







前天看了一篇文章图像分割用diffusion,今天看了篇文章图像合成不用diffusion,你说说这~
传送门:【技术追踪】SDSeg:医学图像的 Stable Diffusion 分割(MICCAI-2024)
UNest:UNet结构的Transformer,一种用于非配对医学图像合成的新框架,涵盖三种模态(MR、CT和PET),在六项医学图像合成任务中将最近的方法改进了19.30%。
论文:Structural Attention: Rethinking Transformer for Unpaired Medical Image Synthesis
代码:https://github.com/HieuPhan33/MICCAI2024-UNest (即将开源)
0、摘要
非配对医学图像合成的目的是为准确的临床诊断提供补充信息,并解决获得对齐的多模态医学扫描的挑战。
由于Transformer能够捕获长期依赖关系,他们在图像转换任务中表现非常出色,但只是在监督训练中有效,在非配对图像转换中性能下降,特别是在合成结构细节方面。
本文的经验证明,在缺乏成对数据和强归纳偏差的情况下,Transformer会收敛到非最优解。为了解决这个问题,本文引入了UNet结构Transformer(UNet Structured Transformer,UNest)—— 一种新的架构,它包含了结构归纳偏差,用于非配对的医学图像合成。
本文利用SAM模型来精确地提取前景结构,并在主要解剖结构中实施结构注意。这会指导模型学习关键的解剖区域,从而在缺乏监督的非配对训练中改进结构合成。
在两个公共数据集上进行评估,涵盖三种模态(MR、CT和PET),在六项医学图像合成任务中将最近的方法改进了19.30%。
1、引言
1.1、图像合成的意义
医学影像具有多个模态,不同模态可提供互补的信息,但多次扫描可能是耗时、昂贵的,且有辐射暴露的风险,医学图像合成是一种新思路。(格局打开~)
1.2、现有合成方法局限
(1)大多数合成方法基于有监督的Pix2Pix方法,需要成对数据,不好获取;
(2)CycleGAN是非配对图像转换的开创性工作;
(3)以往的方法采用带有局部归纳偏置的卷积算子,指导模型提取局部特征。这限制了它们捕捉远程空间上下文的能力;
1.3、ViT方法的不足
(1)ViT可建模全局依赖,在分割、超分任务上表现优异;然而,ViT模型在应用于未配对的医学图像合成时很困难;
(2)由于没有归纳偏置,ViT的样本效率较低,在低数据条件下无法注意到鉴别特征;
(a)目前的ViT方法无法在鼻腔内合成复杂的解剖结构;
(b)Transformer方法倾向于关注不太相关的背景特征;
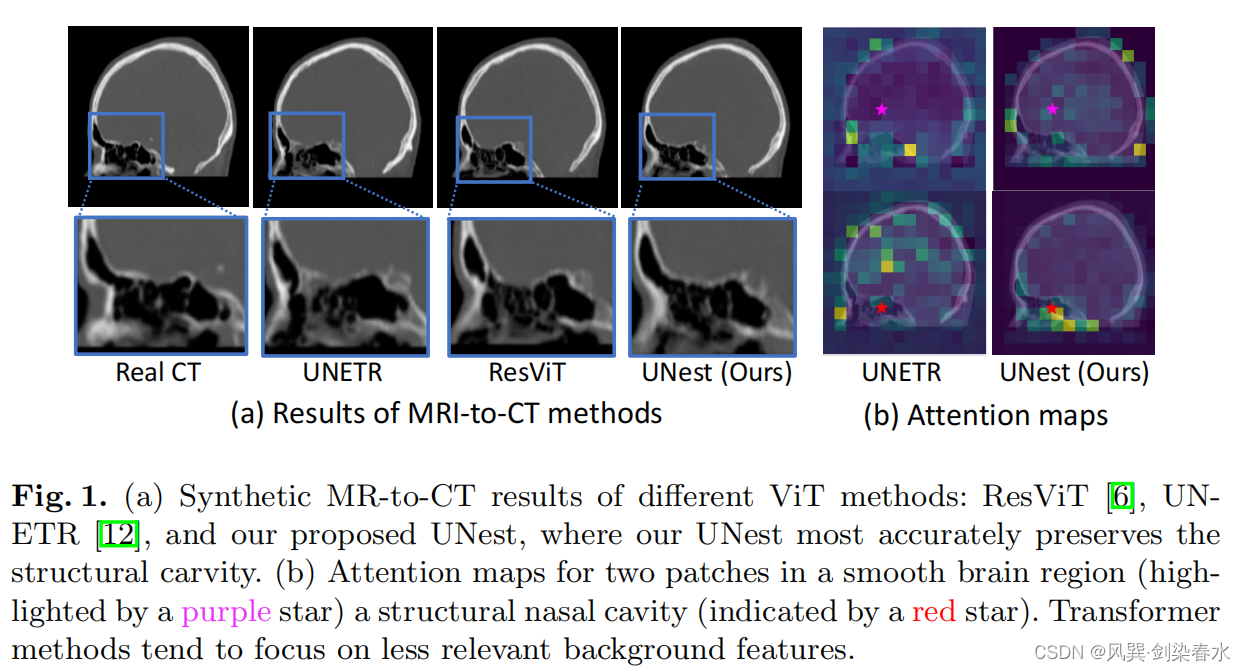
1.4、本文贡献
(1)本文发现,加入结构引导偏差使Transformer能够专注于鉴别区域,从而增强了非配对图像合成中解剖结构的合成;
(2)提出UNest框架,应用了双重注意策略:前景的结构注意和背景的局部注意;
(3)对MR、CT和PET三种模态的六种图像转换任务进行评估,UNest显著提高了各种解剖结构的准确性;
2、方法
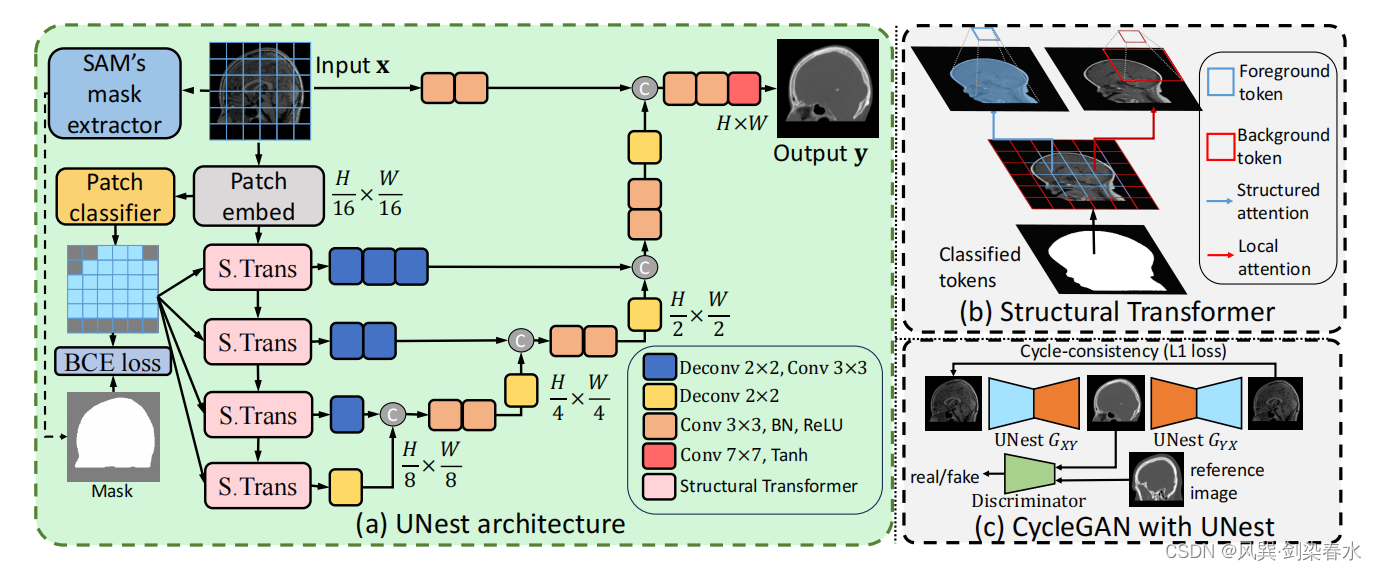
UNest整体框架图:
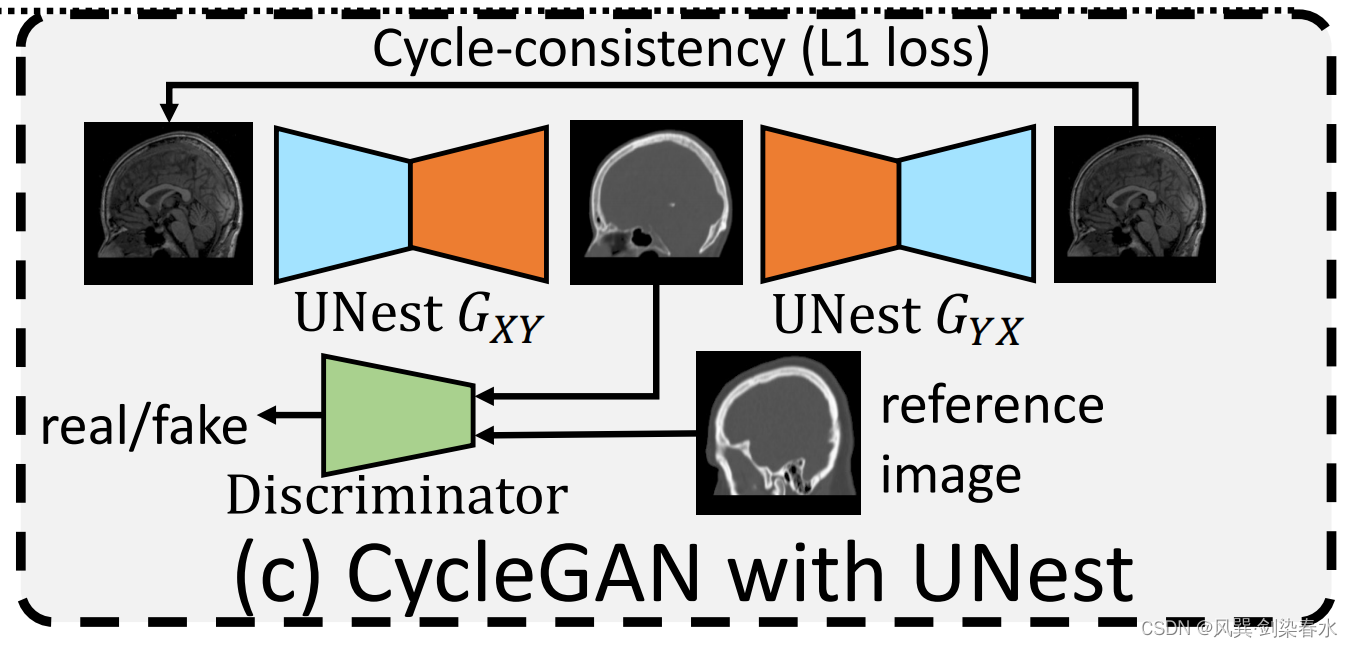
2.1、CycleGAN概述
基于CycleGAN,UNest有两个生成器: G X Y {G_{XY}} GXY 和 G Y X {G_{YX}} GYX,学习 X {X} X 和 Y {Y} Y 两个域之间的前向和向后映射。
G
X
Y
{G_{XY}}
GXY 和
G
Y
X
{G_{YX}}
GYX 被训练来欺骗鉴别器
D
Y
{D_{Y}}
DY 和
D
X
{D_{X}}
DX,训练损失为对抗损失:

针对未配对的训练,CycleGAN施加了循环一致性损失:
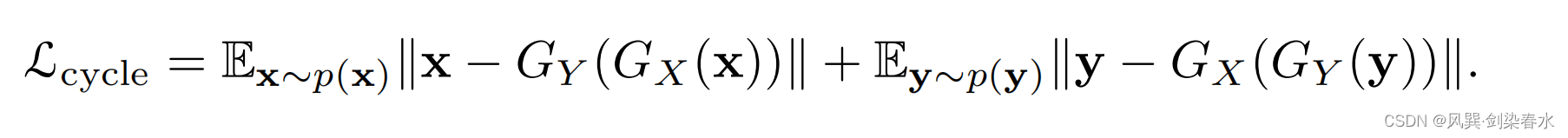
整体上还是CycleGAN模式:
2.2、非配对图像合成中的Transformer模型分析
常规的 self-attention 是在整个图中做的:
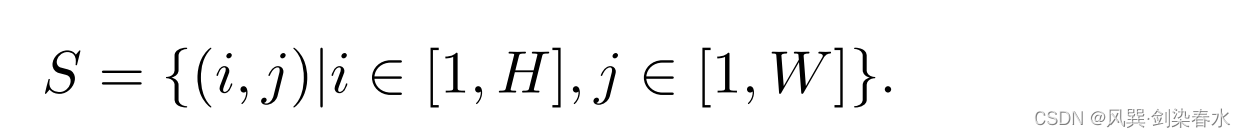
本文考虑CNN的局部归纳偏差,从查询(Q) tokens 周围的
m
×
m
{m×m}
m×m 窗口中聚合 tokens:
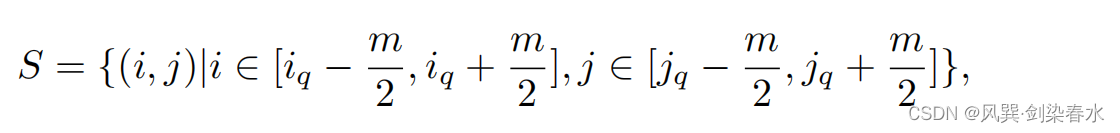
ResViT和UNETR采用的全局注意使髋关节结构变形,而Swin UNETR采用的局部注意产生伪影:
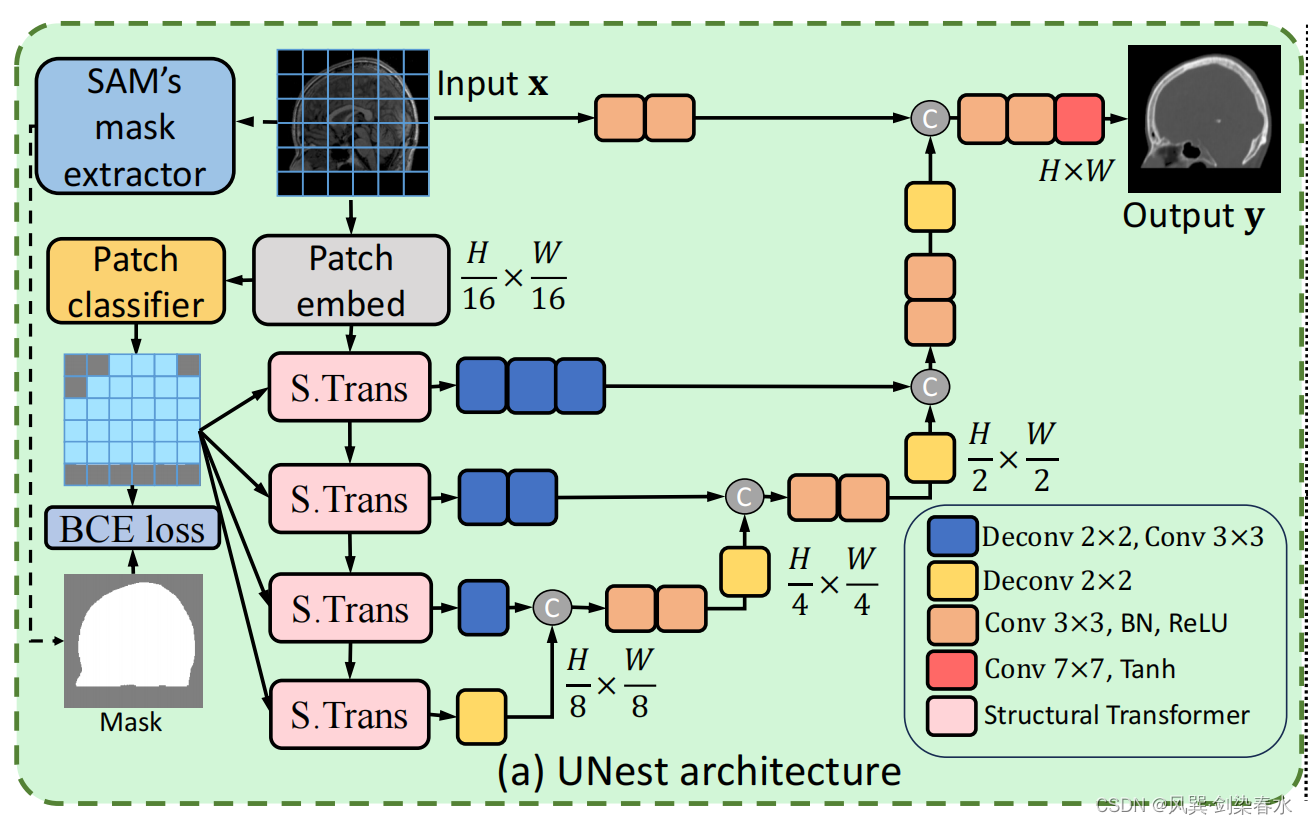
2.3、UNet Structural Transformer
与之前的全局注意或局部注意不同,本文的结构注意聚集在主要解剖结构中,在划分patch之后,采用轻量级分类器实现对patch的分类标注。
怎么训练patch分类器呢,使用SAM提取原图的分割结果,取前景最大部分为mask,计算与真实标签的BCE损失,优化patch分类器:
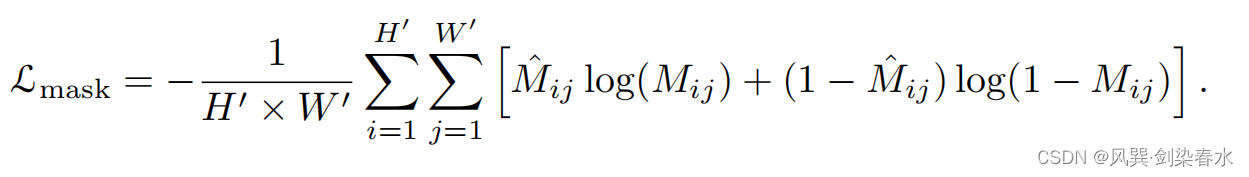
最终损失为三个损失的加权:
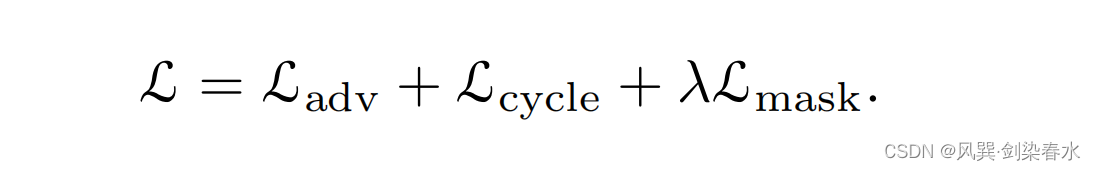
UNest由Structural Transformer(ST)块和一个具有跳跃连接的卷积解码器组成:
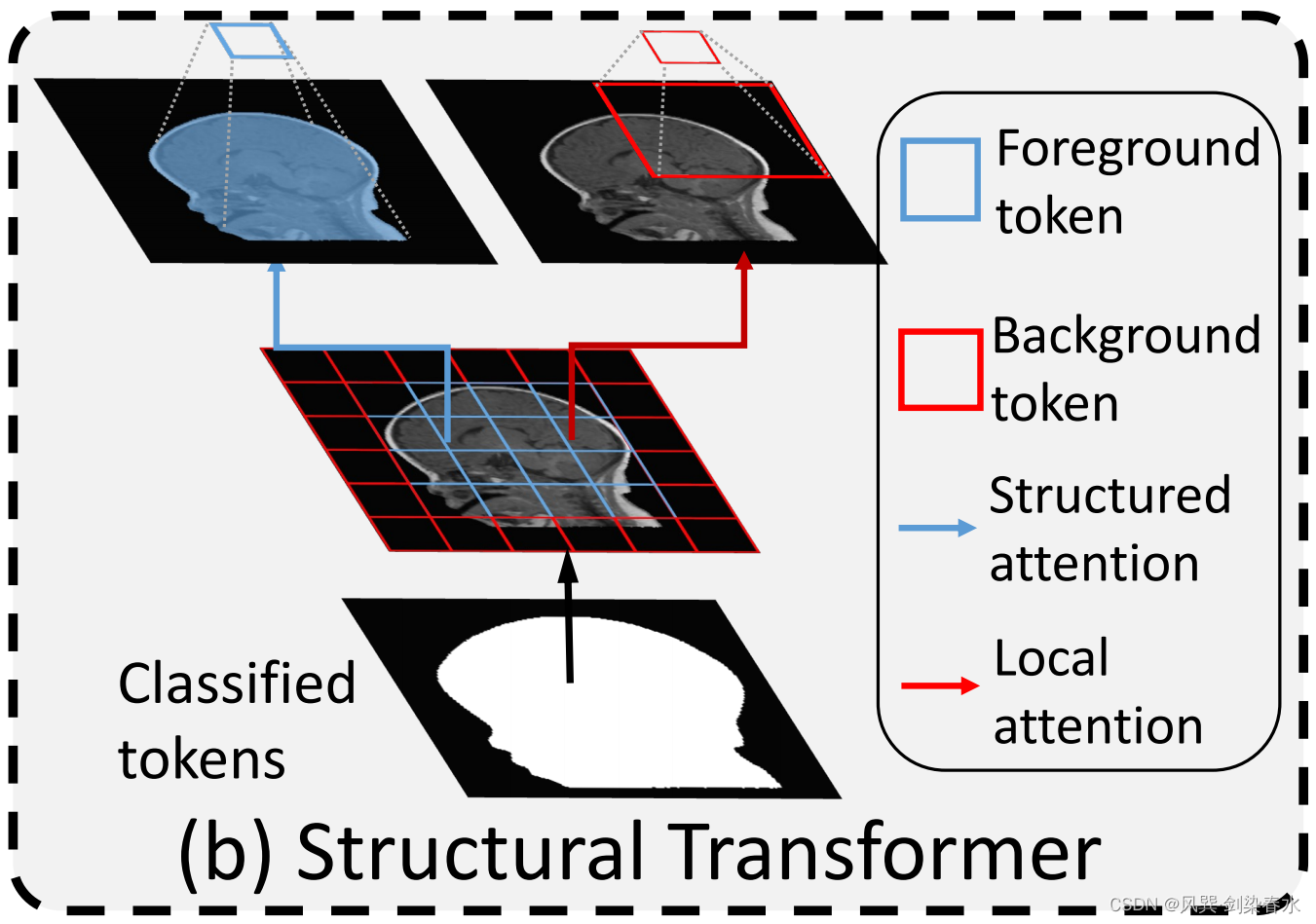
2.4、Structural Transformer模块细节
为了在非配对训练下引导 Transformer,本文采用双重注意策略。对于前景,利用结构注意来学习解剖区域内的关系。对于背景,进行局部关注,实现前景和背景特征之间的有效信息交换。(具体实施还是后面看代码比较直观~)
分别对前景 tokens 和背景 tokens 实施双重注意策略:
3、实验与结果
3.1、数据集与实施细节
(1)MRXFDG数据集:MR-to-CT、MR-to-PET,37例,224×224;
(2)AutoPET数据集:PET-to-CT,310例,256×256;
(3)两数据集划分:8:1:1;
(4)显卡: 2块 NVIDIA RTX 3090 GPUs ;
(5)优化器:Adam;
(6)epoch:100;
(7)学习率:0.0001,在最后50个epoch线性衰减到0;
3.2、评价指标
(1)平均绝对误差(MAE)
(2)峰值信噪比(PSNR)
(3)结构相似性(SSIM)
(4)报告结果运行5次,与其他方法比较采用
t
{t}
t 检验,显著性差异
p
<
0.05
{p<0.05}
p<0.05
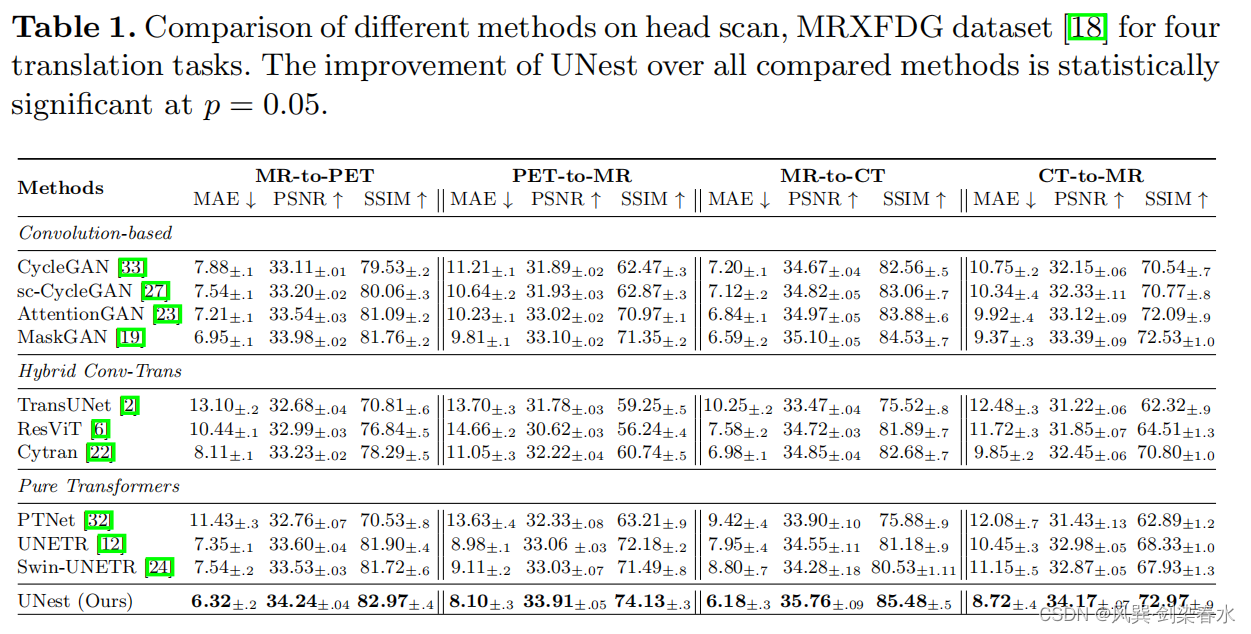
3.3、与先进技术比较
四个转换任务,三种网络类型(卷积类,Transformer类,混合类):
可视化结果:在没有引导偏差的情况下,UNETR倾向于产生更模糊的细节,而Swin-UNETR则扭曲了大脑皮层下结构的细节;
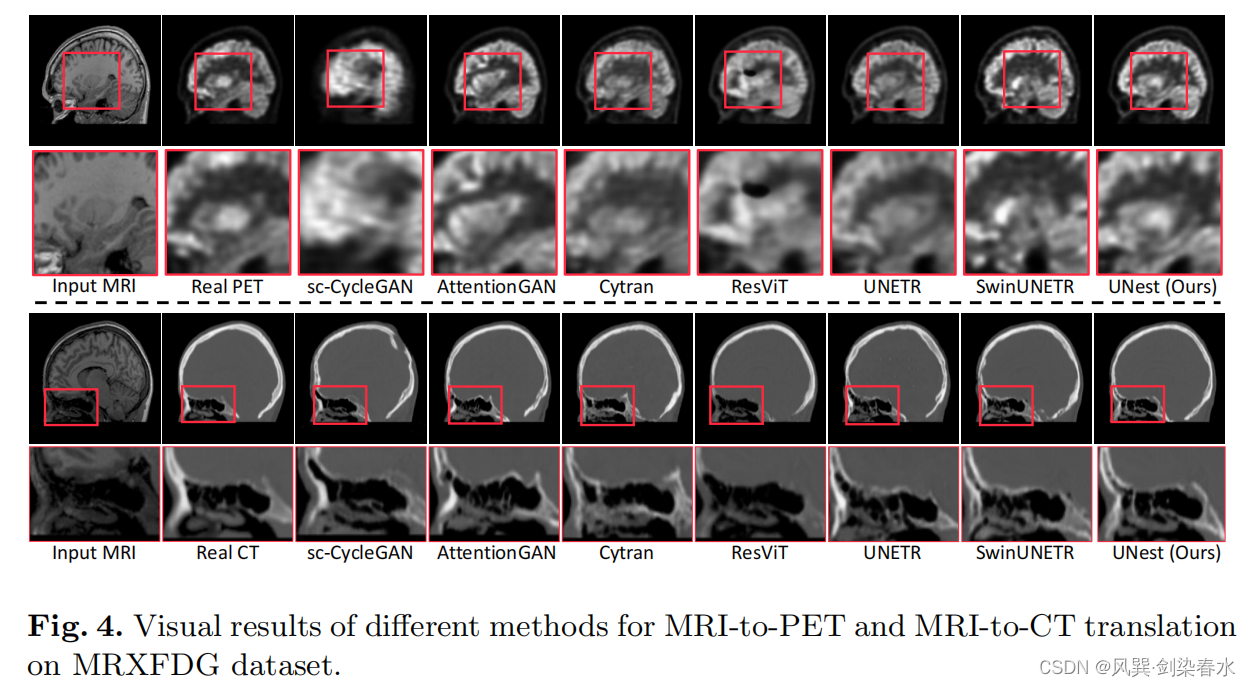
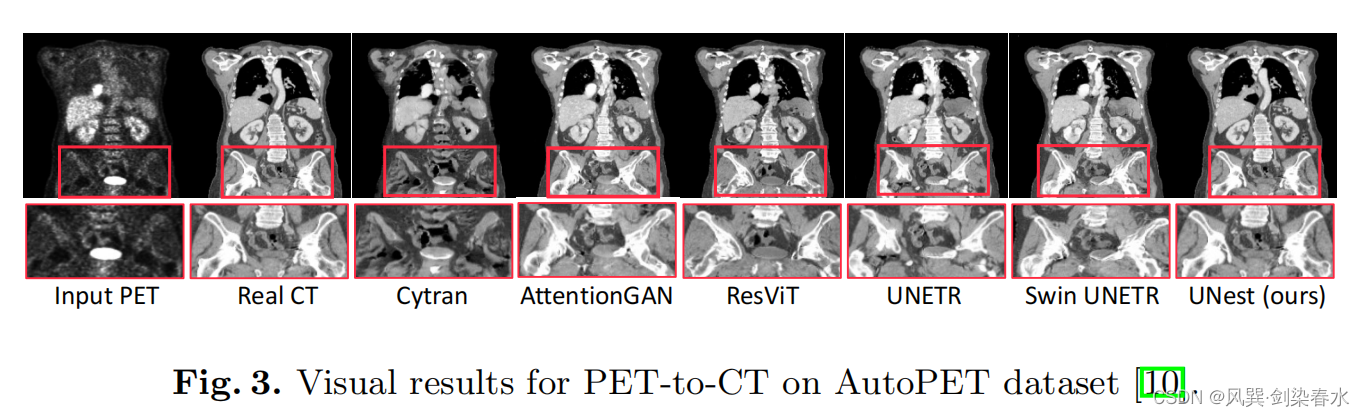
AutoPET数据集结果:
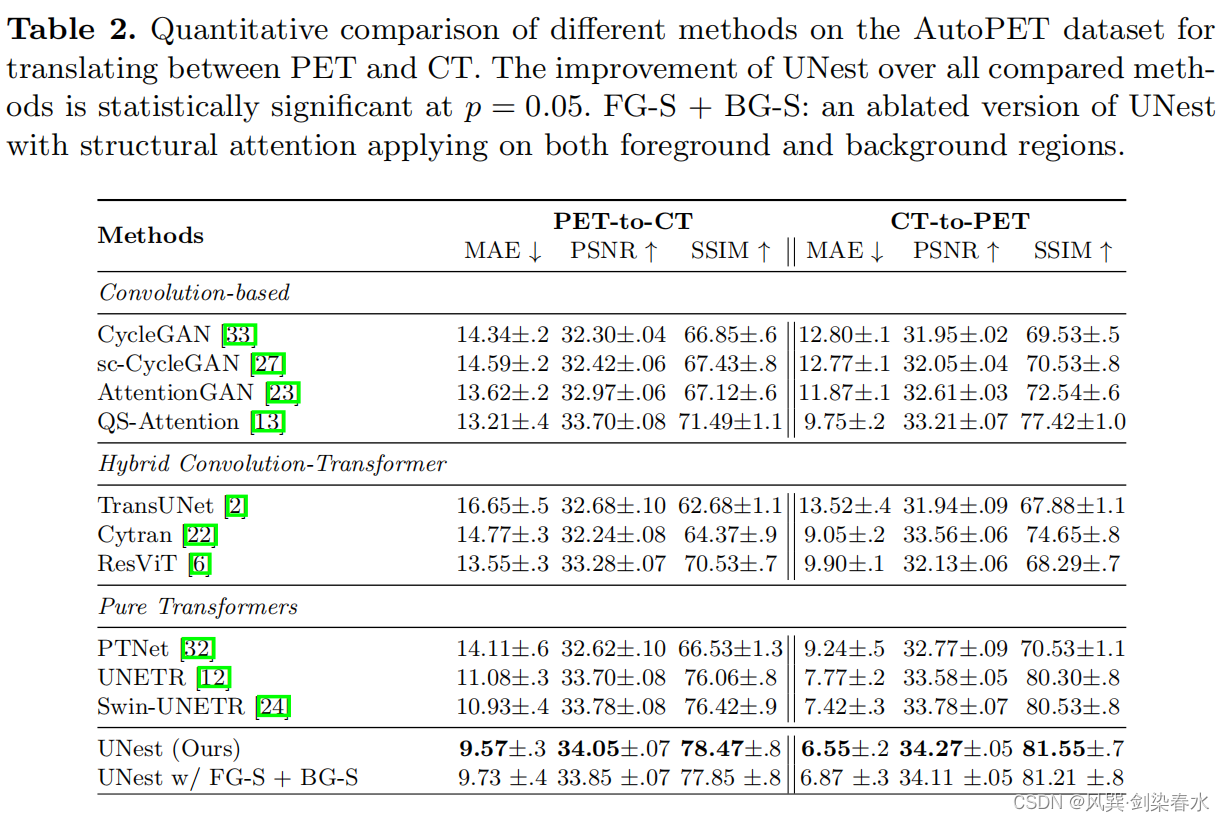
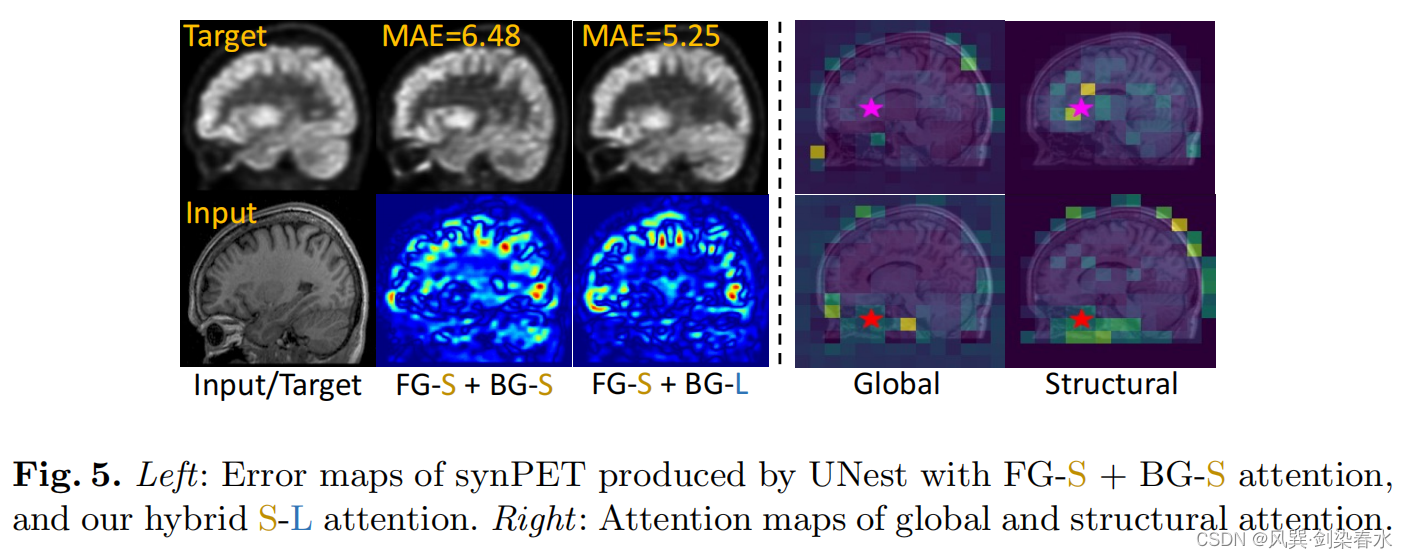
3.4、消融实验
表2可以看出,双重注意和结构注意FG-S + BG-S在PET-CT上对UNETR和Swin UNETR的MAE分别提高了12.18%和10.98%。(百分数表示实在是妙啊~)
整体注意关注较少相关的BG tokens,而结构注意则自适应地关注解剖特征:
在图像合成领域diffusion盛行的时候,还有transformer的一席之地~

















 72
72

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









