







1.解决什么问题
之前分辨率提升都是使用生成对抗网络,训练过这个东西的朋友应该都清楚这个东西训练成功是一件非常偶然的事情,所以自然这就是分辨率提升的痛点,所以就有了这篇作者用diffusion模型替代生成对抗网络的文章。
2.怎么做
谈到diffusion怎么生成,其实主要还是两个方面:
- 1.怎么控制
- 2.从什么出发
2.1怎么控制?
-
1)想要提升分辨率,其实就是完全再画一张新的图片,所以这个高分辨率的图片也要从噪声当中来。
-
2)但是既然有低分辨率的图片就不能真的从一个噪声当中来,需要加入低分辨率图片的信息,因为低分辨率和高分辨率的相关性很好,所以不用特殊的做特征提取直接加入到逐层的噪声识别当中即可。(相当于没有特征提取网络直接把低分辨率图片当成控制信息输入)
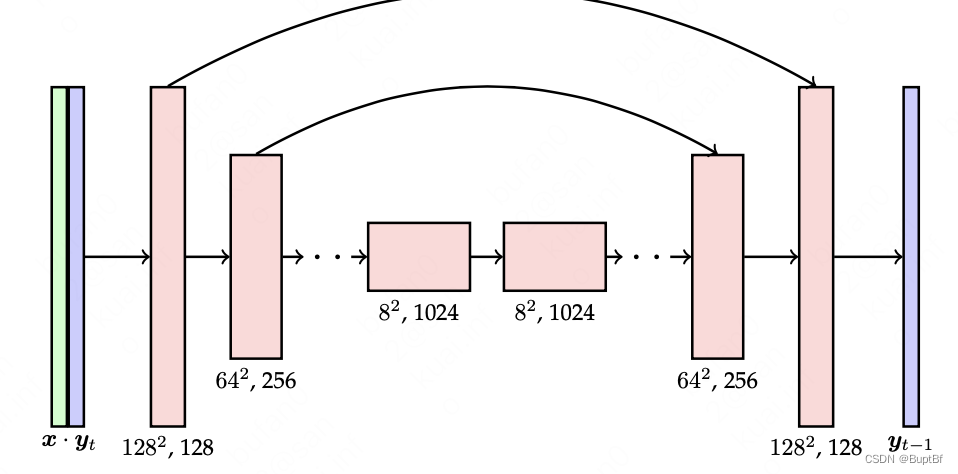
2.2 从什么出发?
作者自己陈述理论上生成应该是从低分辨率出发并最终得到高分辨率的生成,也就是从噪声出发在用低分辨率的图片控制下生成高分辨率图片。感觉直接从一个迁移到另外一个不是diffusion擅长的,如果好做的话作者自己就做了,不会专门加这么一段话。
3.启示
控制信息并不是提取才是最好的,有时候也能直接输入其中,不是固定的模式也要结合当时的情况















 8915
8915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











