







模型优化思路:
建立lightgbm、xgboost和catboost的集成模型进行预测,
具体实现方式:分别使用lightgbm、xgboost和catboos建立预测模型,对三者的预测结果进行均值融合,得到集成模型的预测结果
def cv_model(clf, train_x, train_y, test_x, clf_name, seed = 2023):
folds = 5
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
oof = np.zeros([train_x.shape[0], 3])
test_predict = np.zeros([test_x.shape[0], 3])
cv_scores = []
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
print('************************************ {} ************************************'.format(str(i+1)))
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]
if clf_name == "lgb":
train_matrix = clf.Dataset(trn_x, label=trn_y)
valid_matrix = clf.Dataset(val_x, label=val_y)
params = {
'boosting_type': 'gbdt',
'objective': 'multiclass',
'num_class':3,
'min_child_weight': 6,
'num_leaves': 2 ** 6,
'lambda_l2': 10,
'feature_fraction': 0.8,
'bagging_fraction': 0.8,
'bagging_freq': 4,
'learning_rate': 0.1,
'seed': 2023,
'nthread' : 16,
'verbose' : -1,
}
model = clf.train(params, train_matrix, 200, valid_sets=[train_matrix, valid_matrix],
categorical_feature=[])
val_pred = model.predict(val_x, num_iteration=model.best_iteration)
test_pred = model.predict(test_x, num_iteration=model.best_iteration)
if clf_name == "xgb":
xgb_params = {
'booster': 'gbtree',
'objective': 'multi:softprob',
'num_class':3,
'max_depth': 5,
'lambda': 10,
'subsample': 0.7,
'colsample_bytree': 0.7,
'colsample_bylevel': 0.7,
'eta': 0.1,
'tree_method': 'hist',
'seed': 520,
'nthread': 16,
'tree_method': 'gpu_hist',
}
train_matrix = clf.DMatrix(trn_x , label=trn_y)
valid_matrix = clf.DMatrix(val_x , label=val_y)
test_matrix = clf.DMatrix(test_x)
watchlist = [(train_matrix, 'train'),(valid_matrix, 'eval')]
model = clf.train(xgb_params, train_matrix, num_boost_round=200, evals=watchlist)
val_pred = model.predict(valid_matrix)
test_pred = model.predict(test_matrix)
if clf_name == "cat":
params = {'learning_rate': 0.1, 'depth': 5, 'bootstrap_type':'Bernoulli','random_seed':2023,
'od_type': 'Iter', 'od_wait': 100, 'random_seed': 11, 'allow_writing_files': False,
'loss_function': 'MultiClass', "task_type": device}
model = clf(iterations=200, **params)
model.fit(trn_x, trn_y, eval_set=(val_x, val_y),
metric_period=50,
use_best_model=True,
cat_features=[],
verbose=1)
val_pred = model.predict_proba(val_x)
test_pred = model.predict_proba(test_x)
oof[valid_index] = val_pred
test_predict += test_pred / kf.n_splits
F1_score = f1_score(val_y, np.argmax(val_pred, axis=1), average='macro')
cv_scores.append(F1_score)
print(cv_scores)
return oof, test_predict# 处理train_x和test_x中的NaN值
train_df = train_df.fillna(0)
test_df = test_df.fillna(0)
# 处理train_x和test_x中的Inf值
train_df = train_df.replace([np.inf, -np.inf], 0)
test_df = test_df.replace([np.inf, -np.inf], 0)
# 入模特征
cols = [f for f in test_df.columns if f not in ['uuid','time','file']]
for label in ['label_5','label_10','label_20','label_40','label_60']:
print(f'=================== {label} ===================')
# 选择lightgbm模型
lgb_oof, lgb_test = cv_model(lgb, train_df[cols], train_df[label], test_df[cols], 'lgb')
# 选择xgboost模型
xgb_oof, xgb_test = cv_model(xgb, train_df[cols], train_df[label], test_df[cols], 'xgb')
# 选择catboost模型
cat_oof, cat_test = cv_model(CatBoostClassifier, train_df[cols], train_df[label], test_df[cols], 'cat')
# 进行取平均融合
final_test = (lgb_test + xgb_test + cat_test) / 3
test_df[label] = np.argmax(final_test, axis=1)
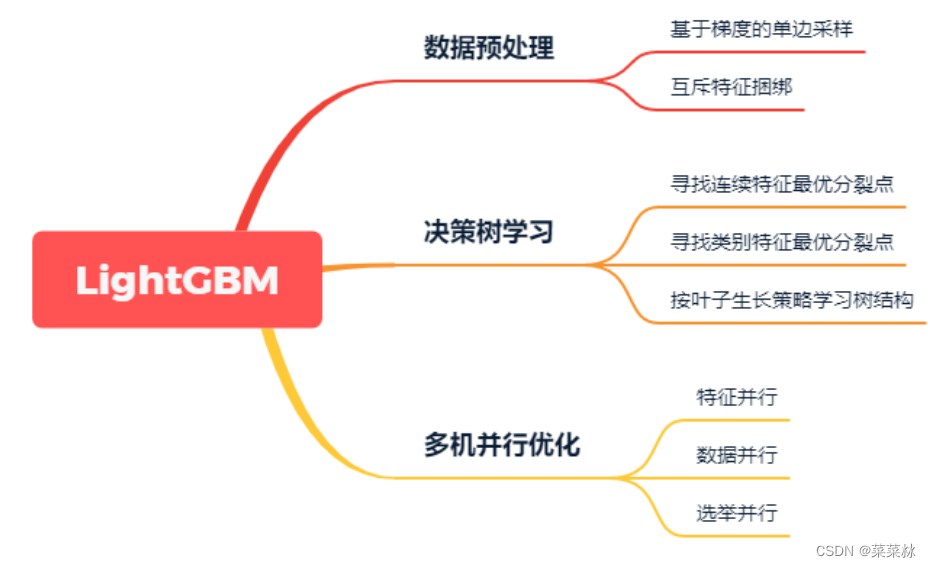
LightGBM
CatBoost
如何衡量特征和目标之间的非线性关系?
A、相关系数
B、互信息
C、协方差
D、最大信息系、
答案:ABC只能描述线性的关系,D可以描述非线性的关系。最大信息系数(MIC)可衡量特征和目标非线性关系。0-1间数值,越大表示关系越强。相比其他选项,MIC更适合发现非线性关系。A.最常见的皮尔逊相关系数的原理就是根据数据的协方差和标准差评判自变量与因变量数据是否拟合在一条线性线上。B.相关系数是从统计学角度出发,而互信息则是从联合概率密度角度出发,即自变量出现时因变量出现的概率,表达意义与皮尔逊相完关系数类似,范围为0-1,即两变量关系从不确定到完全确定。C.皮尔逊等相关系数便由协方差出发,只能衡量两变量的整体误差,无非线性相关度量能力。
1.什么是正则化,请解释L1范数和L2范数的区别?
正则化是一种防止过拟合的技术,能够提高模型的泛化能力。则化通过向损失函数中引入惩罚项来实现,这些惩罚项会根据模型参数的大小进行调整,以减少大的参数值,从而使模型更加平滑和稳定。
L1范数正则化(Lasso正则化):它向损失函数中添加参数的绝对值之和作为惩罚项。L1正则化有助于产生稀疏权重,即许多特征的权重会变为零,从而实现特征选择和降维的效果。
* L2范数正则化(Ridge正则化):它向损失函数中添加参数的平方和的平方根作为惩罚项。L2正则化倾向于将权重分布在多个特征上,而不会特别强调让某些特征的权重变为零。
L1正则化会倾向于使一些特征的权重变为零,从而达到特征选择的效果,适用于特征稀疏化的场景。而L2正则化会让所有特征的权重都趋于减小,但不会直接使某些特征的权重变为零,适用于降低模型复杂度的场景。















 454
454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









