







[memory footprint reduction] Tempo: Accelerating Transformer-Based Model Training through Memory Footprint Reduction. Muralidhar Andoorveedu, Zhanda Zhu, Bojian Zheng, Gennady Pekhimenko. NIPS’22
论文地址:https://arxiv.org/pdf/2210.10246
在深度学习模型的训练中,批量大小往往受到加速器内存容量的限制,因为训练反向传播需要存储更大的激活/特征图,而扩大批量大小就需要存储更大的特征图。
为了解决这个问题,作者们提出了一种新的方法——Tempo。Tempo提供了对GELU、LayerNorm和Attention层的替代实现,从而减少了内存的使用,最终实现了更为高效的训练。
本文是一篇关注算子融合的文章。
结果表明,在BERT-LARGE预训练任务上,它能够使得批量大小提高高达2倍,训练吞吐量增加了16%。在GPT2和RoBERTa模型上,Tempo的训练速度比基线快了19%和26%。
先前工作的问题
第一类方法:过于通用的优化技术
这类方法主要包括内存卸载(offloading)、检查点(checkpointing),以及数据压缩/编码。这些方法的主要特点是它们是设计来应对各种模型和任务的,因此可能无法充分利用基于Transformer的模型的特性。
-
内存卸载:这种方法将部分数据从GPU内存转移到CPU内存,以降低GPU内存的使用。然而,这种方法可能会引入额外的数据传输开销(事实上可以进行一个计算与通信的重叠,也有很多文章做得很好),从而影响模型的训练性能。
-
检查点:这种方法通过只保存必要的中间状态来减少内存使用,而其他状态可以在需要时重新计算。例如,反向传播过程中,我们只需要保存部分中间状态,而其他状态可以通过前向传播重新计算。然而,这种方法可能会增加计算开销(之前读过一些文章,可以细粒度的使用这个,比如占存储多的但是计算快的),例如在某些研究中观察到的30%的性能降低。
数据压缩/编码:这种方法通过压缩或编码数据来减少内存使用。然而,这种方法可能会引入额外的压缩和解压缩的计算开销。(这类也有文章在做,如何更快精度损失更小)
第二类方法:过于特定的优化技术
这类方法主要是为特定模型或层设计的优化技术,例如Gist和In-Place ABN就是为卷积神经网络(CNNs)设计的。(文章提出的这两篇论文没有看过,不过他说的也有道理,但是这个逻辑不是很强。别的文章也可以攻击这篇文章仅适用于Transformer-base的model)
-
Gist:这是一种针对卷积神经网络的内存优化技术,通过减少卷积层的空间复杂度来减少内存使用。然而,这种方法并不适用于基于Transformer的模型,因为Transformer的主要组成部分是注意力层,而不是卷积层。
-
In-Place ABN:这是一种针对卷积神经网络的批量归一化(Batch Normalization)优化技术,通过在原地计算和更新归一化参数来减少内存使用。然而,这种方法也不适用于基于Transformer的模型,因为Transformer通常使用层归一化(Layer Normalization),而不是批量归一化。
总的来说,第一类方法可能由于过于通用而无法充分利用基于Transformer的模型的特性,而第二类方法可能由于过于特定而不能直接应用于基于Transformer的模型。
本文的工作
提出了一种专门为基于Transformer的模型定制的新方法,称为Tempo。这种方法包括三种新技术:
- (i)原地GELU,
- (ii)原地LayerNorm,
- 和(iii)子层Dropout重计算。
这些技术都是为了在不牺牲计算性能的前提下,提高内存效率。
内存分析
-
在计算注意力的地方,我们注意到每个特征图的大小为O(S^2)。在这一点上,我们存储了三个大小为[B × A × S^2]的特征图。基于BERTBASE参数的计算显示,当序列长度为512时,这三个特征图占了编码器层激活内存的56%。
-
在Transformer的一层中,我们存储了两个LayerNorm层的输入,大小为[B × S × H]。
-
关注GELU层,这被用作前面全连接层(大小为[B × S × 4H])的激活函数。此功能的激活内存占用了BERTBASE在序列长度为128时,总层激活内存的近17%。
对应措施:
- 虽然没有直接处理注意力层那三个特征图(占比超过一半),但是这些特征图要去到LN那里,作者处理了LN层。
- GELU占比有些大,本文处理了这个层
- 注意力层的三个特征图还要经过dropout层,所以也要进行一个处理
本文没有直接处理注意力层的巨大的特征图,而是对这巨大的特征图的去向进行处理:Dropout和LN
这里放一张Transformer的图,供大家对应理解,这部分就不解释图了。
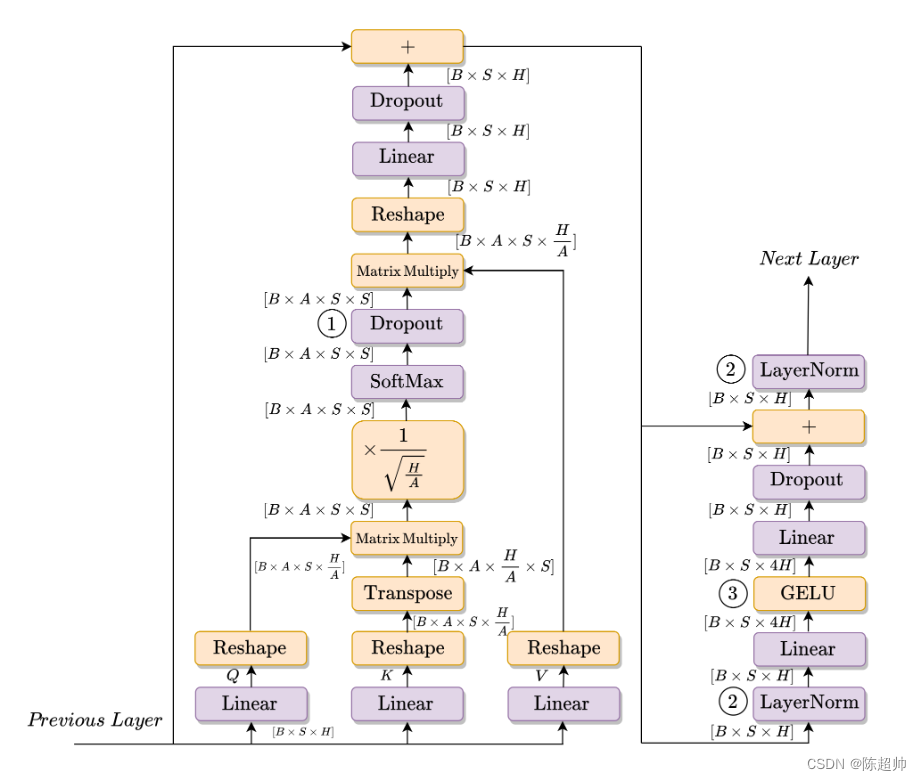
作者指出,虽然模型参数对内存占用有影响,但在训练过程中实际上主要的内存容量消耗者是激活特征图。特别是,大部分这种激活内存将在BERT的每一个Transformer编码器层中使用。在序列长度为128、批处理大小为32的MRPC微调任务上,对Huggingface的BERTBASE实现进行性能分析显示,66%的总内存被这些编码器激活占用。
这里指出来激活内存的占比比较高,之前也有一些文章说优化器状态占比比较高,可能是模型之间的差异,这个地方值得去调研一下。在传统的Transformer和现在的大语言模型,这个内存的占用可能会有所却别。
相关的工作介绍
这里主要是温故知新一下
减少深度学习模型训练内存占用的三种主要技术:检查点(Checkpointing)、卸载(Offloading)和压缩/编码(Compression/encoding)。
-
检查点(Checkpointing):这种技术涉及到在前向传播过程中丢弃某些特征图,同时保留其他的。然后,在反向传播过程中,这些被丢弃的特征图可以从保留的特征图中重新计算出来,因此可以用于计算梯度。
-
卸载(Offloading):这种技术的主要思想是将原本会存储在GPU内存中的特征图卸载到CPU内存中。这种技术还可能涉及到预取(pre-fetching)张量,以便提前使用。然而,卸载技术受到系统变量(如通信通道带宽)的影响,并且需要大量的工程努力来避免高开销。
-
压缩/编码(Compression/encoding):这种技术可以分为两种不同的类别,无损(lossless)和有损(lossy)。然而,基本的思想是在前向传播过程中压缩特征图,以减少它们占用的空间,然后在反向传播过程中对其进行解压以供使用。
这些技术通常是正交的,也就是说,它们可以同时使用,而且不会互相干扰。例如,在之前的一些工作中,卸载和检查点技术就被同时使用。
本文的工作
原位GELU(In-place GELU)
GELU是一种常用的激活函数。在原位GELU中,每层的输出是在原地计算的,而不是使用输出激活来计算梯度。这样可以节省存储空间。
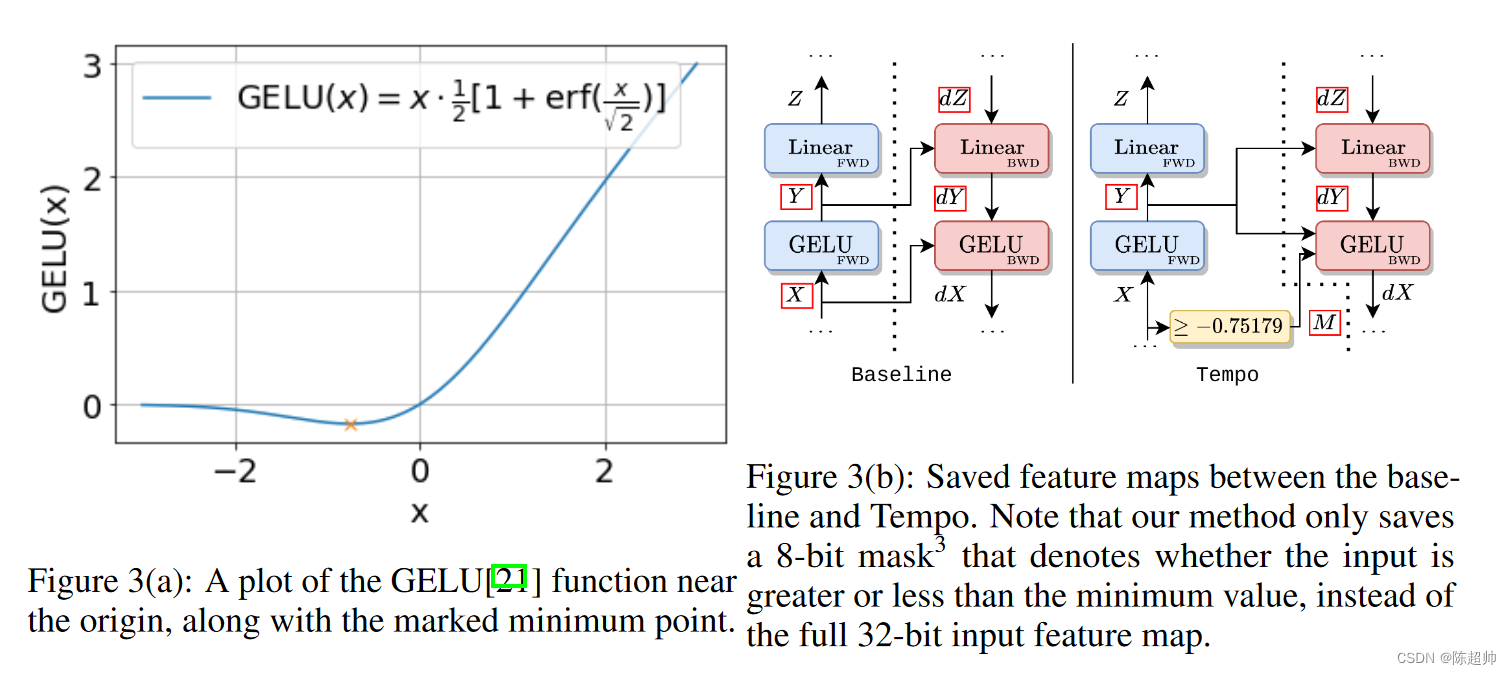
图3a展示了这个函数的图形。参考图3b中的基线,注意到在反向传播过程中,X和Y都需要被存储。Y被下游的全连接层所需要,而X是为了GELU层本身存储的。以前的研究已经证明,ReLU等某些激活函数可以在原地计算出来,这并不会影响反向传播的计算。如果我们能够在原地计算GELU函数,可能通过在反向传播时从输出恢复输入,我们就能够节省存储X所需的空间。然而,这是无法直接做到的。
关于GELU函数的一个关键观察是,它不是双射的,所以没有办法从输出计算出输入而不需要额外的信息。
但是:
- 我们观察到GELU函数是连续的,并且只有一个极值点,这个极小值点在x ≈ -0.75179处(如图3a所示)。
- 这意味着只需要一个额外的信息:输入源自最小值的哪一侧,就能计算出GELU的反函数。这是因为在最小值的每一侧,函数都是一一对应的,因此在每个区间内,输入都可以从输出中恢复出来。
基于这个关键观察,我们可以舍弃输入,只保留GELU的输出,以及一个额外的信息,即输入是否大于或等于最小值出现的值。图3b说明了我们的方法和基线之间的区别。
为了在实际系统上高效地执行这个操作,我们注意到,原始的导数可以与函数反函数组合,以创建一个复合核。这个核由这个复合函数的多项式近似组成,这个近似是必要的,因为GELU是超越的,所以反函数不能用基本函数求解。(这个地方我觉得知道他是怎么做的就行了,暂不深究其数学近似方法,留一个tag在这里,需要的时候回来看看)
原位LayerNorm(In-place LayerNorm)
LayerNorm是一种常见的归一化技术,用于减少内部协变量移位。原位LayerNorm也是在原地计算每层的输出,以节省存储空间。
- 通常,LayerNorm的梯度计算依赖于下一层的梯度输入,以及为此计算而保存的输入特征图。
- 我们能够得出LayerNorm层的梯度作为其输出的函数的表达式,类似于GELU。
- 使用类似原地GELU的方法,LayerNorm的内存占用只是前向传播中计算出的中间均值和方差。
这个部分的数学比较复杂,我建议想要学习的同学去看看原文,这个部分在附录中

也就是说我们直接使用 LayerNorm 的输出值 和存储的权重γ,偏差β和输入的方差γ²来计算梯度就可以了,不需要存储和计算LayerNorm的输入了。
与Checkpointing的比较:请注意,尽管原位GELU需要比从X重新计算Y更多的内存,但是由于重新计算,它将产生更大的开销。
此外,我们的技术与传统的Checkpointing是正交的,因为它可以利用不需要为输入X重新计算的事实,这对于原位GELU和原位LayerNorm都是如此。所以说,这个其实可以和Checkpointing结合起来一起用。
子层Dropout重计算(Sub-Layer Dropout Recomputation)
在子层Dropout重计算中,输出被丢弃,并且通过仔细查看Dropout层的结构,能够在没有过多重计算的情况下重新计算输出。这个部分make sense.
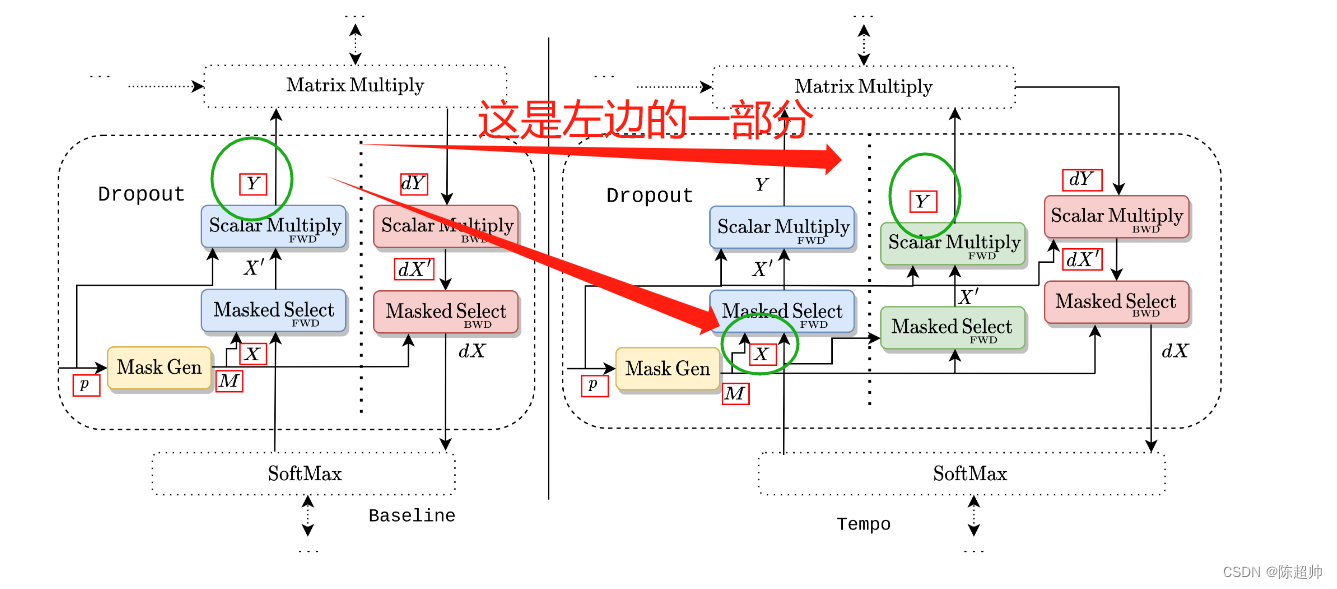
在实现Dropout时,会生成一个"掩码"(mask),这个掩码记录了哪些神经元被关闭,哪些神经元保持活跃。同时,也会生成Dropout之后的输出。
在反向传播过程中,原则上我们需要保留前向过程中所有的输入和中间计算结果,因为这些都可能被用于计算梯度。但是,这样会占用大量的内存,所以有一种叫做"检查点"的技术,可以在内存中只保留一部分中间结果,其他的在需要的时候重新计算。
这里提到的"子层重新计算",就是指在一个层级中,只重新计算一部分的特征图,而不是全部。以Dropout层为例,我们可以选择只保留掩码,而不保留Dropout的输出。因为掩码只包含布尔值,所以占用的内存很小。在反向传播时,我们可以使用掩码重新计算Dropout的输出,因此,我们可以在减少内存使用的同时,也不会增加太多的计算量。这就是所谓的"子层重新计算"策略。
这个部分的输入是那个占比很大的注意力层的东西,通过优化这个重计算方法,可以减少很多内存占用,虽然实现是比较简单的。
softmax优化
作者指出,PyTorch中的softmax函数的实现在内存使用上不够高效,因为它在反向传播过程中保留了函数的输入和输出。实际上,只需要保留输出就足够了。这种优化已经在Huggingface库的一些模型中实现过。
也就是说本文的系统中也优化了softmax,但是这是用的别人的实现,所以作者就不展开说了。
这篇理解起来比较简单,就写到这里~















 541
541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









