







系列文章目录
论文名称:Pyramid Real Image Denoising Network(金字塔真实图像去噪网络)
论文地址:https://arxiv.org/abs/1908.00273
代码地址:https://github.com/491506870/PRIDNet
发表时间:2019
应用领域:真实图像盲去噪
核心模块:噪声估计、多尺度去噪、特征融合
注:本文出自:Whn丶nnnnn,此文仅做搬运
文章目录
摘要
虽然CNN已经在特定噪声建模和去噪方面表现出色,它们在real-world noisy images的去噪上仍旧表现很差,主要的原因是real-world noise更为复杂和多样。为了解决盲去噪问题,本文中提出了一种金字塔真实图像去噪网络(PRIDNet),它有三个阶段组成:噪声估计(noise estimation)、多尺度去噪(multi-scale denoising)、特征融合(feature fusion)。在两个real-wolrd noisy datasets上测试的结果表明PRIDNet已经可以在定量分析和视觉感知质量上达到SOTA denoisers的水平。
引言
Image Denoising的目的是从noisy image中恢复clean image,这在低级视觉任务中起着关键作用,目前的研究已可以在分布规律的噪声(AWGN,shot noise)的去噪上取得良好的效果,但是specific noise和real-world noise之间存在很大差异,real-world noise来自拍摄环境和ISP等因素,所以它要更复杂。
近期的深度卷积神经网络(Deep CNN)在对特定噪声去除方面有了重大改进,如REDNet、DnCNN等,但是当这些针对特定噪声的方法泛化到real-world noise时,它们的性能甚至会比传统的方法(如BM3D)表现更差,针对real-world noise的方法很少,比如FFDNet、CBDNet、Path-Restore等。尽管这些方法在real-world noisy image denoising上取得了进步,它们仍旧存在三个需要重视的问题:
- 大多数基于CNN的去噪方法,所有通道的特征(channel-wise features)均被平等对待,而没有根据它们的重要性进行调整。在CNN中,不同特征通道会捕捉到不同类型的噪声,某些噪声要比其它噪声更重要,应当分配更大的权重。
- 之前提到的方法,有着固定的感受野(fixed receptive fields),无法携带多样的信息(diverse information)。传统的BM3D会考虑全局信息(global information),在整个图像中搜索相似的块。由于特征不限于小区域,因此不同大小的感受野可以充分利用hierarchical spatial features。
- 对于多尺度特征的聚合(aggregation of multi-scale features),大多数方法只是简单地以元素求和的方式将它们组合或只是将它们串联(concatenate),虽然包含了所有尺度的信息,但是对不同尺度的特征进行了不加区分的处理,不能自适应地表达多尺度特征。
为了解决以上几个问题,提出了PRIDNet,工作的主要贡献包括以下三方面:
- Channel Attention:在提取的噪声特征上利用通道注意机制(channel attention mechanism),自适应地校正通道重要性(channel importance)
- Multi-scale feature extraction:设计了一种金字塔去噪结构(pyramid denoising structure),其中每个分支都关注一个尺度的特征。利用它,我们可以同时提取全局信息并保留局部细节,从而为后续的全面去噪做好准备。
- Feature self-adaptive fusion:在级联的多尺度特征,每个通道代表一个尺度的特征,我们引入了一个核选择模块(kernel selecting module)。采用线性组合的方法对不同卷积核大小的多分支进行融合,使得不同尺度的特征图可以通过不同的核来表达。
提示:以下是本篇文章正文内容,下面案例可供参考
网络架构
整体架构
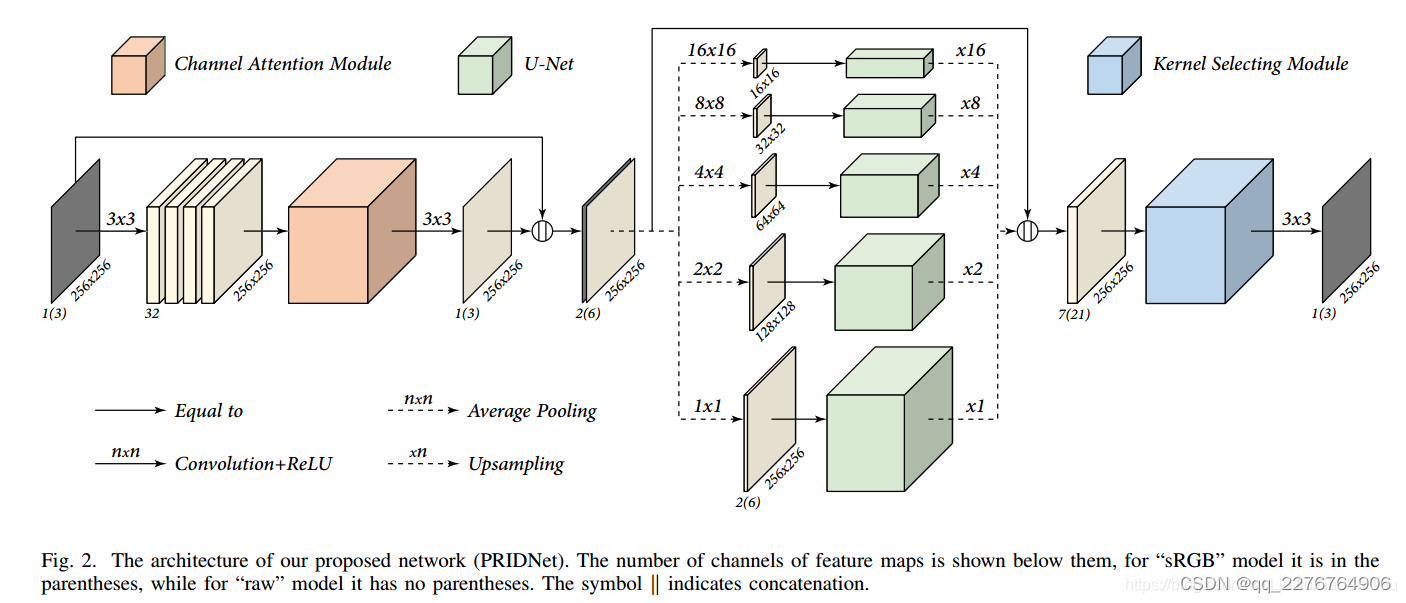
如图2所示,我们的模型包括三个阶段:噪声估计阶段,多尺度降噪阶段和特征融合阶段。 输入的噪点图像按三个阶段依次处理。 由于所有操作在空间上都是不变的,因此它足够健壮,可以处理任意大小的输入图像。为了避免信息丢失,在馈入下一级之前,将第一级的输出与其输入连接起来,然后进入第二级。
噪声估计阶段
这个阶段关注从噪声图像中提取特征,使用了简单的五层全卷积自网络(fully convolutional subnetwork),不进行pooling和batch normalization(这部分和CBDNet的
C
N
N
E
{CNN}_E
CNNE类似),每一个Conv层后进行ReLU激活。在每个卷积层,特征通道被设置为32(最后一层设置为1或3),filter size3*3。在最后一层之前,插入一个channel attention module来校准通道之间的相互依赖性(interdependencies)。
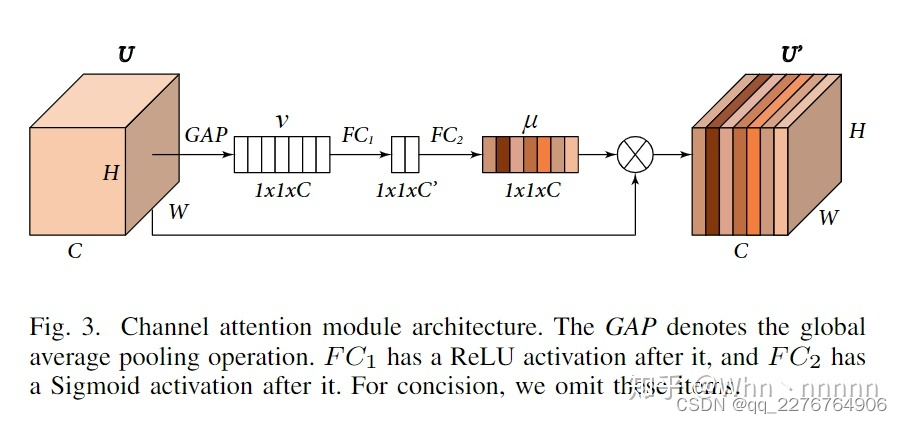
channel attention module 如下图所示,我们的目标是收集通道权重
μ
=
[
μ
1
,
μ
2
,
…
μ
c
]
∈
R
1
×
1
×
C
\mu=[\mu_1,\mu_2,\ldots\mu_c]\in R^{1\times1\times C}
μ=[μ1,μ2,…μc]∈R1×1×C,它用于重新缩放输入特征图
U
∈
R
H
×
W
×
C
U\in R^{H\times W\times C}
U∈RH×W×C,来生成重新校准的特征。
1.首先使用全局平均池化(global average pooling,GAP)将U的全局信息(global information)压缩到 通道描述符(channel descriptor)
v
∈
R
1
×
1
×
C
v\in R^{1\times1\times C}
v∈R1×1×C中。
2.紧接着是两个全连接层(fully connected layers,FC),中间层的通道数设置为2。
整个过程可以表示为
μ
=
S
i
g
m
o
d
(
F
C
2
(
R
e
L
U
(
F
C
1
(
G
A
P
(
U
)
)
)
)
)
)
)
\mu=Sigmod(FC_2(ReLU(FC_1(GAP(U)))))))
μ=Sigmod(FC2(ReLU(FC1(GAP(U))))))),channel attention module最后的输出(记为
U
′
∈
R
H
×
W
×
C
U^{\prime}\in R^{H\times W\times C}
U′∈RH×W×C)可以通过
U
′
=
U
∘
μ
U^{\prime}=U\circ\mu
U′=U∘μ获得,其中∘表示
U
i
∈
R
H
×
W
U_{i}\in R^{H\times W}
Ui∈RH×W标量校准权重(scalar calibration weight)
μ
i
,
i
=
1
,
2
,
…
,
C
\begin{matrix}\mu_{i},i=1,2,\ldots,C\end{matrix}
μi,i=1,2,…,C 之间的逐通道乘(channel-wise multiplication)。
Multi-scale Denoising Stage
Pyramid pooling 已经在多个领域广泛应用,例如场景解析(Scene parsing)、图片压缩(image compression)等,但是目前没有应用在image denoising中。研究表明CNN的感受野要比理论上小得多,尤其是在较高层,这意味着提取特征是难以完全提取到global information。
为了解决这个问题,提出了一个5层的金字塔结构(five-level pyramid).经过5个并行的通路,将输入的特征图下采样(downsampling)为不同的大小来帮助分支获取不同比例的感受野(receptive fields)来同时捕获original,local和global information。Pooling Kernels被设置为11、22、44、88、16*16,每个池化后的特征输入到U-Net中(U-Net由deep encoding-decoding和skip connections组成)。
注:5层U-Nets之间不共享权重,在这一阶段的最后,用双线性插值(bilinear interpolation)将多层去噪后的特征进行上采样,然后拼接在一起。
Feature Fusion Stage
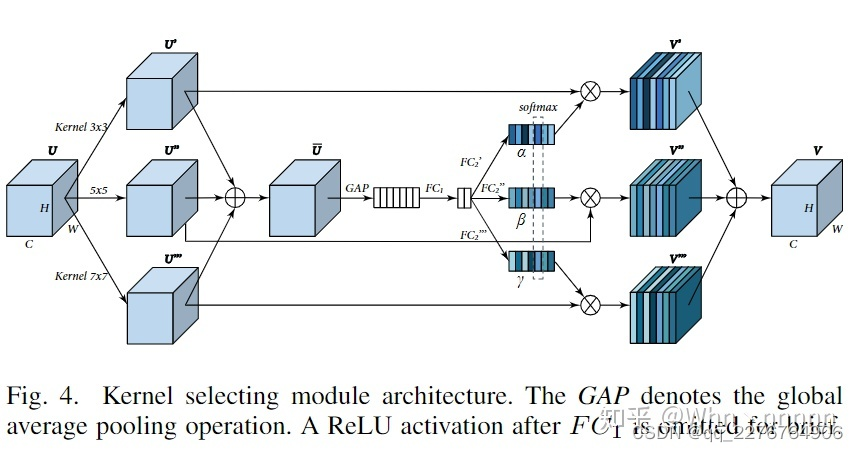
为了在级联多尺度结果(concatenated multi-scale results)中为每个通道选择大小不同的核,引入了一个核选择模块(kernel selecting module)。
核选择模块的细节如下图所示,
1.给定特征图
U
∈
R
H
×
W
×
C
U\in R^{H\times W\times C}
U∈RH×W×C由kernel size为3、5、7的3个并行卷积进行运算,得到
U
′
∈
R
H
×
W
×
C
U'\in R^{H\times W\times C}
U′∈RH×W×C、
U
′
′
∈
R
H
×
W
×
C
U''\in R^{H\times W\times C}
U′′∈RH×W×C、
U
′
′
′
∈
R
H
×
W
×
C
U^{\prime\prime\prime}\in R^{H\times W\times C}
U′′′∈RH×W×C,
2.通过逐元素(element-wise)求和来整合所有分支的信息:
U
‾
=
U
′
+
U
′
′
+
U
′
′
′
\overline{U}=U'+U''+U'''
U=U′+U′′+U′′′。
3.然后缩小
U
‾
\overline{U}
U并通过GAP和2个FC层进行扩展,这个channel attention module操作类似,不过最后没有Sigmoid层。
4.
F
C
2
F C_{2}
FC2层的3个输出
α
′
∈
R
1
×
1
×
C
,
β
′
∈
R
1
×
1
×
C
,
γ
′
∈
R
1
×
1
×
C
\alpha'\in R^{1\times1\times C},\beta'\in R^{1\times1\times C},\gamma'\in R^{1\times1\times C}
α′∈R1×1×C,β′∈R1×1×C,γ′∈R1×1×C通过softmax计算,在通道(channel wise)上跨分支应用:
k
c
=
e
k
c
′
e
α
c
′
+
e
β
c
′
+
e
γ
c
′
,
k
=
α
,
β
,
γ
k_{c}=\frac{e^{k_{c}^{\prime}}}{e^{\alpha_{c}^{\prime}+e^{\beta_{c}^{\prime}}+e^{\gamma_{c}^{\prime}}}},k=\alpha,\beta,\gamma
kc=eαc′+eβc′+eγc′ekc′,k=α,β,γ,分别表示
U
′
,
U
′
′
,
U
′
′
′
U^{\prime},U^{\prime\prime},U^{\prime\prime\prime}
U′,U′′,U′′′的软注意力矢量(soft attention vector),
α
c
\alpha_{c}
αc为
α
\alpha
α的第c个元素,
β
c
\beta_{c}
βc,
γ
c
\gamma_{c}
γc也是类似的。
5、通过将各个核和它们的注意权重(attention weight)组合起来计算最终的输出特征图V:
V
c
=
α
c
⋅
U
′
+
β
c
⋅
U
′
′
+
γ
c
⋅
U
′
′
′
V_{c}=\alpha_{c}\cdot U'+\beta_{c}\cdot U''+\gamma_{c}\cdot U'''
Vc=αc⋅U′+βc⋅U′′+γc⋅U′′′,其中
α
c
+
β
c
+
γ
c
=
1
\alpha_{c}+\beta_{c}+\gamma_{c}=1
αc+βc+γc=1,
V
=
[
V
1
,
V
2
,
…
,
V
C
]
,
V
c
∈
R
H
×
W
V=[V_{1},V_{2},\ldots,V_{C}],V_{c}\in R^{H\times W}
V=[V1,V2,…,VC],Vc∈RH×W,最终使用一个1*1Conv层压缩为1或3来进行特征融合(feature fusion)。
Experiments
Datasets
使用SIDD dataset中RAW域和sRGB域的320个图像对(noisy-clean)进行训练,使用SIDD dataset中的40张图片作为验证数据进行消融实验(ablation study)。使用DND、NC12 datasets进行测试。
Implementation Details
使用raw和sRGB噪声图像对进行训练,采用L1 loss,优化器选择器Adam( β 1 = 0.9 , β 2 = 0.999 , ϵ = 1 0 − 8 \beta_1=0.9,\beta_2=0.999,\epsilon=10^{-8} β1=0.9,β2=0.999,ϵ=10−8)…更多细节参照原文
Comparison with State-of-the-arts
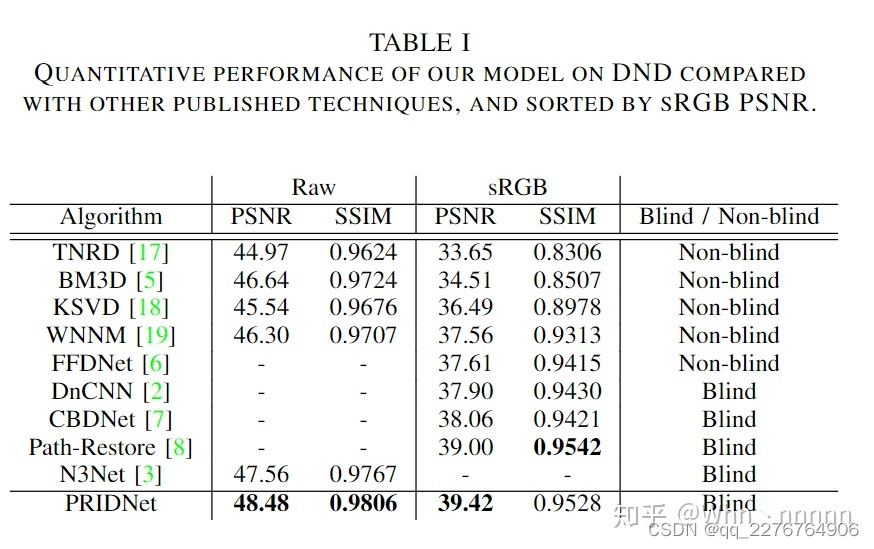
从在DND测试集上去噪结果的PSNR值来看,PRIDNet的确是表现优异的盲去噪算法(blind enoising),效果要由于CBDNet、Path-Restore等新兴算法。
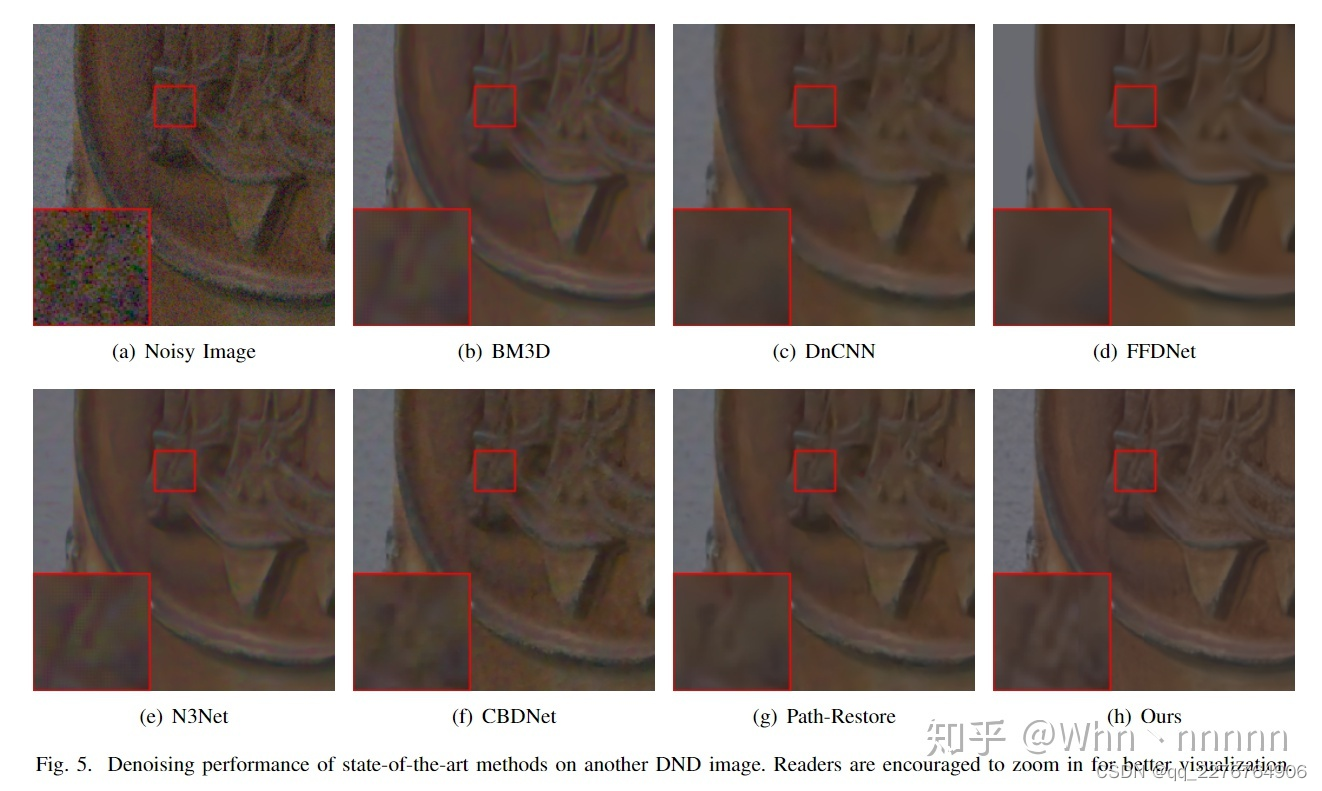
PRIDNet能够在保存正常图片的纹理细节的同时去除大部分噪声,在定量分析(PSNR)和视觉质量(visual quality)上均表现不错。

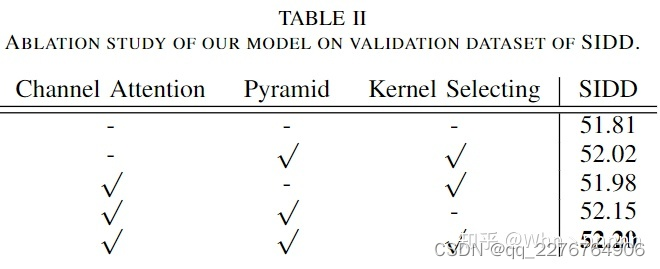
Ablation Studies(消融实验)
消融实验部分详细内容可以参照原文,主要是为了证明作者提出的Channel attention、Pyramid和Kernel Selecting 3个模块对于Denoising性能的提升是有用的
Conclusion
在本文中,作者团队提出了用于real-world noisy images的盲去噪(blind denoising)的PRIDNet。网络结构包括顺序连接的3个部分:Noise Estimation(探讨特征通道的相对重要性)、Multi-scale Denoising(使用金字塔池化进行多尺度特征去噪)、Feature Fusion(自适应核选择特征融合),PRIDNet在定性和定量的实验上均有不错的表现。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。















 1061
1061











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









