






研究的动机
- LLM的效果很好,但是他有时候不能完全理解人们的意图;
- 因此本文探索一种方式来促进模型理解人们的意图;
研究思路
- 大模型取得了很好的效果,但是如何削减人类的描述和大模型的理解偏差(gap)成为一个新的研究重点;
- 虽然前人的研究主要集中在重新训练模型完成这个任务,但是重新训练模型存在效率和开源模型少以及可解释性不足的问题;
- 因此本文作者提出了BPO( Black-box Prompt Optimization)一种黑盒的prompt优化,作者主要区分了自己的方案的APE(automatic-prompt-engineers),他这里提出的方案在于可以自动完成优化,是一个an automatic prompt optimizer
- 并且超过了现有的一些方法和基线。
这里对为什么和训练LLM模型本文做对比以及为什么和APE不一样其实是一个隐藏问题
提出的方法
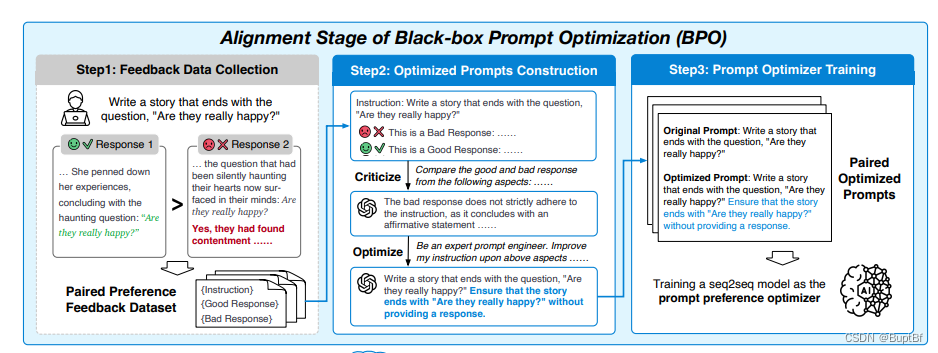
其实这个方法主要是分为几个步骤:
- 1.人工的标记数据
- 2.使用模型批评比较两个回答的差异,然后让模型依据这个差异修改prompt
- 3.形成原始prompt和优化后的prompt对,训练一个seq2seq的模型
这里就可以明显的看出来作者为什么要和微调模型的基线做对比了,他也是训练了一个seq2seq的模型来增强prompt,也训练了,所以要和训练的基线作对比,以及确实和APE不一样。
最后取得的效果
展示了(demonstrated):
- 1.BPO可以提升大模型表现,并提升效果超过RLHF、PPO、DPO *
- 2.BPO可以通过优化回答也能取得效果
















 954
954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











