







大模型相关目录
大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容
从0起步,扬帆起航。
- 基于Dify的QA数据集构建(附代码)
- Qwen-2-7B和GLM-4-9B:大模型届的比亚迪秦L
- 文擎毕昇和Dify:大模型开发平台模式对比
- Qwen-VL图文多模态大模型微调指南
- 从零开始的Ollama指南:部署私域大模型
- 基于Dify的智能分类方案:大模型结合KNN算法(附代码)
- OpenCompass:大模型测评工具
- 一文读懂多模态大模型基础架构
- 大模型管理平台:one-api使用指南
- 大模型RAG、ROG、RCG概念科普
- RAGOnMedicalKG:大模型结合知识图谱的RAG实现
- DSPy:变革式大模型应用开发
- 最简明的Few-shot Prompt指南
few-shot learning 是一种Prompt方法,借鉴了迁移学习的范畴,旨在通过利用少量样本使大模型快速适应新任务和输出要求。这种方法通常应用于自然语言处理(NLP)领域,特别是在训练数据稀缺的情况下。在 few-shot下,模型通过仅使用少量的样本(即 few-shot)来适应新任务。
Prompt few-shot learning 强调了“提示”(prompt)的作用。提示是一种设计良好的输入,旨在引导预训练模型生成期望的输出。这种方法的关键在于,通过精心设计的提示,可以有效地将预训练模型的能力迁移到新的任务上,即使是在极少的样本情况下。提示工程的艺术在于,如何通过最小的修改,使得预训练模型能够在新任务上表现良好。
通俗的讲,few-shot learning 就像是给一个已经学会了很多知识的智能助手提供一些线索,让它能够快速地学会如何处理一个新问题。这个智能助手首先在一个大数据库中学习了很多通用的知识,这些知识可以帮助它理解世界。当它遇到一个新的问题时,我们不需要提供大量的例子,只需要给出几个关键线索(也就是提示),这个助手就能利用它之前学到的知识,快速地理解并解决新问题。想象一下,这个智能助手就像是一个聪明的学生,已经学会了大量的数学公式和概念。现在,如果你给它一个新的数学问题,它可能不立即知道如何解决。但是,如果你给出一些提示,比如“这个问题和之前的几何问题有点像”,这个学生就能快速地应用它之前学到的几何知识来解决这个新问题,即使它之前没有见过完全一样的问题。
"""
示例 1:
简介:{{introduce_1}}
内容:{{content_1}}
示例 2:
简介:{{introduce_2}}
内容:{{content_2}}
"""
以下是创建的最新内容输出:
"""
简介:{{introduce}}
内容:{{content}}
1.few-shot使用场景
- 专业领域:在法律、医学或技术领域等专业领域工作时,收集大量数据可能很困难,只需少量提示即可获得高质量的特定领域输出,而无需大量数据集。
- 动态内容创建:非常适合内容生成等任务,在这些任务中,一致的风格和语气至关重要。
- 严格的输出结构要求:很少有镜头提示在向模型展示您希望输出的结构方面特别有用。
- 定制用户体验:在个性化应用程序中,例如聊天机器人或推荐系统,人工智能需要根据个人用户的偏好和输入快速调整。
2.few-shot数量
多篇研究论文指出,在两个例子之后,先是大模型回答性能大幅上升,然后是停滞不前。在 2 个示例之后,用户只是在燃烧Token。
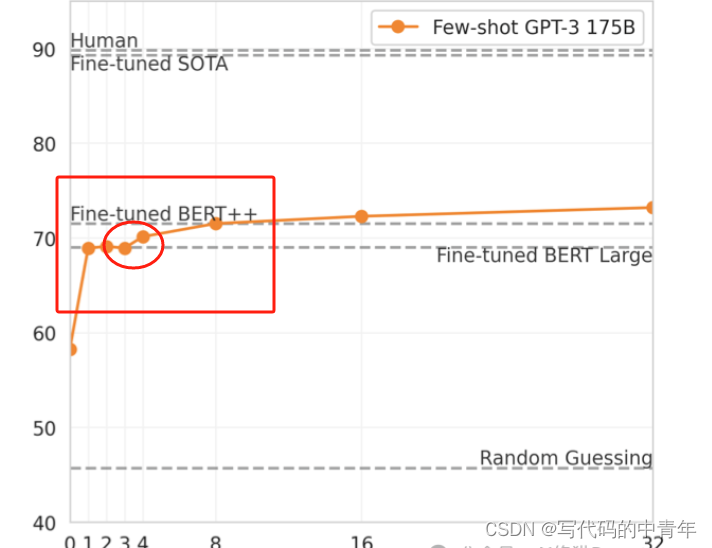
3.few-shot顺序
Calibrate Before Use:Improving Few-Shot Performance of Language Models的论文证明:模型的预测根据示例顺序而有很大差异。
将最关键的例子放在顺序的最后。众所周知,LLM 非常重视他们处理的最后一条信息。
4.few-shot示例方法
- 在对话流中增加理解(高度关联需求进行业务解读)
- 对模型基于正面提示(强调要做什么而非不要做什么)
- 简化提示输出统一(示例间在某种程度上达成高度一致)



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











