







一、论文简述
1. 第一作者:Jiayu Yang
2. 发表年份:2022
3. 发表期刊:CVPR
4. 关键词:MVS、3D重建、深度分布、稀疏代价体
5. 探索动机:近来,使用cost volume pyramid的基于学习的方法通常在粗级别上构建初始的深度估计来执行局部深度搜索,而他们假设所有像素都服从单峰分布,并且将每个像素的深度估计为在预定范围内近似连续的深度分布期望。这些方法忽视了有剧烈深度变化的小物体和边界区域,在这些区域,单峰分布假设并不成立。如果估计的粗深度远离实际深度,误差将传播到细化层级,并且无法通过局部深度搜索进行校正,从而导致不正确的深度预测。
6. 工作目标:处理边缘区域。
7. 核心思想:通过使用多模态分布在不同分辨率下对每个像素深度进行显式建模,作者使用非参数分布沿着3D视觉线学习每个深度假设的概率。这种方法比其他参数化方法灵活,特别在由粗到细结构中。在最高分辨率下使用其对应深度块内的深度分布来指导学习过程。给定学习分布,并通过前K个概率对深度假设进行分支来构建下一级别的代价体。但是,由于像素深度分支处理,它失去了相对空间关系。所以,作者提出一种稀疏代价聚合网络,以保持相对空间关系。
从粗到细结构存在两个主要问题:在粗水平上的早期决策和部分代价体的空间模糊性。而作者以一个非参数深度分布模型结合一个新型多尺度深度评估框架来解决第一个问题,以一个全新的稀疏代价体公式和一个稀疏代价聚合网络来保持刚性的空间关系解决第二个问题。
- We propose a non-parametric depth probability distribution modeling, allowing us to handle pixels with unimodal and multimodal distributions.
- We build a cost volume pyramid by branching the depth samples based on the modeled pixel-wise depth probability distribution.
- We apply a sparse cost aggregation network to process each cost volume to maintain rigid geometric spatial relation in the cost volume and avoid spatial ambiguity.
8. 实验结果:
Extensive experiments on several benchmark datasets demonstrate that our approach achieves superior performance, especially on boundary regions. On the DTU dataset, our approach outperforms the current state-ofthe-art multi-scale patchmatch based approach PatchmatchNet, yielding up to a 32% lower error on boundary regions.
9.论文下载:
https://github.com/NVlabs/NP-CVP-MVSNet
二、实现过程
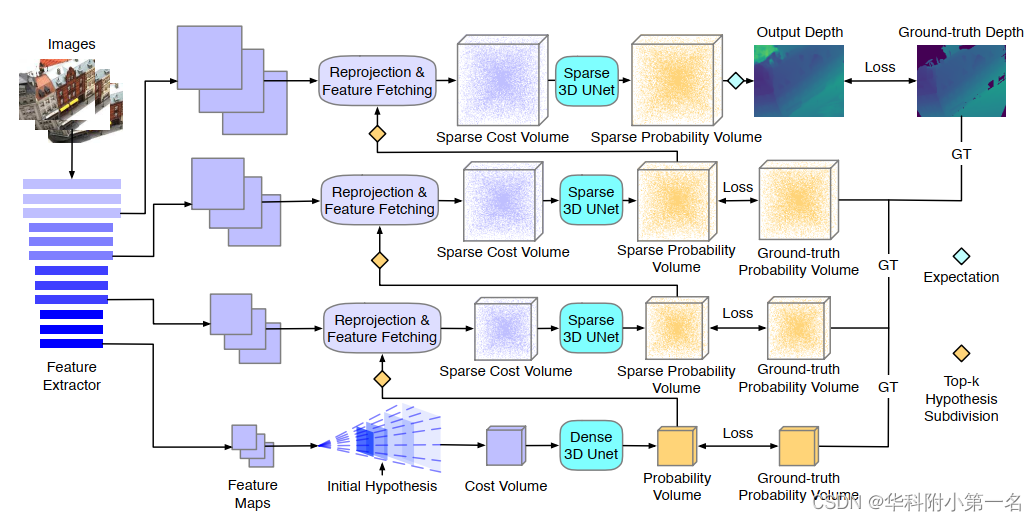
1. NP-CVP-MVSNet概述
首先构建源图像和参考图像的特征金字塔。然后,基于像素级非参数深度概率分布的模型构建代价体金字塔。具体来说,每一层的代价体是基于上一层的top K概率深度采样构建的。代价体是稀疏的,并通过稀疏卷积聚合。深度图D0在全分辨率层级上推断。
2. 非参数深度分布建模
现有方法假设像素p的深度d遵循单峰概率分布Pp(d)。在此假设下,估计的深度d(p)通常定义为该分布的期望,近似为深度假设{dm}M与其沿线的估计概率乘积的积分。
如果离散深度图具有足够高的分辨率,并且能够很好地近似连续深度分布,那么单峰深度分布是一个有效的假设。但是,较低分辨率的像素可能是一组具有不同深度值的3D点的投影,尤其是在一些具有深度不连续物体边界的3D结构上时,如下图所示,这是固有的多模态分布。其中粗像素的深度分布可以用全分辨率深度图上对应块的深度观测值来近似。
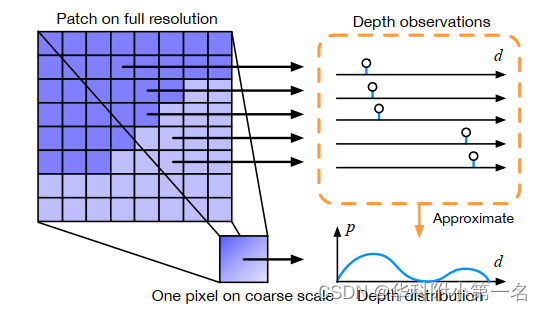
如下图a所示,现有的基于代价体的级联工作使用单峰分布来表示这些像素可能会导致不正确的深度估计。估计的深度,定义为分布的期望,可能与任何深度模态都不同;因此,在接下来的改进步骤中难以恢复。也就是说,算法做出了一个不准确的早期决策,其误差将传播到后续的模块。相反,本文为每个像素引入非参数深度概率模型,以处理具有任意分布的像素。具体来说,给定粗层l的像素p,其深度dp遵循连续的概率分布。用一组离散深度假设(离散采样){dl p,m}来近似这个连续分布Pl(dp)。接下来,介绍基于这种非参数深度概率分布建模的深度推理框架。

单峰和非参数深度搜索。(a)现有方法假设分布为单峰分布,可能导致深度估计不正确。(b)非参数深度模型可以从多模态深度分布中估计出正确的深度。
3. 代价体金字塔
利用特征金字塔来提取特征fl,构造用于深度推断的代价体金字塔{0…L},其中L = L表示最小分辨率下的最粗层级,L=0表示全分辨率对应的最细层级。
3.1. 用于深度初始化的常规代价体
给定一个预先定义的全局深度搜索范围,在逆深度空间上均匀采样深度值。每一个采样深度表示该平行于参考摄像机图像平面的一个平面。使用深度d计算出的单应性变化,将源视图的特征映射到参考视图。并把匹配代价计算为参考特征f0L与被映射源特征fiL的组相关性。然后估计每个深度假设平面的代价图,并将它们连接成一个代价体。并采用视图聚合模型来估计来自不同源视图的可见性映射并融合匹配代价。给定常规代价体,然后使用一个常规3D-UNet去代价聚合。初始的代价聚合网络输出一个概率模型,其定义为每个像素的非参数深度概率分布,代表每个深度样本的可能性。然后,用前K个概率探索像素级深度样本,以构建下一层的代价体。
3.2. 用于深度改进的稀疏代价体
在不丧失一般性的情况下,我们从现在开始忽略像素索引。让{dl Qi}K定义了l级上K个估计概率的深度样本,其中{Qi}K定义了前K个指标和∆dl为对应的深度搜索间隔。为了围绕从level l获得的K个可能的深度样本进行局部搜索,通过将每个选定的level l深度样本细分为两个样本来定义level l−1的深度样本,如下图所示。

每个像素dm的计算公式为:
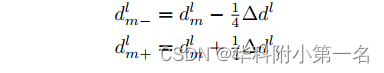
并且深度搜索间隔Δdl−1=0.5Δdl。
由于层级之间的分辨率差异,Sl−1由层级l−1的块内的像素共享,对应于层级l的像素。然后根据新的深度样本构建代价体来建模在层l−1深度概率分布。但因为深度样本是以像素方式形成的,因此不保留相邻3D点之间的相对空间位置。所以使用稀疏cost volume和基于稀疏卷积的聚合信息。
3.3. 稀疏代价聚合网络
因为使用常规的密集3D卷积不能使稀疏代价体有效聚合,所以利用pk的刚性空间关系构建了一个稀疏代价聚合网络,由三个稀疏3D 卷积层、一个稀疏BN层和一个稀疏ReLU激活层组成。网络的输出是一个概率分布,可作为构建下一改进层级的代价体的输入,如图。

稀疏的代价体和稀疏的代价聚合。颜色表示假设的相对深度。(a)现有方法构建了具有空间模糊性的平坦代价体。(b)构建稀疏代价体,利用稀疏代价体来保持刚性空间关系。
4. 全分辨率深度推断
只在全分辨率level 0下推断深度,并将估计分布的期望作为每个像素的深度:
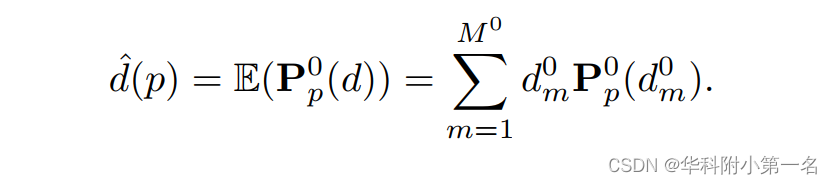
5. 损失函数
我们以监督的方式训练网络。使用高分辨率深度图观测值近似的深度概率分布作为GT。对于每个像素p, 真实值概率分布Pl gt,p是由在全分辨率下对应图像块Φp的深度观测的直方图近似,由观测值的总和归一化得到。
以高分辨率真实值的深度图观察近似为深度概率分布。而地面概率分布近似于对应patch在全分辨率下的深度观测直方图,并由观察之和归一化。
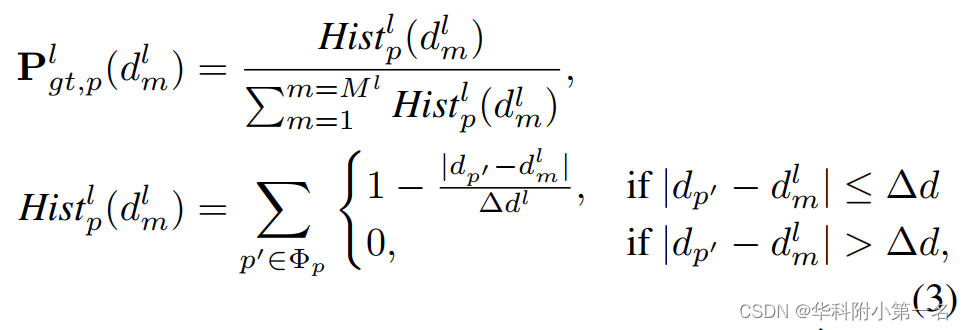
其中dp'是块Φp中像素p'的真实深度值, dlm为深度假设,∆dl为深度假设之间的间隔。对于像素p的每个假设dlm,将损失计算为估计概率和真实概率之间的二进制交叉熵,
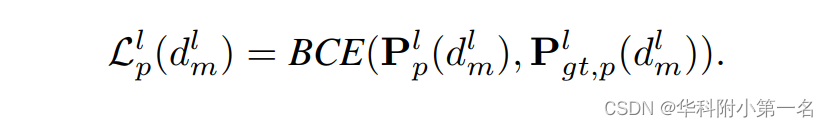
根据经验,真实概率分布通常集中在少数假设上,导致零概率和非零概率样本数量不平衡,所以做了损失平衡。
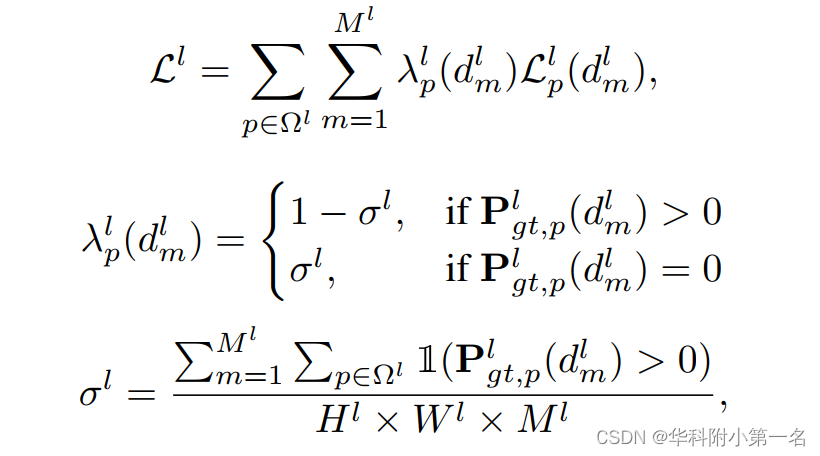
其中Ωl定义了l级的图像坐标域,σl表示假设概率大于0的百分比。在最后一层,通过测量真实深度图和最终估计深度图之间距离的l1范数来监督深度估计。

总损失是粗尺度上的BCE损失和最终层次上的l1损失的加权和,
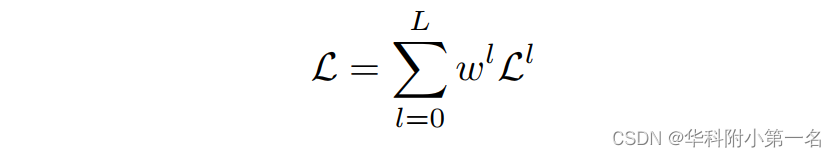
6. 实验
6.1. 实现细节
训练。使用大小为640 × 512的降采样和裁剪图像及其对应的深度图在DTU数据集上训练模型。
度量。精确度度量从估计点云到真实点云的距离,单位是毫米,完整性度量从真实点云到估计点的距离。总分是准确性和完整性的平均值。
评估。设每层假设数为{M l}Ll=0 {8,16,32,96}进行检验。
在效率方面,模型需要6054 MB GPU内存和1.2s来估计全分辨率的深度图,这与现有的基于代价体的方法相当。
6.2. 与先进技术的比较
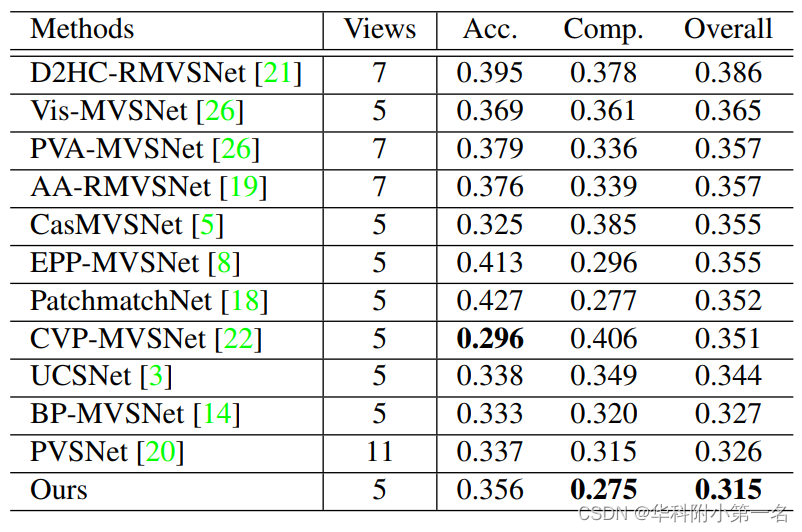
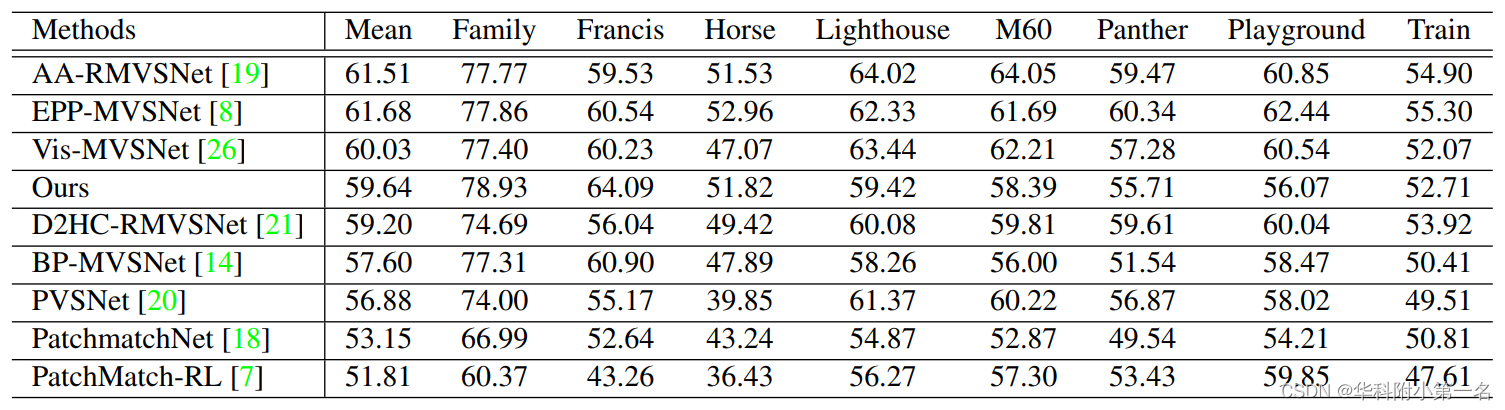
使用标准3D卷积的非参数深度分布建模会由于空间模糊导致性能下降。提出的稀疏代价聚合可以提高基于单模的方法的性能。提出的非参数深度分布建模需要稀疏代价聚合以获得最佳重构质量。
局限
然而,稀疏卷积的计算成本很高,因为它们没有完全优化。这增加了推断时间。
















 4832
4832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











