







模型简称LM-BFF,better few-shot fine-tuning of language models。
符号:
预训练模型为 L \mathcal{L} L,总数据集为 D \mathcal{D} D,标签空间为 Y \mathcal{Y} Y;对于 D \mathcal{D} D中的每个类,我们采样K个样本,组成训练集 D t r a i n \mathcal{D_{train}} Dtrain;词表为 V \mathcal{V} V;Prompt的样板记为 T \mathcal{T} T;验证集 D d e v \mathcal{D_{dev}} Ddev。 ∣ D d e v ∣ > = ∣ D t r a i n ∣ |\mathcal{D_{dev}}| >= |\mathcal{D_{train}}| ∣Ddev∣>=∣Dtrain∣,验证集越大,测试的越准确,该实验设置为 ∣ D d e v ∣ = ∣ D t r a i n ∣ |\mathcal{D_{dev}}| = |\mathcal{D_{train}}| ∣Ddev∣=∣Dtrain∣。
输入端
自动生成Prompt
对于给定与
Y
\mathcal{Y}
Y对应的词表中的label,利用自回归模型T5自动生成Prompt。对于Decode阶段,我们采用beam search,选取n个
T
\mathcal{T}
T。我们可以在
D
t
r
a
i
n
\mathcal{D_{train}}
Dtrain中 fine-tune 这n个
T
\mathcal{T}
T,再在
D
d
e
v
\mathcal{D_{dev}}
Ddev中测试,选取最好的那一个;也可以一直使用这n个
T
\mathcal{T}
T来训练和测试。实验证明n越大,测试效果越好,见图。


Prompt的拼接方式

该论文采用c中的方式:我们随机采样一个样本(作者说选取多个没有见到效果提升),例如:No reason to wath. It was [MASK];再从每个类中采样一个样本,嵌入标签,一起组成输入。例如:对于postive类,我们选取了A fun ride. It was great.,对于negative类,我们选取了The drama discloses nothing. It was terrible.。实验结果表明从每个类中选取的样本越短越好,这可能是因为作者使用的Roberta与Bert等模型的不够大,理解不了组合成的输入;也可能输入变得太长了,采用长序列模型可能会改善。
输出端
Answer的映射记为 M : Y → V \mathcal{M:Y\rightarrow V} M:Y→V, 也 M ( y ) , y ∈ Y \mathcal{M(y)}, y \in \mathcal{Y} M(y),y∈Y。y表示了一个标签,对于样本来说我们记为c。
自动生成label
对于
D
t
r
a
i
n
D_{train}
Dtrain某个类别中的样本c,记为
D
t
r
a
i
n
c
D_{train}^c
Dtrainc。对于每个
D
t
r
a
i
n
c
D_{train}^c
Dtrainc,我们用不做fine-tune的
L
\mathcal{L}
L来预测 k 个word。
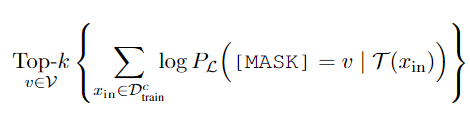
这样,每个类别在词表中都有k个word来对应。
训练
函数表达式为:
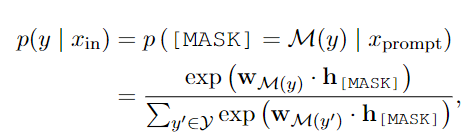
其中,
p
(
y
∣
x
i
n
)
p(y|x_{in})
p(y∣xin)表示类别的概率;
M
(
y
)
\mathcal{M(y)}
M(y)表示把
y
y
y映射成
V
\mathcal V
V中的某一个词;
x
p
r
o
m
p
t
x_{prompt}
xprompt为组合后的输入;
w
M
(
y
)
w_{\mathcal{M(y)}}
wM(y)代表
M
(
y
)
\mathcal{M(y)}
M(y)的词向量。
h
[
M
A
S
K
]
h_{[MASK]}
h[MASK]为
L
\mathcal L
L在[MASK]位置的输出向量。
h
[
M
A
S
K
]
h_{[MASK]}
h[MASK]必定与
V
\mathcal V
V中的一个词相近,其实
h
[
M
A
S
K
]
⋅
w
M
(
y
)
h_{[MASK]} \cdot w_{\mathcal{M(y)}}
h[MASK]⋅wM(y)计算的就是两者的相似度,
h
[
M
A
S
K
]
h_{[MASK]}
h[MASK]与哪一个
M
(
y
)
\mathcal{M(y)}
M(y)相近,那个类别的概率就越大。
对于分类
标签中的每个类别的概率
P
l
a
b
e
l
i
P_{label_i}
Plabeli,其实就是该类别对应的词表中词
w
M
(
y
)
w_{\mathcal{M(y)}}
wM(y)乘以
h
[
M
A
S
K
]
h_{[MASK]}
h[MASK]后归一化(此处为softmax)的值。
损失函数为交叉熵。
对于回归
假设预测范围为[
v
l
v_l
vl,
v
u
v_u
vu],我们选择其中一个类别
y
u
y_u
yu,根据表达式计算
p
(
y
u
∣
x
i
n
)
p(y_u|x_{in})
p(yu∣xin)的概率,
那么预测的值就为:
y
=
v
l
+
p
(
y
u
∣
x
i
n
)
⋅
v
u
y=v_l + p(y_u|x_{in}) \cdot v_u
y=vl+p(yu∣xin)⋅vu。
损失函数为
p
(
y
u
∣
x
i
n
)
p(y_u|x_{in})
p(yu∣xin)与
(
y
−
v
l
)
/
(
v
u
−
v
l
)
(y-v_l)/(v_u-v_l)
(y−vl)/(vu−vl)的 KL divergence。
p
(
y
u
∣
x
i
n
)
p(y_u|x_{in})
p(yu∣xin)概率分布其实表示的是:预测的不同类别的多少。
(
y
−
v
l
)
/
(
v
u
−
v
l
)
(y-v_l)/(v_u-v_l)
(y−vl)/(vu−vl)概率分布其实表示的是:真实的不同类别的多少。
我认为,回归问题比较好做的是分类转回归的问题,对于本事就是回归的问题,可能 M ( y ) \mathcal{M(y)} M(y)就不太好找。















 7154
7154











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









