










懒人救星版:
1.任意多输入多输出都可以用(采用如下三套数据集:
4输入2输出.xlsx 4输入3输出.xlsx 5输入3输出.xlsx数据特点:(多元化的数据)
包含0-1数据、大于1的数据和极大的数据(10的8次方)
3.统计误差指标和决定系数R2都有
每个代码压缩文件包改动代码处不超过4处
如下图代码中:(改动点总计4处代码即可运行)

改动点和改动详细说明都已标注在代码中
前沿图:
三目标为例图(支持任意多目标,这里只展示二目标和三目标)
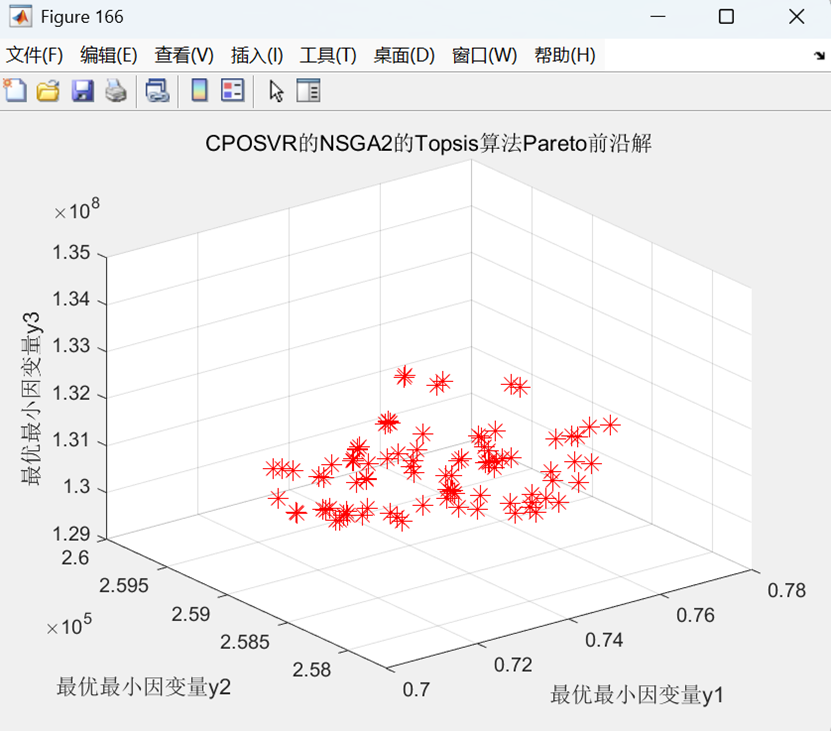
三目标为例图(支持任意多目标,这里只展示二目标和三目标)
代码整体运行效果如下图:
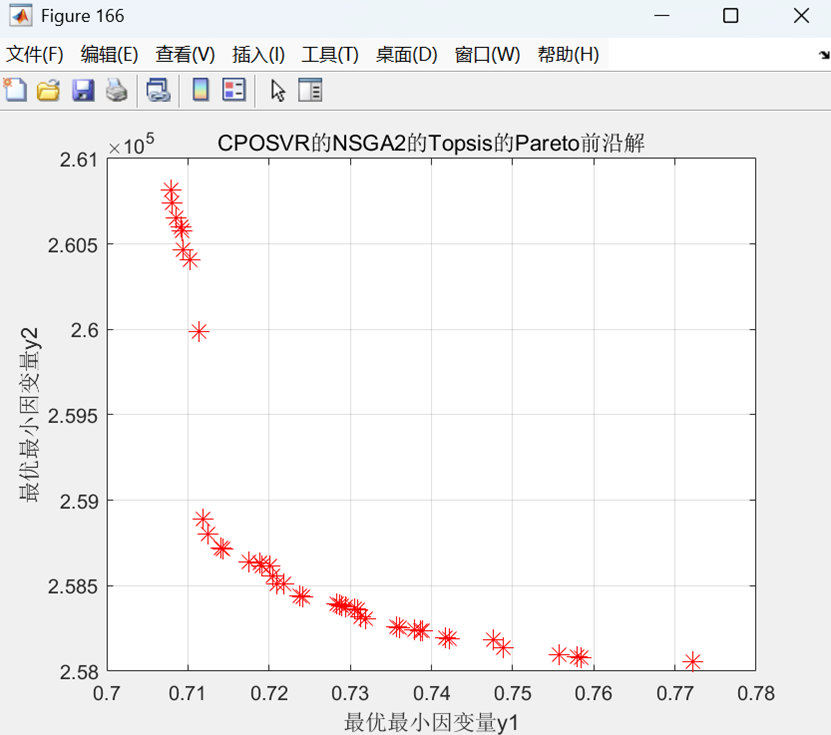
以二目标为例效果图:
以三目标为例效果图:
NSGA2-Topsis结合后求解的结果图:
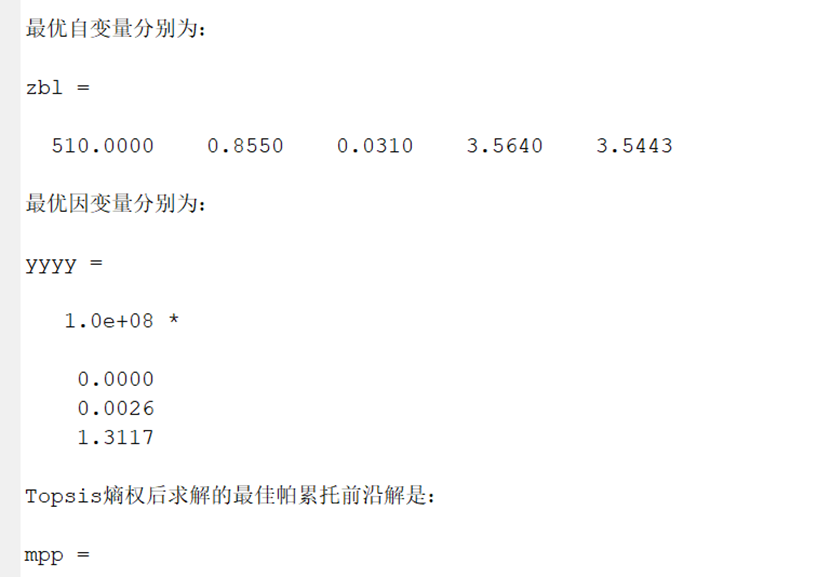
熵权法Topsis求解帕累托前沿解各解的接近度如下:

采用的数据集如下:
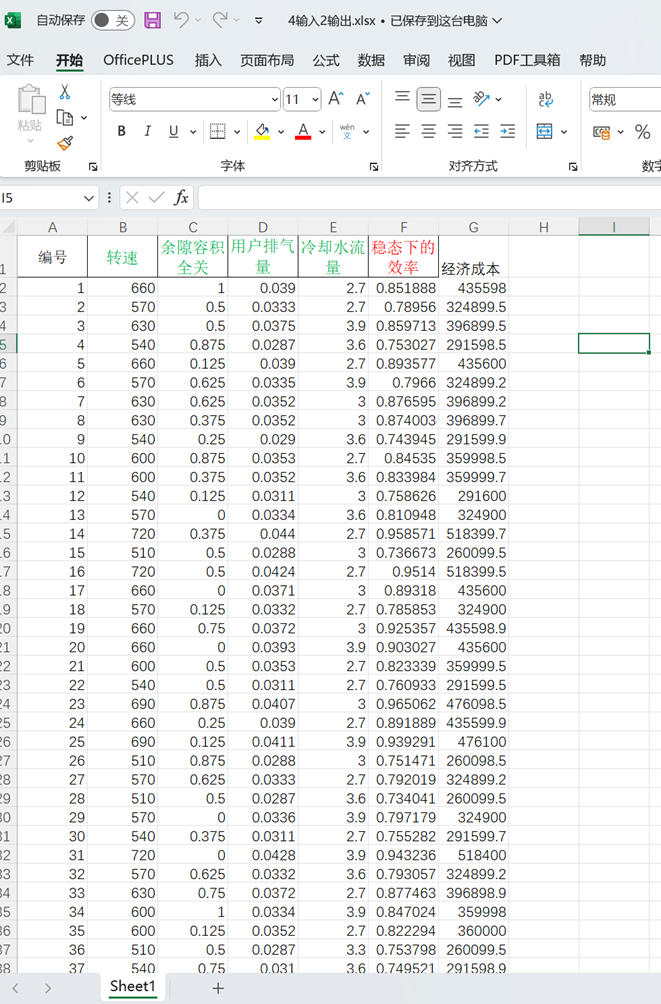
4输入2输出.xlsx如下:
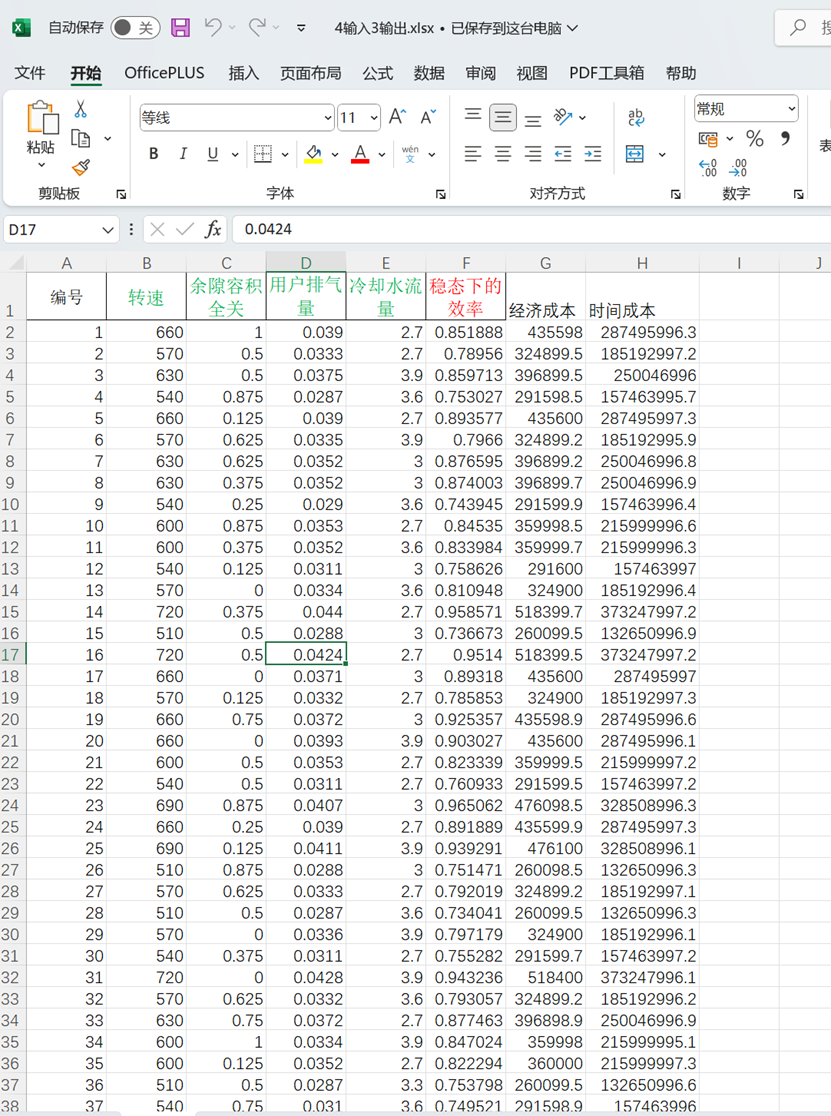
4输入3输出.xlsx如下:
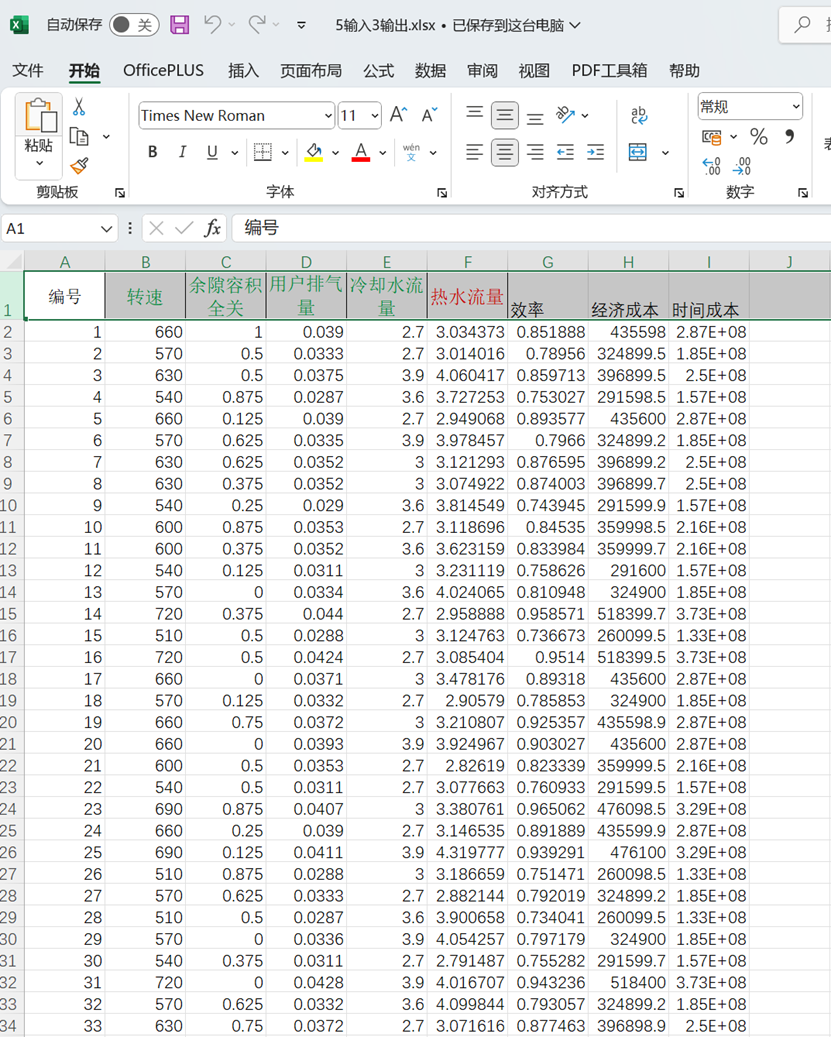
5输入3输出如下:

![]() 编辑
编辑
首先,Topsis,也就是逼近理想解排序法,是一种多准则决策分析方法。它的基本思想是通过计算各方案与理想解(正理想解)和负理想解之间的距离来进行排序。理想解是各指标的最优值,负理想解是各指标的最劣值。然后根据相对接近度来排序,相对接近度越高,方案越优。
然后是熵权法,这是一种客观赋权方法,用于确定各指标的权重。熵原本是热力学中的概念,后来在信息论中用于衡量信息的不确定性。熵权法通过计算各指标的熵值来判断该指标的离散程度,离散程度越大,熵值越小,信息量越大,权重也就越高。反之,离散程度越小,熵值越大,权重越低。
Topsis 熵权法是指在 Topsis 中使用熵权法来确定各指标的权重,而不是主观赋权。这样可以让权重的确定更客观,减少主观因素的影响。
Topsis 熵权法是一种结合了逼近理想解排序法(Topsis)和熵权法的多准则决策分析方法,主要用于解决多指标评价问题。其核心思想是通过熵权法客观确定指标权重,再利用 Topsis 对方案进行排序。
原理如下:
包括数据标准化、熵权计算、加权矩阵构建、理想解确定、距离计算和排序
1. 数据标准化

2. 熵权法计算指标权重
熵权法通过指标的信息量客观确定权重,步骤如下:


3. 构建加权标准化矩阵

4. 确定正理想解和负理想解


SVM原理介绍
SVM简介
支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
核心原理:
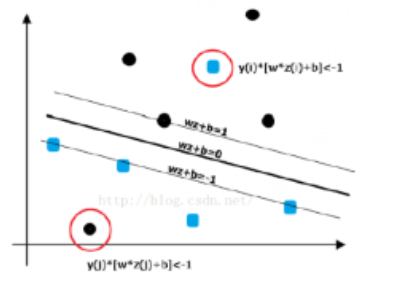
SVM学习的基本想法是求解能够正确划分训练数据集并且几何间隔最大的分离超平面。如下图所示, \boldsymbol{w}\cdot x+b=0 即为分离超平面,对于线性可分的数据集来说,这样的超平面有无穷多个(即感知机),但是几何间隔最大的分离超平面却是唯一的。
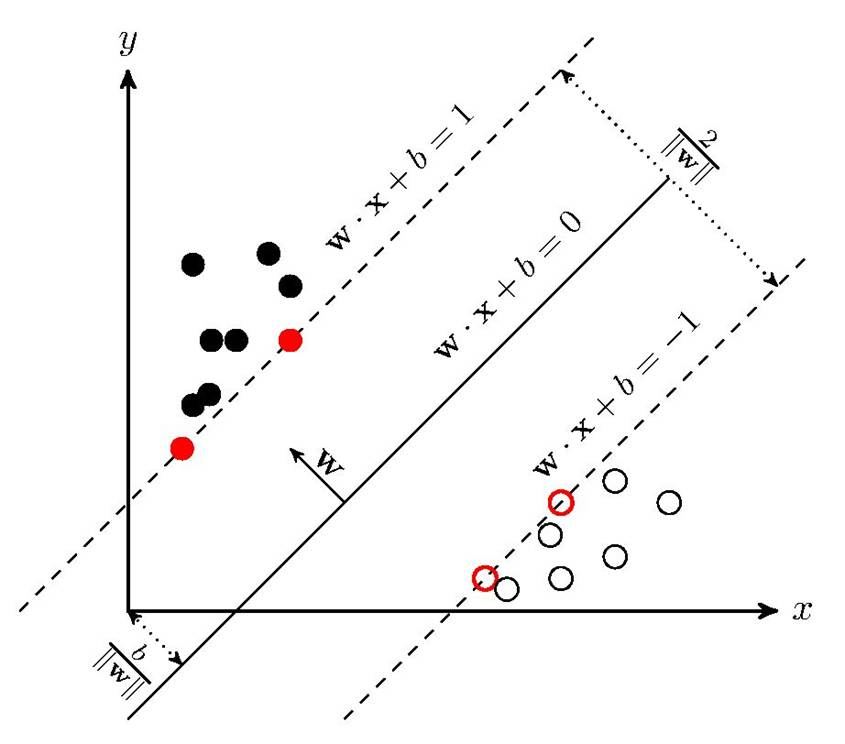
超平面的表达式为:
WTx+b=0
原理举例:WT取(w1,w2),x取(x1,x2)T, 则原式得 w1x1+w2x2+b=0 与传统直线 Ax+By+c=0 方程式
相同,由二维三维空间推到更高维平面的一般式即为上式。
W:为平面法向量,决定了超平面的方向
b: 决定了超平面距原点的距离
法向量与样本属性的个数、超空间维数相同。在超空间中我们要求的参数就是决定超平面的W和b值。
在超空间中任意一点x到超平面的距离为:
我们可以由特殊到一般的理解一下这个式子,如果在二维空间即平面上,点到直线的距离为:
式子中A,B,C是直线的参数也就是W,x0和y0是x的坐标,这样r式是不是就好理解了,这个距离是几何距离,也就是人眼直观看到的距离。几何距离只有大小没有方向,因为式子是被套上绝对值的,将绝对值摘掉,现在我们就人为规定,样本数据中到超平面的距离为正的点为+1类的样本点,就是这类点给它打个标签+1,到超平面的距离为负的点标签为-1,为什么不是+2,-2其实都可以,取1是为了后续方便计算;
现在假设这个超平面能够将样本正确分类,只不过这个超平面的w和b值我们不知道,这正是我们要求的,但是这个平面是一定存在的,有:
将几何距离r式中的分子绝对值和分母拿掉以后(因为都为正)剩下的wT+b是能够判断出样本为+1还是-1类别的部分,定义函数距离(很重要)为:
函数距离就是样本类别乘wT+b。因为正样本类别为+1,且wT+b也为正;负样本类别为-1且wT+b为负。所以函数距离只有大小没有方向。
函数距离就相当于几何距离的分子部分,在所有样本中每一个点都有一个函数距离和一个几何距离,几何距离是可观测到的直接的距离,函数距离具有如下性质:一个点到超平面的函数距离取决于这个超平面的法向量和b值,同一个超平面可以有多组w和b值,但每组值成比例。w和b值不同,点的函数距离也不同。
三维空间举例:
现有两个平面2x+3y+4z+2=0 与 4x+6y+8z+4=0
有点:x(1,1,1)
则点到平面的函数距离分别为:11,22。 但平面实质为一个平面,只有w和b值不同,也就是说我们可以通过放缩w和b值,来控制函数距离!!!
重点:支持向量机数学模型原理,其实就是通过控制函数距离来求得最大几何距离。也就是函数距离为约束条件,几何距离为目标函数。具体往下看:
通过放缩w和b,让两类中某一类点距超平面的函数距离分别为1(离超平面的距离相等,为1方便后续计算)。
W和b值未知,但总存在一组值满足上述。如图:
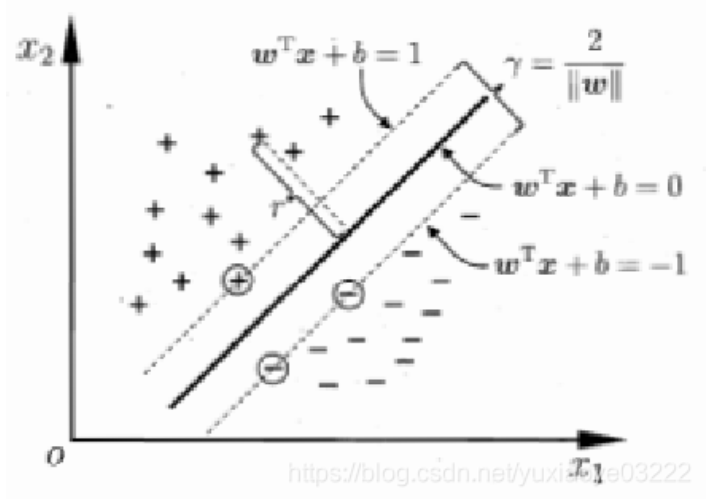
中间最粗的平面为我们要求的超平面,两边的虚线为支撑平面,支撑平面上的点就是支持向量,通过放缩超平面的w和b值,使支持向量到超平面的函数距离为1,支持向量是距超平面最近的点,所以其他向量点到超平面的函数距离一定大于等于1。其实这时候就可以建立最初的模型了,为:
解释一下这个模型,首先先不看目标函数,先看约束条件,约束添加表达的是所有样本点到超平面的距离要大于等于1,在支撑平面上的为1,其他的大于1,根据约束条件其实可以得到无数个平面,如下面两个:
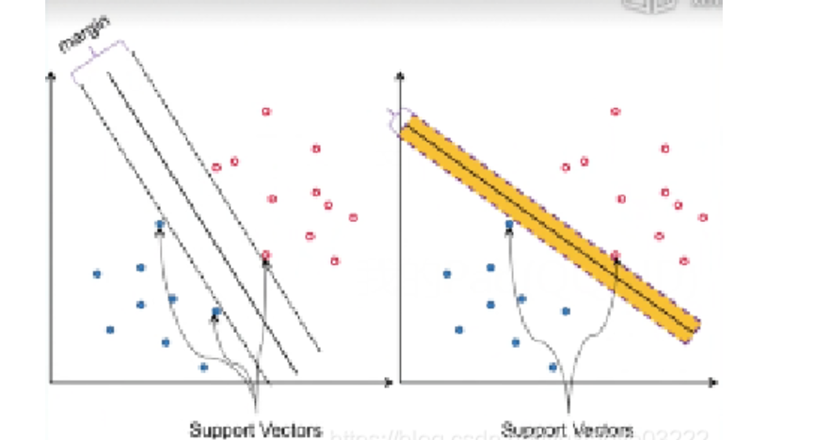
但是,在这些平面中我们需要的是泛华能力最好,鲁棒性最强的那一个,也就是最宽的那一个(margin最大),这时候就需要通过定义目标函数来求得,宽度最大也就是几何距离最大,几何距离的分子是函数距离,而两个支撑平面的函数距离我们定义完了是2,所以才有了上面的数学模型。
总的来说,就是通过函数距离作为约束条件得到无数个能把样本正确分开的平面,然后通过目标函数在这些平面中找最宽的!
把上面的数学模型转化为:
把求最大转变为求最小,即把模型转化为凸函数,其实到这里已经是优化问题了,凸函数是比较容易找到最优解的,因为局部极值就等于全局极值。至于为什么加个二分之一的系数,加个平方,都是为了后续解模型时求导方便。这个模型即为支持向量机的基本型,后面涉及到的软间隔,支持向量回归都从这个形式出发。
所建立的模型为凸二次规划(局部极值的全局极值、目标函数为二次约束条件为一次)。能直接用现成的优化计算包求解,但是可以有更高效的办法。利用拉格朗日乘子法,将两个参数的优化问题转化为一个参数的优化问题,进而求解模型。
对所建立的模型使用拉格朗日乘子法,将约束条件转化为目标函数,即对每条约束添加拉格朗日乘子 ɑi>0。得到如下拉格朗日函数。
其中令对w和b的偏导为零可得
对于等式约束可以直接使用拉格朗日乘子法求极值,对于不等式约束要满足KKT条件约束进行求解,模型对应的KKT条件为:
将w公式代入原函数有:
上面最后的那个式子可以看到已经不含w和b值了,就只有拉格朗日乘子。利用SMO算法将每个样本数据的乘子解出来,观察约束条件
总有
和
前者意味着向量点根本不会在求和中出现,后者意味着向量在支撑平面上,是一个支撑向量,训练完成后大部分样本都不需要保留。也就是训练完后大部分拉格朗日乘子都为零,只有在支撑平面上的样本的拉格朗日乘子不为0。
至此,已经对支持向量机有一个基本认识,以上数学推理为支持向量机的硬间隔。记住这个模型:
支持向量机的软间隔、核函数方法、支持向量回归都是在这个模型的基础上的。上面讲的是样本完全线性可分,但是实际中,不可分的情况多谢,如果是线性不可分的如:
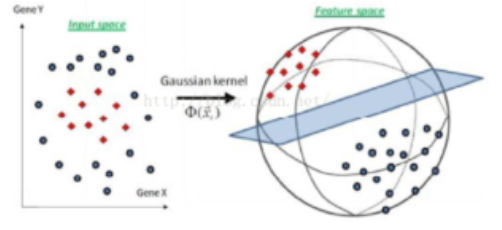
需要把数据映射到更高维空间,这时候用到核函数。
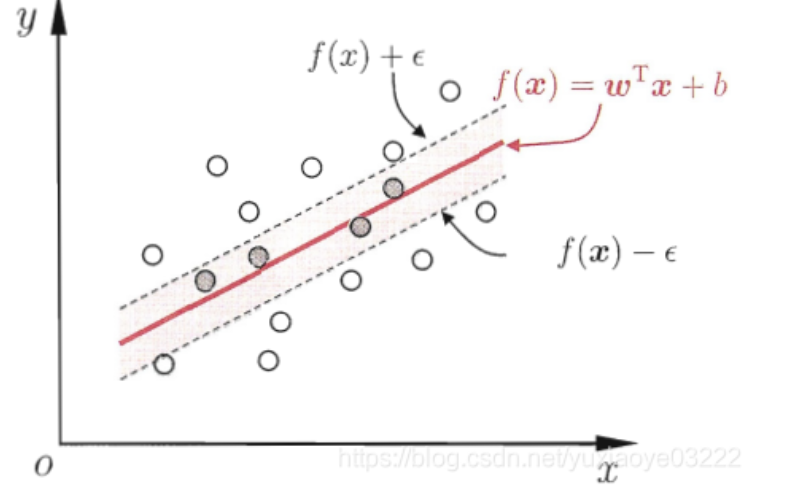
如果数据有噪声如:
那么用到的是支持向量机的软间隔。
如果你不是分类数据而是要有监督的预测数据,那么就是支持向量回归。
CPO(冠豪猪算法)
原理:
CPO模拟了冠豪猪的各种防御行为。冠豪猪的四种防御策略是视觉、声音、气味和身体攻击。这些策略从最不激进到最激进排序。在CPO中,我们可以可视化搜索空间,四个不同的区域模拟了防御CP区域。第一个区域(A),CP远离捕食者,代表第一个防御区域,用于实施第一个防御策略。第二区域(B)代表第二防御区域,用于在捕食者不害怕第一防御机制并向捕食者移动的情况下实施第二防御策略。第三区域(C)代表第三防御区,用于实施第三防御策略,当捕食者不害怕第二和第三防御机制,仍向CP移动时,该策略被激活。最后一个区域(D)代表最后一个防御区域,用于实施最后一个防守策略。在最后一个区域,在之前的所有防御机制失效后,CP会攻击捕食者,使其失去能力,甚至杀死它们以保护自己。
一、种群初始化
与其他基于元启发式群体的算法类似,CPO从初始个体集(候选解决方案)开始搜索过程:
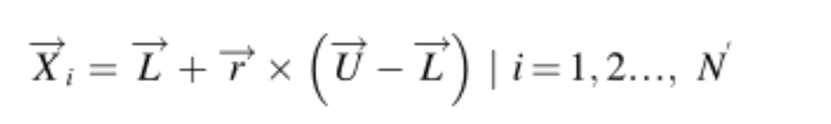
其中N表示个体数量(种群大小N),Xi是搜索空间中的第i个候选解,L和U分别是搜索范围的下限和上限,r是在0和1之间随机数
二、循环种群减少技术
循环种群减少技术(CPR),除了加快收敛速度外,还可以保持种群多样性。这种策略模拟了这样一种想法,即并非所有CP都激活防御机制,而是只有那些受到威胁的CP才激活防御机制。因此,在该策略中,在优化过程中从种群中获得一些CP,以加快收敛速度,并将它们重新引入种群中,从而提高多样性,避免陷入局部极小值;该循环基于循环变量T,以确定优化过程中执行该过程的次数。
N=Nmin+N-Nmin×(1-(t%TmaxTTmaxT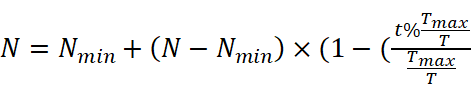 ))
))
其中,T是确定循环数的变量,t是当前函数评估,Tmax是函数评估的最大数量,%表示余数或模运算符,Nmin是新生成的种群中个体的最小数量,因此种群大小不能小于Nmin。随着当前函数评估次数的增加,人口规模逐渐减少,甚至达到40人。这表示第一个循环。之后,种群规模再次最大化,然后逐渐减小,甚至达到优化过程的终点。这表示第二个也是最后一个周期,因为T被设置为2。由此可以看出,种群规模先是最大化,然后逐渐缩小,甚至达到Nmin。
三、勘探阶段
(1)第一防御策略
当CP意识到捕食者时,它开始举起并扇动羽毛笔,给人一种更深的印象。因此,捕食者有两种选择,要么向它移动,要么远离它。在第一种选择中,由于捕食者向CP移动,捕食者与CP之间的距离减小。这种选择鼓励探索捕食者与CP间的区域,以加快收敛速度。相反,在第二种选择中,捕食者和CP之间的距离最大化,因为捕食者选择离开。此选项鼓励探索遥远的地区,以确定未访问的地区,这可能涉及所需的解决方案。使用正态分布来生成随机值,以数学方式模拟这些选项。如果这些随机值小于1或大于−1,则鼓励向CP靠近。否则,捕食者将远离CP。通常,这种行为在数学上模拟如下:
Xit+1=Xit+τ1×2×τ2×Xcpt-yit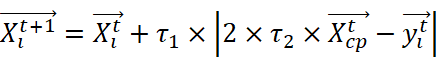
其中xtCP是评估函数t的最佳解,yti是在当前CP和从种群中随机选择的CP之间生成的向量,用于表示捕食者在迭代t时的位置,τ1是基于正态分布的随机数,τ2是区间[0,1]中的随机值。生成yti的数学公式如下所示:
yit=xit+xrt2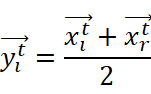
其中r是[1,N]之间的随机数。
(2)第二防御策略
在这种策略中,CP使用声音方法制造噪音并威胁捕食者。当捕食者靠近豪猪时,豪猪的声音会变得更大。为了从数学上模拟这种行为,提出了以下公式:
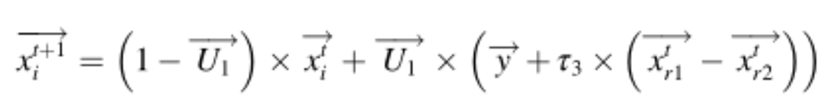
其中r1和r2是[1,N]之间的两个随机整数,τ3是0和1之间生成的随机值。
四、开发阶段
(1)第三防御策略
在这种策略中,CP会分泌恶臭,并在其周围区域传播,以防止捕食者靠近它。为了从数学上模拟这种行为,提出了以下公式:
xit+1=1-U1×xit×xr1t+Sit×xr2t-xr3t-τ3×δ×γt×Sit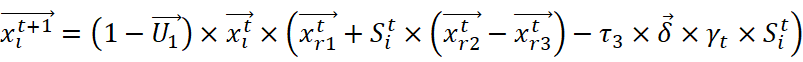
其中r3是[1,N]之间的随机数,δ是用于控制搜索方向的参数,并使用等式(8)定义。xti是迭代t时第i个个体的位置,γt是使用等式(9)定义的防御因子。τ3是区间[0,1]内的随机值,Sti是使用(10)等式定义的气味扩散因子。如下所示:
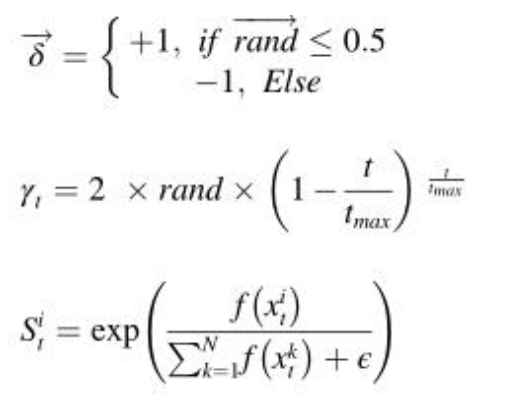
其中,f(xit)表示迭代t时第i个个体的目标函数值,ε是避免被零除的小值,rand是包括在0和1之间随机生成的数值的矢量,rand是包括在1和0之间随机生成数字的变量,N是总体大小,t是当前迭代的次数,tmax是最大迭代次数。U1矢量用于模拟该策略中可能出现的三种情况:
(1)当U1 等于0,CP将停止气味扩散,因为捕食者会因为害怕CP而停止移动,因此捕食者与CP之间的距离保持不变;
(2)当U1等于1时,由于捕食者在附近,CP会显著散发气味;
(3) 当U1是0和1的组合,捕食者与CP保持安全距离,因此,没有必要广泛释放其气味。
(2)第四防御策略
最后一种策略是物理攻击。当捕食者离它很近并用短而厚的羽毛攻击它时,CP会采取物理攻击。在物理攻击过程中,两个物体强烈融合,代表一维的非弹性碰撞。为了用数学公式表达其物理攻击行为,提出了以下公式:
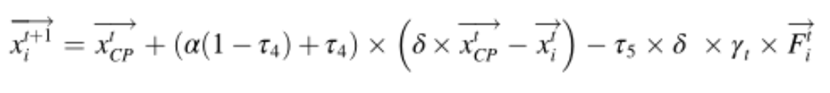
其中xtCP是获得的最佳解,表示xtiCP在迭代t时第i个个体的位置,表示该位置的捕食者,α是稍后在参数设置部分讨论的收敛速度因子,τ4是区间[0,1]内的随机值,Fti是影响第i个捕食者的CP的平均力。它由非弹性碰撞定律提供并由公式定义:
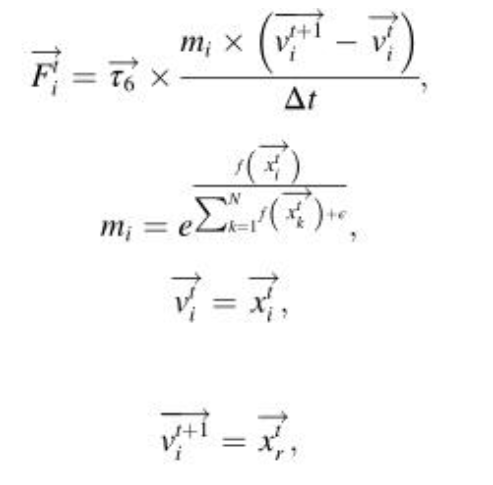
其中mi是迭代t时第i个个体(捕食者)的质量,f(‧)表示目标函数,vi(t+1)是第i个个体在下一次迭代t+1时的最终速度,并基于从当前总体中选择随机解进行分配,vti是迭代t时第i个个体的初始速度,Δt是当前迭代的次数,τ6是包括在0和1之间生成的随机值的向量。在等式中,基于分子除以当前迭代来计算CP的平均力,当前迭代在优化过程中线性增加。因此,CP的平均力的影响逐渐最小化。事实上,这个因素的小值对CPO的性能并不不利,因为它们可能无助于利用迄今为止最好的解决方案周围的各个区域来找到更好的解决方案。因此,通过删除分子并仅依赖于分母,如公式所示。这种方法将有助于在搜索空间内创建广泛的值,从而对迄今为止最好的解决方案周围的区域进行更全面的检查。
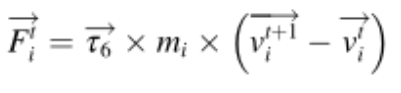

















 1006
1006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









