近专家的策略。
16.6.1 直接模仿学习 行为克隆(behavior cloning,BC)
直接模仿人类专家的“状态-动作对"
直接使用监督学习方法,将专家数据(状态,动作)中的状态看作样本输入,动作视为标签
16.6.2 逆强化学习(inverse RL)
从解答学习问题是什么
逆强化学习:从人类专家提供的范例数据中反推出奖励函数
假设环境的奖励函数应该使得专家轨迹获得最高的奖励值,进而学习背后的奖励函数,最后基于该奖励函数做正向强化学习,从而得到模仿策略。
生成式对抗模仿学习(generative adversarial imitation learning,GAIL)
2016 年由斯坦福大学研究团队提出的基于生成式对抗网络的模仿学习
它诠释了生成式对抗网络的本质其实就是模仿学习。
模仿了专家策略的占用度量,即尽量使得策略在环境中的所有状态动作对的占用度量和专家策略的占用度量一致。
深度Q网络算法
深度Q网络是基于深度学习的Q学习算法,其结合了价值函数近似(value function approximation)与神经网络技术,并采用目标网络和经验回放等方法进行网络的训练。
Q学习采用动作价值函数Q(s,a)
在实际任务中,状态数量巨大,使用真正的价值函数通常是不切实际的,所以使用了价值函数近似的方法。
Q-learning算法:状态离散,动作离散,并且空间都比较小的情况下适用
若动作是连续(无限)的,神经网络的输入:状态s和动作a。输出:在状态s下采取动作a能获得的价值。
若动作是离散(有限)的,除了可以采取动作连续情况下的做法,我们还可以:神经网络的输入:状态s。输出:每一个动作的Q值。
通常 DQN(以及 Q-learning)只能处理动作离散的情况,因为在Q函数的更新过程中有max_a这一操作。
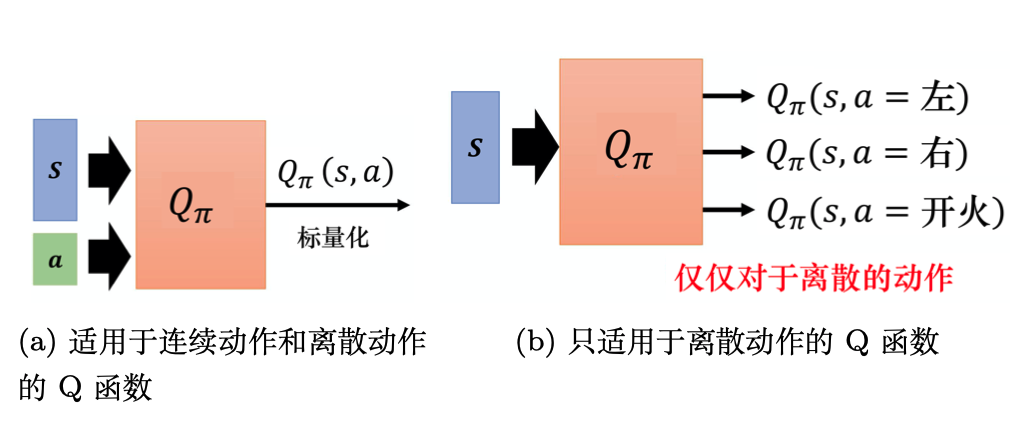
Q网络:用于拟合Q函数的神经网络
用权重为w的Q网络
Q
(
s
,
a
,
w
)
Q(s,a,w)
Q(s,a,w)表示value函数
Q
∗
(
s
,
a
)
Q^∗(s,a)
Q∗(s,a)
DQN 算法最终更新的目标:最小化损失函数
Q 网络的损失函数构造为均方误差的形式:
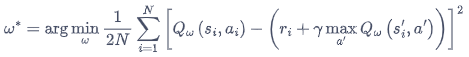
I
=
(
r
+
γ
max
a
Q
(
s
′
,
a
′
,
w
)
−
Q
(
s
,
a
,
w
)
)
2
I=\left(r+\gamma \max _{a} Q\left(s^{\prime}, a^{\prime}, \mathbf{w}\right)-Q(s, a, \mathbf{w})\right)^{2}
I=(r+γmaxaQ(s′,a′,w)−Q(s,a,w))2
经验回放(experience replay)
如果某个算法使用了经验回放,该算法就是off-policy算法。
维护一个回放缓冲区,将每次从环境中采样得到的四元组数据(状态、动作、奖励、下一状态)存储到回放缓冲区中,训练 Q 网络的时候再从回放缓冲区中随机采样若干数据来进行训练。
好处:
- 打破样本之间的相关性,让其满足独立假设。
在 MDP 中交互采样得到的数据本身不满足独立假设,因为这一时刻的状态和上一时刻的状态有关。
非独立同分布的数据对训练神经网络有很大的影响,会使神经网络拟合到最近训练的数据上。
回放缓冲区里面的经验来自于不同的策略,我们采样到的一个批量里面的数据会是比较多样的。 - 提高样本效率。
每一个样本可以被使用多次,十分适合深度神经网络的梯度学习。
与环境交互比较慢,训练网络比较快。
强化学习最花时间的过程是与环境交互,使用GPU乃至TPU来训练网络相对来说是比较快的。
用回放缓冲区可以减少与环境交互的次数。
因为在训练的时候,我们的经验不需要通通来自于某一个策略(或者当前时刻的策略)。
一些由过去的策略所得到的经验可以放在回放缓冲区中被使用多次,被反复地再利用,这样采样到的经验才能被高效地利用。
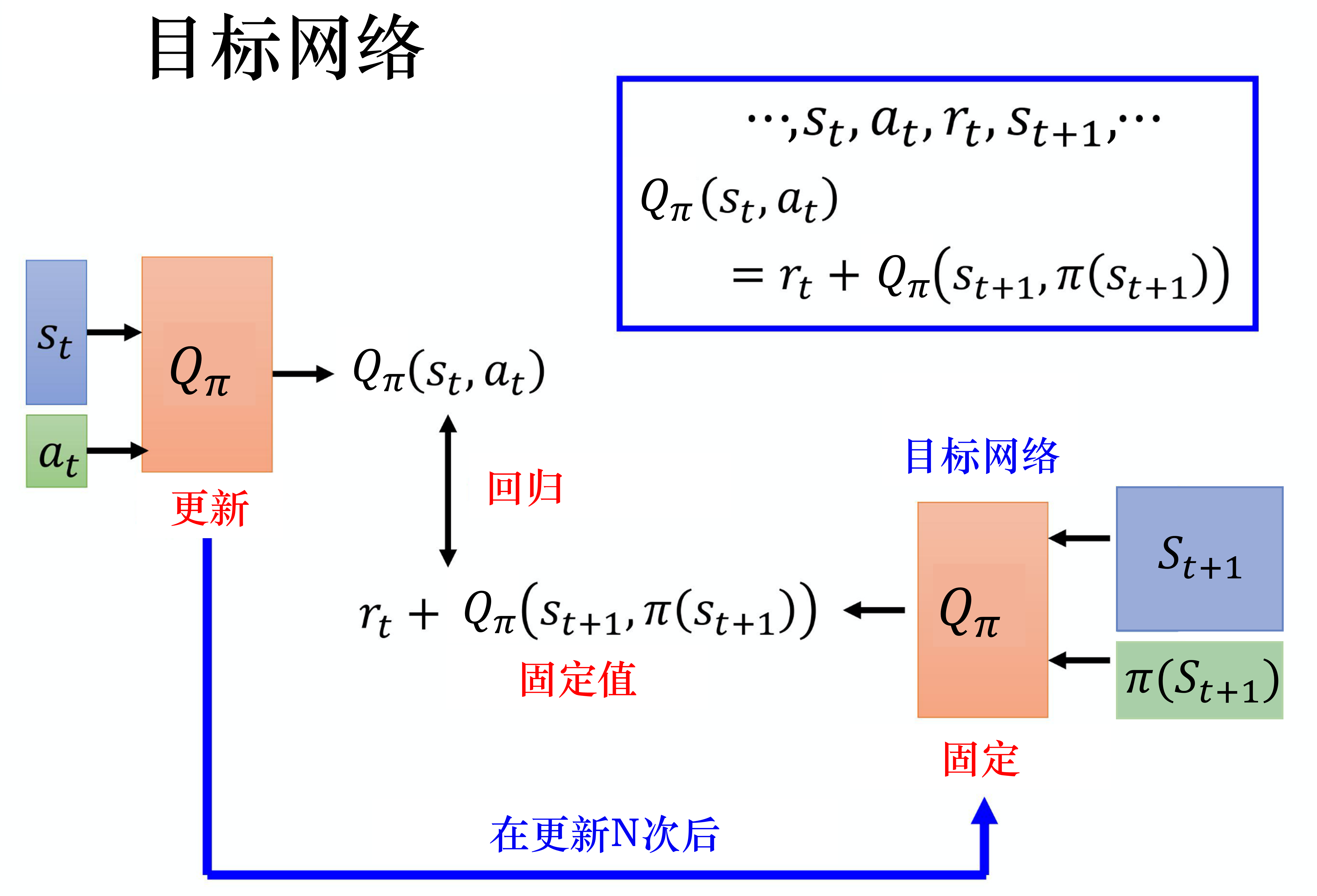
目标网络(target network)
损失函数包含神经网络的输出,因此在更新网络参数的同时目标也在不断地改变,这容易造成神经网络训练的不稳定性。
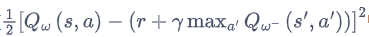
训练网络:用于计算损失函数的前一项,并且使用正常梯度下降方法来进行更新。
目标网络:用于计算损失函数的后一项
r
+
γ
max
a
′
Q
(
s
′
,
a
′
,
w
−
)
r+\gamma \max _{a'} Q\left(s^{\prime}, a^{\prime}, \mathbf{w}-\right)
r+γmaxa′Q(s′,a′,w−)
训练网络在训练中的每一步都会更新。
目标网络的参数每隔几步才会与训练网络同步一次。
这样做使得目标网络相对于训练网络更加稳定。
deep Q network, DQN


Double Deep Q-Network
[1509.06461] Deep Reinforcement Learning with Double Q-learning
DQN的问题:DQN算法通常会导致对Q值的过高估计
DQN:Q_next = max(Q_next(s’, a_all))
Y
t
D
Q
N
≡
R
t
+
1
+
γ
max
a
Q
(
S
t
+
1
,
a
;
θ
t
−
)
Y_{t}^{\mathrm{DQN}} \equiv R_{t+1}+\gamma \max _{a} Q\left(S_{t+1}, a ; \boldsymbol{\theta}_{t}^{-}\right)
YtDQN≡Rt+1+γmaxaQ(St+1,a;θt−)
Double DQN:Q_next = Q_next(s’, argmax(Q_eval(s’, a_all)))
Y
t
DoubleDQN
≡
R
t
+
1
+
γ
Q
(
S
t
+
1
,
argmax
a
Q
(
S
t
+
1
,
a
;
θ
t
)
;
θ
t
−
)
Y_{t}^{\text {DoubleDQN }} \equiv R_{t+1}+\gamma Q\left(S_{t+1}, \underset{a}{\operatorname{argmax}} Q\left(S_{t+1}, a ; \boldsymbol{\theta}_{t}\right); \boldsymbol{\theta}_{t}^{-}\right)
YtDoubleDQN ≡Rt+1+γQ(St+1,aargmaxQ(St+1,a;θt);θt−)
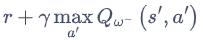
DQN的优化目标为 ,动作的选取依靠目标网络
,动作的选取依靠目标网络
Double DQN 的优化目标为 ,动作的选取依靠训练网络
,动作的选取依靠训练网络
用训练网络计算使Q值最大的动作
用目标网络计算Q值
当前的Q网络w用于选择动作
旧的Q网络w−用于评估动作
I
=
(
r
+
γ
Q
(
s
′
,
argmax
a
′
Q
(
s
′
,
a
′
,
w
)
,
w
−
)
−
Q
(
s
,
a
,
w
)
)
2
I=\left(r+\gamma Q\left(s^{\prime}, \underset{a^{\prime}}{\operatorname{argmax}} Q\left(s^{\prime}, a^{\prime}, \mathbf{w}\right), \mathbf{w}^{-}\right)-Q(s, a, \mathbf{w})\right)^{2}
I=(r+γQ(s′,a′argmaxQ(s′,a′,w),w−)−Q(s,a,w))2
Double DQN 的代码实现可以直接在 DQN 的基础上进行,无须做过多修改。
几乎没有增加运算量
不需要新的网络
优先级经验回放 (prioritized experience replay, PER)
[1511.05952] Prioritized Experience Replay
Double Learning and Prioritized Experience Replay
重视值得学习的样本
时序差分误差 = 网络的输出与目标之间的差距
如果采样过的数据的时序差分误差特别大,那么应该让它们以更大的概率被采样到。
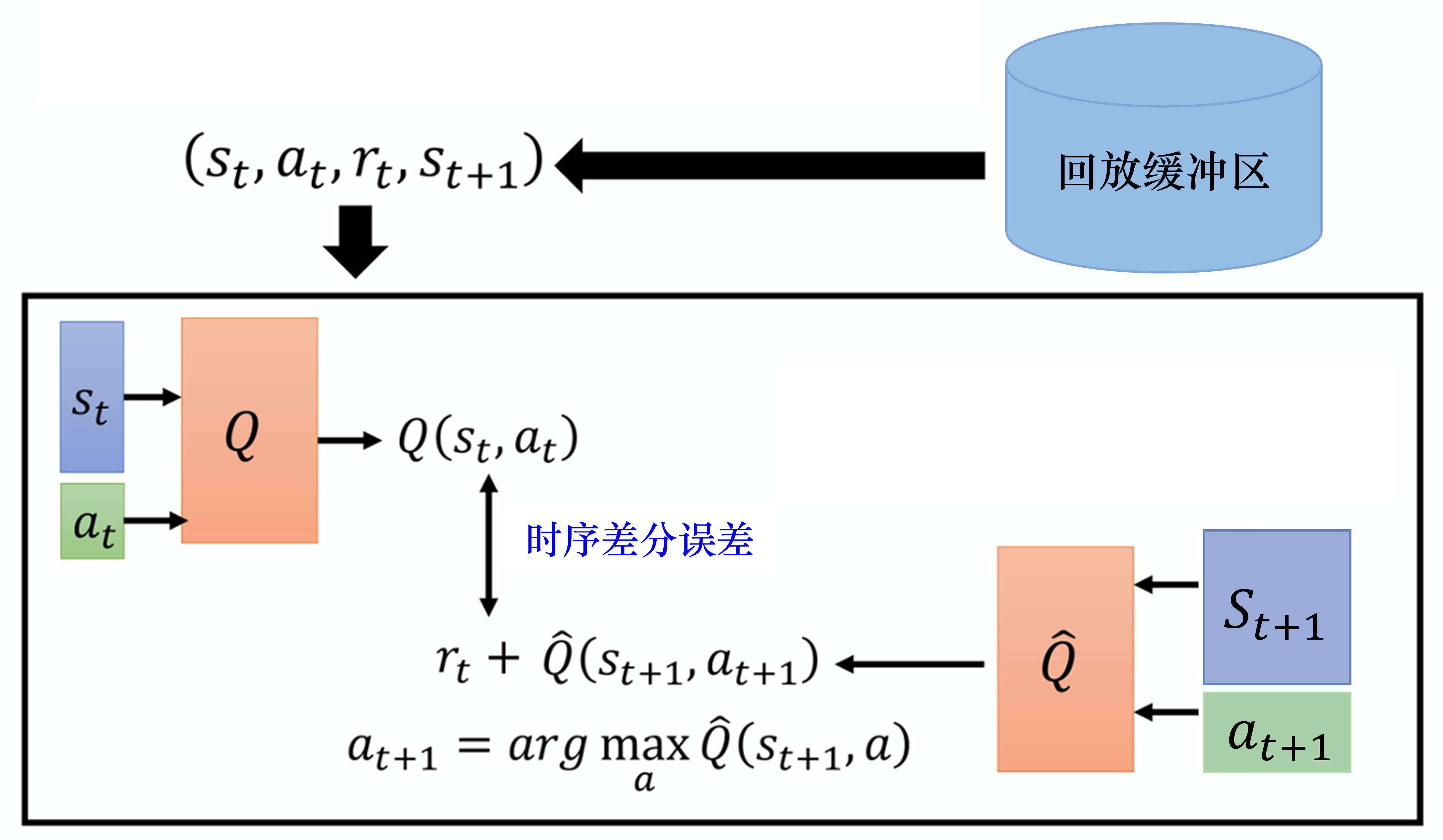

batch 抽样的时候并不是随机抽样, 而是按照 Memory 中的样本优先级来抽
用到 TD-error, 也就是 Q现实 - Q估计 来规定优先学习的程度
如果 TD-error 越大, 就代表我们的预测精度还有很多上升空间, 那么这个样本就越需要被学习, 也就是优先级 p 越高
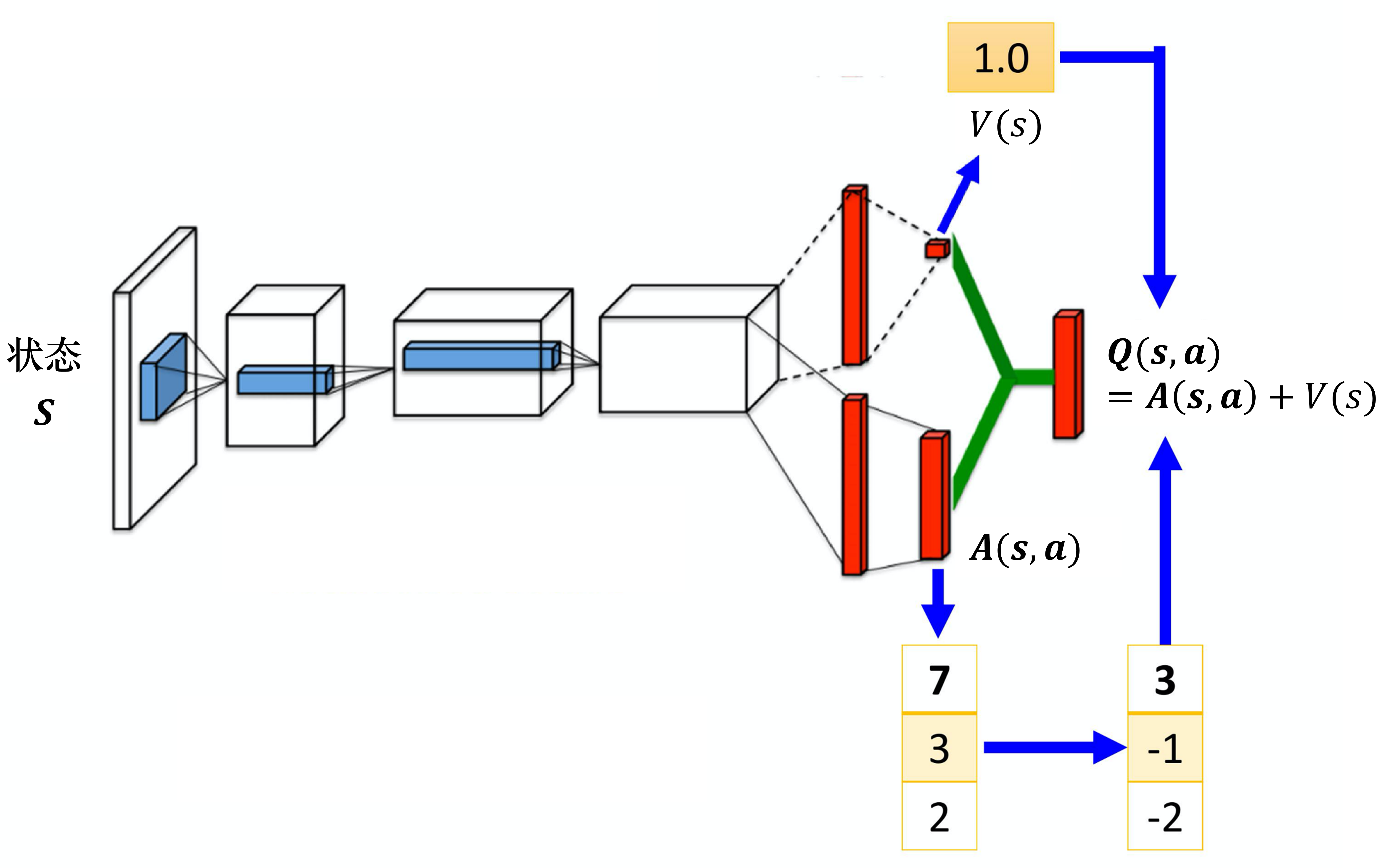
Dueling Deep Q-Network
[1511.06581] Dueling Network Architectures for Deep Reinforcement Learning
Dueling DQN 能够很好地学习到不同动作的差异性,在动作空间较大的环境下非常有效。
有时我们更新时不一定会将 V(s) 和 Q(s,a) 都更新。
我们将其分成两个部分后,就不需要将所有的状态-动作对都采样一遍,我们可以使用更高效的估计Q值的方法将最终的 Q(s,a) 计算出来。
动作状态价值函数 = 状态价值函数 + 优势函数
将Q网络分成2个通道
Q
η
,
α
,
β
(
s
,
a
)
=
V
η
,
α
(
s
)
+
A
η
,
β
(
s
,
a
)
Q_{\eta, \alpha, \beta}(s,a) = V_{\eta, \alpha}(s) + A_{\eta, \beta}(s,a)
Qη,α,β(s,a)=Vη,α(s)+Aη,β(s,a)
V
η
,
α
(
s
)
V_{\eta, \alpha}(s)
Vη,α(s):状态价值函数,与action无关
A
η
,
β
(
s
,
a
)
A_{\eta, \beta}(s,a)
Aη,β(s,a):该状态下采取不同动作的优势函数,与action有关
η
\eta
η是状态价值函数和优势函数共享的网络参数,一般用在神经网络中,用来提取特征的前几层
α
\alpha
α和
β
\beta
β分别为状态价值函数和优势函数的参数。
竞争深度Q网络的问题:最后学习的结果可能是这样的:
智能体就学到V(s)等于0,A(s,a)等于Q,就和原来的深度Q网络一样。
解决方案:在把A(s,a)与V(s)加起来之前,先处理A(s,a)。比如减去均值
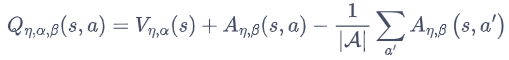
虽然它不再满足bellman最优方程,但实际应用时更加稳定。
策略梯度 Policy Gradients
基于值函数的方法:学习值函数,然后根据值函数导出一个策略。学习过程中并不存在一个显式的策略
基于策略的方法:直接显式地学习一个目标策略。
policy gradient要输出不是action的value,而是具体的那一个action,跳过了value这个阶段。输出的这个action可以是一个连续的值。
优点:连续动作
在策略梯度中,梯度可以写成一般的形式:
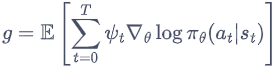
其中,
ψ
t
\psi_t
ψt可以有很多种形式

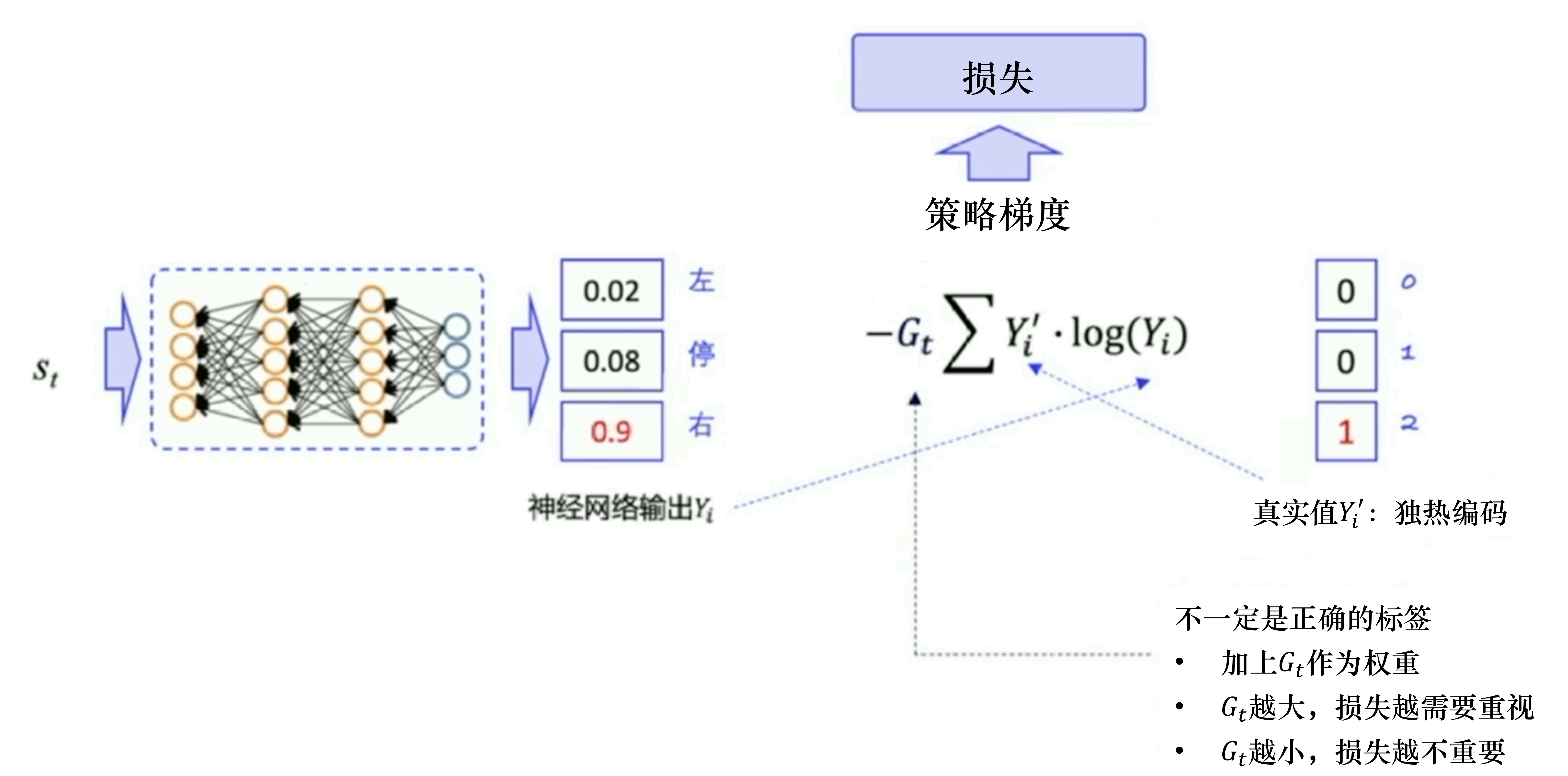
最小化损失 → 最大化Y’=1对应的那个Y
REINFORCE:蒙特卡洛策略梯度
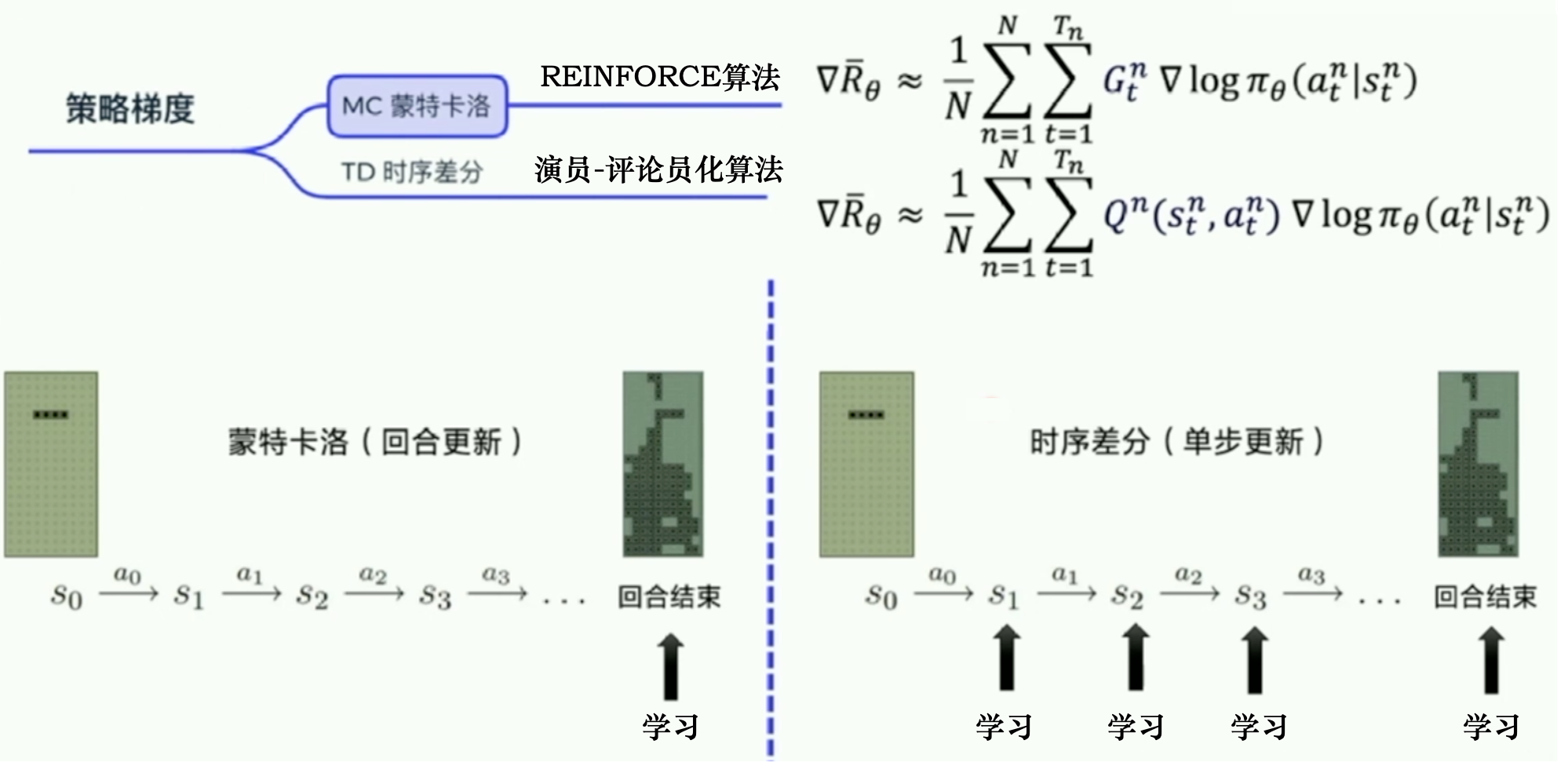
Gt:从第t步开始,往后能够获得的总奖励

REINFORCE 算法
1.用一个策略模型来输出动作概率。通过 sample() 函数得到一个具体的动作,与环境交互,得到整个回合的数据。
2.执行 learn() 函数,用这些数据去构造损失函数,“扔”给优化器优化,更新策略模型。
在状态s对所选动作a的吃惊度:delta(log(Policy(s,a)) * V)
Policy(s,a)概率越小,-log(Policy(s,a))(即-log§)越大
如果Policy(s,a)很小时,拿到的R大,即V大,那-delta(log(Policy(s,a)) * V)就更大,表示更吃惊。(选了一个不常选的动作,却发现它能得到的reward很大,那么大幅修改参数)
因为使用了蒙特卡洛方法,REINFORCE算法的缺点:回合更新
1.梯度估计的方差很大
2.只能在序列结束后进行更新,这同时也要求任务具有有限的步数
Actor-Critic算法则可以在每一步之后都进行更新,并且不对任务的步数做限制。
Actor-Critic
Actor-Critic算法既学习价值函数,又学习策略函数
本质上是基于策略的算法,因为这一系列算法的目标都是优化一个带参数的策略,只是会额外学习价值函数,从而帮助策略函数更好地学习。
Actor-Critic有演员网络和评论家网络。
- Actor使用策略梯度函数:生成动作并与环境交互。
策略函数,描述状态和离散动作或连续动作分布的映射关系。
在Critic价值函数的指导下用策略梯度学习一个更好的策略。 - Critic使用价值函数:评估Actor的表现,并在下一阶段指导Actor的行为。
传统的值函数,来评估不同状态下的收益
通过Actor与环境交互收集的数据学习一个价值函数,这个价值函数会用于判断在当前状态什么动作是好的,什么动作不是好的。
它可以加速策略梯度函数的收敛,但这还不足以解决复杂的问题。
结合了Policy Gradient (Actor)和Function Approximation (Critic)的方法
Actor基于概率选行为
Critic基于Actor的行为评判行为的得分
Actor根据Critic的评分修改选行为的概率
Actor 在运用 Policy Gradient 的方法进行 Gradient ascent 的时候, 由 Critic 来告诉他, 这次的 Gradient ascent 是不是一次正确的 ascent。如果这次的得分不好, 那么就不要 ascent 那么多
Actor-Critic的优势:可以进行单步更新,比传统的Policy Gradient要快。
Actor-Critic的劣势:取决于Critic的价值判断,但是Critic难收敛,再加上Actor的更新,就更难收敛。

Advantage Actor-Critic
Q
π
(
s
,
a
)
=
V
π
(
s
)
+
A
π
(
s
,
a
)
Q^\pi(s,a) = V^\pi(s) + A^\pi(s,a)
Qπ(s,a)=Vπ(s)+Aπ(s,a)
A
π
(
s
,
a
)
=
Q
π
(
s
,
a
)
−
V
π
(
s
)
A^\pi(s,a)= Q^\pi(s,a) - V^\pi(s)
Aπ(s,a)=Qπ(s,a)−Vπ(s)
Advantage Actor-Critic采用了优势函数
缺点:需要估计2个网络:Q网络和 V网络。估计不准的风险变成原来的两倍。
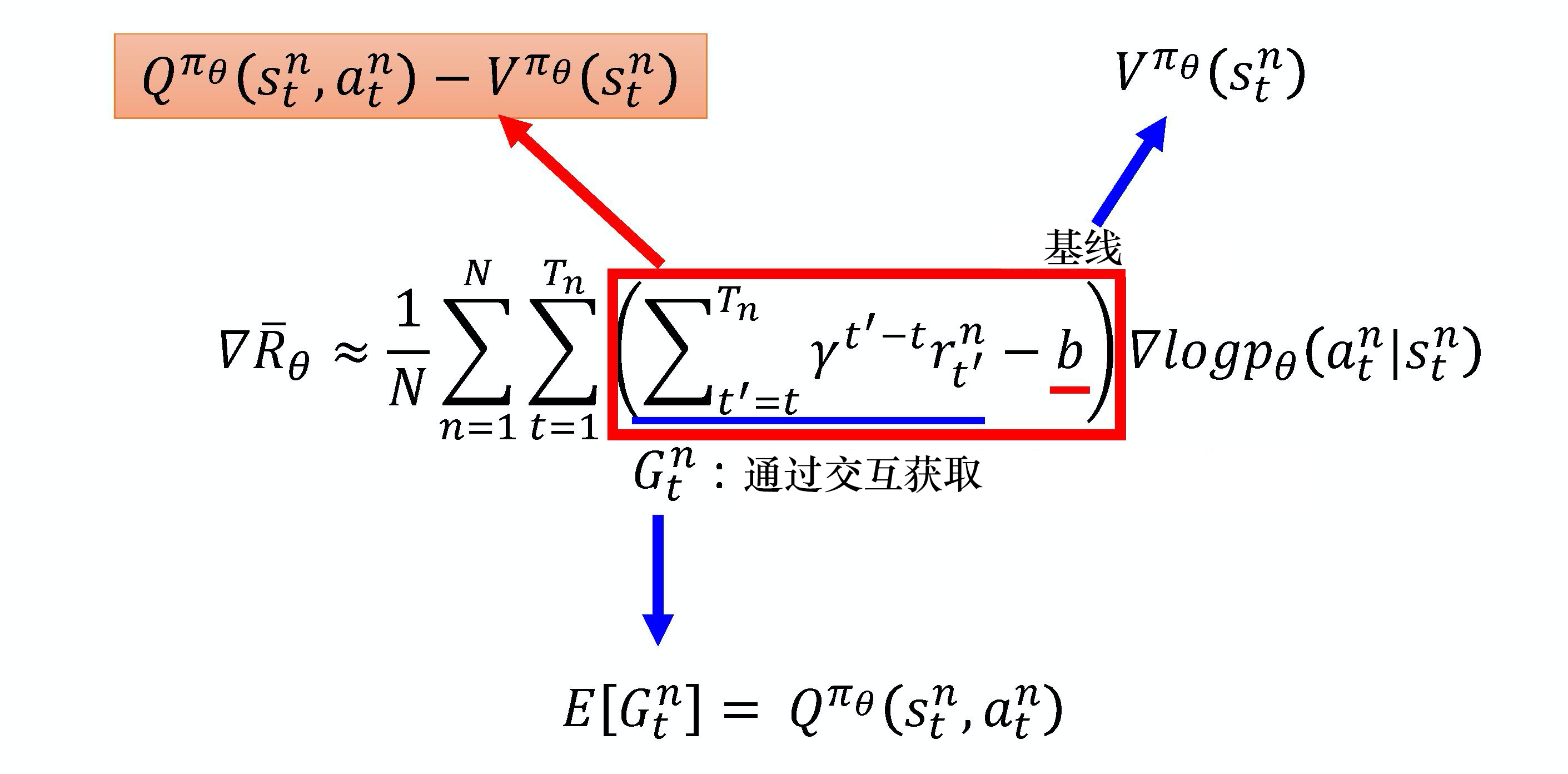
时序差分残差 Actor-Critic
A
π
(
s
t
,
a
t
)
=
Q
π
(
s
t
,
a
t
)
−
V
π
(
s
t
)
A^\pi(s_{t}, a_{t})= Q^\pi(s_{t}, a_{t}) - V^\pi(s_{t})
Aπ(st,at)=Qπ(st,at)−Vπ(st)
用
r
t
+
γ
V
π
(
s
t
+
1
)
r_{t}+ \gamma V^\pi(s_{t+1})
rt+γVπ(st+1)替换
Q
π
(
s
t
,
a
t
)
Q^\pi(s_{t}, a_{t})
Qπ(st,at)得到
r
t
+
γ
V
π
(
s
t
+
1
)
−
V
π
(
s
t
)
r_{t}+ \gamma V^\pi(s_{t+1}) - V^\pi(s_{t})
rt+γVπ(st+1)−Vπ(st)
不需要估计Q,只需要估计V
引入一个随机的参数r,r的方差小于G的方差
Critic网络Vπ(s)接收一个状态,输出一个标量。
Actor的策略π(s)接收一个状态,
如果动作是离散的,输出就是一个动作的分布。
如果动作是连续的,输出就是一个连续的向量。
Actor网络和Critic网络的输入都是s,所以它们前面几个层(layer)是可以共享的。
Asynchronous Advantage Actor-Critic (A3C)
[1602.01783] Asynchronous Methods for Deep Reinforcement Learning
异步优势演员-评论员算法
不同于经验回放,异步优势演员评论家在环境的多个实例上异步地并行执行多个代理。这种并行性还去相关代理的数据,变成一个更加平稳的过程中,因为在任何给定的时间步,并行代理都会经历各种不同的状态。
A3C同时使用很多个进程(worker),每一个进程就像一个影分身,最后这些影分身会把所有的经验值集合在一起。
如果CPU少,那么不好实现A3C,但可以实现Advantage Actor-Critic。

路径衍生策略梯度(pathwise derivative policy gradient)
路径衍生策略梯度
可以看成一种特别的DQN方法,解连续动作
可以看成一种特别的Actor-Critic方法
原来的Actor-Critic的问题:Critic只告诉Actor好或不好的,没有告诉Actor什么样是好。
Critic会直接告诉Actor什么动作才是好的。
- 策略π与环境交互并估计Q值。
- 固定Q值,只去学习一个Actor。假设这个Q值估得很准,它知道在某一个状态采取什么样的动作会得到很大的Q值。
接下来就学习这个Actor,Actor在给定s的时候,采取了a,可以让最后Q函数算出来的值越大越好。
我们用准则(criteria)去更新策略π

深度Q网络→路径衍生策略梯度

Actor-Critic and GAN
Connecting Generative Adversarial Network and Actor-Critic Methods
| Actor-Critic | GAN 生成对抗网络 | |
|---|---|---|
| Actor 演员 | generator 生成器 | |
| Critic 评论员 | discriminator 判别器 |

信赖域策略优化 (Trust Region Policy Optimization, TRPO)
基于策略的方法:参数化智能体的策略,并设计衡量策略好坏的目标函数,通过梯度上升的方法来最大化这个目标函数,使得策略最优。
策略梯度算法的缺点:当策略网络是深度模型时,沿着策略梯度更新参数,很有可能由于步长太长,策略突然显著变差,进而影响训练效果。
策略的改变导致数据分布的改变,这大大影响深度模型实现的策略网络的学习效果
TRPO算法优点:在理论上能够保证策略学习的性能单调性。
通过划定一个可信任的策略学习区域,保证策略学习的稳定性和有效性。
在 2015 年被提出
[1] SCHULMAN J, LEVINE S, ABBEEL P, et al. Trust region policy optimization [C]// International conference on machine learning, PMLR, 2015:1889-1897.

重要性采样
E
x
∼
p
[
f
(
x
)
]
=
∫
f
(
x
)
p
(
x
)
d
x
=
∫
f
(
x
)
p
(
x
)
q
(
x
)
q
(
x
)
d
x
=
E
x
∼
q
[
f
(
x
)
p
(
x
)
q
(
x
)
]
{{\mathbb{E}}_{x\sim p}}\left[ {f(x)} \right] = \int {f(x)p(x){\rm{d}}x} = \int {f(x){{p(x)} \over {q(x)}}q(x){\rm{d}}x} = {{\mathbb{E}}_{x\sim q}}\left[ {f(x){{p(x)} \over {q(x)}}} \right]
Ex∼p[f(x)]=∫f(x)p(x)dx=∫f(x)q(x)p(x)q(x)dx=Ex∼q[f(x)q(x)p(x)]
在重要性采样中将 p 替换为任意的 q,但是本质上要求两者的分布不能差太多
当我们对于两者的采样次数都比较多时,最终的结果会是较为接近的。但是通常我们不会取理想数量的采样数据,所以如果两者的分布相差较大,最后结果的方差将会很大。
如果在θ下的pθ(at∣st)与在θ′下的pθ′(at∣st)相差太多,那么会导致重要性采样结果偏差较大。
TRPO和PPO在训练的过程中增加一个限制,这个限制对应θ和θ′输出的动作的KL散度,来衡量θ与θ′的相似程度。
KL散度是一个函数,其度量的是两个动作(对应的参数分别为 θ 和 θ′ )间的行为距离,而不是参数距离。
行为距离:在相同状态下输出动作的差距(概率分布上的差距),概率分布即KL散度。
同策略
E
(
s
t
,
a
t
)
∼
π
θ
[
A
θ
(
s
t
,
a
t
)
∇
log
p
θ
(
a
t
n
∣
s
t
n
)
]
{{\mathbb{E}}_{\left( {{s_t},{a_t}} \right)\sim{\pi _\theta }}}\left[ {{A^\theta }\left( {{s_t},{a_t}} \right)\nabla \log {p_\theta }\left( {a_t^n|s_t^n} \right)} \right]
E(st,at)∼πθ[Aθ(st,at)∇logpθ(atn∣stn)]
异策略:行为策略是
θ
′
\theta ^\prime
θ′,目标策略是
θ
\theta
θ
E
(
s
t
,
a
t
)
∼
π
θ
′
[
p
θ
(
s
t
,
a
t
)
p
θ
′
(
s
t
,
a
t
)
A
θ
(
s
t
,
a
t
)
∇
log
p
θ
(
a
t
n
∣
s
t
n
)
]
{{\mathbb{E}}_{\left( {{s_t},{a_t}} \right)\sim{\pi _{{\theta ^\prime }}}}}\left[ {{{{p_\theta }\left( {{s_t},{a_t}} \right)} \over {{p_{{\theta ^\prime }}}\left( {{s_t},{a_t}} \right)}}{A^\theta }\left( {{s_t},{a_t}} \right)\nabla \log {p_\theta }\left( {a_t^n|s_t^n} \right)} \right]
E(st,at)∼πθ′[pθ′(st,at)pθ(st,at)Aθ(st,at)∇logpθ(atn∣stn)]
假设
A
θ
(
s
t
,
a
t
)
A^{\theta}(s_t,a_t)
Aθ(st,at)和
A
θ
′
(
s
t
,
a
t
)
A^{\theta'}(s_t,a_t)
Aθ′(st,at)可能是差不多的。
p
θ
(
s
t
,
a
t
)
=
p
θ
(
a
t
∣
s
t
)
p
θ
(
s
t
)
{p_\theta }\left( {{s_t},{a_t}} \right) = {p_\theta }\left( {{a_t}|{s_t}} \right){p_\theta }({s_t})
pθ(st,at)=pθ(at∣st)pθ(st)
p
θ
′
(
s
t
,
a
t
)
=
p
θ
′
(
a
t
∣
s
t
)
p
θ
′
(
s
t
)
{p_{\theta '}}\left( {{s_t},{a_t}} \right) = {p_{\theta '}}\left( {{a_t}|{s_t}} \right){p_{\theta '}}({s_t})
pθ′(st,at)=pθ′(at∣st)pθ′(st)
E
(
s
t
,
a
t
)
∼
π
θ
′
[
p
θ
(
a
t
∣
s
t
)
p
θ
(
s
t
)
p
θ
′
(
a
t
∣
s
t
)
p
θ
′
(
s
t
)
A
θ
′
(
s
t
,
a
t
)
∇
log
p
θ
(
a
t
n
∣
s
t
n
)
]
{{\mathbb{E}}_{\left( {{s_t},{a_t}} \right)\sim{\pi _{{\theta ^\prime }}}}}\left[ {{{{p_\theta }\left( {{a_t}|{s_t}} \right){p_\theta }({s_t})} \over {{p_{\theta '}}\left( {{a_t}|{s_t}} \right){p_{\theta '}}({s_t})}}{A^{\theta '}}\left( {{s_t},{a_t}} \right)\nabla \log {p_\theta }\left( {a_t^n|s_t^n} \right)} \right]
E(st,at)∼πθ′[pθ′(at∣st)pθ′(st)pθ(at∣st)pθ(st)Aθ′(st,at)∇logpθ(atn∣stn)]
假设
p
θ
(
s
t
)
=
p
θ
′
(
s
t
)
p_{\theta}(s_t)=p_{\theta'}(s_t)
pθ(st)=pθ′(st)
E
(
s
t
,
a
t
)
∼
π
θ
′
[
p
θ
(
a
t
∣
s
t
)
p
θ
′
(
a
t
∣
s
t
)
A
θ
′
(
s
t
,
a
t
)
∇
log
p
θ
(
a
t
n
∣
s
t
n
)
]
{{\mathbb{E}}_{\left( {{s_t},{a_t}} \right)\sim{\pi _{{\theta ^\prime }}}}}\left[ {{{{p_\theta }\left( {{a_t}|{s_t}} \right)} \over {{p_{\theta '}}\left( {{a_t}|{s_t}} \right)}}{A^{\theta '}}\left( {{s_t},{a_t}} \right)\nabla \log {p_\theta }\left( {a_t^n|s_t^n} \right)} \right]
E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)∇logpθ(atn∣stn)]
目标函数
J
θ
′
(
θ
)
=
E
(
s
t
,
a
t
)
∼
π
θ
′
[
p
θ
(
a
t
∣
s
t
)
p
θ
′
(
a
t
∣
s
t
)
A
θ
′
(
s
t
,
a
t
)
]
{J^{{\theta ^\prime }}}(\theta ) = {{\mathbb{E}}_{\left( {{s_t},{a_t}} \right)\sim{\pi _{{\theta ^\prime }}}}}\left[ {{{{p_\theta }\left( {{a_t}|{s_t}} \right)} \over {{p_{{\theta ^\prime }}}\left( {{a_t}|{s_t}} \right)}}{A^{{\theta ^\prime }}}\left( {{s_t},{a_t}} \right)} \right]
Jθ′(θ)=E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)]
广义优势估计(Generalized Advantage Estimation,GAE)
δ V = r t + γ V ( s t + 1 ) − V ( s ) \delta^V=r_t+\gamma V(s_{t+1})-V(s) δV=rt+γV(st+1)−V(s)
A ^ π ( 1 ) : = δ t V = − V ( s t ) + r t + γ V ( s t + 1 ) A ^ π ( 2 ) : = δ t V + γ δ t + 1 V = − V ( s t ) + r t + γ r t + 1 + γ 2 V ( s t + 2 ) A ^ π ( 3 ) : = δ t V + γ δ t + 1 V + γ 2 δ t + 2 V = − V ( s t ) + r t + γ r t + 1 + γ 2 r t + 2 + γ 3 V ( s t + 3 ) A ^ π ( k ) : = ∑ l = 0 k − 1 γ l δ t + l V = − V ( s t ) + r t + γ r t + 1 + ⋯ + γ k − 1 r t + k − 1 + γ k V ( s t + k ) \hat{A}_{\pi}^{(1)}:=\delta_t^V =-V(s_t)+r_t+\gamma V(s_{t+1}) \\ \hat{A}_{\pi}^{(2)}:=\delta_t^V+\gamma \delta_{t+1}^V =-V(s_t)+r_t+\gamma r_{t+1}+\gamma^2 V(s_{t+2}) \\ \hat{A}_{\pi}^{(3)}:=\delta_t^V+\gamma \delta_{t+1}^V+\gamma^2 \delta_{t+2}^V =-V(s_t)+r_t+\gamma r_{t+1}+\gamma^2 r_{t+2}+\gamma^3 V(s_{t+3}) \\ \hat{A}_{\pi}^{(k)}:=\sum_{l=0}^{k-1} \gamma^l \delta_{t+l}^V =-V(s_t)+r_t+\gamma r_{t+1}+\cdots+\gamma^{k-1} r_{t+k-1}+\gamma^k V(s_{t+k}) A^π(1):=δtV=−V(st)+rt+γV(st+1)A^π(2):=δtV+γδt+1V=−V(st)+rt+γrt+1+γ2V(st+2)A^π(3):=δtV+γδt+1V+γ2δt+2V=−V(st)+rt+γrt+1+γ2rt+2+γ3V(st+3)A^π(k):=∑l=0k−1γlδt+lV=−V(st)+rt+γrt+1+⋯+γk−1rt+k−1+γkV(st+k)
广义优势估计
GAE
(
γ
,
λ
)
\text{GAE}(\gamma, \lambda)
GAE(γ,λ)
A
^
π
:
=
(
1
−
λ
)
(
A
^
π
(
1
)
+
λ
A
^
π
(
2
)
+
λ
2
A
^
π
(
3
)
+
…
)
=
(
1
−
λ
)
(
δ
t
V
+
λ
(
δ
t
V
+
γ
δ
t
+
1
V
)
+
λ
2
(
δ
t
V
+
γ
δ
t
+
1
V
+
γ
2
δ
t
+
2
V
)
+
…
)
=
(
1
−
λ
)
(
δ
t
V
(
1
+
λ
+
λ
2
+
…
)
+
γ
δ
t
+
1
V
(
λ
+
λ
2
+
λ
3
+
…
)
.
+
γ
2
δ
t
+
2
V
(
λ
2
+
λ
3
+
λ
4
+
…
)
+
…
)
=
(
1
−
λ
)
(
δ
t
V
(
1
1
−
λ
)
+
γ
δ
t
+
1
V
(
λ
1
−
λ
)
+
γ
2
δ
t
+
2
V
(
λ
2
1
−
λ
)
+
…
)
=
∑
l
=
0
∞
(
γ
λ
)
l
δ
t
+
l
V
\hat{A}_{\pi}:= (1-\lambda)(\hat{A}_{\pi}^{(1)}+\lambda \hat{A}_{\pi}^{(2)}+\lambda^2 \hat{A}_{\pi}^{(3)}+\ldots) \\ = (1-\lambda)(\delta_t^V+\lambda(\delta_t^V+\gamma \delta_{t+1}^V)+\lambda^2(\delta_t^V+\gamma \delta_{t+1}^V+\gamma^2 \delta_{t+2}^V)+\ldots) \\ = (1-\lambda)(\delta_t^V(1+\lambda+\lambda^2+\ldots)+\gamma \delta_{t+1}^V(\lambda+\lambda^2+\lambda^3+\ldots) .+\gamma^2 \delta_{t+2}^V(\lambda^2+\lambda^3+\lambda^4+\ldots)+\ldots) \\ = (1-\lambda)(\delta_t^V(\frac{1}{1-\lambda})+\gamma \delta_{t+1}^V(\frac{\lambda}{1-\lambda})+\gamma^2 \delta_{t+2}^V(\frac{\lambda^2}{1-\lambda})+\ldots) \\ = \sum_{l=0}^{\infty}(\gamma \lambda)^l \delta_{t+l}^V
A^π:=(1−λ)(A^π(1)+λA^π(2)+λ2A^π(3)+…)=(1−λ)(δtV+λ(δtV+γδt+1V)+λ2(δtV+γδt+1V+γ2δt+2V)+…)=(1−λ)(δtV(1+λ+λ2+…)+γδt+1V(λ+λ2+λ3+…).+γ2δt+2V(λ2+λ3+λ4+…)+…)=(1−λ)(δtV(1−λ1)+γδt+1V(1−λλ)+γ2δt+2V(1−λλ2)+…)=∑l=0∞(γλ)lδt+lV
GAE
(
γ
,
0
)
:
A
^
π
:
=
δ
t
=
r
t
+
γ
V
(
s
t
+
1
)
−
V
(
s
t
)
\text{GAE}(\gamma, 0):\quad \hat{A}_{\pi}:=\delta_t =r_t+\gamma V(s_{t+1})-V(s_t)
GAE(γ,0):A^π:=δt=rt+γV(st+1)−V(st)
GAE
(
γ
,
1
)
:
A
^
π
:
=
∑
l
=
0
∞
γ
l
δ
t
+
l
=
∑
l
=
0
∞
γ
l
r
t
+
l
−
V
(
s
t
)
\text{GAE}(\gamma, 1):\quad \hat{A}_{\pi}:=\sum_{l=0}^{\infty} \gamma^l \delta_{t+l} =\sum_{l=0}^{\infty} \gamma^l r_{t+l}-V(s_t)
GAE(γ,1):A^π:=∑l=0∞γlδt+l=∑l=0∞γlrt+l−V(st)
0 ≤ λ ≤ 1 0\le\lambda\le1 0≤λ≤1
近端策略优化(proximal policy optimization,PPO)
TRPO算法的缺点:计算过程非常复杂,每一步更新的运算量非常大。
PPO的优点:简化了 TRPO 中的复杂计算,并且它在实验中的性能大多数情况下会比 TRPO 更好
在 2017年被提出
PPO 是 TRPO 的第一作者 John Schulman 从加州大学伯克利分校博士毕业后在 OpenAI 公司研究出来的。
[1] SCHULMAN J, FILIP W, DHARIWAL P, et al. Proximal policy optimization algorithms [J]. Machine Learning, 2017.
PPO是同策略算法
1.虽然PPO的优化目标涉及到了重要性采样,但其只用到了上一轮策略θ′的数据。
2.PPO目标函数中加入了KL散度的约束,行为策略θ′和目标策略θ非常接近,PPO的行为策略和目标策略可认为是同一个策略
PPO-惩罚(PPO-Penalty)
PPO-截断(PPO-Clip)
深度确定性策略梯度 (Deep Deterministic Policy Gradient, DDPG)
动作连续、off-policy、确定性策略(目标策略),单步更新
深度:使用了深度神经网络
确定性:输出的是一个确定的动作,可以用于连续动作环境
策略梯度:用到的是策略网络,并且每步都会更新一次,其是一个单步更新的策略网络。
off-policy的原因:
1.使用了经验回放
2.对输出动作加了一定的噪声,行为策略不再是优化的策略。
确定性策略:a=π(x),即在状态x下执行a动作;
随机性策略:P=π(x,a),即在状态x下执行a动作的概率。
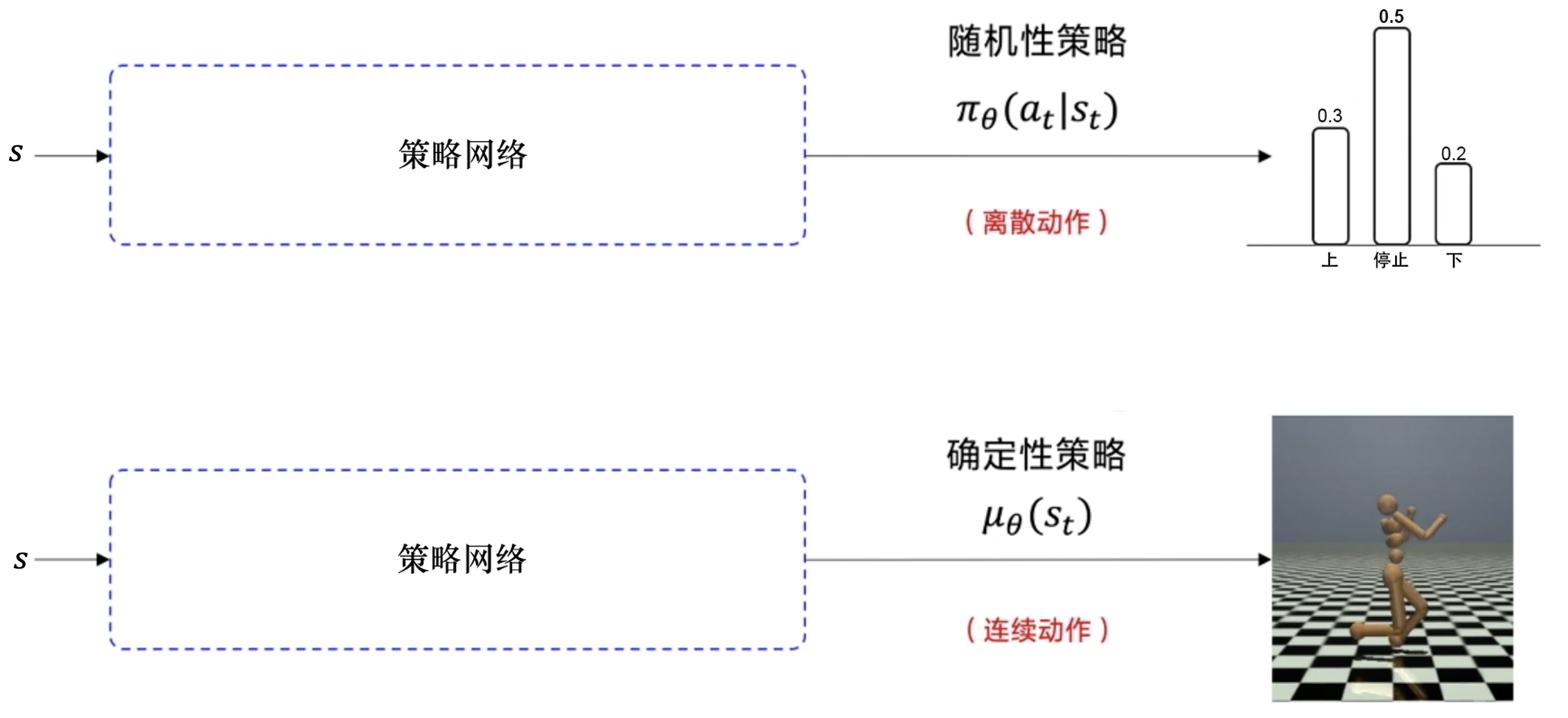
输出离散动作,加一层 softmax 层,确保所有的输出是动作概率,并且所有的动作概率和为 1。
输出连续动作,加一层 tanh 函数,把输出限制到 [−1,1],然后根据实际动作的范围将其缩放,再输出给环境。
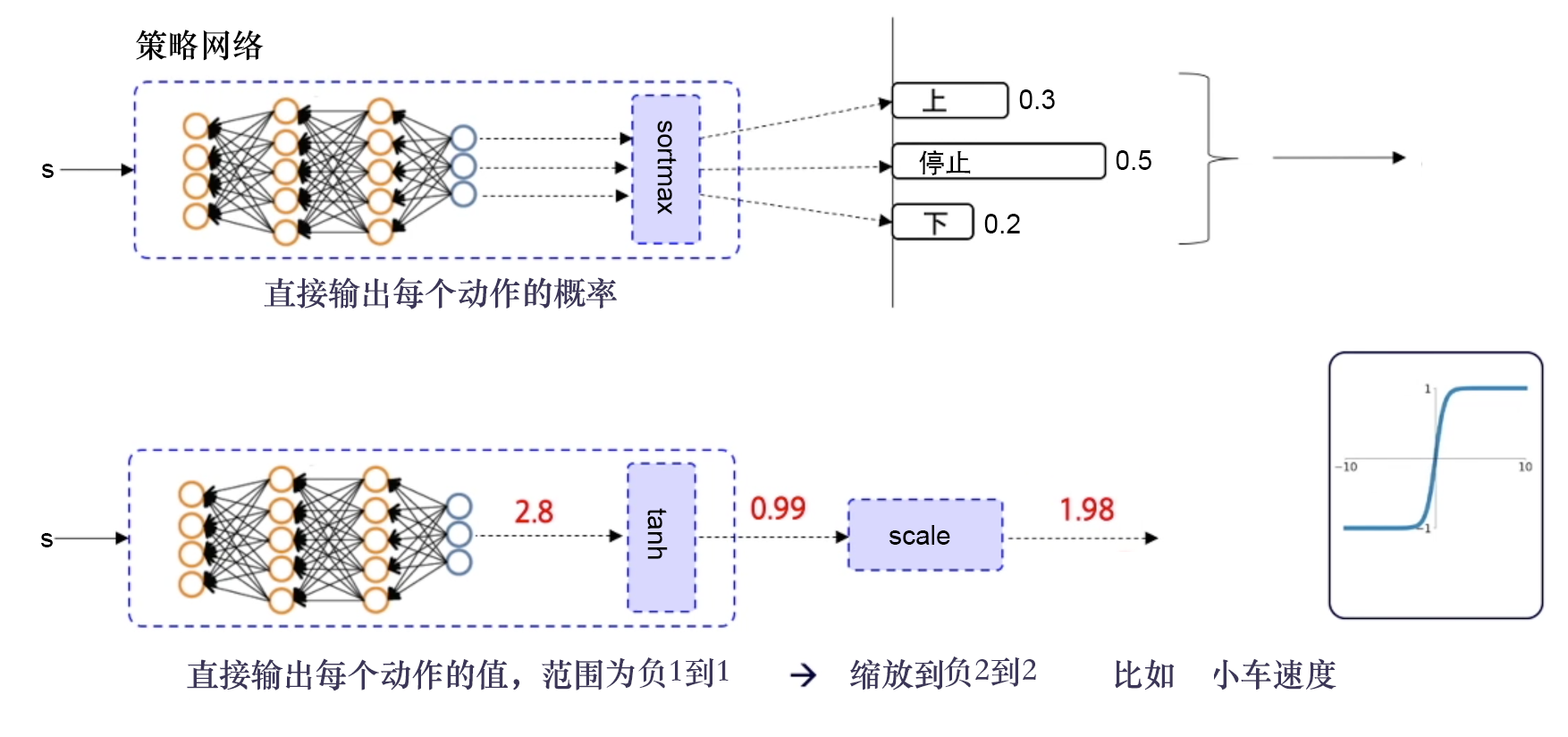
Google DeepMind提出的
使用Actor-Critic结构,结合了DQN结构的优势,提高了Actor-Critic的稳定性和收敛性。
由于有环境反馈的奖励存在,因此Critic的评分会越来越准确,所评判的Actor的表现也会越来越好。
优化策略网络的梯度:最大化Q值。损失函数:-Q。
优化Q网络:让Q网络的输出逼近Q_target。损失函数:Qw(s,a)和Q_target的均方差。
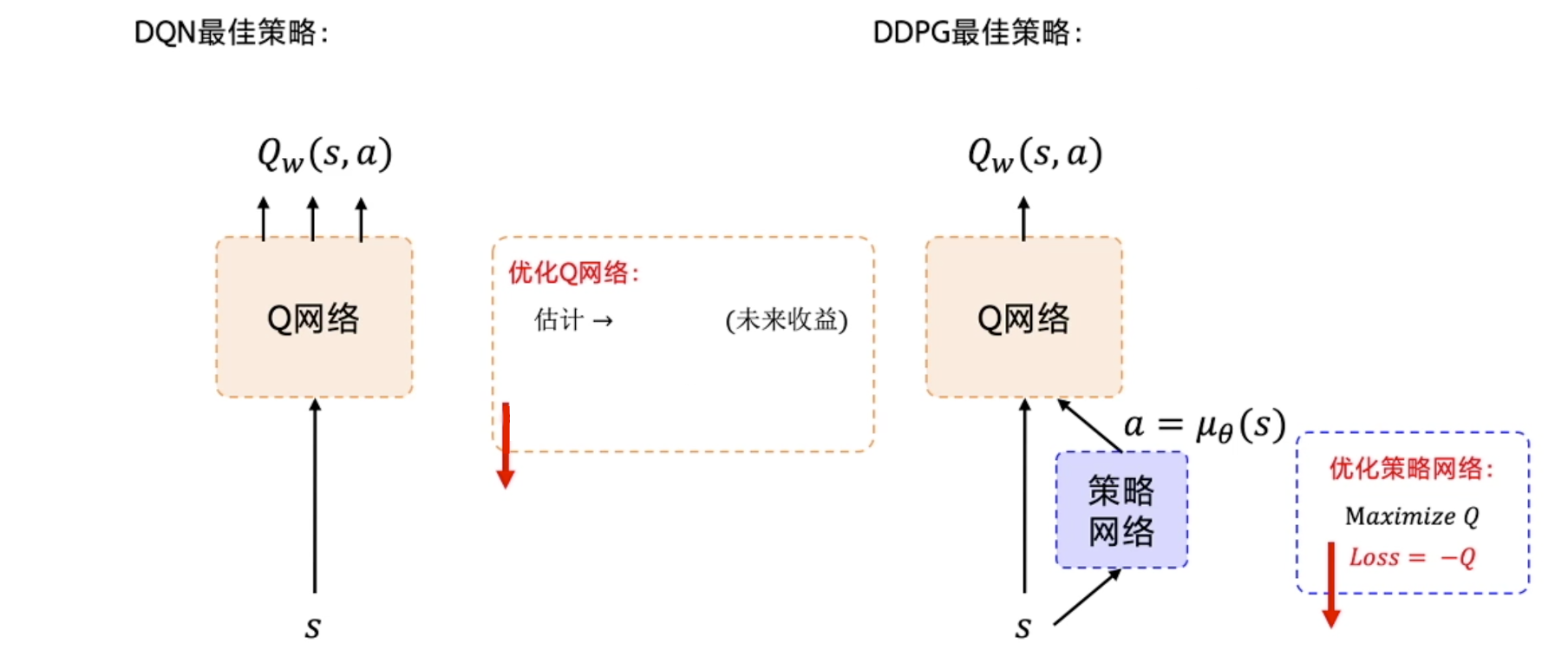
DDPG要用到4个神经网络,其中Actor和Critic各用1个网络,此外它们都各自有1个目标网络。
训练需要用到的数据:只需要s、a、r、s′
经验回放:用回放缓冲区把这些数据存起来,然后采样进行训练。经验回放的技巧与DQN中的是一样的。因为 DDPG 使用了经验回放技巧,所以 DDPG 是off-policy。
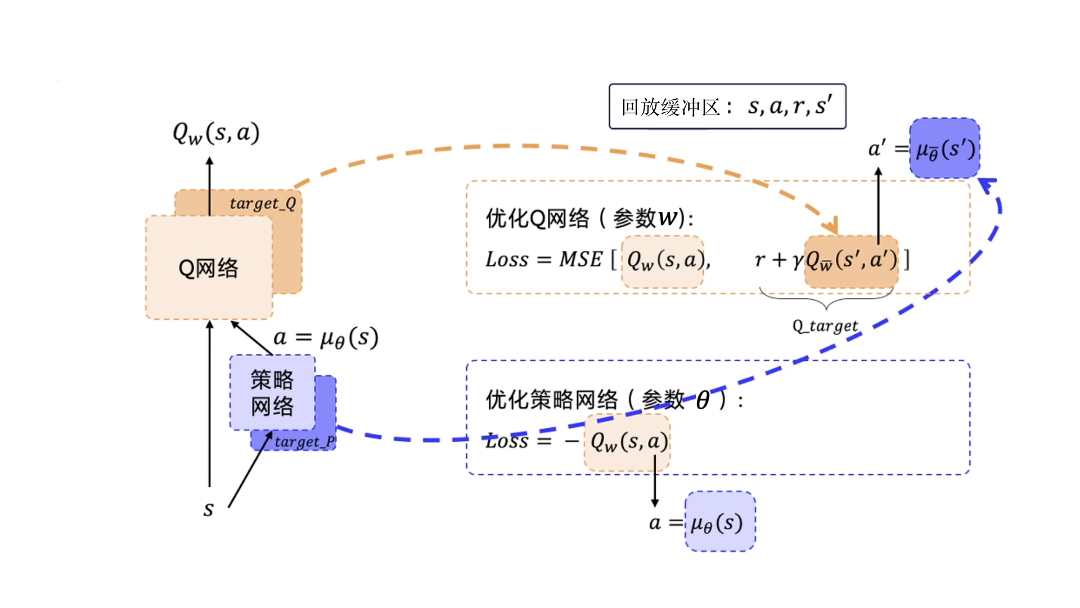
目标网络的更新
软更新: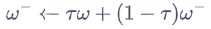
在DQN中,τ=1,即每隔一段时间将Q网络直接复制给目标Q网络;
在DDPG中,τ<1,目标Q网络逐渐接近Q网络。目标μ网络也使用这种软更新的方式。
DDPG采用了Double DQN中的技术来更新Q网络。
由于DDPG采用的是确定性策略,它本身的探索仍然十分有限。
DQN算法的探索:行为策略采用贪婪策略
DDPG算法的探索:行为策略引入随机噪声。不相关的、均值为 0 的高斯噪声
DDPG特点总结
- 目标网络:Actor和Critic,及其各自的1个目标网络,一共4个神经网络
- Actor网络:输入状态,输出动作(采用torch.tanh)
- Critic网络:输入状态和动作拼接后的向量,输出该状态动作对的价值
- 行为策略引入随机噪声
- 经验回放
- Actor和Critic的损失函数
- 目标网络采用软更新

双延迟深度确定性策略梯度(twin delayed DDPG,TD3)
双延迟深度确定性策略梯度
TD3代码
强化学习算法TD3论文的翻译与解读知乎
DDPG对于超参数和其他类型的调整方面经常很敏感。
DDPG常见的问题:已经学习好的 Q 函数开始显著地高估 Q 值,导致策略被破坏,因为它利用了 Q 函数中的误差。
截断的双 Q 学习(clipped double Q-learning)
TD3通过最小化均方差来同时学习两个Q函数:Q ϕ 1 和 Q ϕ 2 。
2个Q函数都使用一个目标,2个Q函数中给出的较小的值会被作为 Q-target
延迟的策略更新(delayed policy updates)
以较低的频率更新动作网络,以较高的频率更新评价网络
通常每更新2次评价网络就更新1次策略。
目标策略平滑(target policy smoothing)
在目标动作中加入噪声,通过平滑 Q 沿动作的变化,使策略更难利用 Q 函数的误差。
分布的分布式深度确定性策略梯度算法(distributed distributional DDPG,D4PG)
(distributed distributional deep deterministic policy gradient,D4PG)
相对于深度确定性策略梯度算法,其优化部分如下。
- 分布式评论员:不再只估计Q值的期望值,而是估计期望Q值的分布,即将期望Q值作为一个随机变量来估计。
- N步累计回报:计算时序差分误差时,D4PG计算的是N步的时序差分目标值而不仅仅只有一步,这样就可以考虑未来更多步骤的回报。
- 多个分布式并行演员:D4PG使用K个独立的演员并行收集训练数据并存储到同一个回放缓冲区中。
- 优先经验回放(prioritized experience replay,PER):使用一个非均匀概率从回放缓冲区中进行数据采样。
Soft Actor-Critic
off-policy、随机性策略
比DDPG稳定
Soft Actor-Critic
DDPG 的训练非常不稳定,收敛性较差,对超参数比较敏感,也难以适应不同的复杂环境。
2018 年,一个更加稳定的算法 Soft Actor-Critic(SAC)被提出。
SAC 的前身是 Soft Q-learning,它们都属于最大熵强化学习的范畴。
Soft Q-learning 不存在一个显式的策略函数,而是使用一个函数的波尔兹曼分布,在连续空间下求解非常麻烦。为了解决这个问题,SAC 提出使用一个 Actor 表示策略函数。
最大熵强化学习(maximum entropy RL)的思想就是除了要最大化累积奖励,还要使得策略更加随机。如此,强化学习的目标中就加入了一项熵的正则项
熵正则化增加了强化学习算法的探索程度,α越大,探索性就越强,有助于加速后续的策略学习,并减少策略陷入较差的局部最优的可能性。
最大熵强化学习:通过控制策略所采取动作的熵来调整探索与利用的平衡

目标导向的强化学习(goal-oriented reinforcement learning,GoRL)
目标导向的强化学习
事后经验回放(hindsight experience replay,HER)算法于 2017 年神经信息处理系统(Neural Information Processing Systems,NeurIPS)大会中被提出,成为 GoRL 的一大经典方法。
Pendulum by DDPG
pip install gym==0.25.2
python 3.11.7
# https://github.com/boyu-ai/Hands-on-RL/blob/main/%E7%AC%AC13%E7%AB%A0-DDPG%E7%AE%97%E6%B3%95.ipynb
import random
import gym
import numpy as np
from tqdm import tqdm
import torch
from torch import nn
import torch.nn.functional as F
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import rl_utils
# import time
class PolicyNet(torch.nn.Module):
# 策略网络的输出层用正切函数作为激活函数
# 因为正切函数的值域是[-1,1],方便按比例调整成环境可以接受的动作范围
def __init__(self, state_dim, hidden_dim, action_dim, action_bound):
super(PolicyNet, self).__init__()
self.linear1 = torch.nn.Linear(state_dim, hidden_dim)
self.linear2 = torch.nn.Linear(hidden_dim, action_dim)
self.action_bound = action_bound # action_bound是环境可以接受的动作最大值
def forward(self, x):
x = F.relu(self.linear1(x))
x = torch.tanh(self.linear2(x))
return x * self.action_bound
# return torch.tanh(self.fc2(x)) * self.action_bound
class QValueNet(torch.nn.Module):
# 在 DDPG 中处理的是与连续动作交互的环境
# 网络的输入是状态和动作拼接后的向量
# 网络的输出是一个值,表示该状态动作对的价值
def __init__(self, state_dim, hidden_dim, action_dim):
super(QValueNet, self).__init__()
self.linear1 = torch.nn.Linear(state_dim + action_dim, hidden_dim)
self.linear2 = torch.nn.Linear(hidden_dim, hidden_dim)
self.linear_out = torch.nn.Linear(hidden_dim, 1)
def forward(self, x, a):
cat = torch.cat([x, a], dim=1) # 拼接状态和动作
x = F.relu(self.linear1(cat))
x = F.relu(self.linear2(x))
x = self.linear_out(x)
return x
class DDPG:
''' DDPG算法 '''
def __init__(self, state_dim, hidden_dim, action_dim, action_bound, sigma, actor_lr, critic_lr, tau, gamma, device):
self.actor = PolicyNet(state_dim, hidden_dim, action_dim, action_bound).to(device)
self.critic = QValueNet(state_dim, hidden_dim, action_dim).to(device)
self.target_actor = PolicyNet(state_dim, hidden_dim, action_dim, action_bound).to(device)
self.target_critic = QValueNet(state_dim, hidden_dim, action_dim).to(device)
# 初始化目标价值网络:设置和价值网络相同的参数
self.target_critic.load_state_dict(self.critic.state_dict())
# 初始化目标策略网络:设置和策略相同的参数
self.target_actor.load_state_dict(self.actor.state_dict())
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)
self.gamma = gamma # gamma 折扣
self.sigma = sigma # 高斯噪声的标准差,均值直接设为0
self.tau = tau # 目标网络软更新参数
self.action_dim = action_dim
self.device = device
def take_action_noise(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
action = self.actor(state).item()
# 给动作添加噪声,增加探索
action = action + self.sigma * np.random.randn(self.action_dim)
return action
def take_action(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
action = self.actor(state).item()
action = action + np.array([0])
return action
def soft_update(self, net, target_net):
for param_target, param in zip(target_net.parameters(), net.parameters()):
param_target.data.copy_(param_target.data * (1.0 - self.tau) + param.data * self.tau)
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions'], dtype=torch.float).view(-1, 1).to(self.device)
rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1, 1).to(self.device)
# 更新价值网络 critic
next_q_values = self.target_critic(next_states, self.target_actor(next_states)) # 用目标网络计算
q_targets = rewards + self.gamma * next_q_values * (1 - dones)
# 价值网络的损失
critic_loss = torch.mean(F.mse_loss(self.critic(states, actions), q_targets))
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# 更新策略网络 actor
# 策略网络的损失
actor_loss = -torch.mean(self.critic(states, self.actor(states)))
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
self.soft_update(self.actor, self.target_actor) # 软更新目标策略网络
self.soft_update(self.critic, self.target_critic) # 软更新目标价值网络
actor_lr = 3e-4
critic_lr = 3e-3
num_episodes = 200
hidden_dim = 64
gamma = 0.98
tau = 0.005 # 软更新参数
buffer_size = 10000
minimal_size = 1000
batch_size = 64
sigma = 0.01 # 高斯噪声标准差
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
env_name = 'Pendulum-v1'
env = gym.make(env_name)
random.seed(0)
np.random.seed(0)
# env.seed(0)
env.reset(seed=0)
torch.manual_seed(0)
replay_buffer = rl_utils.ReplayBuffer(buffer_size)
state_dim = env.observation_space.shape[0]
print(state_dim)
action_dim = env.action_space.shape[0]
action_bound = env.action_space.high[0] # 动作最大值
agent = DDPG(state_dim, hidden_dim, action_dim, action_bound, sigma, actor_lr, critic_lr, tau, gamma, device)
print('Training!!!!')
# time_start = time.perf_counter() # 记录开始时间
return_list = rl_utils.train_off_policy_agent(env, agent, num_episodes, replay_buffer, minimal_size, batch_size)
# time_end = time.perf_counter() # 记录结束时间
# time_sum = time_end - time_start # 计算的时间差为程序的执行时间,单位为秒/s
# print('time = %f' %time_sum)
plt.figure()
plt.plot(list(range(len(return_list))), return_list, label='rewards')
return_list_mv = rl_utils.moving_average(return_list, 9)
# return_list_mv = rl_utils.smooth(return_list, weight=0.9)
plt.plot(list(range(len(return_list_mv))), return_list_mv, label='smoothed')
plt.xlabel('Episodes')
plt.ylabel('Rewards')
plt.title('DDPG on {} (Training)'.format(env_name))
plt.legend(loc='best')
plt.grid()
plt.show()
print('Testing!!!!')
num_episodes_test = 50
return_list_test = rl_utils.test_agent(env, agent, num_episodes_test)
plt.figure()
plt.plot(list(range(len(return_list_test))), return_list_test, label='rewards')
return_list_mv_test = rl_utils.moving_average(return_list_test, 3)
# return_list_mv_test = rl_utils.smooth(return_list_test, weight=0.9)
plt.plot(list(range(len(return_list_mv_test))), return_list_mv_test, label='smoothed')
plt.xlabel('Episodes')
plt.ylabel('Rewards')
plt.title('DDPG on {} (Testing)'.format(env_name))
plt.legend(loc='best')
plt.grid()
plt.show()
print('Rendering!!!!')
rl_utils.test_agent_render(env, agent)
rl_utils.py
# from tqdm import tqdm
import numpy as np
import torch
import collections
import random
import time
class ReplayBuffer:
def __init__(self, capacity):
self.buffer = collections.deque(maxlen=capacity)
def add(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
transitions = random.sample(self.buffer, batch_size)
state, action, reward, next_state, done = zip(*transitions)
return np.array(state), action, reward, np.array(next_state), done
def size(self):
return len(self.buffer)
def compute_advantage(gamma, lmbda, td_delta):
td_delta = td_delta.detach().numpy()
advantage_list = []
advantage = 0.0
for delta in td_delta[::-1]:
advantage = gamma * lmbda * advantage + delta
advantage_list.append(advantage)
advantage_list.reverse()
return torch.tensor(advantage_list, dtype=torch.float)
def moving_average(a, window_size):
cumulative_sum = np.cumsum(np.insert(a, 0, 0))
middle = (cumulative_sum[window_size:] - cumulative_sum[:-window_size]) / window_size
r = np.arange(1, window_size-1, 2)
begin = np.cumsum(a[:window_size-1])[::2] / r
end = (np.cumsum(a[:-window_size:-1])[::2] / r)[::-1]
return np.concatenate((begin, middle, end))
def smooth(data, weight=0.9):
'''用于平滑曲线,类似于Tensorboard中的smooth
Args:
data (List):输入数据
weight (Float): 平滑权重,处于0-1之间,数值越高说明越平滑,一般取0.9
Returns:
smoothed (List): 平滑后的数据
'''
last = data[0] # First value in the plot (first timestep)
smoothed = list()
for point in data:
smoothed_val = last * weight + (1 - weight) * point # 计算平滑值
smoothed.append(smoothed_val)
last = smoothed_val
return smoothed
def train_on_policy_agent(env, agent, num_episodes):
return_list = []
for i_episode in range(int(num_episodes)):
episode_return = 0
transition_dict = {'states': [], 'actions': [], 'next_states': [], 'rewards': [], 'dones': []}
state = env.reset()
done = False
while not done:
action = agent.take_action(state)
next_state, reward, done, _ = env.step(action)
transition_dict['states'].append(state)
transition_dict['actions'].append(action)
transition_dict['next_states'].append(next_state)
transition_dict['rewards'].append(reward)
transition_dict['dones'].append(done)
state = next_state
episode_return += reward
return_list.append(episode_return)
agent.update(transition_dict)
if (i_episode+1)%10 == 0:
time_end = time.perf_counter() # 记录结束时间
time_sum = time_end - time_start # 计算的时间差为程序的执行时间,单位为秒/s
print(f"episodes: {i_episode+1}/{num_episodes}, rewards: {episode_return:.2f}, time consumption: {time_sum:.2f}s")
return return_list
def train_off_policy_agent(env, agent, num_episodes, replay_buffer, minimal_size, batch_size):
return_list = []
time_start = time.perf_counter() # 记录开始时间
for i_episode in range(int(num_episodes)):
episode_return = 0
state = env.reset()
done = False
while not done:
action = agent.take_action_noise(state)
next_state, reward, done, _ = env.step(action)
replay_buffer.add(state, action, reward, next_state, done)
state = next_state
episode_return += reward
if replay_buffer.size() > minimal_size:
b_s, b_a, b_r, b_ns, b_d = replay_buffer.sample(batch_size)
transition_dict = {'states': b_s, 'actions': b_a, 'next_states': b_ns, 'rewards': b_r, 'dones': b_d}
agent.update(transition_dict)
return_list.append(episode_return)
if (i_episode+1)%10 == 0:
time_end = time.perf_counter() # 记录结束时间
time_sum = time_end - time_start # 计算的时间差为程序的执行时间,单位为秒/s
print(f"episodes: {i_episode+1}/{num_episodes}, rewards: {episode_return:.2f}, time consumption: {time_sum:.2f}s")
return return_list
def test_agent(env, agent, num_episodes):
return_list = []
for i_episode in range(int(num_episodes)):
episode_return = 0
state = env.reset()
done = False
while not done:
action = agent.take_action(state)
next_state, reward, done, _ = env.step(action)
state = next_state
episode_return += reward
return_list.append(episode_return)
return return_list
def test_agent_render(env, agent):
# 环境初始化
state = env.reset()
# 循环交互
while True:
# 渲染画面
env.render()
# 从动作空间随机获取一个动作
# action = env.action_space.sample()
action = agent.take_action(state)
# agent与环境进行一步交互
next_state, reward, done, _ = env.step(action)
# print('state = {0}; reward = {1}'.format(next_state, reward))
state = next_state
# 判断当前episode 是否完成
if done:
print('done')
break
time.sleep(0.06)
# 环境结束
env.close()
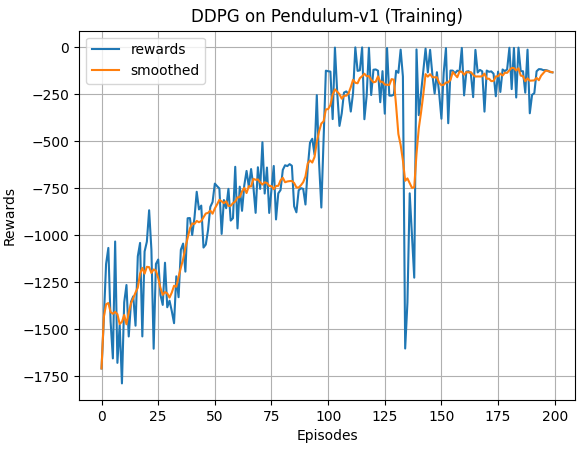
奖励关于episode的曲线(训练)
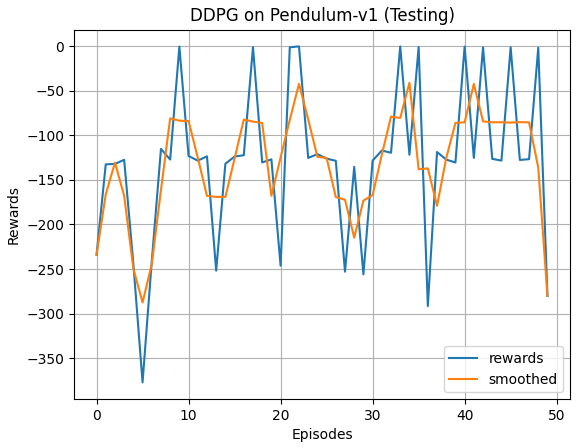
奖励关于episode的曲线(测试)
render
















 7960
7960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











