






DifferentiAble pRompT (DART),预训练的语言模型+反向传播对提示模板和目标标签进行差异优化
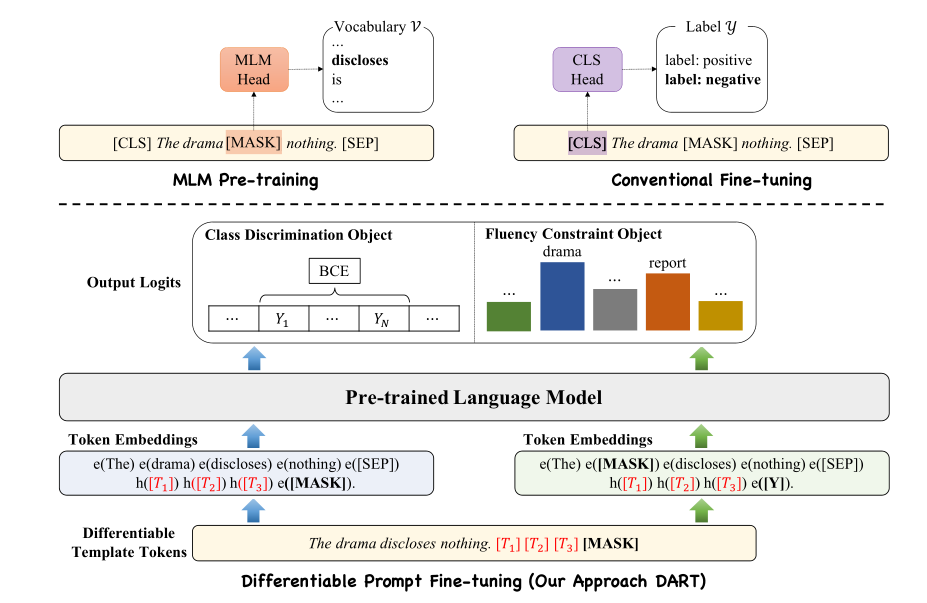
提出了一种新的可微提示(DART)微调方法。如图所示,关键思想是利用语言模型中的一些参数(未使用的标记),它们充当模板和标签token,并使用反向传播在连续空间中对其进行优化。随后,引入可微提示学习来获得优化的提示模板和标签。因为有限样本的微调可能会受到不稳定性的影响。进一步引入了一个辅助流畅性约束对象,以确保prompt嵌入之间的关联
提出了一个新的简单的few-shot learning框架,在15个NLP数据集上进行了实验。在所有任务中只需少量训练样本,DART就能获得更好的性能。值得注意的是,在关系提取数据集上,在设置K=8(全监督设置为1.55%)时,与传统微调相比,绝对性能平均提高了23.28%
p-tuning方法仍然需要优化外部参数(例如,P-tuning中的LSTM),并且容易产生复杂的标签空间。本研究旨在开发一种基于预训练的新的few-shot learning模型,减少提示工程(包括模板和标签)和外部参数优化。此外,所提出的方法仅利用非侵入性对模型的修改,可以插入任何预先训练的语言模型并进行扩展到广泛的分类任务。
1. 模板可微优化
输入与p-tuning类似
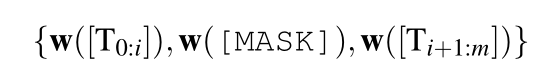
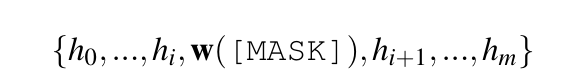
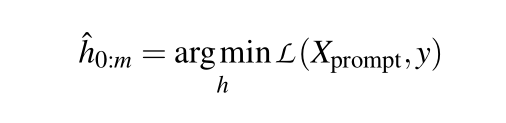
提示嵌入的值hi必须相互依赖,而不是相互依赖而不是独立。与利用双向LSTM的P-tuning不同,DART利用辅助流利度约束目标将prompt embedding之间相互联系(和预训练过程类似的流畅度目标(Fluency Constraint Object),对每个样本随机选取词元进行遮盖并预测)
2. label可微优化
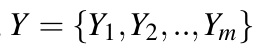
不同于之前的将Yi转化为label token,这一步将Yi映射到连续的词表空间
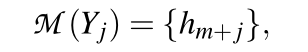
避免优化任何外部参数
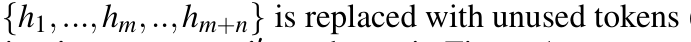
替换为未使用的token
3. Class Discrimination Object 和 Fluency Constraint Object
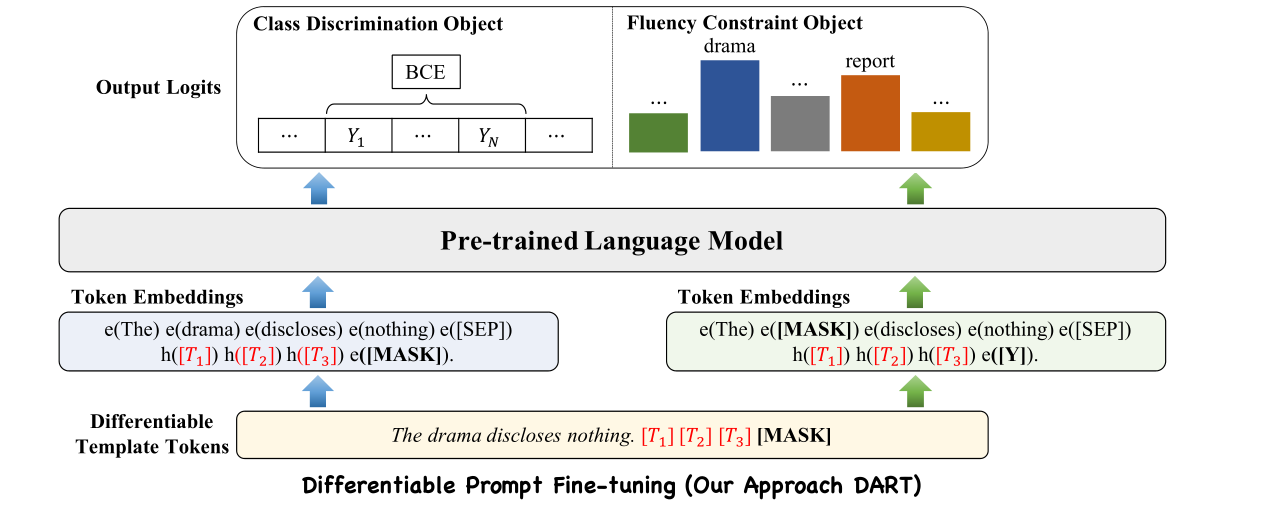
前面是进行句子分类
后面是类似于预训练MLM的对输入句子中的一个标记进行随机掩蔽,并进行掩蔽语言预测















 5156
5156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









