








一、论文信息
论文题目:Demystify Mamba in Vision: A Linear Attention Perspective
中文题目:在视觉中揭开Mamba的神秘面纱:一种线性注意力视角
论文链接:https://arxiv.org/pdf/2405.16605
官方github:https://github.com/LeapLabTHU/MLLA
所属机构:清华大学,阿里巴巴集团
核心速览:本文揭示了Mamba模型与线性注意力Transformer之间的密切关系,并通过理论和实证分析,探讨了Mamba成功的关键因素。研究发现,Mamba模型在视觉任务中表现出色,主要归功于其遗忘门和块设计。基于这些发现,提出了Mamba Inspired Linear Attention(MILA,代码中命名为MLLA)模型,该模型在图像分类和高分辨率密集预测任务中均超越了现有的视觉Mamba模型。

二、论文概要
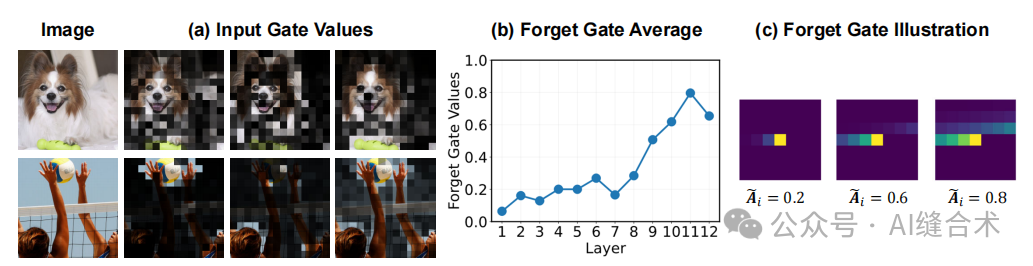
图4:(a)输入门值分布的可视化。(b)不同层中遗忘门值的平均值。(c)不同遗忘门值的衰减效应。
1. 研究背景:
-
研究问题:Mamba模型为何能在处理高分辨率输入的视觉任务中表现出色?它与性能较差的线性注意力Transformer有何相似之处和不同之处?
-
研究难点:理解Mamba模型的成功因素,特别是其与线性注意力Transformer之间的关系,以及如何将这些因素应用到线性注意力Transformer中以提升其性能。
-
文献综述:文章回顾了Transformer和注意力机制在视觉任务中的应用,指出了Softmax注意力的二次复杂度在处理高分辨率图像时的局限性。同时,介绍了线性注意力作为一种具有线性复杂度的替代方案,以及Mamba模型在有效序列建模方面的潜力。此外,还探讨了其他研究者如何尝试将Mamba应用于视觉任务,并分析了Mamba模型在视觉任务中的应用前景。
2. 本文贡献:
-
Mamba模型与线性注意力Transformer的关系:研究揭示了Mamba模型与线性注意力Transformer之间的密切关系,将Mamba重新表述为线性注意力Transformer的一个变体,并指出了六个主要区别:输入门、遗忘门、快捷连接、无注意力归一化、单头和修改后的块设计。
-
核心操作的解释:通过将选择性状态空间模型(SSM)与线性注意力公式统一表述,发现SSM类似于单头线性注意力,但增加了输入门、遗忘门和快捷连接,同时省略了归一化和多头设计。
-
宏观架构设计分析:现代线性注意力Transformer模型通常采用线性注意力子块和MLP子块的块设计。Mamba通过结合H3和门控注意力等基本设计,修改了块设计,形成了更有效的架构。
-
MILA模型的创新:基于Mamba模型的核心设计,提出了MILA模型,该模型在多个视觉任务中均表现出色,证明了线性注意力Transformer通过集成Mamba模型的关键设计可以超越Mamba模型本身。
三、创新方法
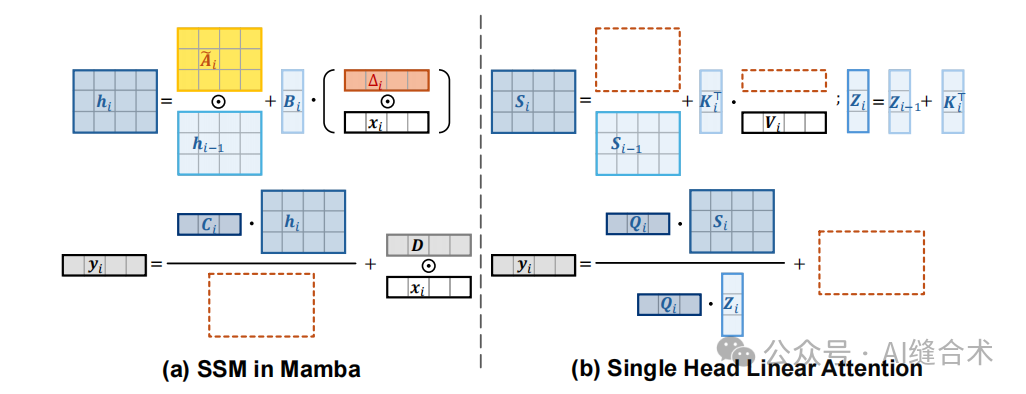
图1:在Mamba中选择性SSM和单头线性注意力的示意图。 可以看出,选择性SSM类似于带有额外输入门∆i、遗忘门Aei和快捷连接D ⊙ xi的单头线性注意力,同时省略了归一化QiZi。
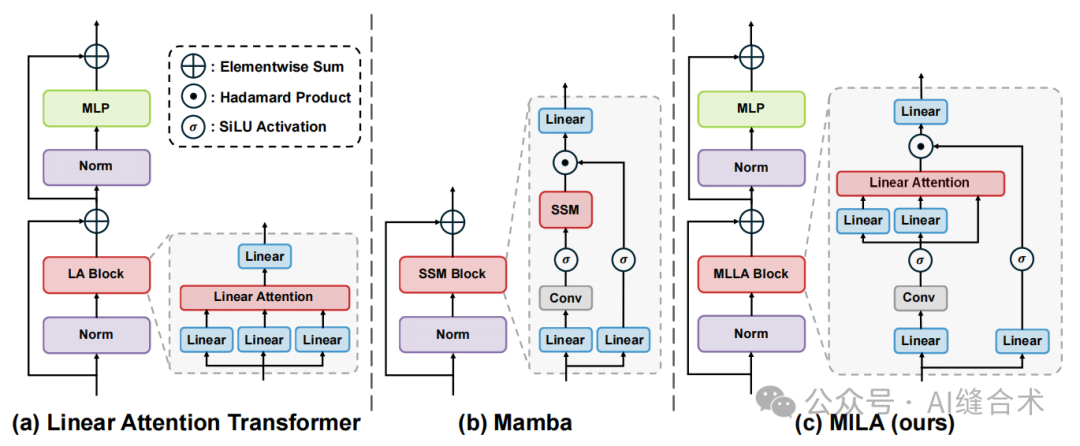
图3:线性注意力Transformer、Mamba和我们的MILA的宏观设计示意图。
1. 现代线性注意力Transformer模型:通常采用图3(a)中描述的块设计,该设计由一个线性注意力子块和一个MLP子块组成。
2. Mamba:相比之下,Mamba通过结合两种基本设计,即H3和门控注意力,修改了块设计,从而形成了图3(b)中所示的架构。Mamba块集成了多种操作,如选择性SSM、逐深度卷积、线性映射、激活函数、门控机制等,往往比传统的Transformer块设计更有效。
3. MILA:
①将Mamba重新表述为线性注意力Transformer的一个变体,并指出了六个差异性(distinctions):输入门、遗忘门、快捷连接、无注意力归一化、单头和修改后的块设计。
②使用广泛使用的Swin Transformer架构作为基线模型,分别向基线模型中引入了六个差异性,以评估每个差异对模型性能的影响。
③基于评估结果,将有用的结构设计整合到线性注意力Transformer中,创建了MILA模型,形成了在图3(c)中展示的MILA块,计算复杂度为:

④MILA模型结合了线性注意力和Mamba设计的优点,旨在在不同的视觉任务中实现更优的性能。
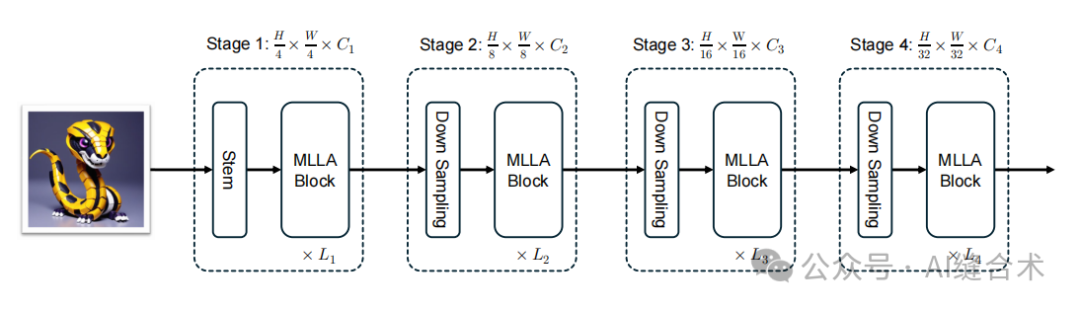
图7:MILA模型的架构。
四、实验分析
1. 实验设置:使用Swin Transformer架构来验证六个区别的影响,通过将Softmax注意力替换为线性注意力创建基线模型,并分别引入每个区别来评估其影响。
2. 实验方法:实验包括图像分类、目标检测和语义分割等任务,通过比较不同模型的参数数量、浮点运算次数(FLOPs)、吞吐量和Top-1准确率来评估模型性能。
3. 实验结果:实验结果表明,遗忘门和块设计是Mamba成功的核心因素,而其他四个区别对模型性能的影响较小。基于这些发现,提出了Mamba-Inspired Linear Attention(MILA)模型。
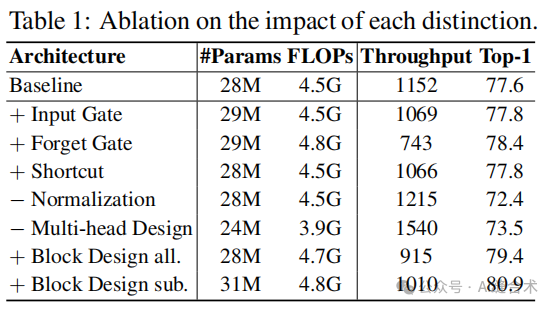
4. MILA模型的性能:MILA模型在多个视觉任务中超越了各种视觉Mamba模型,同时保持了并行计算和快速推理速度。在ImageNet-1K分类任务中,MILA模型在不同模型大小下均取得了更高的准确率。
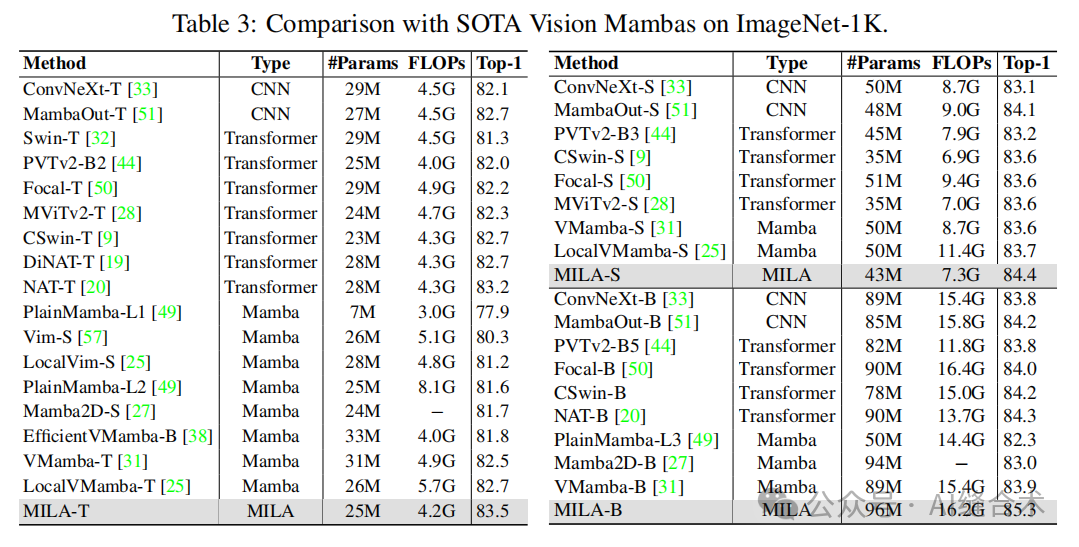
5. MILA模型的效率:MILA模型在推理速度上显著优于视觉Mamba模型,例如在COCO目标检测任务中,MILA模型的推理速度比Mamba2D快4.5倍,同时保持了更高的准确率。
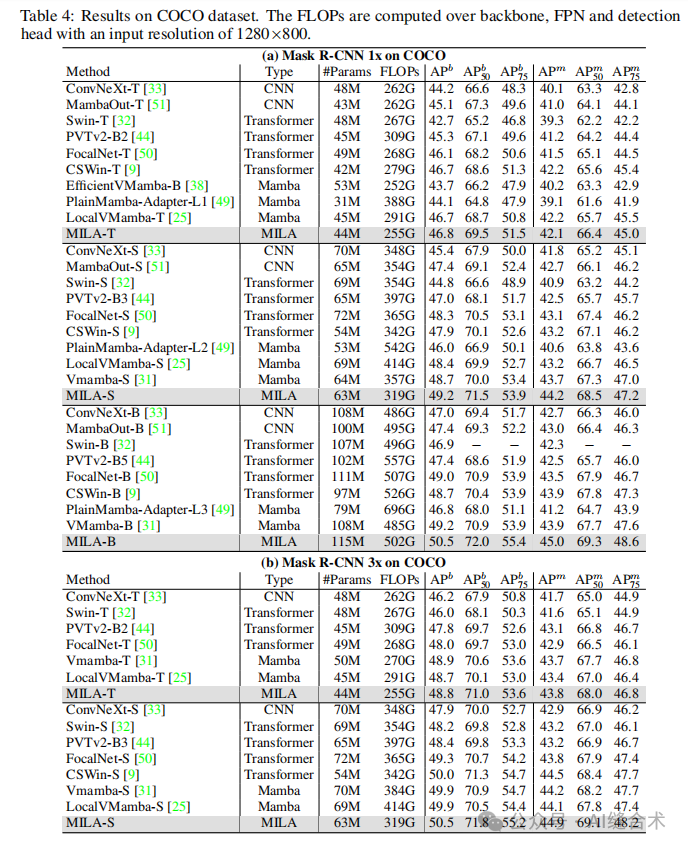
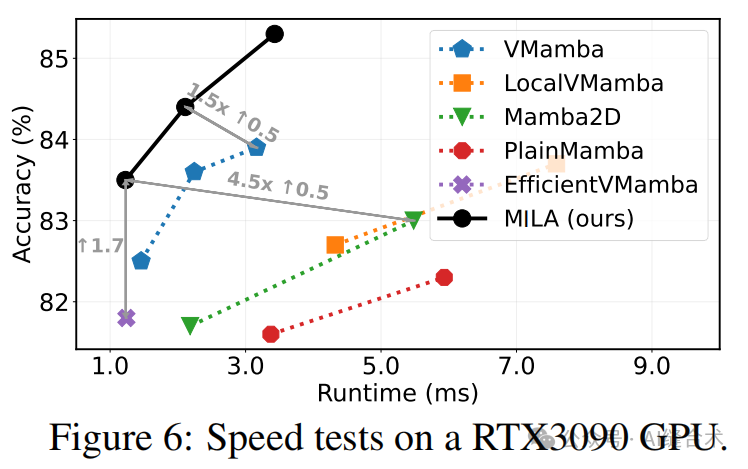
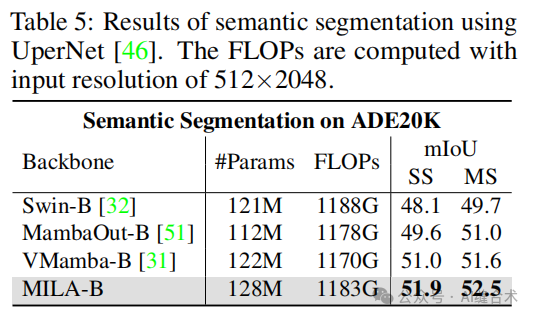
6. MILA模型的适用性:MILA模型在高分辨率密集预测任务中也表现出色,例如在ADE20K语义分割任务中,MILA模型的性能优于其他模型。
五、代码
https://github.com/AIFengheshu/Plug-play-modules
2025年全网最全即插即用模块,全部免费!适用于图像分类、目标检测、实例分割、语义分割、单目标跟踪(SOT)、多目标跟踪(MOT)、RGBT、图像去噪、去雨、去雾、去模糊、超分等计算机视觉(CV)和图像处理任务,持续更新中......
欢迎转发、点赞、收藏~


















 600
600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











