







Backbone is All Your Need: A Simplified Architecture for Visual Object Tracking
论文地址:https://arxiv.org/pdf/2203.05328
贡献:
1、提出了SimTrack,一种简化的跟踪架构,它将序列化的范例和搜索馈送到变压器主干中,以进行联合特征学习和交互。与现有的Siamese跟踪体系结构相比,SimTrack只有一个分支主干,去掉了现有的交互头,使框架更简单,学习能力更强。
2、为了弥补SimTrack下采样造成的信息丢失,提出了一种中央凹窗策略,帮助transformer骨干在重要的样例图像区域捕获更多细节。
动机:
虽然有效,但这些 Transformer 头是高度定制和精心设计的,因此很难将它们合并到更一般的系统中或泛化到各种智能任务。
由于Transformer 具有优越的模型容量,因此可以通过充分利用Transformer 的特定任务来删除具有特定任务先验知识的子模块和过程。然而,正如本文所观察到的,在现有的VOT方法中没有研究利用Transformer 来产生简单和通用的框架。
通过以上观察,本文倡导通过利用Transformer 主干进行联合功能学习和交互的简化跟踪(SimTrack)范例。
具体地说,我们首先将样本(Z)和搜索(X)图像序列化为多个令牌,并将它们一起发送到我们的Transformer主干。然后,来自Transformer主干的搜索特征直接用于通过预测器进行目标定位,而不需要任何交互模块。
此外,SimTrack为视觉目标跟踪带来了多个新的好处。
1、SimTrack是一个更简单、更通用的框架,子模块更少,对VOT任务的先验知识的依赖也更少。
2、我们的Transformer主干中的注意机制促进了样本和搜索功能之间的多层次和更全面的交互。这样,在每个Transformer块中,搜索和样本图像的主干特征将相互依赖,从而产生指定的样例(搜索)敏感而不是一般搜索(样例)特征,这是看似简单的Transformer主干有效性的隐藏因素。
3、去掉Transformer头可以减少训练负担。一方面,SimTrack 可以达到与基线模型相同的训练损失或测试精度,只有一半的训练 epoch,因为信息交互发生在初始化良好的变压器主干中,而不是随机初始化的变压器头中。另一方面,虽然在主干中添加信息交互会带来额外的计算,但额外的计算通常比来自转换器头的计算要小。
4、根据广泛的实验,SimTrack 可以通过使用与 Siamese 主干相同的转换器与其他基于变压器的跟踪器进行适当的初始化来获得更准确的结果。
虽然基于Transformer的主干能够联合实现样本与搜索之间的充分特征学习和交互,但下采样操作可能会导致VOT不可避免的信息丢失,这是一个定位任务,需要更多的对象视觉细节,而不仅仅是抽象/语义视觉概念。为了减少下采样的不利影响,进一步提出了一种受中央凹中心启发的中心凹窗口策略。
中央凹中心是眼睛中的一个小中心区域,使人眼能够从视觉区域的中心部分捕获更多有用的信息。在本文中,样本图像中的中心区域包含更多的目标相关信息,并相应地需要更多的关注。因此,在中心区域添加一个中心凹窗口来产生更多样化的目标补丁,使图像中心周围的补丁采样频率高于图像边界周围的补丁采样频率,提高跟踪性能。
1、基本方法:
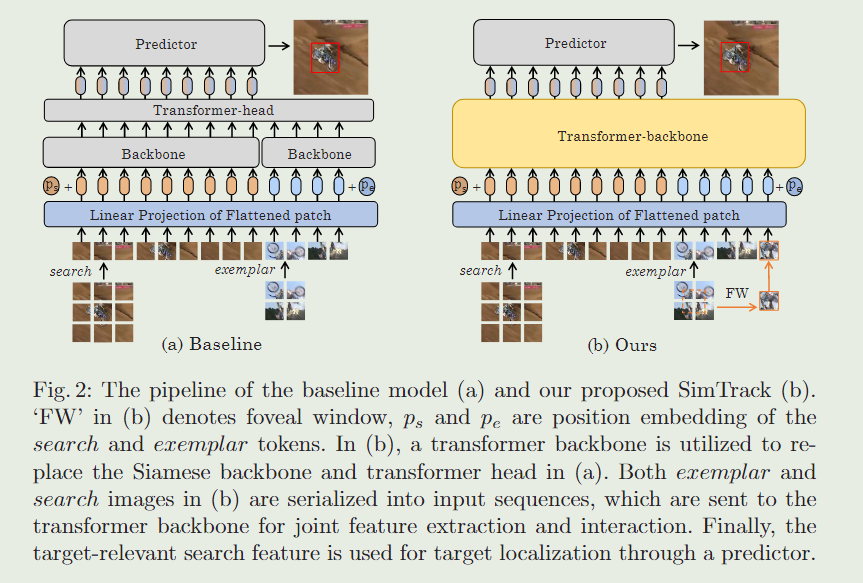
我们的SimTrack由变压器主干和预测器组成,如图2(b)所示。
Transformer主干用于样本和搜索特征之间的特征提取和信息交互,引导网络学习与目标相关的搜索特征。在通过主干后,将搜索区域对应的输出特征发送到角点预测器进行目标定位。
1、Baseline Model
STAK-S在推理过程中没有额外的后处理,这与我们简化跟踪框架的最初目的是一致的。我们将STARK-S的主干从Res50替换为VIT,以获得我们的基线模型STARK-SV。
Image serialization
两个输入图像在主干之前被序列化为输入序列。
具体地说,类似于目前的视觉转换器,我们将图像 Z ∈ R H z × W z × 3 Z\in{R^{H_z\times W_z\times 3}} Z∈RHz×Wz×3和 X ∈ R H x × W x × 3 X\in{R^{H_x\times W_x\times 3}} X∈RHx×Wx×3重塑为两个扁平2D斑块序列 Z p ∈ R N z × ( P 2 ⋅ 3 ) Z_p\in{R^{N_z\times{(P^2\cdot3)}}} Zp∈RNz×(P2⋅3)和 X p ∈ R N x × ( P 2 ⋅ 3 ) X_p\in{R^{N_x\times{(P^2\cdot3)}}} Xp∈RNx×(P2⋅3),其中 ( P , P ) (P,P) (P,P) 是图像patch的分辨率, N z = H z W z / P 2 N_z=H_zW_z/P^2 Nz=HzWz/P2和 N x = H x W x / P 2 N_x=H_xW_x/P^2 Nx=HxWx/P2 是示例和搜索图像的patch数。通过线性投影将 2D 补丁映射到具有 C 维的 1D 令牌。在添加带有位置嵌入的 1D 标记后,我们得到主干的输入序列,包括示例序列$ e^0\in R^{N_z×C}$ 和搜索序列 s 0 ∈ R N x × C s^0\in{R^{N_x\times C}} s0∈RNx×C。
Feature extraction with backbone
Transformer主干由 L 层组成。我们利用 e l e^l el 和 s l s^l sl 来表示第 ( l + 1 ) (l + 1) (l+1) 层的输入示例和搜索序列, l = 0 , . . . , L − 1 l=0,...,L-1 l=0,...,L−1。每一层中样本特征的前向过程可以写成:
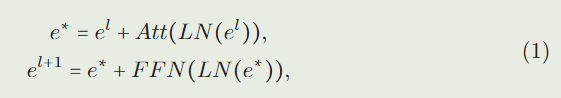
其中 FFN 是前馈网络,LN 表示 Layer norm,Att 是 self attention 模块(为了简化,我们在以下函数中删除了 LN),
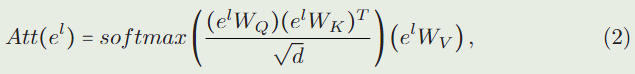
其中 1 / d 1/\sqrt{d} 1/d是比例因子, W Q ∈ R C × D , W K ∈ R C × D , W V ∈ R C × D W_Q\in R^{C×D} , W_K\in R^{C×D} , W_V\in R^{C×D} WQ∈RC×D,WK∈RC×D,WV∈RC×D 是将输入序列转换为查询、键和值的项目指标。通常,采用多头自注意力代替等式中的自注意力。为了简单和更好地理解,我们在描述中使用自注意力模块。我们可以看到, e l e^l el 的特征提取只考虑了示例信息。 s l s^l sl 的前馈过程与 e l e^l el 相同。在将输入传递到主干后,我们得到输出示例序列 e L e^L eL 和输出搜索序列 s L s^L sL。
Feature interaction with transformer head.
特征$ e^L ∈ R^{N_z ×D}$ 和$ s^L ∈ R^{N_x ×D}$ 在 Transformer 头中相互交互。我们建议读者参阅STARK-S,了解我们的基线模型中变压器头的更多细节。
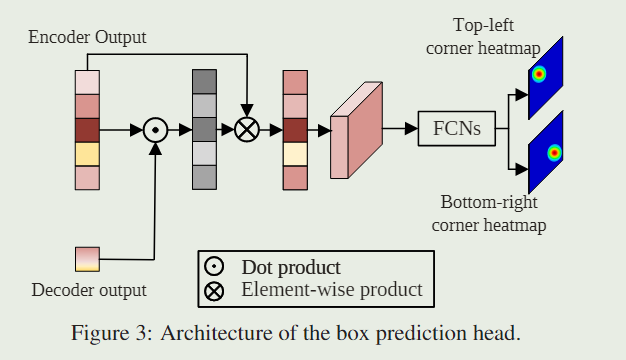
Target localization with predictor
在Transformer 头之后,我们得到一个目标相关的搜索特征 s L ∗ ∈ R N x × D ∗ s^{L^*}\in R^{N_x\times D^∗} sL∗∈RNx×D∗,它被重塑为 H x s × W x s × D ∗ \frac{H_x}{s}\times\frac{W_x}{s}\times{D^*} sHx×sWx×D∗并发送到角预测器。角落预测器为目标框的左上角和右下角输出两个概率图。
在离线训练中,随机选择视频中预定义帧范围内的一对图像作为样本帧和搜索帧。在搜索框上得到预测框 b i b_i bi后,通过 l 1 l_1 l1损失和广义IoU损失对整个网络进行训练:
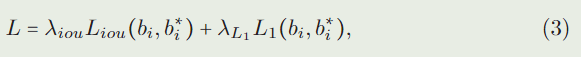
其中 b i ∗ b^*_i bi∗为ground truth框, λ i o u λ_{iou} λiou和 λ L 1 λ_{L_1} λL1为损失权重, L i o u L_{iou} Liou为广义IoU loss, L 1 L_1 L1为 l 1 l_1 l1loss。
2、Simplified Tracking Framework
我们的关键思想是将基线模型中的Siamese主干和变压器头替换为统一的Transformer 主干,如图2 (b)所示。对于STARK-S,主干的功能是提供强大的特征提取。Transformer头负责范例和搜索特征之间的信息交互。在我们的SimTrack中,只需要一个变压器主干来进行联合功能和交互学习。
Joint feature extraction and interaction with transformer backbone.
与基线模型不同,我们直接沿着第一个维度连接 e 0 e^0 e0和 s 0 s^0 s0,并将它们一起发送到Transformer 主干网。第 ( l + 1 ) (l + 1) (l+1)层前馈过程为:
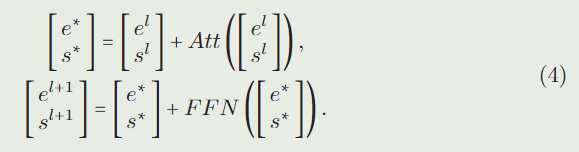
为了简化,在式(4)中去除了层归一化的符号。式(1)与式(4)的主要区别在于 A t t ( ⋅ ) Att(\cdot) Att(⋅)中的计算,
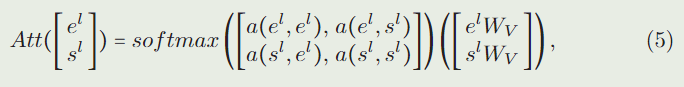
式中 a ( x , y ) = ( x W Q ) ( y W K ) T / d a(x, y) = (xW_Q)(yW_K)^T/\sqrt{d} a(x,y)=(xWQ)(yWK)T/d。在转换等式(5)之后,样本注意力 A t t ( e l ) Att(e^l) Att(el)和搜索注意力 A t t ( s l ) Att(s^l) Att(sl)是:
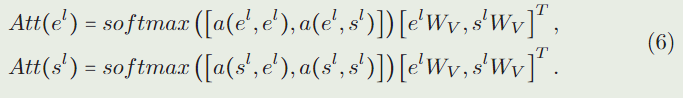
在基线模型中,样本和搜索特征的特征提取是相互独立的,而在我们的Transformer 主干中,样本的特征学习与搜索图像的特征学习是相互影响的。 A t t ( e l ) Att(e^l) Att(el)包含来自 s l s^l sl的信息,反之亦然。样本和搜索特征之间的信息交互存在于Transformer 主干的每一层,因此不需要在主干之后增加额外的交互模块。我们直接将输出的搜索特征 s L s^L sL发送到预测器进行目标定位。
Distinguishable position embedding.
它是无缝传输从分类任务预训练的网络的通用范式,为 VOT 提供更强的初始化。在我们的方法中,我们还使用预训练的参数初始化我们的 Transformer 主干。对于搜索图像,输入大小(224 × 224)与一般视觉变换器相同,所以预训练的位置嵌入 p0 可以直接用于搜索图像(ps = p0)。然而,样本图像比搜索图像小,因此预先训练的位置嵌入方法不能很好地适应样本图像。此外,对两幅图像使用相同的预训练位置嵌入,使得主干没有信息来区分两幅图像。
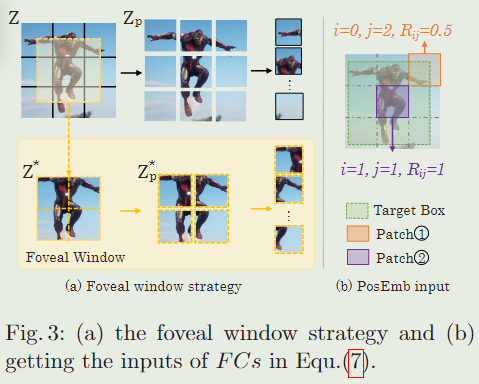
为了解决这个问题,我们在样本特征上添加了一个可学习的位置嵌入 p e ∈ R N z × D p_e ∈ R^{N_z ×D} pe∈RNz×D,它由补丁的空间位置$ (i, j)$ 和该补丁中目标区域的比率 R i j R_{ij} Rij计算得出(如图 3 (b) 所示),

其中 p e p_e pe表示示例特征的位置嵌入, F C s FCs FCs 是两个全连接层。在获得位置嵌入 p e p_e pe和 p s p_s ps后,我们将它们添加到嵌入向量中。生成的嵌入向量序列用作变压器主干的输入。
3、Foveal Window Strategy
示例图像包含中心的目标和目标周围的少量背景。下采样过程可以将重要的目标区域分割成不同的部分。为了为Transformer 主干提供更详细的目标信息,我们进一步在样本图像上提出了一种中心凹窗口策略,以可接受的计算成本产生更多样化的目标补丁。
如图3(a)第二行所示,我们在样本图像的中心裁剪一个较小的区域 Z ∗ ∈ R H z ∗ × W z ∗ × 3 Z^*\in R^{H_z^*×W_z^* ×3} Z∗∈RHz∗×Wz∗×3,并将 Z ∗ Z^* Z∗序列化为图像补丁 Z p ∗ ∈ R N z ∗ × ( P 2 ⋅ 3 ) Z^*_p\in R^{N^*_z×(P^2⋅3)} Zp∗∈RNz∗×(P2⋅3),其中 N x ∗ = H x ∗ W x ∗ / P 2 N^*_x = H^*_x W^*_x/P^2 Nx∗=Hx∗Wx∗/P2。
Z ∗ Z^∗ Z∗上的分割线位于样本图像 Z Z Z上的分割线的中心,从而确保中心凹斑块 Z p ∗ Z^∗_p Zp∗包含与原始斑块 Z p Z_p Zp不同的目标信息。
得到中央凹斑块 Z p ∗ Z^*_p Zp∗后,根据式(7)计算其位置嵌入。然后,我们用与 Z p Z_p Zp相同的线性投影映射 Z p ∗ Z^*_p Zp∗,并将映射的特征与位置嵌入相加,得到中央凹序列 e 0 ∗ e^{0*} e0∗。
最后,Transformer 主干的输入包括搜索序列 s 0 s^0 s0、范例序列 e 0 e^0 e0和中央凹序列 e 0 ∗ e^{0*} e0∗。样本图像在VOT中较小,因此 e 0 e^0 e0和 e 0 ∗ e{0*} e0∗中的令牌数也较小。














 229
229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









