









如果您对这个论文不太了解,想从总体上先了解这个论文的情况,可以前往Neural Inertial Localization论文简述
快速预览
0.Abstract
0.1 逐句翻译
This paper proposes the inertial localization problem,the task of estimating the absolute location from a sequence of inertial sensor measurements.
本文提出了惯性定位问题,即从一系列惯性传感器测量中估计绝对位置的任务。
This is an exciting and unexplored area of indoor localization research, where we present a rich dataset with 53 hours of inertial sensor data and the associated ground truth locations.
这是室内定位研究中一个令人兴奋的、未开发的领域,我们提供了一个包含53小时惯性传感器数据和相关地面真实位置的丰富数据集。
We developed a solution, dubbed neural inertial localization (NILoc)which
我们开发了一种解决方案,称为神经惯性定位(NILoc)
-
uses a neural inertial navigation technique to turn inertial sensor history to a sequence of velocity vectors;then
1)利用神经惯性导航技术将惯性传感器历史转换为速度向量序列 -
employs a transformer-based neural architecture to find the device location from the sequence of velocities.
2)采用基于transformer的神经结构从速度序列中查找设备位置。
We only use an IMU sensor, which is energy efficient and privacy preserving compared to WiFi, cameras, and other data sources.
我们只使用了一个IMU传感器,与WiFi、摄像头和其他数据源相比,它更节能、更保护隐私。
Our approach is significantly faster and achieves competitive results even compared with state-of-the-art methods that require a floorplan and run 20 to 30 times slower.
与最先进的方法相比,我们的方法明显更快,取得了有竞争力的结果,即使需要一个平面图,运行速度要慢20到30倍。
We share our code, model and data at https://sachini.github.io/niloc.
我们在https://sachini.github.io/niloc上分享我们的代码、模型和数据。
0.2 总结
相当于什么都没说,这是一篇说惯性定位的文章,有两个特点:
- 1)是通过估计速度得到定位结果的
- 2)是用transformer的
1. Introduction
1.1逐句翻译
第一段(作者说他要提出一种新的范式,用来解决惯性定位)
Imagine one stands up, walks for 3 meters, turns right, and opens a door in an office. This information might be sufficient to identify the location of the individual.
想象一个人站起来,走3米,向右转,打开一间办公室的门。这些信息可能足以确定个人的位置。
A recent breakthrough in inertial navigation [10, 14, 22] allows us to obtain such motion history using an inertial measurement unit (IMU).
最近惯性导航技术的一项突破[10,14,22]允许我们使用惯性测量单元(IMU)获得这样的运动历史。
What is missing is the technology that maps a motion history to a location.
现在缺少的是将运动历史映射到某个位置的技术。
This papers addresses this gap, seeking to open a new paradigm in the localization research, named “inertial localization”, whose task is to infer the location from a sequence of IMU sensor data.
本文针对这一空白,试图在定位研究中开辟一种新的范式,即“惯性定位”,其任务是从IMU传感器数据序列中推断位置。
第二段(前人的研究都使用了wifi,但如果用wifi扩展性就弱了,因此不能用wifi)
Indoor localization is a crucial technology for locationaware services, such as mobile business applications for consumers, entertainment (e.g., Pokemon Go) for casual users, and industry verticals for professional operators (e.g., maintenance at a factory).
室内定位是位置感知服务的关键技术,如面向消费者的移动商务应用,面向休闲用户的娱乐(如《Pokemon Go》),以及面向专业运营商的垂直行业(如工厂维护)。
State-of-the-art indoor localization systems [5] mostly rely on WiFi, whose infrastructure is ubiquitous thanks to the demands on Internet of Things (IoT).
最先进的室内定位系统[5]大多依赖于WiFi,由于物联网(IoT)的需求,其基础设施无处不在。
Nevertheless, accuracy of WiFi based localization depends on infrastructure (i.e number of access points) thus cannot scale easily to non-commercial private spaces.
然而,基于WiFi的定位精度取决于基础设施(即接入点的数量),因此无法轻松扩展到非商业私人空间。
第三段(惯性传感器与之相比具有很大优势)
IMU is a powerful complementary modality to WiFi, which has proven effective for the navigation task recently [10,14,22]. IMU 1) works anytime anywhere (e.g., inside a pocket/bag/hand); 2) is energy efficient to be an always-on sensor and 3) protects the privacy of bystanders.
IMU是WiFi的强大补充方式,最近在导航任务中被证明是有效的[10,14,22]。IMU
1)随时随地都可以使用(例如,在口袋/包/手上);
2)是一个永远在线的传感器,具有能源效率;(大约就是惯性传感器可以一直工作)
3)保护旁观者的隐私。
第四段(介绍惯性导航定位)
This paper introduces a novel inertial localization problem as a task of estimating the location from a history of IMU measurements.
本文介绍了一种新的惯性定位问题,即从惯性单位的测量历史中估计位置。
The paper provides the first inertial localization benchmark, consisting of 53 hours of motion data and ground-truth locations over 3 buildings.
该论文提供了第一个惯性定位基准,包括3栋建筑上53小时的运动数据和地面真实位置。
The paper also proposes an effective solution to the problem, dubbed neural inertial localization (NILoc).
本文还提出了一种有效的解决方法,即神经惯性定位(NILoc)。
NILoc first uses a neural inertial navigation technique [10] to turn IMU sensor data into a sequence of velocity vectors, where the remaining task is to map a velocity sequence to a location.
NILoc首先使用神经惯性导航技术[10]将IMU传感器数据转换为速度向量序列,剩下的任务是将速度序列映射到某个位置。
The high uncertainty in this remaining task is the challenge of inertial localization.
剩余任务的高度不确定性是惯性定位的挑战。
For instance, a stationary motion can be anywhere, and a short forward motion can be at any corridor.
例如,静止的运动可以在任何地方,而短的前进运动可以在任何走廊。
To overcome the uncertainty, our approach employs a Transformer-based neural architecture [27] (capable of encoding complex long sequential data) with a Temporal Convolutional Network (further expanding the temporal capacity by compressing the input sequence length) and an auto-regressive decoder (handling arbitrarily long sequential data).
为了克服不确定性,我们的方法采用了基于Transformer的神经体系结构(能够对复杂的长序列数据进行编码)和时间卷积网络(通过压缩输入序列长度进一步扩展时间容量)和自回归解码器(处理任意长序列数据)。
第五段(谈贡献)
The contributions of the paper are 3-fold: 1) a novel inertial localization problem, 2) a new inertial localization benchmark, and 3) an effective neural inertial localization algorithm.
本文的贡献有三个方面:
1)一个新的惯性定位问题,
2)一个新的惯性定位基准,
3)一个有效的神经惯性定位算法。
We will share our code, models and data.
我们将分享我们的代码、模型和数据。
2. Related Work
2.1. Indoor localization
Outdoor navigation predominately uses satellite GPS.Indoor localization often relies on multiple data sources such as images, WiFi, magnet, or IMU. We review indoor localization techniques based on the input modalities
暂时跳过
IMU and floorplan
IMU and floorplan fusion allows classical filtering methods (e.g., particle filter) to perform localization [25]
by using inertial navigation to propagate particles and the floorplan to re-weight particles. This approach is sensitive to cumulative sensor errors in inertial navigation. Correlation between a short motion history (five seconds) and floorplan can provide additional prior to weigh particles [16] but requires start location and orientation to initialize the system. We employ a novel Transformer-based neural architecture that regresses the location from long motion history even under severe bending. Our approach does not require a floorplan, which often misses transient objects (e.g., chairs/desks) and needs occasional updates, thus provide a compelling alternative.
3. Inertial Localization Problem
3.1 逐句翻译
详细介绍惯性定位的问题设定(如果了解惯性定位,直接跳过就好,作者是输入加速度、陀螺仪、地磁输出位置)
Inertial localization is the task of estimating the location of a subject in an environment, solely from a history of IMU sensor data.
惯性定位是一项仅从IMU传感器的历史数据估计环境中目标位置的任务。
There is a training phase and a testing phase i.e. without a use of a floorplan or external location information.
有一个训练阶段和一个测试阶段,即不使用平面图或外部位置信息。
During testing, an input is a sequence of acceleration (accelerometer), angular velocity (gyroscope), and optionally magnetic field (compass) measurements, each of which has 3 DoFs.
在测试过程中,输入是一系列加速度(加速度计)、角速度(陀螺仪)和可选磁场(罗盘)测量,每一个都有3个DoF。(这个DoF指的是自由度,也就是三轴)
An output is position estimations for a given set of timestamps, when ground-truth positions are available.
输出是一组给定时间戳的位置估计,当地面真实位置可用时。
During training, we have a set of input IMU sensor data and output positions.
在训练过程中,我们有一组输入IMU传感器数据和输出位置。
第二段(介绍本文的衡量标准)
Metrics: The localization accuracy is measured by
- the ratio (%) of correct position estimations within a distance threshold (1, 2, 4, or 6 meters) [24];
- the ratio (%) of correct velocity directions within an angular threshold (20 or 40 degrees).
指标:定位精度是通过
1)在距离阈值(1、2、4或6米)[24]内正确位置估计的比率(%);
2)在一个角度阈值(20或40度)内的正确速度方向的比例(%)。
The position ratio is the main metric, while the direction ratio measures the temporal consistency
位置比是主要度量指标,方向比衡量时间一致性
第三段(文章作者是有机会性修正的,这种修正来自于一段时间一次的WiFi定位)
Re-localization task extension: We propose an inertial re-localization task, which is different from inertial localization in that the position R2 (and optionally the motion direction SE(2)) is known apriori.
再定位任务扩展:我们提出了一种惯性再定位任务,它与惯性定位的不同之处在于位置R2(可选的运动方向SE(2))是先验已知的。
The task represents a scenario where one uses WiFi to obtain a global position once in a few minutes, while re-localizing oneself in-between with an IMU sensor for energy efficiency.
该任务描述了一个场景,使用WiFi在几分钟内获得一次全球位置,同时使用IMU传感器重新定位自己,以提高能源效率。
3.2 总结
- 1.这个文章当中说的定位就是传统九轴输入输出一个位置
- 2.这个文章的评价标准是:
1)在距离阈值(1、2、4或6米)[24]内正确位置估计的比率(%);
2)在一个角度阈值(20或40度)内的正确速度方向的比例(%)。 - 3.这个文章当中的模型带有机会性修正
4. Inertial Localization Dataset
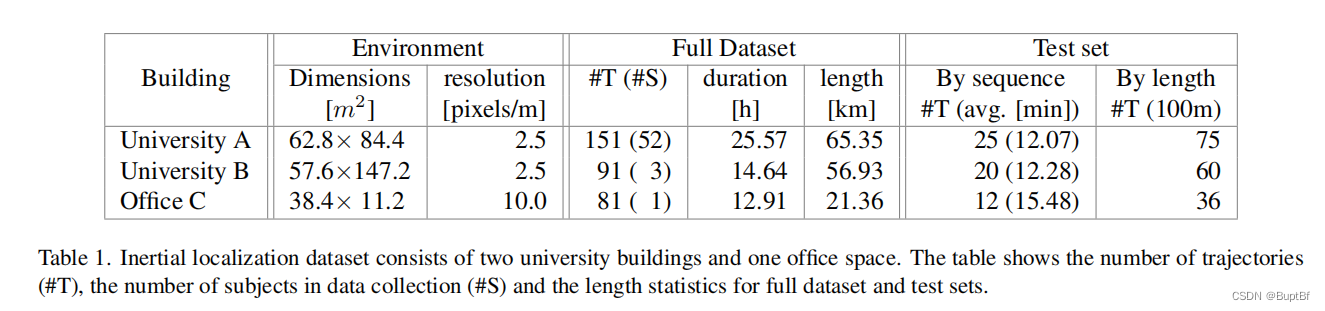
第一段(总体介绍这个数据集都包含什么)
We present the first inertial localization dataset, containing 53 hours of motion/trajectory data from two university buildings and one office space. Table 1 summarizes the dataset statistics, while Fig. 2 visualizes all the ground-truth trajectories overlaid on a floorplan. Each scene spans a flat floor and the position is given as a 2D coordinate without the vertical displacement.
我们提出了第一个惯性定位数据集,包含了来自两个大学建筑和一个办公空间的53小时的运动/轨迹数据。表1总结了数据集统计数据,而图2可视化了覆盖在平面图上的所有地面真实轨迹。每个场景跨越一个平坦的地板,位置以二维坐标给出,没有垂直位移。
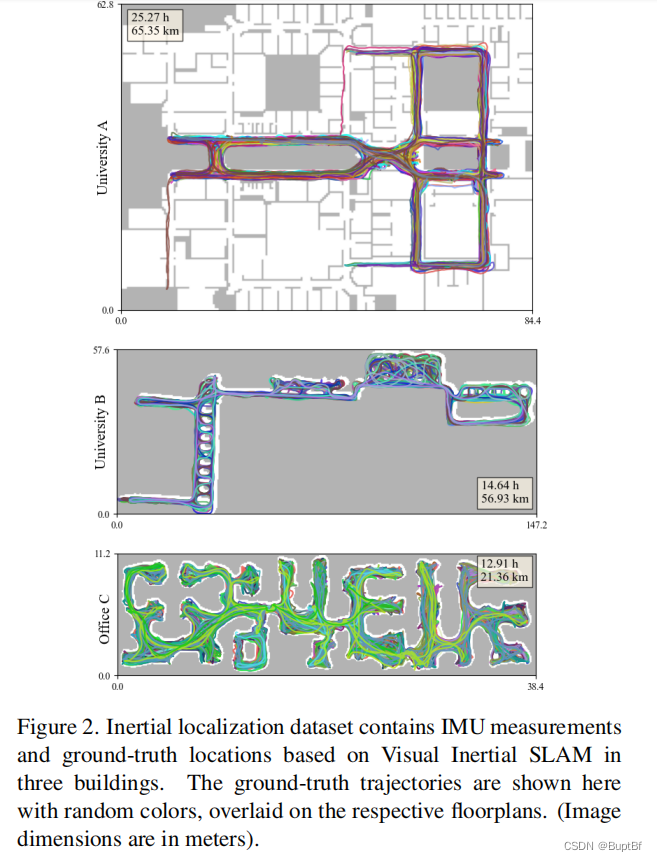
If available, a floorplan image is provided for a scene for qualitative visualization, which depicts architectural structures (e.g., walls, doors, and windows) but does not contain transient objects such as chairs, tables, and couches.
如果可能的话,提供一个用于定性可视化的场景的平面图图像,它描述了建筑结构(例如,墙壁、门和窗户),但不包含诸如椅子、桌子和沙发等临时对象。
(场景可能提供一部分)
Data collection:
We collect IMU sensor data and groundtruth locations with smartphones. In the future, AR devices (e.g., Aria glasses by Meta, Spectacles by Snap)will allow collection of ego-centric datatsets with tightly coupled IMU and camera data. We used two devices in this work; 1) a handheld 3D tracking phone (Google Tango, AsusZenfone AR) with built-in Visual Inertial SLAM capability, producing ground-truth relative motions, where the Z axis is aligned with the gravity; and 2) a standard smartphone, recording IMU sensor data under natural phone handling (e.g. in a pocket, hand or used for calling etc.). We utilize Tango Area Description Files [6] to align ground-truth trajectories to a common coordinate frame then manually align with the floorplan. University A contains data from RoNIN dataset [10] aligned manually to a floorplan. Both IMU sensor data and ground-truth positions are recorded at 200Hz.
Test sequences:
We randomly select one sixth of the trajectories as the testing data, whose average duration is
13.3 minutes. We also form a set of short fixed-length sub-sequences for testing by randomly cropping three sub-sequences (100 meters) from each testing sequence.
5. NILoc: Neural Inertial Localization
5.0 简述
5.0.1逐句翻译
第一段(文章主要关注是速度向量转化为位置的过程)
Instead of regressing locations from IMU measurements, our system NILoc capitalizes on neural inertial navigation technology [10] that turns a sequence of IMU sensor data to a sequence of velocity vectors, where our core task will be to turn velocity vectors into location estimations.
我们的NILoc系统利用了神经惯性导航技术[10],将IMU传感器数据序列转换为速度向量序列,而不是从IMU测量数据回归位置,我们的核心任务将是将速度向量转换为位置估计。
(文章主要关注是速度转化为位置的问题)
第二段(总览各个网络结构什么作用)
High uncertainty is the challenge in the task. NILoc employs a neural architecture with two Transformer-based network branches [27], capable of using long history of complex motion data to reduce uncertainty.
高不确定性是任务中的挑战。NILoc采用了具有两个基于Transformer的网络分支[27]的神经体系结构,能够使用复杂运动数据的长历史来减少不确定性。
The “velocity branch” encodes a sequence of velocity vectors, where a Temporal Convolutional Network compresses temporal dimension to further augment the temporal receptive field.
“速度分支”编码速度向量序列,其中时间卷积网络压缩时间维度以进一步增强时间感受野。(中间的卷积是为了增加感受野)
The “auto-regressive location branch” encodes a sequence of location likelihoods, capable of autoregressively producing location estimates on a long horizon.
“自回归位置分支”编码一个位置可能性序列,能够在较长的视距上自回归生成位置估计。
The network is trained per scene given training data.
每个场景给定训练数据,对网络进行训练。
第三段(介绍下面各节讲什么)
The section explains the two branches (Secs. 5.1 and 5.2), the training scheme (Sec. 5.3), and the data augmentation process (Sec. 5.4), which proves effective in the absence of sufficient training data.
本节解释了两个分支(第5.1节和第5.2节)、培训方案(第5.3节)和数据增强过程(第5.4节),在缺乏足够的培训数据的情况下,该过程被证明是有效的。
5.1 Velocity branch
5.1.1
简述(网络组成是基于tcn的速度压缩器、Transformer速度编码器和翻译感知位置解码器。)
The branch estimates a location sequence using a history of velocity data. It consists of three network modules: TCN-based velocity compressor, Transformer velocity encoder, and Translation-aware location decoder.
分支使用速度数据的历史记录来估计位置序列。它由三个网络模块组成:基于tcn的速度压缩器、Transformer速度编码器和翻译感知位置解码器。
TCN-based velocity compressor(TCN压缩):
Transformer is powerful but memory intensive. We use a temporal convolutional network (TCN) [2] to compress a velocity sequence length by a factor of 10, allowing us to process longer motion history.
Transformer功能强大,但需要大量内存。我们使用时间卷积网络(TCN)[2]将速度序列长度压缩为10倍,允许我们处理更长的运动历史。
In particular, we use a 2-layer TCN with a receptive field of 10 to compress a sequence of 2D velocity vectors {vt} of length T into a sequence of d-dimensional2 feature vectors {v′t} of length T/10:
特别地,我们使用一个接受场为10的2层TCN将长度为T的二维速度向量{vt}序列压缩为长度为T/10的d维2特征向量{v 't}序列:
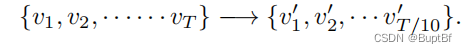
Transformer encoder:
Transformer architecture [27] takes compressed velocity vectors {v′t} as tokens and initializes each feature vector ft by concatenating the d/2 dimensional trigonometric position encoding of the frame index:
Transformer架构[27]以压缩速度向量{v 't}作为标记,通过连接帧索引的d/2维三角位置编码,初始化每个特征向量ft:ft is of dimension d′(= 3/2 d).
(理解一下这个d是啥,这个d就是v 't的维度)
(为什么变成了3/2d,因为后面加入的,cos (wit), sin (wit)两个东西都是d/4长度。)
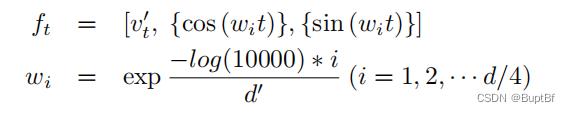
An output embedding et per token is also a d′ dimensional vector encoding the location likelihood.
每个标记的输出嵌入et也是编码位置可能性的d维向量。
The encoder has two blocks of self-attention networks.Each block has 2 standard transformer encoderlayers with 8-way multi-head attention.
编码器有两个自我注意网络块。每个块有2个标准的有8路多头注意力机制的transformer编码器。
Feature vectors after the first block are also passed to the other branch (i.e., auto-regressive location branch).
第一个块之后的特征向量也被传递到另一个分支(即自回归定位分支)。
Translation-aware location decoder(诠释编码器):
The last module operates on each individual embedding:et.
最后一个模块操作每个单独的嵌入,这个东西被称作et。
First, et is rearranged into an image feature volume (3D tensor 3) and up-sampled via a 3-layer fully convolutional decoder with transpose convolutions.
首先,et被重新排列成一个图像特征体(3D张量),并通过一个带有转置卷积的3层全卷积解码器进行上采样。
(这图像特征体(3D张量)是场景绑定的,需要根据不同的场景做出变换,原文也说了在ABC三个不同的场景这里分别是不同的:The dimensions (width,height,channels) are 24x18x1, 16x44x1, and 14x48x1 for the three scenes A, B, and C, respectively)
The last layer is a “translationaware” 1 × 1 convolution, whose parameters are not shared across pixels
最后一层是参数不跨像素共享“翻译感知”的1 × 1卷积
(这里的最大关键是一个参数不共享的1×1卷积,这样就使得每个位置得到不同的映射)
To account for uncertainty, the output location is represented as a 2D likelihood map Lt of size W×H: L(x, y).
为了考虑不确定性,输出位置表示为大小为W×H: L(x, y)的2D似然图Lt。
This translation-aware layer allows the network to easily learn translation-dependent information such as “people never come to this location” or “one always pass through this doorway”
这个翻译感知层允许网络轻松地学习与翻译相关的信息,如“人们从来没有来过这个位置”或“总是有人经过这个门口”。
5.1.2 总结
整体逻辑
- 1.网络整体是:基于tcn的速度压缩器、Transformer速度编码器和翻译感知位置解码器三部分组成。
- 2.tcn速度压缩器:为了增加感受野,所以用tcn压缩一下原来的速度
- 3.Transformer encoder:为利用卷积进行特征提取。
- 4.Translation-aware location decoder:为了更加适合这个场景,所以设置了这一层,目标是对输出的图片用卷积进行一个修正,但是这个是场景有关的,每个场景需要用不同的网络
- 5.这里注意这个Translation-aware location decoder,关注的始终不是这一点,或是这一片区域,而是关注的是整张地图,输出始终是当前人在整张地图的位置。(也就是背景板始终是整张地图,所以多次训练之后才能得到轨迹在当前地图下的修正)
需要注意的是,最终进行位置修正的1×1卷积网络是:
- 1.每个场景不同的
- 2.不共享参数的,因为一个轨迹当中不同位置的优化需要不同
5.2. Auto-regressive location branch
5.2.1逐句翻译
第一段(位置分支加入了速度特征,可以推算更多的内容)
The location branch combines the velocity features from the velocity branch and prior location likelihoods, which comes from its past inference or an external position information such as WiFi.
位置分支结合了来自速度分支的速度特征和先验位置可能性,先验位置可能性来自于它的过去推断或外部位置信息,如WiFi。
第二段(位置分支的区别)
The location branch has the same architecture as the velocity branch with two differences.
位置分支具有与速度分支相同的体系结构,但有两个不同之处。
First, instead of a TCN-based velocity compressor, we use a ConvNet to convert each W×H likelihood map into a d′ -dimensional vector.
首先,我们不使用基于tcn的速度压缩器,而是使用ConvNet将每个W×H似然图转换为d维向量。
We use the same trigonometric position encoding (but with dimension d′ instead of d/2 to match the dimension), which is added to the vector. Second, we inject velocity features from the velocity branch via cross-attention after every self-attention layer (i.e., before every add-norm layer).
我们使用相同的三角位置编码(但使用维数d '而不是d/2来匹配维数),它被添加到向量中。其次,我们在每个自我注意层之后(即每个添加范数层之前)通过交叉注意从速度分支注入速度特征。
The rest of the architecture is the same.
其余的体系结构是相同的。
Note that both branches predict locations, and have different trade-offs (See Sect. 6.4 for ablation study and discussion).
注意这两个分支预测位置,并有不同的权衡(见6.4节消融研究和讨论)。
第三段(介绍具体的位置模型预测逻辑)
At inference time, we first evaluate the velocity branch in a sliding window fashion to compute velocity feature vectors.
在推理时,我们首先以滑动窗口的方式计算速度分支来计算速度特征向量。
The location branch takes a history of location likelihoods up to 20 frames: {Lt, Lt−1, · · ·Lt−19}.
位置分支获取最多20帧的位置可能性历史:{Lt, Lt−1,···Lt−19}。
L0 encodes external initial location information (e.g., from WiFi) or a uniform distribution if not available.
L0编码外部初始位置信息(例如,来自WiFi),如果不可用则编码均匀分布。
At the output, a node initialized with a likelihood at frame t′ will have a likelihood estimate at frame t′ + 1.
在输出处,在帧t '处初始化似然值的节点将在帧t ’ + 1处得到似然估计。
Therefore, we infer a likelihood up to 20 times for one frame, where we compute the weighted average as the final likelihood by decreasing the weights from 1.0 down to 0.05 from the first inference result to the last.
因此,我们在一帧中最多推断20次似然,其中我们计算加权平均值作为最终似然,从第一个推断结果到最后一个推断结果,将权重从1.0降低到0.05。
5.2.2 总结
- 1.融合了速度特征,所以可以预测更多的内容
- 2.这里预测是超过需求的位置信息,再将这些信息融合。
5.3. Training scheme
5.3.1原文翻译
We use a cross entropy loss at both branches.
我们在两个分支都使用交叉熵损失。
The ground-truth likelihood is a zero-intensity image, except for one pixel at the ground-truth location whose value is 1.0.
真值是使用一个像素图片表示的,真值的位置是1,不是真值的位置是0
We employ parallel scheduled sampling [17] to train the auto-regressive location branch without unrolling recurrent inferences.
我们使用并行调度抽样[17]来训练自回归位置分支,而不展开循环推理。
The process has two steps. First, we pass GT likelihoods to all the input tokens and make predictions.
这个过程有两个步骤。首先,我们将GT可能性传递给所有的输入令牌并进行预测。
Second, we keep the GT likelihoods in the input tokens with probability rteacher (known as a teacher-forcing ratio), while replacing the remaining nodes with the predicted likelihoods.
其次,我们将GT似然保留在概率为rteacher(称为教师-强迫比)的输入令牌中,同时用预测似然替换其余节点。
The back-propagation is conducted only in the second step.
反向传播只在第二步中进行。
rteacher is set to 1.0 in the first 50 epochs, and reduced by 0.01 after every 5 epochs.
Rteacher在前50个周期被设置为1.0,每5个周期后降低0.01。
5.3.2总结
讲训练方法,没有看懂
5.4. Synthetic data generation 人工数据合成
5.4.1 逐句翻译
The Transformer architecture requires a large amount of training data.
Transformer体系结构需要大量的训练数据。
We crop data over different time windows to augment training samples.
我们裁剪不同时间窗口的数据来增加训练样本。
However, in the absence of sufficient training data, we use the following three steps to generate more training samples synthetically:
但在缺乏足够训练数据的情况下,我们采用以下三个步骤综合生成更多的训练样本:
-
Compute a likelihood map of training trajectories (i.e., where they pass through);
1)计算训练轨迹的似然图(即训练轨迹经过的位置); -
Randomly pick a pair of locations from high likelihood areas;
2)从高可能性区域中随机选择一对位置; -
Solve an optimization problem to produce a trajectory that is smooth and pass through the area of high likelihood. Given a synthesized trajectory, we sample velocity vectors based on the distance of travel as in our preprocessing step, which are directly passed to the TCN-based velocity compressor during training.
3)求解优化问题,生成光滑且通过高可能性区域的弹道。给定一个合成轨迹,我们在预处理步骤中基于旅行距离采样速度向量,在训练过程中直接传递给基于tcn的速度压缩器。
All the steps are standard heuristics and we refer the details to the supplementary
所有的步骤都是标准的启发式,我们参考补充的细节
5.4.2 总结
- 1.因为新冠的大流行,采集数据变得困难
- 2.所以要想办法生成更多的真值,大约就是按照模型预测的结果进行回传,判断标准是通过性好的轨迹进行回传。















 633
633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











