






前言
大模型在多轮对话场景有着广泛的应用,然而现在对其进行深入研究的很少,今天就给大家介绍一篇最新paper,其主要聚集大模型对多轮对话指令跟随的能力,其从数据集、训练方法以及如何评估三个层面都进行针对性的多轮优化。
论文链接:https://arxiv.org/pdf/2310.07301

方法
如图(a)作者首先训练了一个Parrot-Ask Model用来模拟用户提问,然后基于该model进行自动互动就可以得到更多轮数的高质量对话,接着图(b)基于启发式设计了三种常见策略得到正-负样本pair,有了数据后就可以开始训练了,首先图©基于高质量对话进行sft,图(d)用正-负样本pair进行偏好学习。
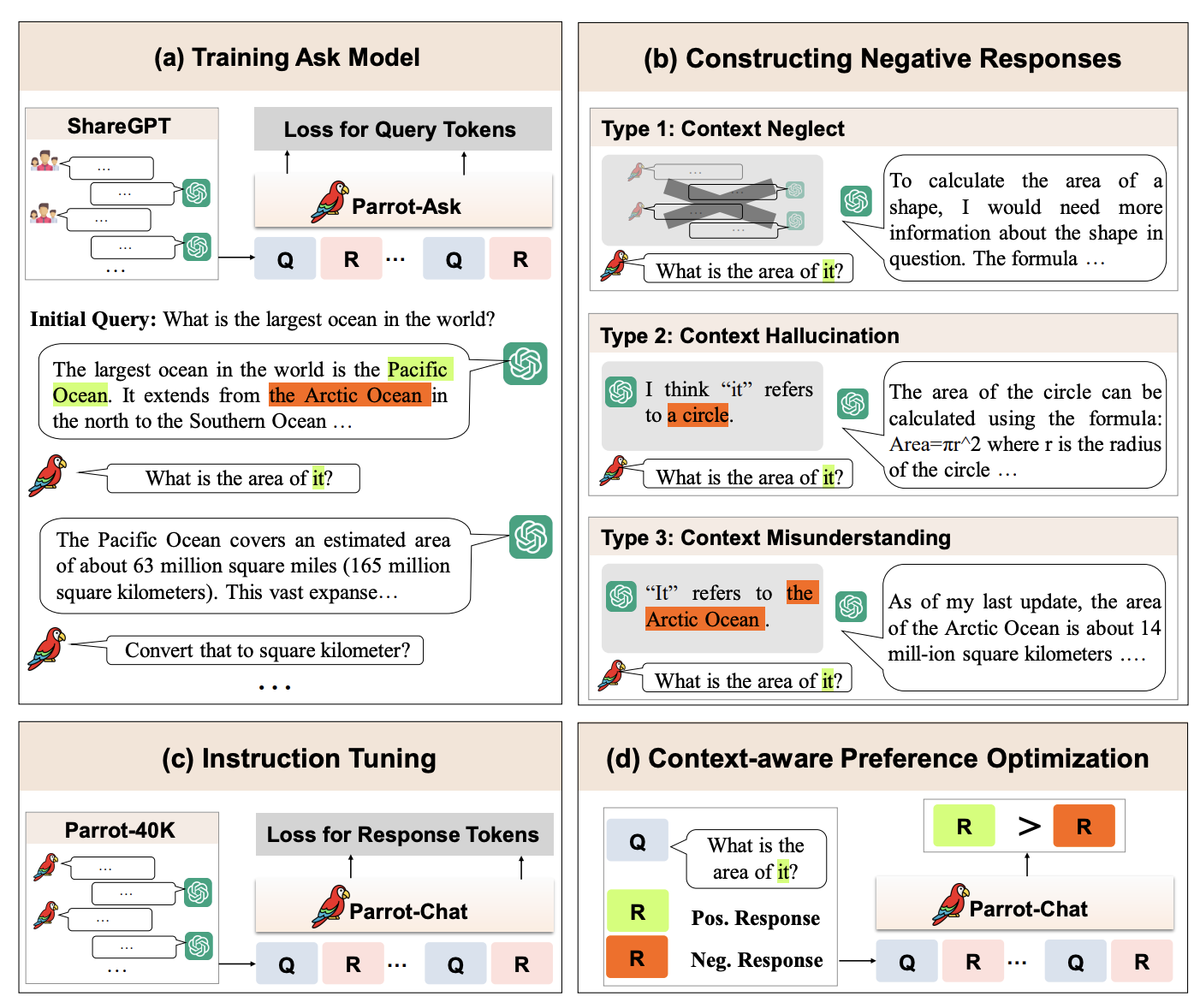
下面我们详细看一下各个环节具体是怎么做的。
- Dataset Collection
多轮对话其实可以拆成两个角色在聊天,一个是user一个是bot。这两个角色说话风格和内容是有着很大差异的,bot目前有很多比如chatgpt,gpt4等等。但是user是非常稀缺的,因为其要求掌握真实用户的提问习惯,为此作者专门训练了一个模拟用户提问的model。
具体来说作者使用user-ChatGPT真实数据来训练一个user提问模型(论文中叫做ask model),和通常训练bot恰恰相反,其是根据历史对话来计算下一轮提问的loss。训练的时候也会添加一些system信息

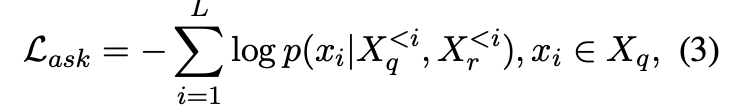
然后其从ShareGPT和UltraChat中抽取了20K的第一轮数据作为seed,使用训练好的ask model和chatgpt以seed为开端自动聊多轮,直到达到规定的轮数。当然后面会再进行一次过滤比如过滤掉重复提问,短提问等等。
当然也可以直接用chatgpt进行模拟user比如

下面是一些具体例子对比

可以看到自己训练的ask模型更像人提问。
- Context-Aware Preference Optimization
相比于单轮对话,多轮对话更为复杂,有时候其需要结合历史对话来回答。于是作者需要先找出这部分query。具体做法是使用代词识别(因为通常代词指代的具体信息就在历史对话)以及借助gpt4去判断出那些需要历史对话才能回答的query。
有了真多轮query以后,作者采用了三种策略来模拟获得bad response(方便后面形成pair偏好训练数据)。
(a) Context Neglect:忽略历史对话,让chatgpt只根据当前query进行回答,这里是在模拟真实场景模型可能会忽略历史对话进行回答。
(b) Context Hallucination:在不给真实历史对话的条件下,让chatgpt去猜测可能的上文,然后基于猜测进行回答,这主要是在模拟产生幻觉的回答。
©Context Misunderstanding:让chatgpt故意选择不相关的历史对话进行结合回答,这主要用来模拟真实场景中大模型错误理解历史对话的场景。
有了上面的负样本,再加上数据本来的正确response,就可以用dpo强化学习算法来进行训练了。
实验
多轮对话的场景的benchmark很少,最出名的就是MT-Bench,但是其只有两轮历史对话,为此作者让标注人员手动额外扩展了六轮,而且为了增加难度,特意做了一些指代和信息缺失等设计即必须依靠历史对话才能回答,随后用gpt4进行打分。
下面是给标注人员看的规则

一些实际的case:

打分的prompt:

核心评估结果如下:
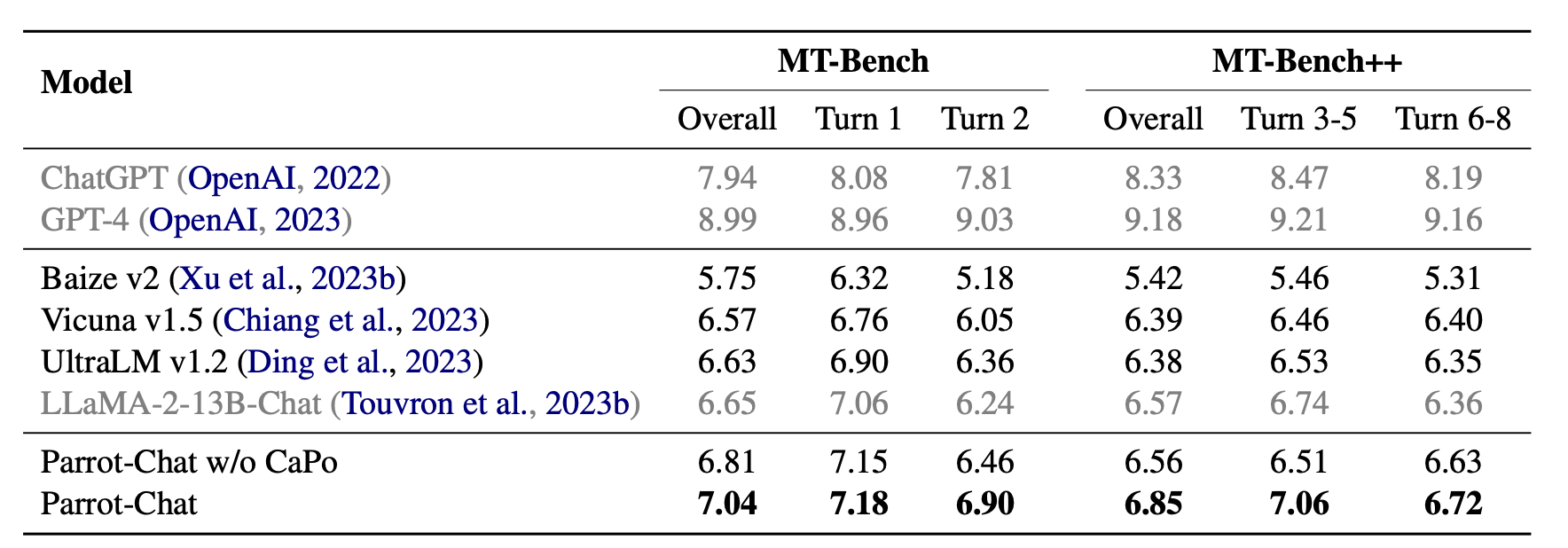
可以看到SFT和DPO过后都是有些提高的。但是和chatgpt以及gpt4还是有明显的差距。
总结
(1) 多轮对话场景下收集query是非常重要的,说白了就是收集真实场景的需求到底是啥,知道了query就等于知道了用户真真关心的是啥,那么就可以针对性的进行优化response,所以这也是大平台的优势之一,openai能够通过api从全球收集大量各种各样的真实需求,这一壁垒是非常高的。返回头来说对于我们做某一垂类场景的时候,这篇文章给我们的启示是:可以先想办法收集一部分真实的query,然后训练一个query模仿器(ask model)得到更多的真实候选query,然后迭代优化甚至快速上线,拿到更多真实的query(这非常珍贵),训练更好的query模仿器,再迭代优化,直到最后得到大量真实的query,至此你就有了自己的第一个壁垒了:真实query。
(2)因为收集query是非常重要的一环,笔者这里想再提一点,如前面所说我们可以训练一个ask model,但是我们可不可以不训练呢?即直接通过Prompt Engineering让一个现有的大模型比如gpt4去模拟user进行提问,当然可以(论文就给出了一个用chatgpt的例子)!!!但是这里面最少需要考虑两个点,第一是成本问题,自己训练虽然需要成本但是推理的时候就可以大大降低成本了,调用gpt4的话成本有可能会高一些。第二就是效果问题,调用现成api的话需要做的就是Prompt Engineering,是否能够写出一个好的prompt来使得大模型query模拟?而直接训练因为学过了真实数据可能会更好一点。
(3) 就论文最后的效果来看,提升的不是很大,但总的来说多轮对话场景其实是一个很常见的常见,值得深入研究,包括数据集的获取、训练和评估,论文算是开了个好头。
关注
欢迎关注,下期再见啦~

















 1394
1394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









