







 本文详细描述了如何在Python环境下安装和配置Langchain-Chatchat项目,涉及环境准备、依赖管理、大模型下载、向量数据库初始化以及项目启动过程,包括GitLFS的安装和使用,以及Swagger接口文档查看。
本文详细描述了如何在Python环境下安装和配置Langchain-Chatchat项目,涉及环境准备、依赖管理、大模型下载、向量数据库初始化以及项目启动过程,包括GitLFS的安装和使用,以及Swagger接口文档查看。
首先放上该方案项目的git地址:https://github.com/chatchat-space/Langchain-Chatchat
以下是我的搭建和踩坑经验记录
一、环境准备
1、python安装
在环境中安装python,我安装的是3.9版本的python,官方要求的是Python 3.8 - 3.10 版本。不知道如何查看版本的,请使用这个命令:python --version
2、项目依赖
挑选一个自己看着顺眼的目录,拉取项目依赖:
git clone https://github.com/chatchat-space/Langchain-Chatchat.git
拉取完毕后,进入该目录:
cd Langchain-Chatchat
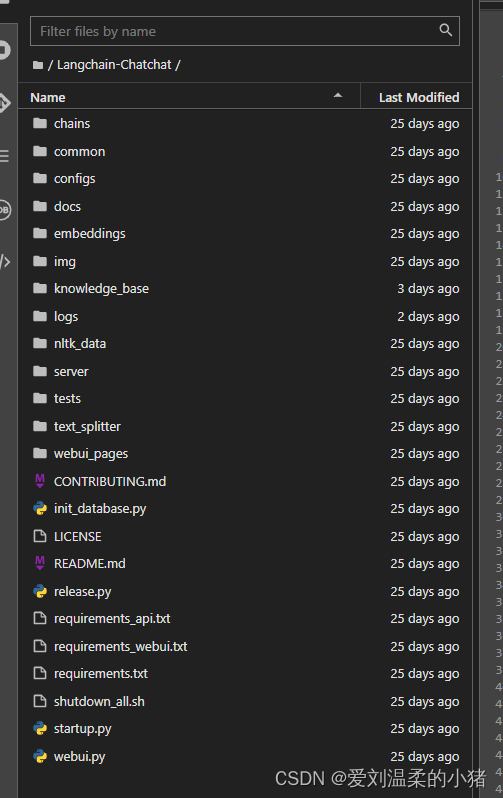
可以看到目录里有三个文件: requirements.txt 、requirements_api.txt、requirements_webui.txt 。
requirements.txt :
代表项目的python全部依赖,如果既需要自带的画面展示,又需要将api接口开放出来,就选择这个全部依赖安装。
requirements_api.txt:代表只启动本项目api服务所需的依赖。
requirements_webui.txt:代表只启动本项目web端服务所需要的依赖。
根据自己需求选择安装依赖,我是全部安装,也就是执行pip install -r requirements.txt命令。另外两个命令如下:
pip install -r requirements_api.txt
pip install -r requirements_webui.txt
如果出现了依赖冲突,就用pip uninstall 依赖名 去卸载原本依赖,然后看提示信息需要的版本,使用pip install 模板名==版本在这里插入代码片 来安装指定版本的依赖。然后重新执行pip install -r requirements.txt一定要确保依赖全部安装成功。
3、git大文件存储功能安装
在下载大模型之前确保git安装了大文件存储,也就是Git LFS,不确定是否安装的话用这个命令看一下:git lfs install,出现如下提示就是已经安装了git lfs:

如果没安装git lfs,根据你的依赖包管理工具的类型来安装一下git lfs:
- 包管理是apt/deb的,执行这个命令:
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash然后执行sudo apt-get install git-lfs来安装。 - 包管理是yum/rpm的,执行这个命令:
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.rpm.sh | sudo bash然后执行sudo yum install git-lfs来安装。
记得安装完之后,git lfs install看一下是否安装成功。
4、大模型下载与配置
选择目录的另一个地方,执行git clone https://huggingface.co/THUDM/chatglm2-6b 拉取大模型,一定要完整拉取成功。
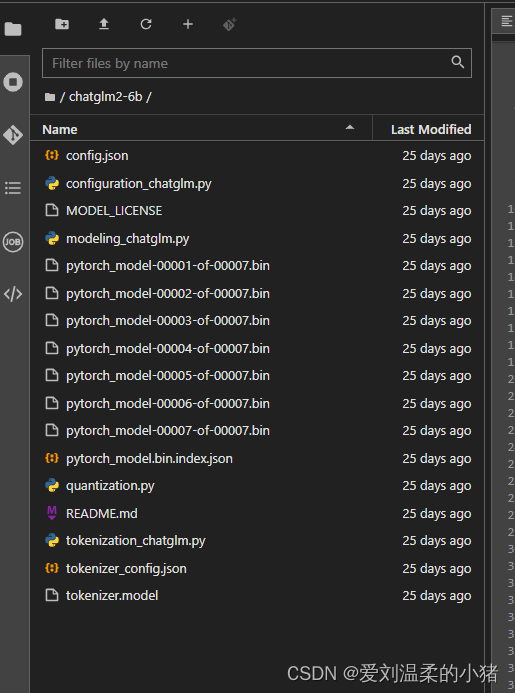
在次选择目录的另一个地方,执行git clone https://huggingface.co/moka-ai/m3e-base 拉取分词嵌入式模型,这个比上边那个大模型小。
我拉取完毕的整体结构如下:
确保没问题后,开始配置:
- 复制模型相关参数配置模板文件 configs/model_config.py.example 存储至项目路径下 ./configs
路径下,并重命名为 model_config.py。 - 复制服务相关参数配置模板文件 configs/server_config.py.example 存储至项目路径下 ./configs
路径下,并重命名为 server_config.py。
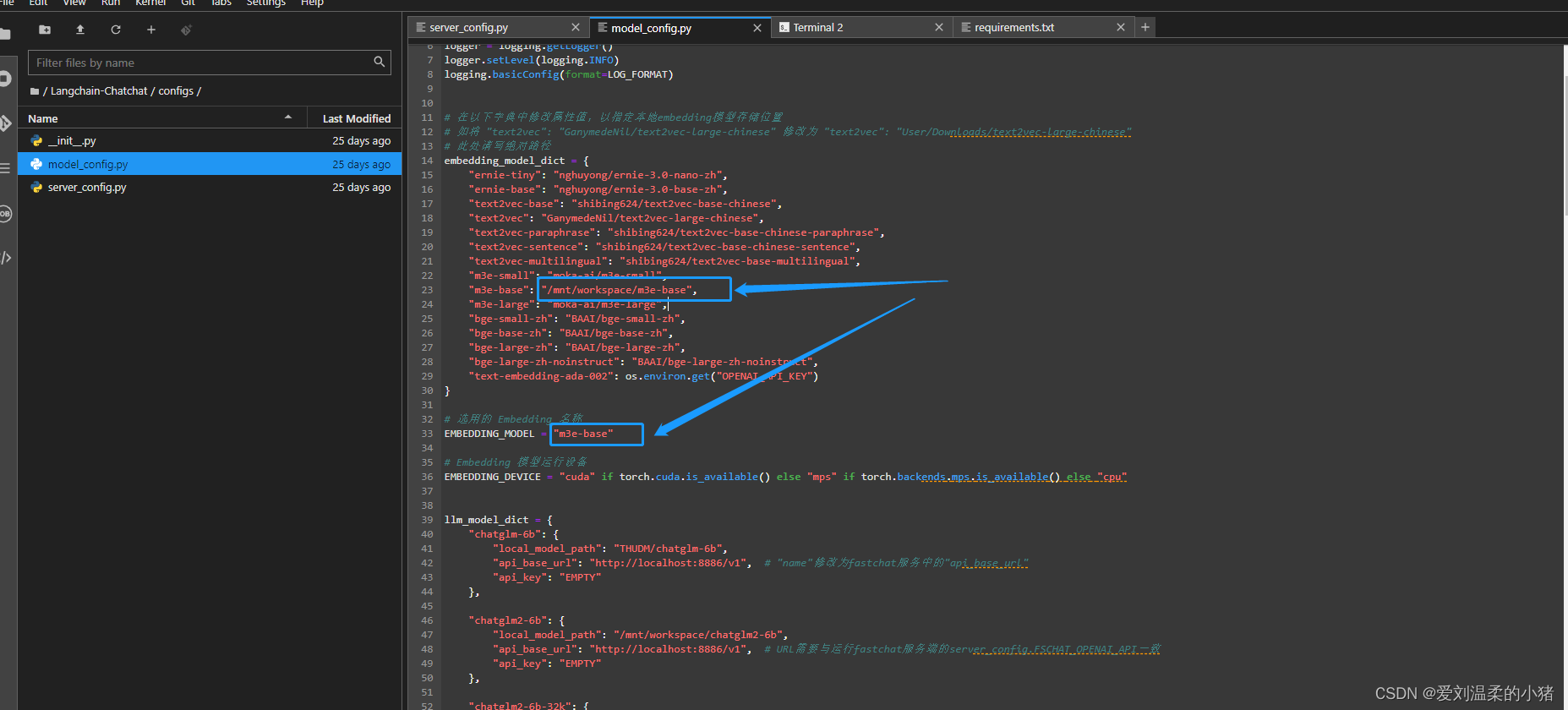
在model_config.py文件中,修改这两个,对应好你下载的两个大模型目录和名称,一定要是绝对路径。
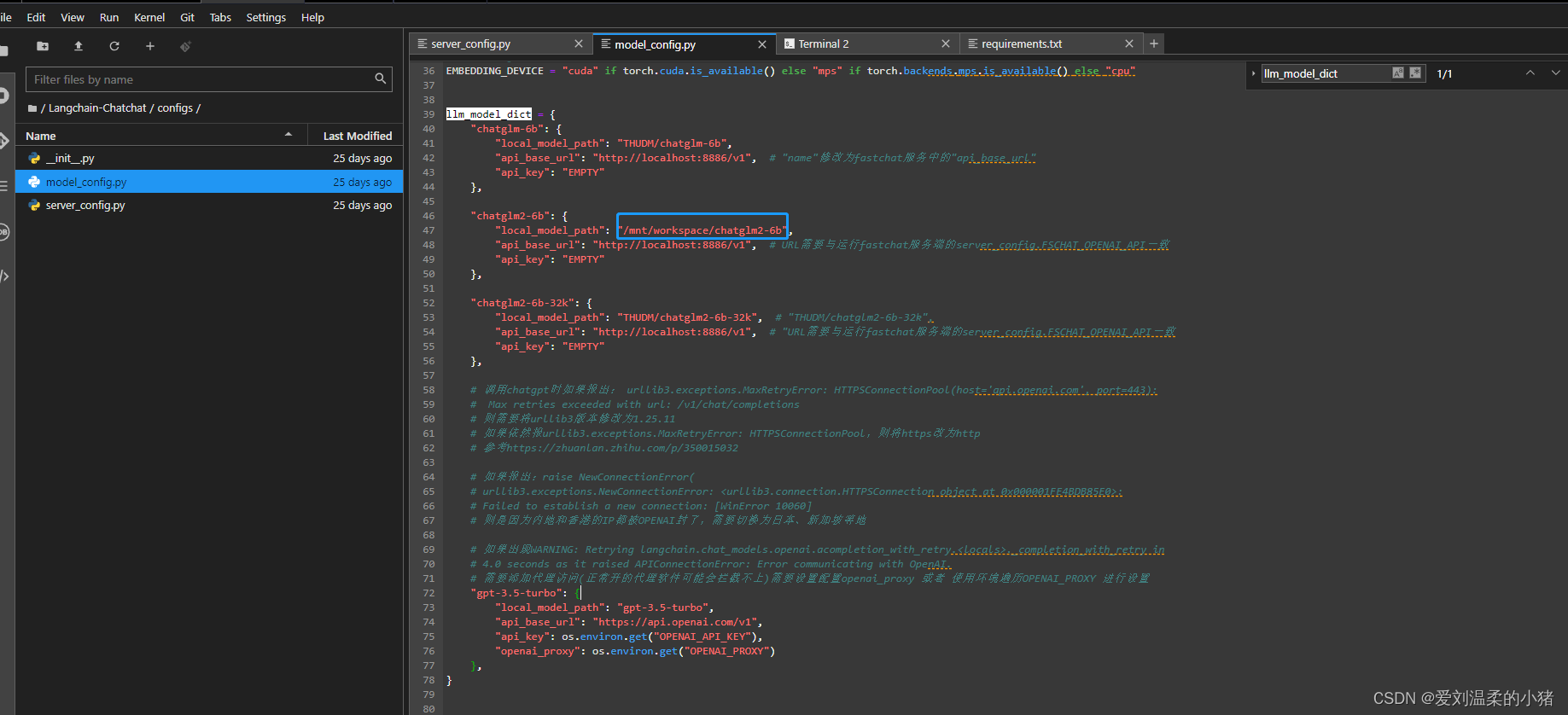
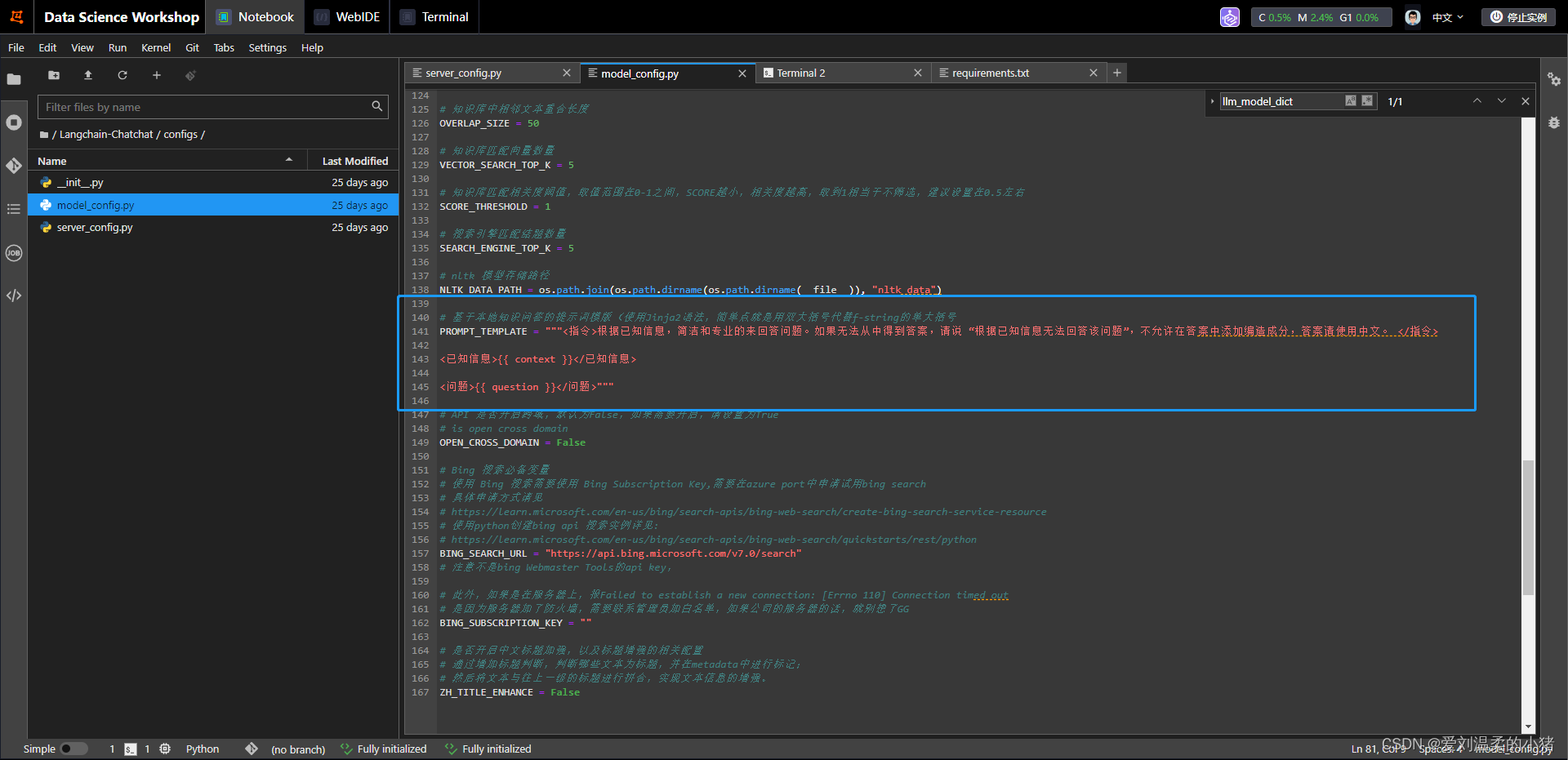
当然,如果你想修改提示词模板的话,改这里就行:
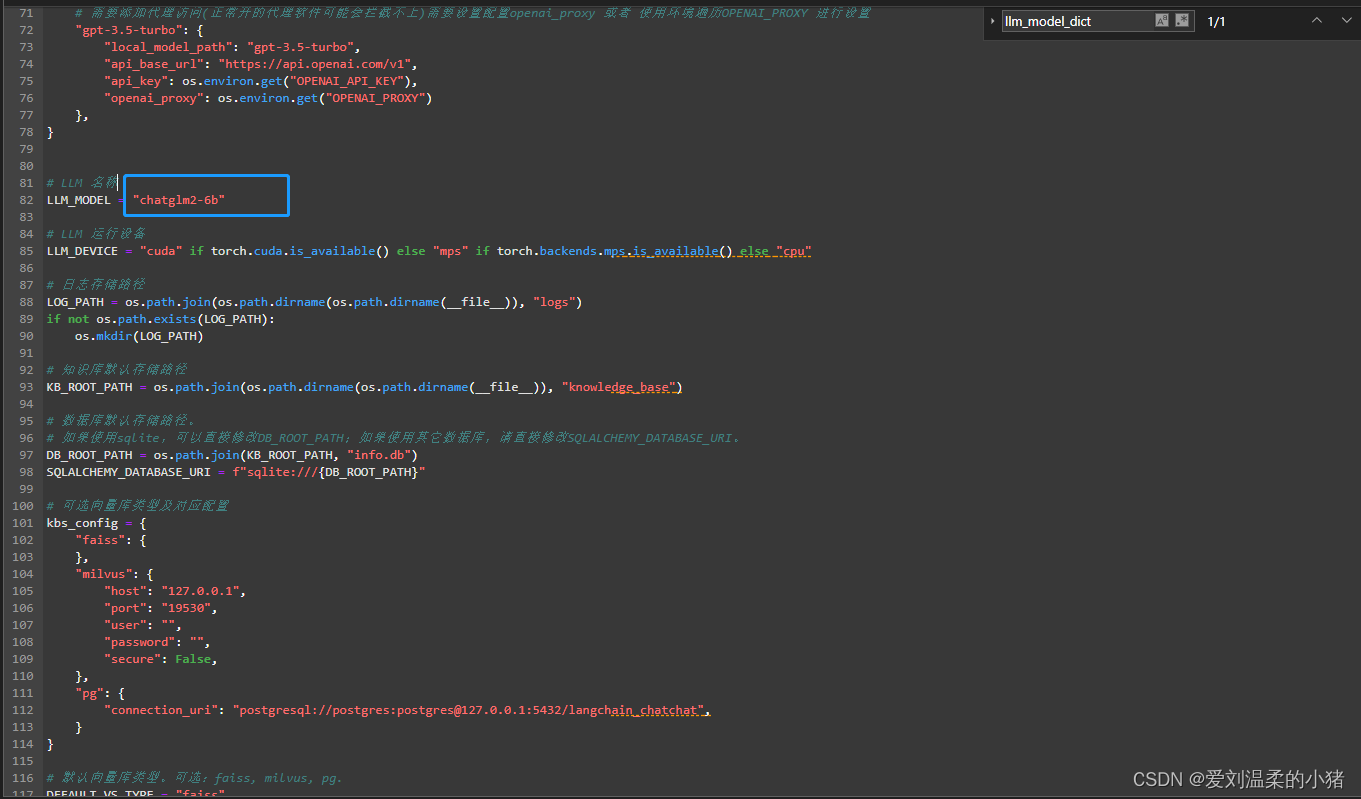
server_config.py文件中没什么要修改的,除非你想改多卡配置或者是api端口等。想修改API端口看下方图片:
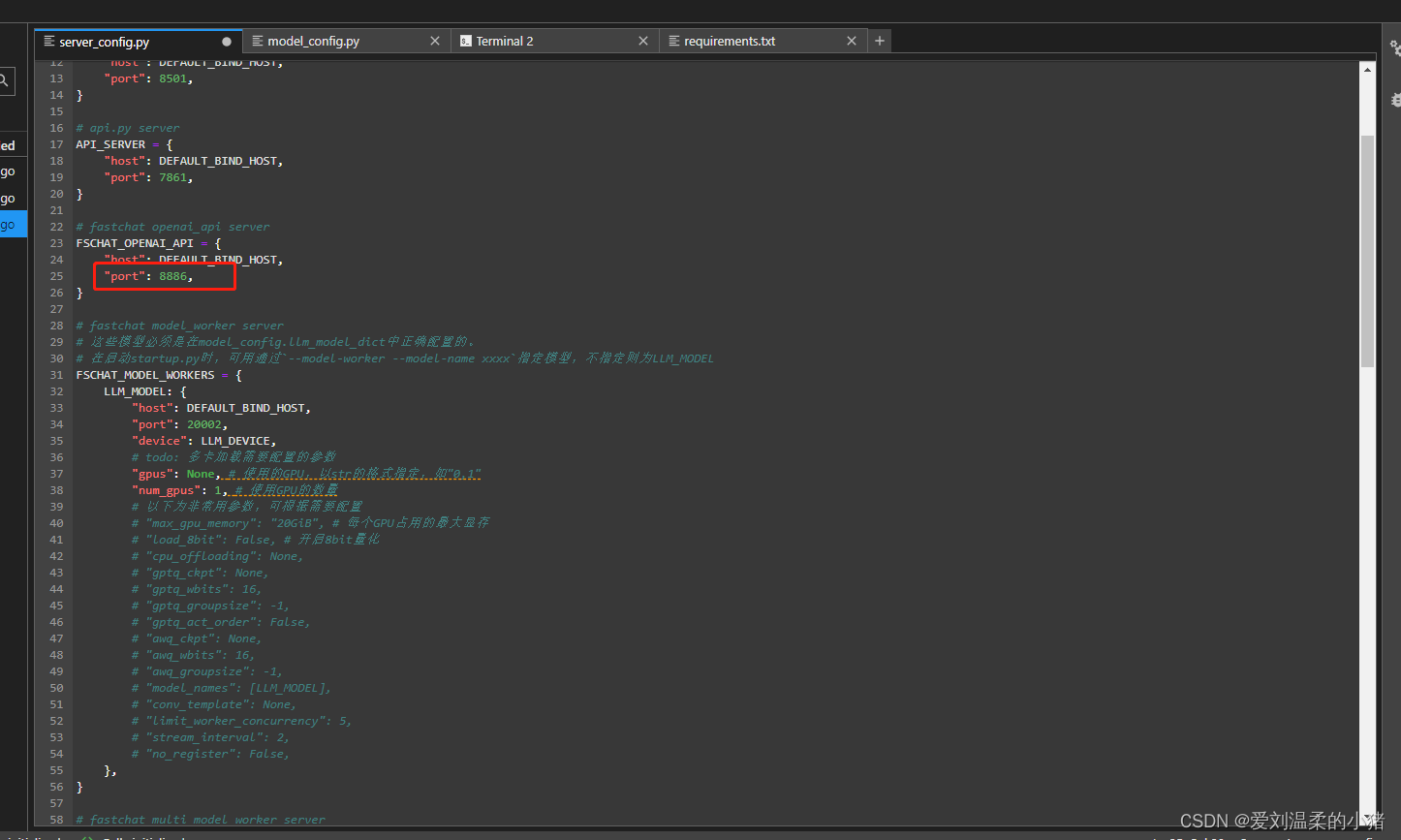
注意:model_config.llm_model_dict中模型配置的api_base_url需要与这里的修改的端口号一致。
5、向量数据库初始化
在LangChain目录下执行命令:python init_database.py --recreate-vs 等待向量数据库初始化完成即可。
接下来就可以启动项目了。
6、项目启动
一键启动脚本 startup.py,一键启动所有 Fastchat 服务、API 服务、WebUI 服务,用下方的命令:
python startup.py -a
并可使用 Ctrl + C 直接关闭所有运行服务。如果一次结束不了,可以多按几次。
可选参数包括 -a (或–all-webui), --all-api, --llm-api, -c (或–controller),
–openai-api, -m (或–model-worker), --api, --webui,其中:–all-webui 为一键启动 WebUI 所有依赖服务;
–all-api 为一键启动 API 所有依赖服务;
–llm-api 为一键启动 Fastchat 所有依赖的 LLM 服务;
–openai-api 为仅启动 FastChat 的 controller 和 openai-api-server 服务; 其他为单独服务启动选项。
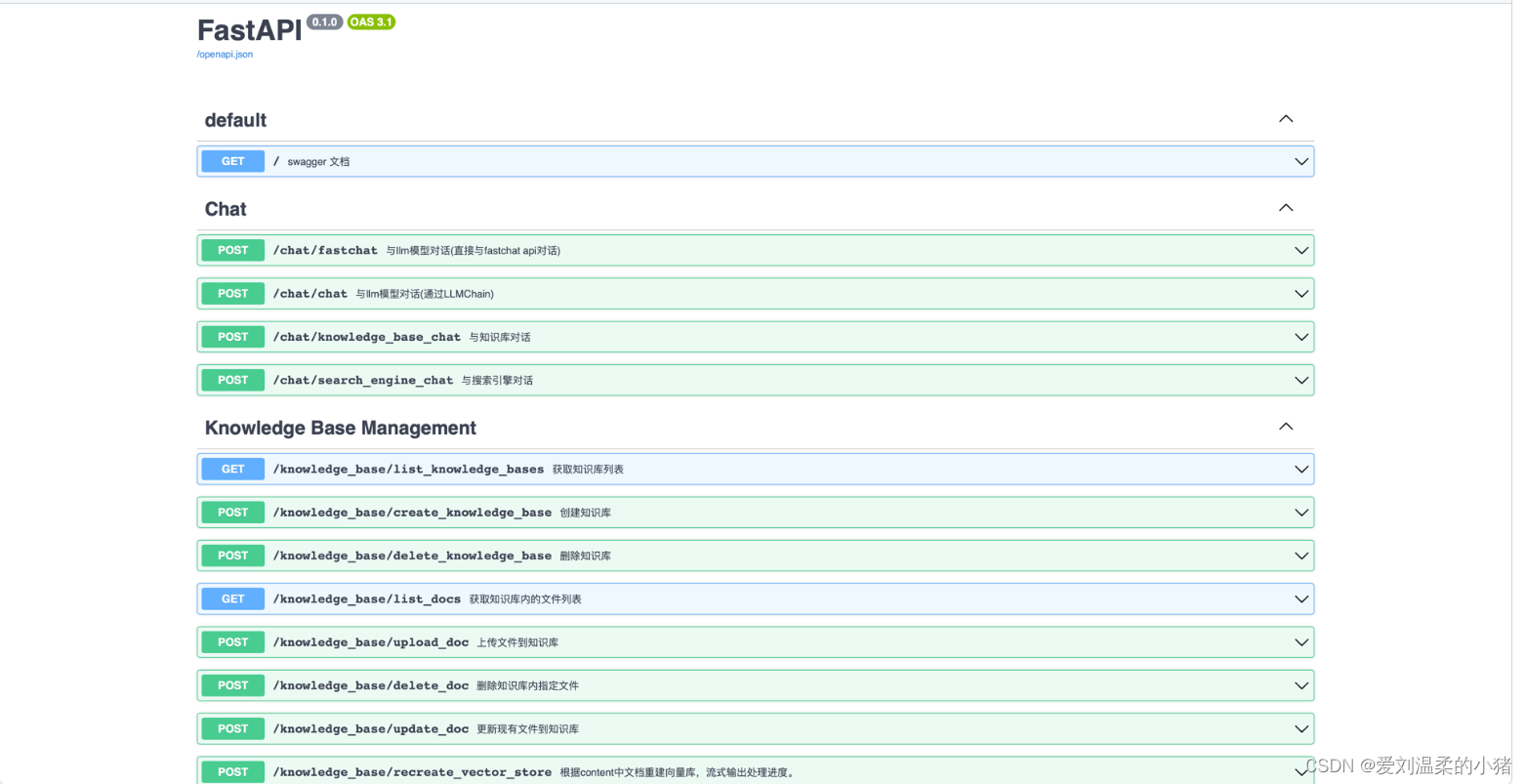
启动后可以查看swagger接口文档:
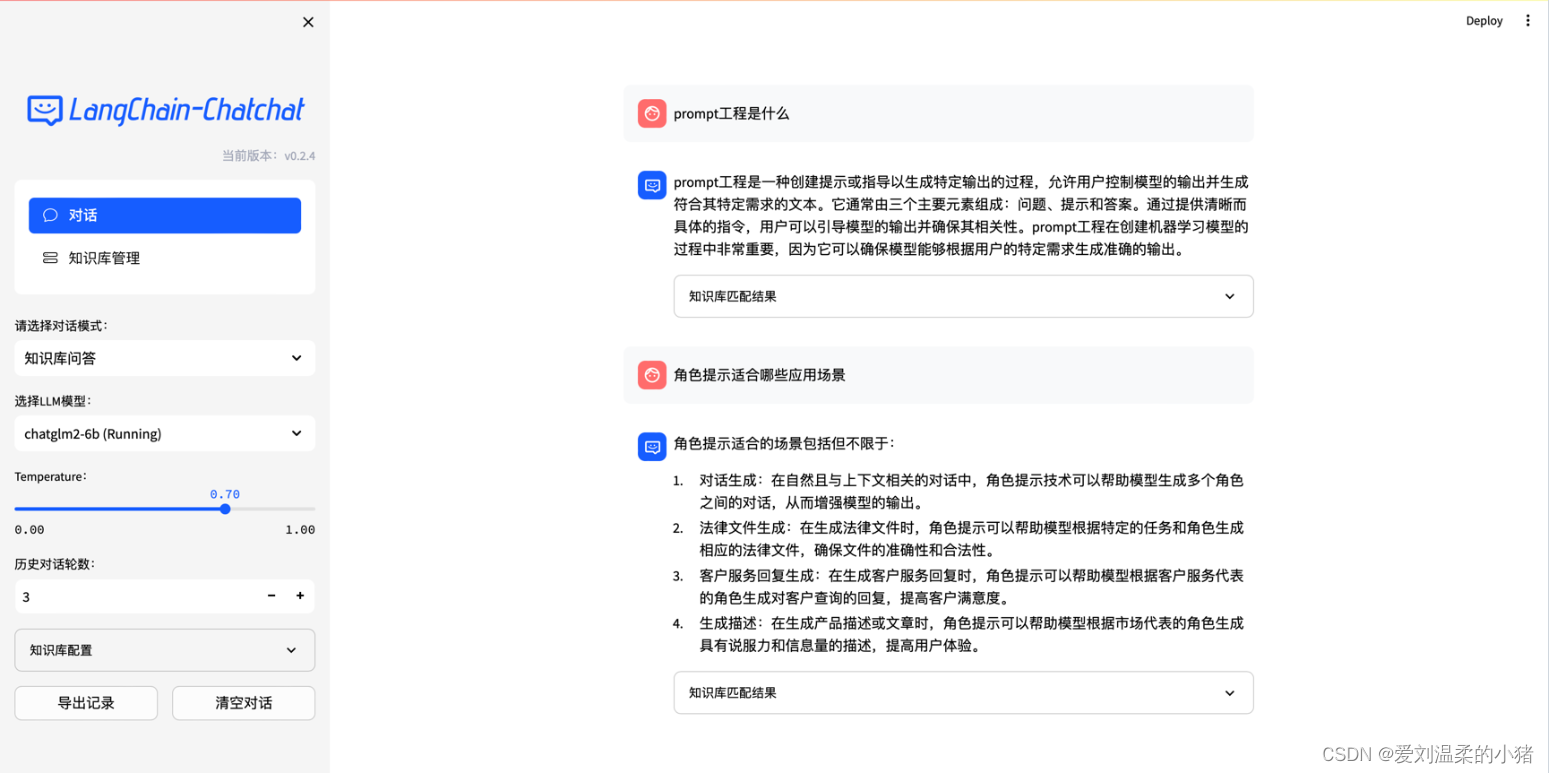
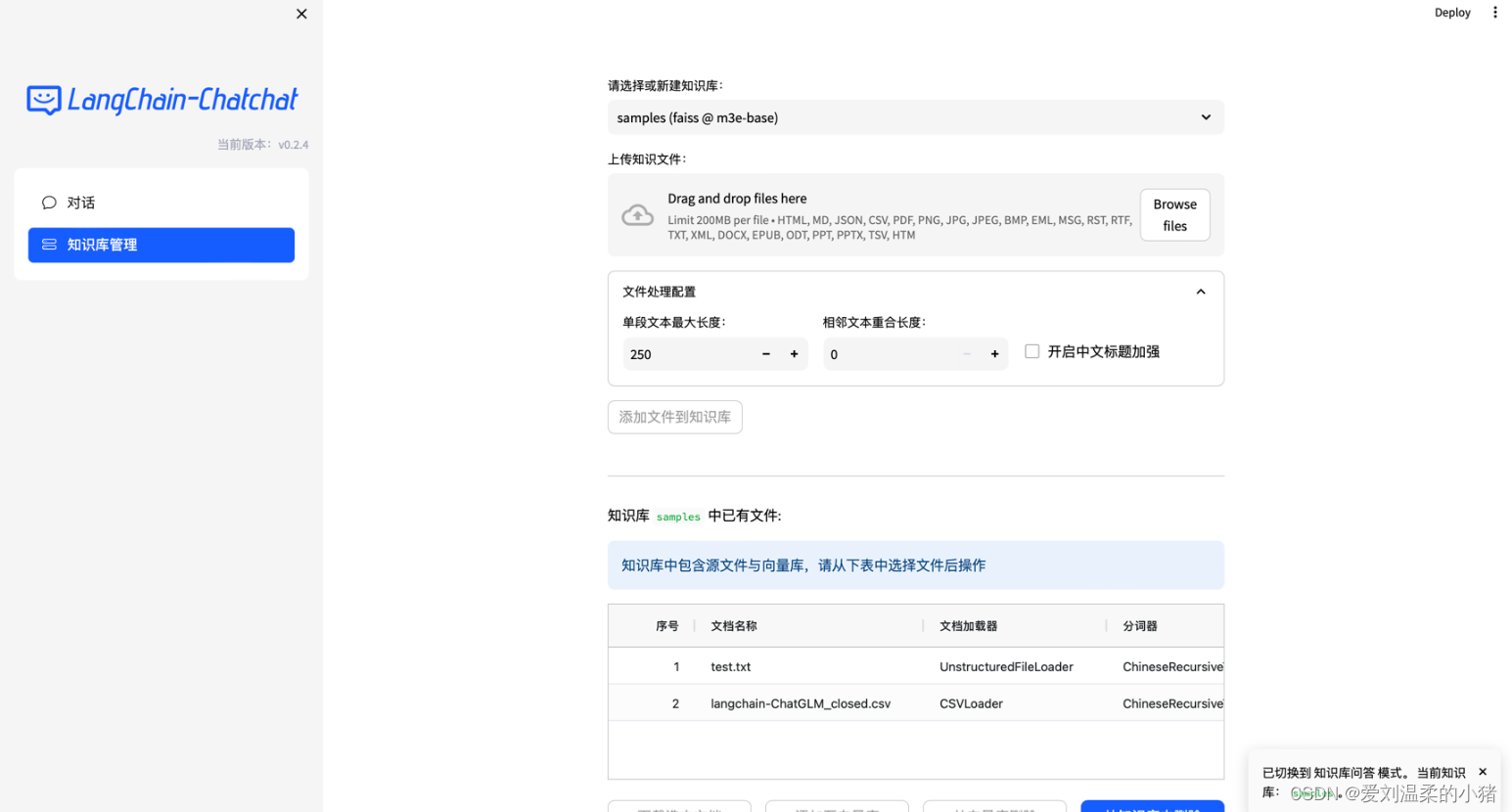
也可以直接使用自带的项目webui:

















 1382
1382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









