







论文笔记--Selective Annotation Makes Language Models Better Few-Shot Learners
1. 文章简介
- 标题:Selective Annotation Makes Language Models Better Few-Shot Learners
- 作者:Hongjin Su, Jungo Kasai, Chen Henry Wu, Weijia Shi, Tianlu Wang, Jiayi Xin, Rui Zhang, Mari Ostendorf, Luke Zettlemoyer, Noah A. Smith, Tao Yu
- 日期:2022/09/05
- 期刊:arxiv preprint
2. 文章导读
2.1 概括
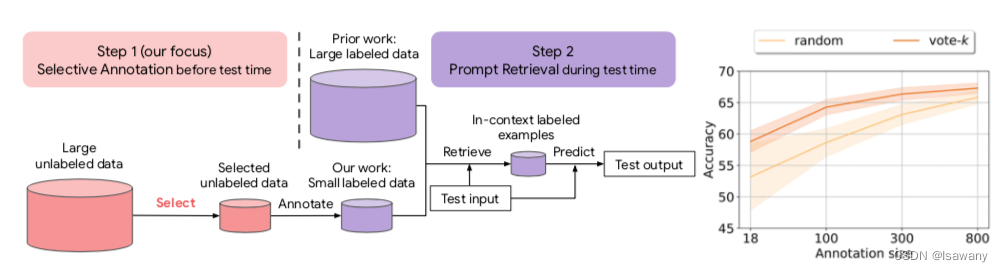
文章从样本池中筛选数据集,对选中的样本进行标注,再通过prompt retrieval进行训练,整体架构如下:
实验证明,通过对选中的少量样本进行标注,得到的模型效果可以追平甚至超过对所有样本进行标注:
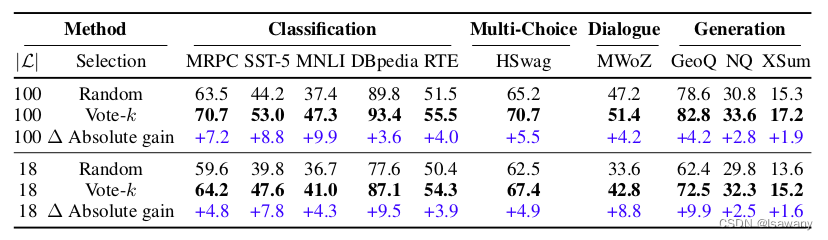
其中Vote-k为本文所述的方法。
2.2 文章重点技术
2.2.1 selective annotation(vote-k)
文章设计了Vote-k方法进行样本选择(共计选择 M M M个样本),并对选择的样本进行标注。Vote-k方法分为以下步骤:
- 使用Sentence-BERT计算每个样本的向量表示,其中每个句子的向量表示采用的是句子中所有输入单词表示的平均值(BERT中使用的是<CLS>向量);
- 计算向量表示两两之间的cosine similarity,得到有向图 G = ( V , E ) G=(V, E) G=(V,E),其中图的顶点集 V V V表示输入的所有向量表示,图的边集 E E E由每个顶点及其最近的 k k k个边生成;
- 将所有顶点分成两个集合
U
\mathcal{U}
U和
L
\mathcal{L}
L分别表示未被选择和已被选择的向量,并初始化
L
=
∅
,
U
=
V
\mathcal{L}=\empty, \mathcal{U} = V
L=∅,U=V。对每个未被选择的向量
u
∈
U
u \in \mathcal{U}
u∈U,计算它的分值:
s c o r e ( u ) = ∑ v ∈ { v ∣ ( v , u ) ∈ E , v ∈ U } s ( v ) , s ( v ) = ρ − ∣ { l ∈ L ∣ ( v , l ) ∈ E } ∣ \begin{equation}score(u) = \sum_{v\in\{v|(v,u)\in E, v \in \mathcal{U}\}} s(v), s(v) = \rho^{-|\{l\in \mathcal{L} | (v, l) \in E\}|}\end{equation} score(u)=v∈{v∣(v,u)∈E,v∈U}∑s(v),s(v)=ρ−∣{l∈L∣(v,l)∈E}∣,上述公式表示每个未被选择的向量对分值可由与它相邻的所有向量的 s ( v ) s(v) s(v)之和表示,其中 s ( v ) s(v) s(v)代表的是一个以 v v v相邻节点中在集合 L \mathcal{L} L的元素数量作为参数的函数, v v v的邻居中越多属于 L \mathcal{L} L(即与 v v v相邻的节点中越多元素被选中),则 s ( v ) s(v) s(v)越少,从而 v v v越不容易被选中。此公式旨在使得选中的元素尽可能不相邻,从而增加多样性(diversity); - 迭代选中 M / 10 M/10 M/10个最大score对应的顶点,得到集合 L \mathcal{L} L,剩余的样本集合为 U \mathcal{U} U;
- 使用 L \mathcal{L} L作为In-Context Learning对样本进行训练,计算每个样本 u ∈ U u\in\mathcal{U} u∈U生成过程的平均log-probability,记作confidence score**,score越大表示该样本预测的越准确**;
- 将所有 u ∈ U u\in\mathcal{U} u∈U按照上述score由小到大排序并按顺序分成 M M M个桶,从前 9 M / 10 9M/10 9M/10个桶中分别选一个概率最小的放入 L \mathcal{L} L,最终得到元素个数为 M M M的集合 L \mathcal{L} L。此步骤旨在选择尽可能不同的confidence score对应的样本,从而增加样本的diversity。
2.2.2 prompt retrieval
将上述集合 L \mathcal{L} L人工标注,每次预测的时候进行prompt retrieval:计算所有标注样本和测试样本的cosine similarity,选定和测试样本最为相似的一些标注样本进行In-Context Learning就可以啦!
3. 文章亮点
文章通过选择少量标注样本,可以持平大规模标注样本或随机标注样本得到模型的表现能力。尤其是文章提到了Fast Vote-k方法,可以避免使用BERT编码每个句子,直接得到标注样本,性能略差于Vote-k但由于文章测试的其它模型,适合初学者使用,大幅降低NLP成本。
4. 原文传送门
Selective Annotation Makes Language Models Better Few-Shot Learners
5. References
[1] Learning To Retrieve Prompts for In-Context Learning
[2] Active Learning
[3] Beam Search















 2264
2264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









