







1.多维输入
之前我们的输入都是只有一个维度,如果有多个维度呢?
对于每一行叫做一个sample(样本)
对于每一列叫做一个feature(特征)
数据集各种各样的什么都有。
csv可以使用excel打开,只能打开逗号做分割的数据集,空格和tab都是不行的。所以可以用记事本打开看一下子。
原来的处理函数发生了相应的变化,从一维的变化成了多维

这个过程拆解来看其实是这样子的:为了保证其标量性做了一次转置:

这里我们有一次简写:算出来的这个标量整体写成z

pytorch中的所有继承自torch.nn.module的这些函数都是向量化函数,在执行的时候函数将自动的应用在向量的每个元素当中,如下图所示:
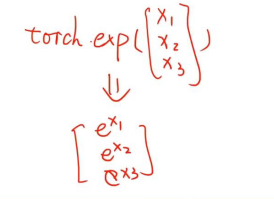
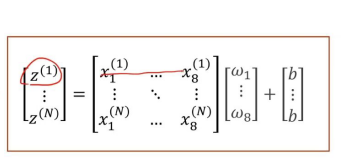
我们使用z来表示全部内容就是这样子的,同时因为自动的向量化我们可以写成后面的形式。然后我们仔细想一下这个事情,把这个再展开,看看抽象里面到底是什么内容:

但是上面的式子,只是我们理解计算做的事情相当于在做什么,看起来好像是使用一个for循环来操作就行了,但是torch真正在做什么呢?其实整体都扩展为向量和矩阵计算的。
2.多层神经网络的问题
之前我们讲的是罗杰斯特回归的情况是,都是一层的,那多层的又是怎样的一种情况呢?
什么是矩阵呢?矩阵其实可以理解成一个空间变换方程,就是从一个维度的方程变化成另外一种维度的方程。从一个维度的空间的一个向量直接对应成为另外一个维度空间的一个向量,所以可以看成是一种空间变换的函数。
我们其实是用多层的线性函数模拟一种非线性的函数,让训练的模型更加接近实际情况。为什么可以拟合一个非线性呢?主要是是siogmal函数来引入了非线性的变换。其实我们只要在维度降低的过程时候多拆分几次就可以了。
当然我们也可以先往高维度变换,再向低维度来进行变化。这种维度变得更多,其实是超参数的变换。这样可以增加学习能力,但是学习能力太强也不行,会产生噪声的问题。
2.1泛化能力
我们已学习来举例子。并不用死扣书本,因为偏技术应用性的内容可能过几年就发生了变化。要有读文档(主要是应对版本更新的问题)、计算机各种科目的基本架构都了解掌握的能力。这样其实就是泛化能力比较强。所以这样我们就更加能够理解学习器学习能力太强的情况了。学习能力太强其实就是在背书本了。
3.代码实现
3.1正常实现
这里面其实我们只是更改了模型这里的内容
class MyModule(torch.nn.Module):
def __init__(self):
super(MyModule,self).__init__()
self.linear9_8=torch.nn.Linear(9,8)
self.linear8_6=torch.nn.Linear(8,6)
self.linear6_2=torch.nn.Linear(6,2)
self.linear2_1=torch.nn.Linear(2,1)
self.sigmoid=torch.nn.Sigmoid()
#这里我们注意我们是让sigmoid单独成为了一个层,和之前的在functional当中调用的那个是不一样的
def forward(self,x):
x=self.sigmoid(self.linear9_8(x))
x=self.sigmoid(self.linear8_6(x))
x=self.sigmoid(self.linear6_2(x))
x=self.sigmoid(self.linear2_1(x))
#我们注意这里的是最好反复使用同一个x,不要写x1x2这种,因为那样子的话容易出错。
3.2激活函数的快速修改
我们可以将激活函数也提前定义出来这样就可以一下子更改所有了
于此同时我们要注意我们是一个分类还是一个回归分析,如果是一个分布我们一定要注意最终一定要是一个sigomid()
class MyModule(torch.nn.Module):
def __init__(self):
super(MyModule,self).__init__()
self.linear9_8=torch.nn.Linear(9,8)
self.linear8_6=torch.nn.Linear(8,6)
self.linear6_2=torch.nn.Linear(6,2)
self.linear2_1=torch.nn.Linear(2,1)
self.active=torch.nn.Sigmoid()
#这里我们注意我们是让sigmoid单独成为了一个层,和之前的在functional当中调用的那个是不一样的
def forward(self,x):
x=self.active(self.linear9_8(x))
x=self.active(self.linear8_6(x))
x=self.active(self.linear6_2(x))
x=self.active(self.linear2_1(x))
#我们注意这里的是最好反复使用同一个x,不要写x1x2这种,因为那样子的话容易出错。
















 4962
4962











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











