







一.什么是Dropout(暂退法)?
在前向传播过程中,计算每⼀内部层的同时注⼊噪声,这种方法被称为暂退法(dropout)。
特点
• 暂退法在前向传播过程中,计算每⼀内部层的同时丢弃⼀些神经元。
• 暂退法可以避免过拟合,它通常与控制权重向量的维数和⼤⼩结合使⽤的。
• 暂退法将活性值h替换为具有期望值h的随机变量。
• 暂退法仅在训练期间使⽤。
二.原理
一个好的模型不应该对其输⼊的微⼩变化所影响。例如,当我们对图像进⾏分类时,我们预计向像素添加⼀些随机噪声应该是基本⽆影响的。这样的模型就有适应性,缓解过拟合就要增加模型的适应性。
三.方法
缓解过拟合的方法:在某些层注入不影响该层期望的噪声。
1.线性模型中:

2.神经网络中
在标准暂退法正则化中,通过按保留(未丢弃)的节点的分数进⾏规范化来消除每⼀层的偏差。换⾔之,每个中间层的激活值h以暂退概率p由随机变量h′替换,如下所⽰:
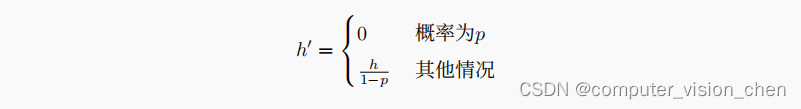
即当概率为p时,h’=0,当概率为1-p时,h’=h/(1-p)
代入随机变量的期望公式得:
E[h'] = 0 * p + h / (1-p) * (1-p) = h
因此,随机将某些神经元置0,其期望值保持不变,即E[h‘] = h。
神经网络dropout可视化
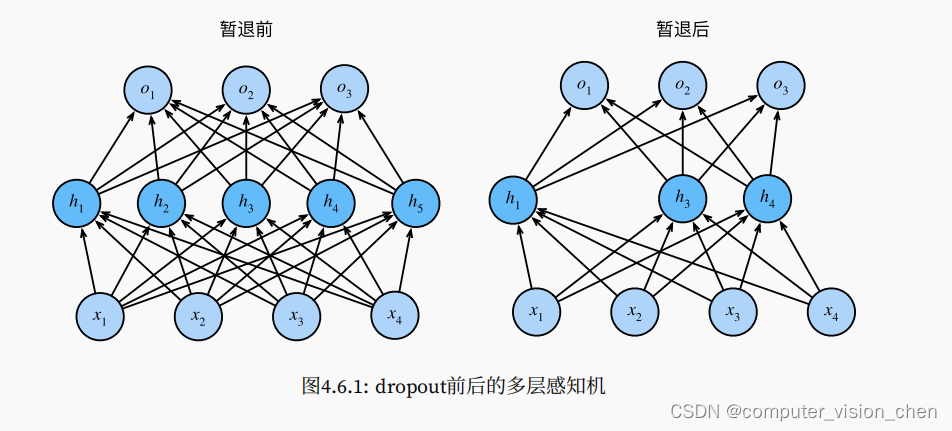
删除了h2,h5之后,输出的计算不再依赖于h2,h5,它们各自的梯度在执行方向传播时也会消失。
代码实现
import torch
from torch import nn
from d2l import torch as d2l
# 对某一层进行dropout
def dropout_layer(X,dropout):
assert 0<= dropout <=1
# 当dropout的概率为1时,那就是所有元素都被丢弃
if dropout ==1:
return torch.zeros_like(X)
# 所有元素都被保留
if dropout ==0:
return X
# torch.rand()返回一个张量,该张量每个元素都是从[0,1)的均匀分布采样而得。相当于为输入X的每个值(神经元)都分配一个概率值
prob = torch.rand(X.shape,dtype=torch.float32)
print(f'prob={prob}')
# 如果某个神经元的概率prop > dropout的概率,则mask对应的位置赋值为1,否则赋值为0
mask = (prob > dropout).float()
print(f'mask={mask}')
return mask * X / (1.0-dropout) # 置0概率<dropout概率的神经元,并缩放剩下的神经元的值
X = torch.arange(16,dtype=torch.float32).reshape((2,8))
print(X)
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
# 神经元概率大于0.5时,该神经元将会被置0
print(f'result = {dropout_layer(X,0.5)}')
prob=tensor([[0.4099, 0.6338, 0.8541, 0.0259, 0.4162, 0.2124, 0.8146, 0.5110],
[0.6377, 0.5202, 0.9243, 0.1278, 0.7006, 0.9055, 0.2089, 0.8652]])
mask=tensor([[0., 1., 1., 0., 0., 0., 1., 1.],
[1., 1., 1., 0., 1., 1., 0., 1.]])
result = tensor([[ 0., 2., 4., 0., 0., 0., 12., 14.],
[16., 18., 20., 0., 24., 26., 0., 30.]])
四.补充
一. 求期望的公式
1. 随机变量的期望
随机变量的期望是对所有可能取值(或离散型变量的可能取值和概率)的加权平均。
对于离散型随机变量X,其期望E(X)可以用以下公式表示:
E(X) = Σ(x * P(X=x))
其中,x代表随机变量X的取值,P(X=x)代表X等于x的概率。
2. 连续型随机变量的期望
对于连续型随机变量X,其期望E(X)可以用以下公式表示:
E(X) = ∫(x * f(x))dx
其中,f(x)为随机变量X的概率密度函数。
二. 以掷骰子为例子计算随机期望
掷骰子时,随机变量是1, 2, 3, 4, 5, 6,每个数字出现的概率是1/6。
对于掷骰子这个例子,我们可以计算期望:
E(X) = (1 * 1/6) + (2 * 1/6) + (3 * 1/6) + (4 * 1/6) + (5 * 1/6) + (6 * 1/6)
= (1 + 2 + 3 + 4 + 5 + 6) / 6
= 3.5
因此,在掷骰子的过程中,随机变量X的期望是3.5。这意味着,在长期重复的掷骰子实验中,我们预计每次投掷的平均点数将接近于3.5。
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











