








一、论文信息
论文题目:EfficientViM: Efficient Vision Mamba with Hidden State Mixer based State Space Duality
中文题目:高效ViM:基于隐藏状态混合器的状态空间对偶性的高效视觉Mamba
论文链接:https://arxiv.org/pdf/2411.15241
官方github:https://arxiv.org/pdf/2411.15241
所属机构:韩国大学——计算机科学与工程系
核心速览:本文介绍了一种名为EfficientViM的新型视觉架构,该架构基于隐藏状态混合器(Hidden State Mixer)和状态空间对偶性(State Space Duality, SSD),旨在资源受限环境下高效捕获全局依赖性,同时降低计算成本。
二、论文概要
Highlight
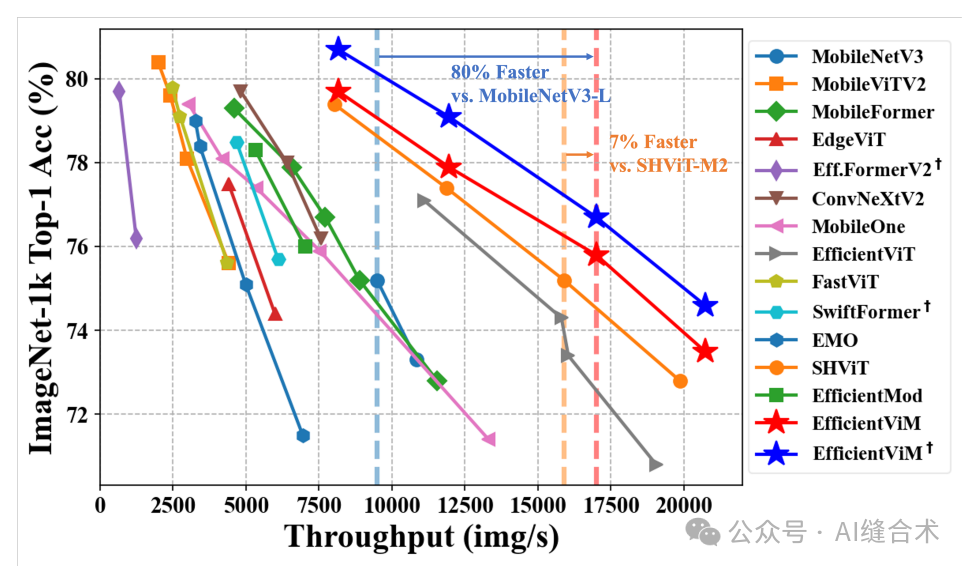
图1. ImageNet-1K 分类上高效网络的比较。我们的EfficientViM系列,标为红色和蓝色星号,展示了最佳的速度-准确率权衡。 ✝ 表示进行蒸馏训练的模型。
1. 研究背景:
-
研究问题:在资源受限的环境中部署神经网络,如移动和边缘设备,需要构建轻量级的视觉架构。这些架构需要在捕获局部和全局依赖性的同时,保持高效的计算性能。
-
研究难点:尽管之前的研究通过构建轻量级卷积神经网络(CNN)和使用深度可分离卷积(DWConv)等技术,成功地减少了模型的计算复杂度,但Vision Transformers(ViTs)的自注意力机制的高计算复杂度仍然是设计高效架构的主要瓶颈。此外,尽管状态空间模型(SSM)提供了一种具有线性计算复杂度的替代方案,但其在视觉任务中的应用仍然面临速度较慢的问题。
-
文献综述:先前的研究尝试通过近似自注意力或限制token数量来降低计算成本,或者开发结合CNN的混合ViTs。然而,这些方法仍然受到自注意力的二次复杂度和SSM的因果约束的限制。最近,一些工作如VSSD和LinFusion进一步改进了SSM,引入了非因果状态空间对偶性(NC-SSD),但这些视觉Mambas的处理速度仍然较慢。本文提出的EfficientViM旨在解决这些挑战,提供一种新的轻量级视觉骨干网络,以实现更快的速度和更高的准确性。
2. 本文贡献:
-
HSM-SSD层设计:EfficientViM的核心是基于隐藏状态混合器的SSD层(HSM-SSD),该层通过在隐藏状态空间内进行通道混合操作,有效降低了计算成本。HSM-SSD层将标准SSD层的线性投影和门控函数从图像特征空间转移到隐藏状态空间,这些隐藏状态被视为样本的压缩潜在表示。
-
总体结论:EfficientViM提出了一种新颖的基于Mamba的轻量级视觉架构,通过HSM-SSD层有效捕获全局依赖关系,同时显著降低了计算成本。该架构在保持模型泛化能力的同时,通过多阶段隐藏状态融合进一步增强了模型的表示能力。
三、创新方法
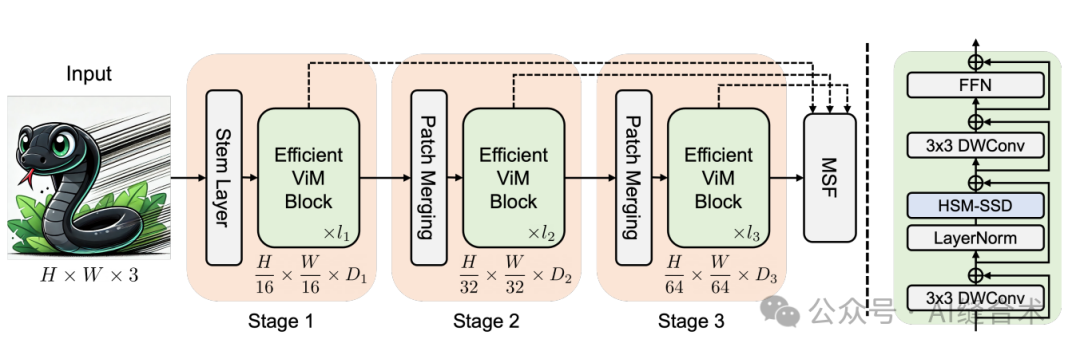
图 4.(左)EfficientViM的整体架构和(右)块设计。虚线表示用于多阶段隐藏状态融合(MSF)的跳过连接。EfficientViM块中HSM-SSD层的示意图在图2中呈现。
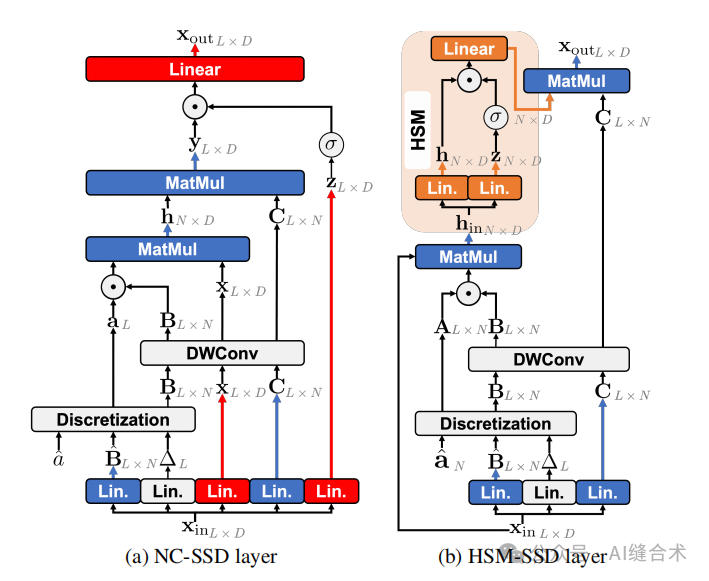
图2. (左) NC-SSD和(右) HSM-SSD层的示意图。在HSM-SSD层中,计算密集型的投影通过HSM中的减少隐藏状态处理,如突出显示所示。红色、蓝色和橙色分别表示需要复杂度为O(LD^2)、O(LND)和O(ND^2)的操作。
Hidden State Mixer (HSM) 是一种用于优化计算效率的机制,它通过减少计算复杂度来提高模型性能。其核心思想是利用一个共享的全局隐藏状态h来执行通道混合,包括门控和输出投影,直接在减少的潜在数组h上进行操作。具体实现原理如下:
1. 线性投影优化:HSM通过首先计算隐藏状态hin,然后将其作为线性投影到隐藏状态,从而将计算复杂度从O(LD^2)降低到O(ND^2),其中N是状态的数量,L是序列长度,D是通道数。这种优化依赖于状态数量N远小于通道数D(即N ≪ D)的情况。
2. 减少隐藏状态的使用:在HSM-SSD层中,通过减少隐藏状态来处理计算密集型的投影,如图2b所示。这使得计算成本主要依赖于状态的数量,而不是通道数。
3. 门控和输出投影的直接应用:HSM直接在隐藏状态上应用门控和投影,而不是先计算Ch再进行门控和投影。这减少了计算复杂度,并且当N较小时,捕捉全局上下文的总复杂度变得可以忽略。
4. 多阶段隐藏状态融合(MSF):为了进一步提升性能,HSM引入了MSF机制,该机制融合了来自网络多个阶段的隐藏状态来生成预测logits。通过这种方式,模型能够整合低层次和高层次的特征,增强模型在推理时的泛化能力。
5. 单头设计:HSM-SSD采用单头设计,通过设置∆ ∈ RL×N和ˆa ∈ RN来估计每个状态的token重要性。这种设计避免了多头配置中的内存绑定操作,提高了吞吐量,并且在保持竞争性能的同时,实现了更高的效率。

四、实验分析
1. 图像分类性能:EfficientViM在ImageNet-1K分类任务中表现出色,与先前的高效网络相比,在速度和准确性方面均有所超越。特别是EfficientViM-M2在保持与MobileViTV2 0.75和FastViT-T8相似性能的同时,实现了约4倍的加速。
2. 扩展性分析:EfficientViM在高分辨率图像上的性能同样优异,与SHViT相比,在5122分辨率下实现了超过15%的速度提升。此外,通过与教师模型RegNetY-160进行蒸馏训练,EfficientViM在速度-准确性权衡上进一步确立了优势。
3. 内存效率:尽管EfficientViM的参数数量相对较多,但其在设备上的内存使用量由推理时的内存I/O决定,而非仅由参数数量决定。EfficientViM在保持最佳吞吐量的同时,显示出与具有较低参数数量的模型相当的内存效率。
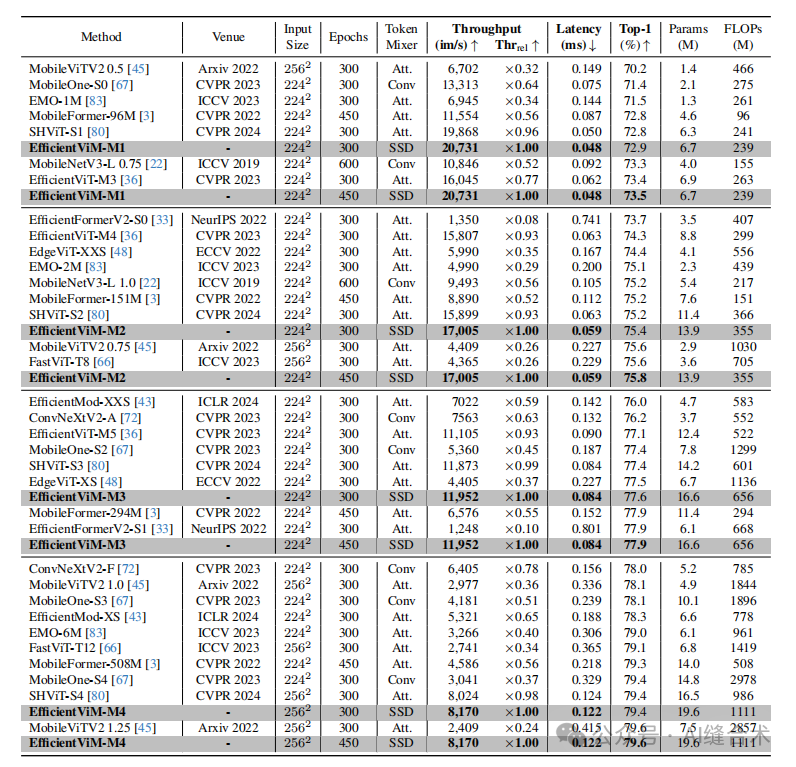
表3. 在ImageNet-1K 分类任务上高效网络的比较。结果按准确率排序。我们还指出了每个方法与EfficientViM相比的相对吞吐量Thrrel。
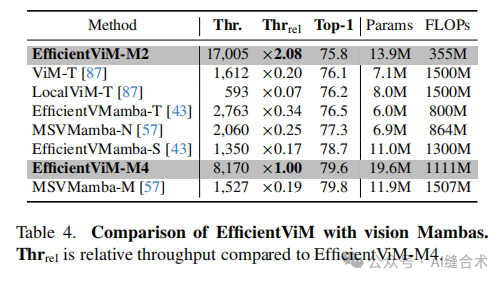
表4. EfficientViM与vision Mambas的比较。Thrrel是与EfficientViM-M4相比的相对吞吐量。
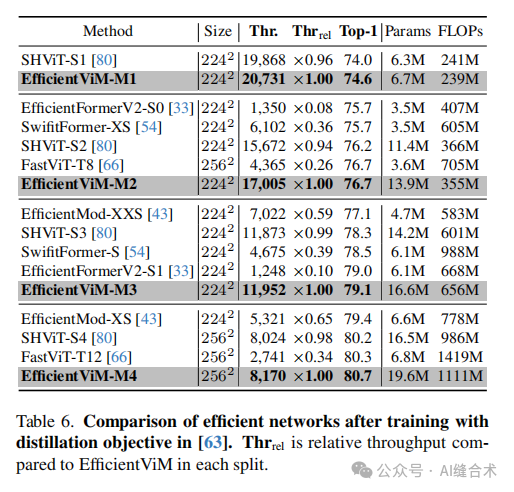
表6. 使用蒸馏目标训练后高效网络的比较。Thrrel是与EfficientViM在每个分割中的相对吞吐量比较。
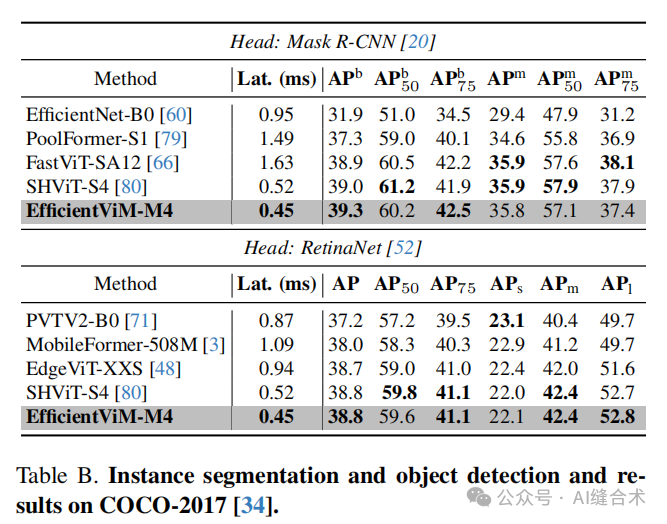
表B. 在COCO-2017上的实例分割、物体检测及结果。
五、代码
运行结果
https://github.com/AIFengheshu/Plug-play-modules
2025年全网最全即插即用模块,全部免费!适用于图像分类、目标检测、实例分割、语义分割、单目标跟踪(SOT)、多目标跟踪(MOT)、RGBT、图像去噪、去雨、去雾、去模糊、超分等计算机视觉(CV)和图像处理任务,持续更新中......
欢迎转发、点赞、收藏~


















 127
127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











