







文章目录
在本文中我们使用 toy 语言接入 MLIR,最终转化为 LLVM IR (或目标代码)为例,来讲解 MLIR 的转换流程。具体的流程如下:
.toy 源文件 → \rightarrow → AST → \rightarrow → MLIRGen(遍历AST生成MLIR表达式) → \rightarrow → Transformation(变形消除冗余) → \rightarrow → Lowering → \rightarrow → LLVM IR / JIT 编译引擎
1. Toy接入MLIR
本节将由 toy 源码生成未经优化的 MLIR 表达式。
1.1 Toy源码和AST
def multiply_transpose(a, b){
return transpose(a) * transpose(b);
}
def main() {
var a<2, 3> = [[1, 2, 3], [4, 5, 6]];
var b<2, 3> = [1, 2, 3, 4, 5, 6];
var c = multiply_transpose(a, b);
print(c);
}
编译得到的AST如下
Module:
Function
Proto 'multiply_transpose' @test/Examples/Toy/Ch1/ast.toy:4:1'
Params: [a, b]
Block {
Return
BinOp: * @test/Examples/Toy/Ch1/ast.toy:5:25
Call 'transpose' [ @test/Examples/Toy/Ch1/ast.toy:5:10
var: a @test/Examples/Toy/Ch1/ast.toy:5:20
]
Call 'transpose' [ @test/Examples/Toy/Ch1/ast.toy:5:25
var: b @test/Examples/Toy/Ch1/ast.toy:5:35
]
} // Block
... // main函数的ast未写出
1.2 生成(未优化)MLIR表达式
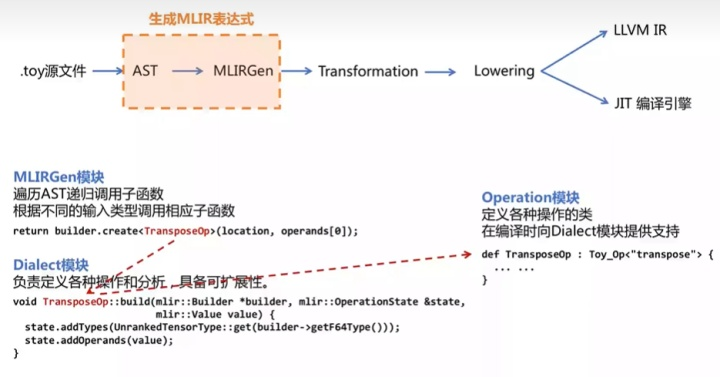
- MLIRGen 模块会遍历 AST ,递归调用子函数,构建
operation。operation 是 dialect 中重要的组成元素,用来表示 dialect 中的某个操作,一个 dialect 中可以有很多的 operation。
mlir::Value mlirGen(CallExperAST &call)
{
llvm::StringRef callee = call.getCallee();
auto location = loc(call.loc());
SmallVector<mlir::Value, 4> operands;
for(auto &expr:call.getArgs()){
auto arg = mlirGen(*expr); // 递归调用
if(!arg)
return nullptr;
operands.push_back(arg);
}
if(callee == "transpose"){
if(call.getArgs().size() != 1){
emitError(location, "MLIR codegen encountered an error: toy.transpose does not accept multiple arguments");
return nullptr;
}
return bulider.creater<TransposeOp>(location, operands[0]);
}
...
}
- 创建好的节点 operation 还没有输入参数等定义,Toy Dialect 模块负责定义各种操作和分析。(Toy Dialect 继承自 mlir::Dialect,并注册了属性、操作和数据类型等)
Toy Dialect 模块的创建 见 MLIR初识 —— Dialect及Operation详解 “3 创建新的dialect”
// TransposeOp
void TransposeOp::build(mlir::OpBuilder &builder, mlir::OperationState &state, mlir::Value value){
state.addTypes(UnrankedTensorType::get(bulider.getF64Type()));
state.addOperands(value);
}
根据 ast 中的节点,生成的一系列 operations 最终组成 MLIR 表达式。(不显示loc的信息)
# 由toy ast 生成 MLIR 表达式
module{
func @multiply_transpose(%arg0: tensor<*xf64>, %arg1: tensor<*xf64>) -> tensor<*xf64> {
%0 = "toy.transpose"(%arg0): (tensor<*xf64>) -> tensor<*xf64>
%1 = "toy.transpose"(%arg1): (tensor<*xf64>) -> tensor<*xf64>
%2 = "toy.mul"(%0, %1): (tensor<*xf64>, tensor<*xf64>) -> tensor<*xf64>
"toy.return"(%2): (tensor<*xf64>) -> ()
}
func @main(){
%0 = "toy.constant"() {value = dense<[[1.000000e+00, 2.000000e+00, 3.000000e+00], [4.000000e+00, 5.000000e+00, 6.000000e+00]]> : tensor<2x3xf64>} : () -> tensor<2x3xf64>
%1 = "toy.reshape"(%0) : (tensor<2x3xf64>) -> tensor<2x3xf64>
%2 = "toy.constant"() {value = dense<[1.000000e+00, 2.000000e+00, 3.000000e+00, 4.000000e+00, 5.000000e+00, 6.000000e+00]> : tensor<6xf64>} : () -> tensor<6xf64>
%3 = "toy.reshape"(%2) : (tensor<6xf64>) -> tensor<2x3xf64>
%4 = "toy.generic_call"(%1, %3) {callee = @multiply_transpose} : (tensor<2x3xf64>, tensor<2x3xf64>) -> tensor<*xf64>
"toy.print"(%4) : (tensor<*x64>) -> ()
"toy.return"() : () -> ()
}
}
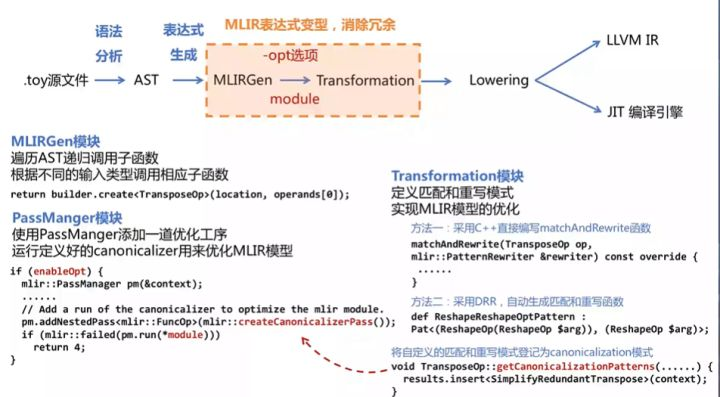
2. MLIR 表达式变形
本节的 2.1、2.2部分对应 Chapter 3: High-level Language-Specific Analysis and Transformation - MLIR (llvm.org)
本节的2.3部分对应 Chapter 4: Enabling Generic Transformation with Interfaces - MLIR (llvm.org)
我们发现生成的 MLIR 表达式往往存在冗余的操作,为了提升程序性能就需要对表达式进行转换变形。MLIR 提供以下两种方式进行模式匹配转换:
其一,使用 C++ 手动编写代码进行表达式的匹配与重写;
其二,使用基于规则的模式匹配和重写的声明式重写规则 DRR进行,但该方法要求使用 ODS)定义操作。
2.1 手动编写代码进行表达式的匹配与重写
对于同一个变量,连续进行多次转置操作,必然存在冗余操作。本节以 “消除两个具有相互抵消效果的转置序列” 为例,说明第一种模式匹配转换方法。(Optimize Transpose using C++ style pattern-match and rewrite)
// toy 代码
def transpose_transpose(x) {
return transpose(transpose(x));
}
// 未引入优化生成的MLIR表达式
func @transpose_transpose(%arg0: tensor<*xf64>) -> tensor<*xf64> {
%0 = toy.transpose(%arg0 : tensor<*xf64>) to tensor<*xf64>
%1 = toy.transpose(%0 : tensor<*xf64>) to tensor<*xf64>
toy.return %1 : tensor<*xf64>
}
- 第一步:直接使用 C++ 写出匹配和重写的代码
下面这段代码位于在 ToyCombine.cpp 中,默认位置在 …/mlir/examples/toy/Ch3/mlir/ToyCombine.cpp
// Fold transpose(transpose(x)) -> x
struct SimplifyRedundantTranspose : public mlir::OpRewritePattern<TransposeOp> {
// 匹配该IR中的所有 toy.transpose
/// mlir使用"benefit"对patterns进行排序,并按profitability顺序处理
SimplifyRedundantTranspose(mlir::MLIRContext *context)
: OpRewritePattern<TransposeOp>(context, /*benefit=*/1) {}
// 尝试匹配并重写
mlir::LogicalResult
matchAndRewrite(TransposeOp op,
mlir::PatternRewriter &rewriter) const override {
// 获取当前Op(一个TransposeOp)的操作数
mlir::Value transposeInput = op.getOperand();
// 获取当前Op的操作数对应的Op
TransposeOp transposeInputOp = transposeInput.getDefiningOp<TransposeOp>();
// 如果当前Op的操作数对应的Op不是Transpose,重写失败
if (!transposeInputOp)
return failure();
// 反之,当前Op就是TransposeOp
// transposeInputOp.getOperand()就是x
rewriter.replaceOp(op, {transposeInputOp.getOperand()});
return success();
}
};
- 第二步:将自定义的匹配和重写模式登记为 canonicalization 模式,使得后续可以使用它
下面这段代码位于 toyc.cpp 中,默认位置为 …/mlir/examples/toy/Ch3/mlir/ToyCombine.cpp
void TransposeOp::getCanonicalizationPatterns(OwningRewritePatternList &results,
MLIRContext *context) {
// SimplifyRedundantTranspose 就是第一步中定义的结构体(类)
results.insert<SimplifyRedundantTranspose>(context);
}
- 第三步:在
Ops.td中设置相应选项
下面这段代码位于 Ops.td 中,默认位置为…/mlir/examples/toy/Ch3/include/toy/Ops.td
def TransposeOp : Toy_Op<"transpose", [NoSideEffect]> {
// MLIR 在优化代码时较为保守,可能会保留一些无效操作
// 设置[NoSideEffect] 可解决这一问题
...
// 确保启用规范化框架,应用 canonicalization pass
let hasCanonicalizer = 1;
...
}
- 第四步:更新主文件以添加
optimization pipeline
下面这段代码位于 toyc.cpp 中,默认位置在 …/mlir/examples/toy/Ch3/toyc.cpp
if (enableOpt) {// enableOpt 是从命令行输入的编译选项
// 使用 PassManger 模块添加优化一道优化工艺
mlir::PassManager pm(&context);
applyPassManagerCLOptions(pm);
// createCanonicalizerPass 创建并使用规范化框架
pm.addNestedPass<mlir::FuncOp>(mlir::createCanonicalizerPass());
// 运行定义好的 canonicalizer 来优化 MLIR 表达式
if (mlir::failed(pm.run(*module)))
return 4;
}
- 最后执行
toyc-ch3 ../../test/Examples/Toy/Ch3/transpose_transpose.toy -emit=mlir -opt,得到优化后的 Toy Dialect IR (MLIR表达式)如下
toy.func @transpose_transpose(%arg0: tensor<*xf64>) -> tensor<*xf64> {
%0 = toy.transpose(%arg0 : tensor<*xf64>) to tensor<*xf64>
toy.return %arg0 : tensor<*xf64>
}
2.2 采用 DDR 自动生成匹配和重写函数
DRR(Declarative, rule-based pattern-match and rewrite)是一种基于 DAG(Directed acyclic graph) 的声明性重写器,提供 table-base 的模式匹配和规则重写的句法。类似于 ODS 框架,我们只需要使用一定的声明性描述,就可以自动生成匹配和规则重写程序。
class Pattern<
dag sourcePattern, list<dag> resultPatterns,
list<dag> additionalConstraints = [],
dag benefitsAdded = (addBenefit 0)>;
生成的 MLIR 表达式存在许多冗余的 reshape 操作,本节以消除冗余的 reshape 操作为例,说明第二种模式匹配转换方法。(Optimize Reshapes using DRR)
// toy 代码
def main() {
var a<2,1> = [1, 2];
var b<2,1> = a;
var c<2,1> = b;
print(c);
}
// 未引入优化生成的MLIR表达式
module {
func @main() {
%0 = toy.constant dense<[1.000000e+00, 2.000000e+00]> : tensor<2xf64>
%1 = toy.reshape(%0 : tensor<2xf64>) to tensor<2x1xf64>
%2 = toy.reshape(%1 : tensor<2x1xf64>) to tensor<2x1xf64>
%3 = toy.reshape(%2 : tensor<2x1xf64>) to tensor<2x1xf64>
toy.print %3 : tensor<2x1xf64>
toy.return
}
}
下面步骤中的代码均位于在 ToyCombine.td 中,默认位置在 …/mlir/examples/toy/Ch3/mlir/ToyCombine.td
使用:
${build_root}/bin/mlir-tblgen --gen-rewriters ${mlir_src_root}/examples/toy/Ch3/mlir/ToyCombine.td -I ${mlir_src_root}/include/自动生成 C++ 代码自动生成的 C++ 代码在 …/mlir/examples/toy/Ch3/mlir/ToyCombine.inc
- 基础方法
// Reshape(Reshape(x)) = Reshape(x)
def ReshapeReshapeOptPattern : Pat<(ReshapeOp(ReshapeOp $arg)),
(ReshapeOp $arg)>;
- 添加参数约束的方法
DDR 提供了一种添加参数约束的方法,以应对当改写只发生在某些特定条件下的情况。(when the transformation is conditional on some properties of the arguments and results)
// 当输入形状和输出形状相同时,才消除该 reshape 操作
def TypesAreIdentical : Constraint<CPred<"$0.getType() == $1.getType()">>;
def RedundantReshapeOptPattern : Pat<
(ReshapeOp:$res $arg), (replaceWithValue $arg),
[(TypesAreIdentical $res, $arg)]>;
Some optimizations may require additional transformations on instruction arguments. NativeCodeCall 通过调用 C++ helper function 或使用 inline C++ 进行更复杂的转换。
// 通过 reshape 常量的形状并消除 reshape 操作来优化对于常量的操作
def ReshapeConstant : NativeCodeCall<"$0.reshape(($1.getType()).cast<ShapedType>())">;
def FoldConstantReshapeOptPattern : Pat<
(ReshapeOp:$res (ConstantOp $arg)),
(ConstantOp (ReshapeConstant $arg, $res))>;
- 最后执行
toyc-ch3 ../../test/Examples/Toy/Ch3/trivial_reshape.toy -emit=mlir - opt,得到优化后的 Toy Dialect IR (MLIR表达式)如下
module {
toy.func @main() {
%0 = toy.constant dense<[[1.000000e+00], [2.000000e+00]]> : tensor<2x1xf64>
toy.print %0 : tensor<2x1xf64>
toy.return
}
}
2.3 通用的转换接口
通过使用 Dialect,MLIR 可以表示多种不同等级的抽象。尽管这些不同的 Dialect 表示不同的抽象,但某些操作的算法机制十分相似,为了减少代码重复,MLIR 提供了一组通用的转换和分析。
-
为了代码执行速度更快,将函数进行内联(inline)操作
-
为了代码生成阶段更方便,需要进行形状推断,确定所有 tensor 的 shape

下面以消除冗余 reshape 操作后的 MLIR 表达式为例
// toy 源码
def multiply_transpose(a, b){
return transpose(a) * transpose(b);
}
def main() {
var a<2, 3> = [[1, 2, 3], [4, 5, 6]];
var b<2, 3> = [1, 2, 3, 4, 5, 6];
var c = multiply_transpose(a, b);
print(c);
}
// 消除冗余 reshape 操作后的 MLIR 表达式
module{
func @multiply_transpose(%arg0: tensor<*xf64>, %arg1: tensor<*xf64>) -> tensor<*xf64> {
%0 = "toy.transpose"(%arg0): (tensor<*xf64>) -> tensor<*xf64>
%1 = "toy.transpose"(%arg1): (tensor<*xf64>) -> tensor<*xf64>
%2 = "toy.mul"(%0, %1): (tensor<*xf64>, tensor<*xf64>) -> tensor<*xf64>
"toy.return"(%2): (tensor<*xf64>) -> ()
}
func @main(){
%0 = "toy.constant"() {value = dense<[[1.000000e+00, 2.000000e+00, 3.000000e+00], [4.000000e+00, 5.000000e+00, 6.000000e+00]]> : tensor<2x3xf64>} : () -> tensor<2x3xf64>
%1 = "toy.constant"() {value = dense<[[1.000000e+00, 2.000000e+00, 3.000000e+00], [4.000000e+00, 5.000000e+00, 6.000000e+00]]> : tensor<2x3xf64>} : () -> tensor<2x3xf64>
%2 = "toy.generic_call"(%0, %1) {callee = @multiply_transpose} : (tensor<2x3xf64>, tensor<2x3xf64>) -> tensor<*xf64>
"toy.print"(%2) : (tensor<*x64>) -> ()
"toy.return"() : () -> ()
}
}
- 内联(inline)
内联会将函数展开,把函数的代码复制到每一个调用处,以解决一些频繁调用的小函数大量消耗栈空间(栈内存)的问题。使用该优化方法后,编译器会将简单函数内嵌到调用处,以储存空间为代价换取运行速度。
(1)首先,我们需要一个专属于 Toy 的内联函数接口,MLIR 中已经提供了相应的内联函数接口模板 DialectInlinerInterface,我们只需要在 Toy Dialect 中继承这一类来编写 Toy 中的内联函数接口即可。
// 该程序位于../mlir/examples/toy/Ch4/mlir/Dialect.cpp
// 定义 Toy 内联函数接口
struct ToyInlinerInterface : public DialectInlinerInterface {
using DialectInlinerInterface::DialectInlinerInterface;
// if the given operation is legal to inline into the given region
bool isLegalToInline(Operation *call, Operation *callable,
bool wouldBeCloned) const final {
return true;
}
// if the given 'src' region can be inlined into the 'dest' region
bool isLegalToInline(Operation *, Region *, bool,
BlockAndValueMapping &) const final {
return true;
}
void handleTerminator(Operation *op,
ArrayRef<Value> valuesToRepl) const final {
// Only "toy.return" needs to be handled here.
auto returnOp = cast<ReturnOp>(op);
// Replace the values directly with the return operands.
assert(returnOp.getNumOperands() == valuesToRepl.size());
for (const auto &it : llvm::enumerate(returnOp.getOperands()))
valuesToRepl[it.index()].replaceAllUsesWith(it.value());
}
};
(2)其次,我们需要在 Toy Dialect 中注册内联接口
// 位于 ../mlir/examples/toy/Ch4/mlir/Dialect.cpp
void ToyDialect::initialize() {
addInterfaces<ToyInlinerInterface>();
}
(3)然后,需要定位函数调用的位置。由于内联操作都是对调用函数进行操作,所以需要让内联器(inliner)知道 Toy Dialect IR 中toy.generic_call代表调用。这里我们需要实现将 CallOpInterface 添加到 GenericCallOp。
// 位于 ../mlir/examples/toy/Ch4/include/toy/Ops.td
// 使用 CallOpInterface 可以将操作标记为调用
include "mlir/Interfaces/CallInterfaces.td"
...
// 将其加入到 GenericCallOp 的 traits 列表中
def FuncOp : Toy_Op<"func",
[DeclareOpInterfaceMethods<CallableOpInterface>]> {
...
}
def GenericCallOp : Toy_Op<"generic_call",
[DeclareOpInterfaceMethods<CallOpInterface>]> {
...
}
上面的程序中,我们使用 DeclareOpInterfaceMethods 指令在GenericCallOp 类中声明接口的使用方法。我们还需要提供 GenericCallOp 的定义。
// 位于 ../mlir/examples/toy/Ch4/mlir/Dialect.cpp
// 返回function operation中可调用区域
Region *FuncOp::getCallableRegion() { return &getBody(); }
// 返回结果类型
ArrayRef<Type> FuncOp::getCallableResults() { return getType().getResults(); }
// ...
// 返回被调用者
CallInterfaceCallable GenericCallOp::getCallableForCallee() {
return getAttrOfType<SymbolRefAttr>("callee");
}
// 获得被调用函数的操作数
Operation::operand_range GenericCallOp::getArgOperands() { return inputs(); }
(4)在调用时实参和形参的类型可能不同,所以需要添加一个显式的类型转换(explicit cast),因此需要在 Toy Dialect 中添加 cast 操作并设置调用接口。
// 位于 ../mlir/examples/toy/Ch4/include/toy/Ops.td
def CastOp : Toy_Op<"cast", [
DeclareOpInterfaceMethods<CastOpInterface>,
NoMemoryEffect,
SameOperandsAndResultShape]
> {
let summary = "shape cast operation";
let description = [{
The "cast" operation converts a tensor from one type to an equivalent type
without changing any data elements. The source and destination types
must both be tensor types with the same element type. If both are ranked,
then shape is required to match. The operation is invalid if converting
to a mismatching constant dimension.
}];
let arguments = (ins F64Tensor:$input);
let results = (outs F64Tensor:$output);
let assemblyFormat = "$input attr-dict `:` type($input) `to` type($output)";
}
上述代码将 CastOpInterface 加入了 traits 列表中,还需要使用 areCastCompatible 来定义进入此接口的方法(hook into this interface)。
// 位于 ../mlir/examples/toy/Ch4/mlir/Dialect.cpp
// 该程序限定了能够进行 explicit cast 的条件
bool CastOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
if (inputs.size() != 1 || outputs.size() != 1)
return false;
TensorType input = inputs.front().dyn_cast<TensorType>();
TensorType output = outputs.front().dyn_cast<TensorType>();
if (!input || !output || input.getElementType() != output.getElementType())
return false;
return !input.hasRank() || !output.hasRank() || input == output;
}
然后在 (1) 中定义好的 ToyInlinerInterface 中增加 explicit cast 的内容,以保证内联操作顺利执行。
// 位于../mlir/examples/toy/Ch4/mlir/Dialect.cpp
// 定义 Toy 内联函数接口
struct ToyInlinerInterface : public DialectInlinerInterface {
...
// 是否在调用中启用 explicit cast
Operation *materializeCallConversion(OpBuilder &builder, Value input,
Type resultType,
Location conversionLoc) const final {
return builder.create<CastOp>(conversionLoc, resultType, input);
}
};
(5)最后将内联优化添加到 optimization pipeline 中(类似于2.1节的第四步)
// 位于 ../mlir/examples/toy/Ch4/toyc.cpp
if (enableOpt) {
mlir::PassManager pm(&context);
applyPassManagerCLOptions(pm);
...
// 将内联优化应用于所有function,然后会删去其他的function,只剩下一个main
pm.addPass(mlir::createInlinerPass());
...
}
运行后可得到经过内联(inline) Pass 后的 Toy Dialect,只剩下了一个function(main函数)
toy.func @main() {
%0 = toy.constant dense<[[1.000000e+00, 2.000000e+00, 3.000000e+00], [4.000000e+00, 5.000000e+00, 6.000000e+00]]> : tensor<2x3xf64>
%1 = toy.constant dense<[[1.000000e+00, 2.000000e+00, 3.000000e+00], [4.000000e+00, 5.000000e+00, 6.000000e+00]]> : tensor<2x3xf64>
%2 = toy.cast %1 : tensor<2x3xf64> to tensor<*xf64>
%3 = toy.cast %0 : tensor<2x3xf64> to tensor<*xf64>
%4 = toy.transpose(%2 : tensor<*xf64>) to tensor<*xf64>
%5 = toy.transpose(%3 : tensor<*xf64>) to tensor<*xf64>
%6 = toy.mul %4, %5 : tensor<*xf64>
toy.print %6 : tensor<*xf64>
toy.return
}
- 形状推断
目前主函数中存在动态和静态形状的混合,提前确定所有 tensor 的形状能够使最终生成的代码更加简洁。
(1)首先,使用 ODS 来定义 ShapeInference 操作的接口
// 位于 ../mlir/examples/toy/Ch4/include/toy/ShapeInferenceInterface.td
def ShapeInferenceOpInterface : OpInterface<"ShapeInference"> {
let description = [{
Interface to access a registered method to infer the return types for an
operation that can be used during type inference.
}];
}
(2)其次,在 Toy Dialect 中 ShapeInferenceOp 添加到需要它的 operation(就像实现内联 Pass中的第三步:把CallOpInterface添加到GenericCallOp)
// 位于 ../mlir/examples/toy/Ch4/include/toy/Ops.td
// 下面是将形状推断操作(ShapeInferenceOp)添加到乘法操作(MulOp)中
// 也可以添加到其他操作中
def MulOp : Toy_Op<"mul",
[..., DeclareOpInterfaceMethods<ShapeInferenceOpInterface>]> {
...
}
(3)然后,一些 operation 就获得了形状推断操作(ShapeInferenceOp)的接口,就需要在这些 operation 中定义对应的形状推断函数,独立定义可以保证 ShapeInferencePass 会独立地作用于该 operation。
// 位于 ../mlir/examples/toy/Ch4/mlir/Dialect.cpp
void MulOp::inferShapes() { getResult().setType(getOperand(0).getType()); }
(4)最后,将形状推断优化添加到 optimization pipeline 中
// 位于 ../mlir/examples/toy/Ch4/toyc.cpp
if (enableOpt) {
mlir::PassManager pm(&context);
applyPassManagerCLOptions(pm);
// 将内联优化应用于所有function,然后会删去其他的function,只剩下一个main
pm.addPass(mlir::createInlinerPass());
// 现在只剩下一个function(main),我们可以推断出operations的shape
mlir::OpPassManager &optPM = pm.nest<mlir::FuncOp>();
// 形状推断优化
optPM.addPass(mlir::toy::createShapeInferencePass());
// 规范化框架优化(2.1节中手动添加的优化)
optPM.addPass(mlir::createCanonicalizerPass());
// 公共子表达式消除(直接调用就行)
optPM.addPass(mlir::createCSEPass());
if (mlir::failed(pm.run(*module)))
return 4;
}
经过内联(inline) Pass 和 形状(shape)推断 Pass,得到优化后的main函数 MLIR 表达式如下
// 内联优化 和 形状推断优化 后的 main 函数 MLIR 表达式
// 将 callee = @multiply_transpose 内联为 toy.mul
// 将 <*xf64> 推断确定为 <3x2xf64>
toy.func @main() {
%0 = toy.constant dense<[[1.000000e+00, 2.000000e+00, 3.000000e+00], [4.000000e+00, 5.000000e+00, 6.000000e+00]]> : tensor<2x3xf64>
%1 = toy.transpose(%0 : tensor<2x3xf64>) to tensor<3x2xf64>
%2 = toy.mul %1, %1 : tensor<3x2xf64>
toy.print %2 : tensor<3x2xf64>
toy.return
}
可选:(5)将优化运用在所有操作operation中
上面编写好的 ShapeInferencePass 会针对每一个 function 进行操作,独立地优化每一个 function (run on each function in isolation)。如果想将优化操作泛化到全局(run on any isolated operation),则可以使用 MLIR 的 OperationPass接口。
" But here our module only contains functions, so there is no need to generalize to all operations."
但在这里,我们的模块只包含函数,因此不需要将 ShapeInferencePass 泛化到所有操作。
// 位于 ../mlir/examples/toy/Ch4/mlir/ShapeInferencePass.cpp
// 需要实现全局的pass都要继承并重写mlir::OperationPass<FuncOp>runOnOperation()
class ShapeInferencePass
: public mlir::PassWrapper<ShapeInferencePass, OperationPass<FuncOp>> {
void runOnOperation() override {
FuncOp function = getOperation();
...
// 算法流程:
// 1.将所有需要进行形状推断的operation加入一个worklist
// 2.遍历这个worklist,对于每个operation,从参数类型推断其输出的形状
// 3.直到worklist为空
}
};
// 通过函数实例化 ShapeInferencePass
std::unique_ptr<mlir::Pass> mlir::toy::createShapeInferencePass() {
return std::make_unique<ShapeInferencePass>();
}
3. Lowering 过程
本节的3.1部分对应Chapter 5: Partial Lowering to Lower-Level Dialects for Optimization - MLIR (llvm.org)
本节的3.2部分对应Chapter 6: Lowering to LLVM and CodeGeneration - MLIR
在编译器一系列转换程序的过程中,越来越多的高层次的简明信息被打散,转换为低层次的细碎指令,这个过程被称为代码表示递降lowerinng ,与之相反的过程被称为代码表示递升raising 。raising远比lowering困难,因为需要在庞杂的细节中找出宏观脉络。
lowering 过程中越晚执行的转换越有结构劣势,因为缺乏高层次信息。
lowering 主要是为了更贴近硬件做代码生成和做硬件相关的优化。
每次
转换遍历(pass)都需要保持原子性,在其内部可能会临时违反源程序语义,但在每个转换遍历之后,中间表示应该是正确的。编译器依赖每个遍历之后的中间表示验证 (validation) 来保证正确性。
在保证转换的正确性之后,才可进行优化。
3.1 从 MLIR 表达式进行部分 Lowering

MLIR 中有许多不同的 Dialect,lowering 过程其实就是在各种 Dialect 之间转化,而 MLIR 提供了一套统一的 DialectConversion 框架来实现不同 Dialect 之间的转化。
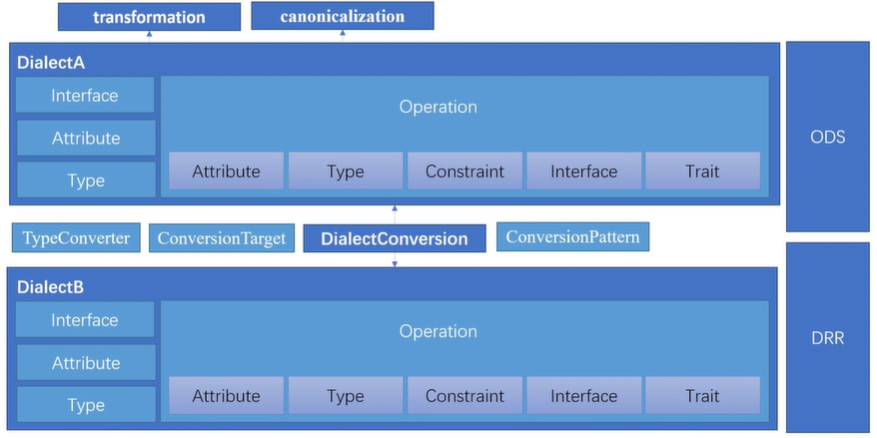
- 要使用 DialectConversion 框架需要 Three Components
(1)Conversion Target(转换目标)
对转换目标 Dialect 进行合法化(legal),对当前的 Dialect 进行非法化(illegal)。主要完成以下三件事:
- Legal Dialects (target dialects)
target.addLegalDialect<mlir::AffineOpsDialect, mlir::StandardOpsDialect>();将 AffineOpsDialect 和 StandardOpsDialect 添加为合法的目标
- Illegal Dialects (fail if not converted)
target.addIllegalDIalect<ToyDialect>();由于 Toy Dialect 已经转换走了,就将其添加为非法的目标
- Legal and Illegal Ops
target.addLegalOp<PrintOp>();// 将保留操作添加为合法操作
target.addIllegalOp<BranchOp>Op;// 将废弃操作添加为非法操作(2)Conversion Pattern(或者称为Rewrite Pattern)
上一步相当于转换了 namespaces,但并没有对其中的 operation 进行转换,需要对 operation 进行匹配和重写,将 illegal operation 转换为 legal operation。(实现operation从源dialect到目标dialect的映射)
(3) Type Conversion(类型转换器)
当前 dialect 中若存在某些特定的数据类型,则需要转换到目标 dialect 中相应的数据类型。
- DialectConversion 框架的转换有 Tow Modes
(1)Partial: Not all input operations have to be legalized to the target
当前 Dialect 中某些 operation 在 lowering 中先进行保留(保留部分之前的信息)
(2)Full: All input operations have to be legalized to the target
当前 Dialect 中全部 operation 在 lowering 中全部去除(类似转换到 LLVM IR)
本节标题的部分lowering 意味着:从一个高抽象级别的 Dialect 到一个低抽象级别的 Dialect 过程中,可以只 lowering 其中一部分 operation,剩下的 operation 只需要升级与其他 operation 共存。现在以对 transformation 后的 MLIR 表达式进行 lowering为例:

// toy 源码
def multiply_transpose(a, b){
return transpose(a) * transpose(b);
}
def main() {
var a<2, 3> = [[1, 2, 3], [4, 5, 6]];
var b<2, 3> = [1, 2, 3, 4, 5, 6];
var c = multiply_transpose(a, b);
print(c);
}
// transformation 后的 MLIR 表达式
toy.func @main() {
%0 = toy.constant dense<[[1.000000e+00, 2.000000e+00, 3.000000e+00], [4.000000e+00, 5.000000e+00, 6.000000e+00]]> : tensor<2x3xf64>
%1 = toy.transpose(%0 : tensor<2x3xf64>) to tensor<3x2xf64>
%2 = toy.mul %1, %1 : tensor<3x2xf64>
toy.print %2 : tensor<3x2xf64>
toy.return
}
- 第一步:定义转换目标(Conversion Target)
为了实现进一步优化,将 Toy Dialect 中计算密集操作转换为 Affine Dialect 和 Standard Dialect(这两个都是 mlir 内置的 Dialect)的组合,但由于 Affine Dialect 中没有 print operation,就需要将 Toy Dialect 中的 print operation 保留并重写。
// 位于 ../mlir/examples/toy/Ch5/mlir/LowerToAffineLoops.cpp
void ToyToAffineLoweringPass::runOnFunction() {
mlir::ConversionTarget target(getContext());
// 将AffineOpsDialect和StandardOpsDialect添加为合法的目标
target.addLegalDialect<mlir::AffineDialect, mlir::memref::MemRefDialect,
mlir::StandardOpsDialect>();
// 将源dialect(ToyDialect)添加为非法的目标
target.addIllegalDialect<ToyDialect>();
// 保留ToyDialect中的print operation,后续重写
target.addLegalOp<PrintOp>();
...
}
- 第二步:明确转换模式(Conversion Patterns)
这一步将使用 ConversionPattern实现对 operation 的匹配和重写,把 illegal operation 转换为 legal operation。官方文档以转换 ToyDialect 中 transpose 操作为例。
ConversionPattern 类似于 RewritePatterns 的转换逻辑,但要多接受一个的操作数(operands)参数,用来在处理类型转换的时候,对旧类型匹配。
// 位于 ../mlir/examples/toy/Ch5/mlir/LowerToAffineLoops.cpp
// 该程序将toy.transpose转换(lower)为AffineLoops
struct TransposeOpLowering : public mlir::ConversionPattern {
TransposeOpLowering(mlir::MLIRContext *ctx)
: mlir::ConversionPattern(TransposeOp::getOperationName(), 1, ctx) {}
// 匹配和重写函数
mlir::LogicalResult
matchAndRewrite(mlir::Operation *op, ArrayRef<mlir::Value> operands,
mlir::ConversionPatternRewriter &rewriter) const final {
auto loc = op->getLoc();
// 实现将当前的操作lower到一组仿射循环
// memRef是AffineDialect的操作数类型,类似于缓冲区
lowerOpToLoops(
op, operands, rewriter,
[loc](mlir::PatternRewriter &rewriter,
ArrayRef<mlir::Value> memRefOperands,
ArrayRef<mlir::Value> loopIvs) {
// TransposeOpAdaptor 是在ODS框架执行后自动生成的
TransposeOpAdaptor transposeAdaptor(memRefOperands);
mlir::Value input = transposeAdaptor.input();
SmallVector<mlir::Value, 2> reverseIvs(llvm::reverse(loopIvs));
return rewriter.create<mlir::AffineLoadOp>(loc, input, reverseIvs);
});
return success();
}
};
- 第三步:将第二步定义的转换模式(TransposeOpLowering)添加到lower过程中用到的 patterns list
// 位于 ../mlir/examples/toy/Ch5/mlir/LowerToAffineLoops.cpp
void ToyToAffineLoweringPass::runOnOperation() {
...
// the set of patterns that will lower the Toy operations.
mlir::RewritePatternSet patterns(&getContext());
patterns.add<..., TransposeOpLowering>(&getContext());
...
}
- 第四步:确定 lower 模式 —— Partial
DialectConversion 框架提供了两种模式的 lowering,Partial Method 和 Full Method,由于需要将 Toy Dialect 中的 print operation 保留并重写,所以这里使用 Partial Method 执行。
// 位于 ../mlir/examples/toy/Ch5/mlir/LowerToAffineLoops.cpp
void ToyToAffineLoweringPass::runOnOperation() {
...
if (mlir::failed(mlir::applyPartialConversion(getOperation(), target, patterns)))
signalPassFailure();
}
- 第五步:将保留的 toy.print 进行重写,以匹配数据格式
在这一步需要将保留的 toy.print 的输出格式 “transform from a value-type, TensorType, to an allocated (buffer-like) type, MemRefType”。
官方文档中提及到有三种实现方法:
- Generate operations from the buffer
loadremains the definition of the operation unchanged, but involves a full copy
- Generate a new version of that operates on the lowered type
toy.printno hidden, unnecessary copy to the optimizer, but needs another operation definition
- Update to allow for operating on the lowered type
toy.printrequires mixing abstraction levels in the dialect
// 为了简单使用的是第三种实现方法
// 位于 ../mlir/examples/toy/Ch5/mlir/Ops.td
def PrintOp : Toy_Op<"print"> {
...
// 之前 let arguments = (ins F64Tensor:$input);
// 添加对 F64MemRef 类型的输出支持
let arguments = (ins AnyTypeOf<[F64Tensor, F64MemRef]>:$input);
}
- 第六步:将定义好的 lowering 添加到 optimization pipeline 中
// 位于 ../mlir/examples/toy/Ch5/toyc.cpp
// 使用 PassManger 模块添加优化工序
if (isLoweringToAffine) {
// 若命令行中指令是 -emit=mlir-affine,则为真
mlir::OpPassManager &optPM = pm.nestmlir::FuncOp();
// LowerToAffine优化,规范化框架优化,公共子表达式消除优化
optPM.addPass(mlir::toy::createLowerToAffinePass());
optPM.addPass(mlir::createCanonicalizerPass());
optPM.addPass(mlir::createCSEPass());
...
}
执行toyc-ch5 ../../test/Examples/Toy/Ch5/affine-lowering.mlir -emit=mlir-affine -opt,得到 lowering 后的结果
func.func @main() {
%cst = arith.constant 1.000000e+00 : f64
%cst_0 = arith.constant 2.000000e+00 : f64
%cst_1 = arith.constant 3.000000e+00 : f64
%cst_2 = arith.constant 4.000000e+00 : f64
%cst_3 = arith.constant 5.000000e+00 : f64
%cst_4 = arith.constant 6.000000e+00 : f64
// Allocating buffers for the inputs and outputs.
%0 = memref.alloc() : memref<3x2xf64>
%1 = memref.alloc() : memref<3x2xf64>
%2 = memref.alloc() : memref<2x3xf64>
// Initialize the input buffer with the constant values.
affine.store %cst, %2[0, 0] : memref<2x3xf64>
affine.store %cst_0, %2[0, 1] : memref<2x3xf64>
affine.store %cst_1, %2[0, 2] : memref<2x3xf64>
affine.store %cst_2, %2[1, 0] : memref<2x3xf64>
affine.store %cst_3, %2[1, 1] : memref<2x3xf64>
affine.store %cst_4, %2[1, 2] : memref<2x3xf64>
// Load the transpose value from the input buffer and store it into the
// next input buffer.
affine.for %arg0 = 0 to 3 {
affine.for %arg1 = 0 to 2 {
%3 = affine.load %2[%arg1, %arg0] : memref<2x3xf64>
affine.store %3, %1[%arg0, %arg1] : memref<3x2xf64>
}
}
// Multiply and store into the output buffer.
affine.for %arg0 = 0 to 3 {
affine.for %arg1 = 0 to 2 {
%3 = affine.load %1[%arg0, %arg1] : memref<3x2xf64>
%4 = affine.load %1[%arg0, %arg1] : memref<3x2xf64>
%5 = arith.mulf %3, %4 : f64
affine.store %5, %0[%arg0, %arg1] : memref<3x2xf64>
}
}
// Print the value held by the buffer.
toy.print %0 : memref<3x2xf64>
memref.dealloc %2 : memref<2x3xf64>
memref.dealloc %1 : memref<3x2xf64>
memref.dealloc %0 : memref<3x2xf64>
return
}
- 第七步:在 Affine Dialect 中进行优化
上一步中的初级优化是正确的,但产生了一些冗余负载(reluctant loads),可以将 LoopFunsionPass 和 MemRefDataFlowOptPass 添加到 optimization pipeline中进一步优化。
// 位于 ../mlir/examples/toy/Ch5/toyc.cpp
if (isLoweringToAffine) {
mlir::OpPassManager &optPM = pm.nestmlir::FuncOp();
optPM.addPass(mlir::toy::createLowerToAffinePass());
optPM.addPass(mlir::createCanonicalizerPass());
optPM.addPass(mlir::createCSEPass());
if (enableOpt) {
// 消除冗余load操作
optPM.addPass(mlir::createLoopFusionPass());
// 使转置和矩阵相乘在一个循环中完成
optPM.addPass(mlir::createMemRefDataFlowOptPass());
}
}
执行toyc-ch5 test/Examples/Toy/Ch5/affine-lowering.mlir -emit=mlir-affine -opt,得到 lowering 后的结果
func.func @main() {
%cst = arith.constant 1.000000e+00 : f64
%cst_0 = arith.constant 2.000000e+00 : f64
%cst_1 = arith.constant 3.000000e+00 : f64
%cst_2 = arith.constant 4.000000e+00 : f64
%cst_3 = arith.constant 5.000000e+00 : f64
%cst_4 = arith.constant 6.000000e+00 : f64
// Allocating buffers for the inputs and outputs.
%0 = memref.alloc() : memref<3x2xf64>
%1 = memref.alloc() : memref<2x3xf64>
// Initialize the input buffer with the constant values.
affine.store %cst, %1[0, 0] : memref<2x3xf64>
affine.store %cst_0, %1[0, 1] : memref<2x3xf64>
affine.store %cst_1, %1[0, 2] : memref<2x3xf64>
affine.store %cst_2, %1[1, 0] : memref<2x3xf64>
affine.store %cst_3, %1[1, 1] : memref<2x3xf64>
affine.store %cst_4, %1[1, 2] : memref<2x3xf64>
affine.for %arg0 = 0 to 3 {
affine.for %arg1 = 0 to 2 {
// Load the transpose value from the input buffer.
%2 = affine.load %1[%arg1, %arg0] : memref<2x3xf64>
// Multiply and store into the output buffer.
%3 = arith.mulf %2, %2 : f64
affine.store %3, %0[%arg0, %arg1] : memref<3x2xf64>
}
}
// Print the value held by the buffer.
toy.print %0 : memref<3x2xf64>
memref.dealloc %1 : memref<2x3xf64>
memref.dealloc %0 : memref<3x2xf64>
return
}
3.2 混合 Dialect 表达式 Lowering 到 LLVM IR
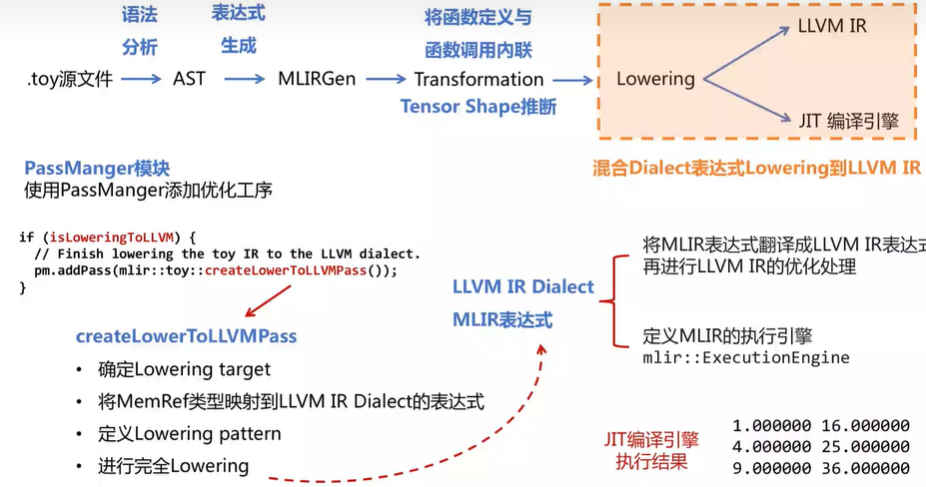
3.1节中已经将 Toy Dialect 转换为 Affine Dialect、Standard Dialect以及包含 Toy Dialect 中的 print operation 的混合操作,需要全部 lowering 到 LLVM Dialect,再 lowering 到 LLVM IR 接入到 LLVM 后端进行 CodeGen。(LLVM Dialcet属于MLIR的Dialect,LLVM IR是LLVM自己的IR)
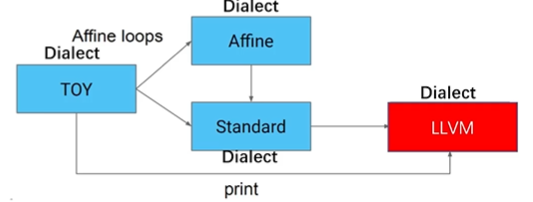
- 第一步:lower
toy.print
“We have already lowered all but the toy.print operations, we will lower this operation to a non-affine loop nest that invokes printf for each element.”
Dialect 转换框架支持传递降低(transitive lowering),不需要直接生成在 LLVM Dialect。通过传递降低,可以应用多种模式来使操作完全合法化。
// 位于 ../mlir/examples/toy/Ch6/mlir/LowerToLLVM.cpp
static FlatSymbolRefAttr getOrInsertPrintf(PatternRewriter &rewriter,
ModuleOp module,
LLVM::LLVMDialect *llvmDialect) {
auto *context = module.getContext();
if (module.lookupSymbol<LLVM::LLVMFuncOp>("printf"))
return SymbolRefAttr::get("printf", context);
// 为printf创建函数声明 signature * `i32 (i8*, ...)`
auto llvmI32Ty = IntegerType::get(context, 32);
auto llvmI8PtrTy = LLVM::LLVMPointerType::get(IntegerType::get(context, 8));
auto llvmFnType = LLVM::LLVMFunctionType::get(llvmI32Ty, llvmI8PtrTy, /*isVarArg=*/true);
// 将printf函数插入父模块的主体中
PatternRewriter::InsertionGuard insertGuard(rewriter);
rewriter.setInsertionPointToStart(module.getBody());
rewriter.create<LLVM::LLVMFuncOp>(module.getLoc(), "printf", llvmFnType);
return SymbolRefAttr::get("printf", context);
}
- 第二步:Conversion Target
“For this conversion, aside from the top-level module, we will be lowering everything to the LLVM dialect.”
// 位于 ../mlir/examples/toy/Ch6/mlir/LowerToLLVM.cpp
mlir::ConversionTarget target(getContext());
target.addLegalDialect<LLVM::LLVMDialect>();
target.addLegalOp<ModuleOp, ModuleTerminatorOp>();
- 第三步:Type Conversion
接下里的 lower 过程还需将当前所使用的 MemRef 类型转换为 LLVM 中的表示形式,MLIR 中已经定义好很多 typeConverter 用于复用。
// 位于 ../mlir/examples/toy/Ch6/mlir/LowerToLLVM.cpp
LLVMTypeConverter typeConverter(&getContext());
- 第四步:Conversion Patterns
// 位于 ../mlir/examples/toy/Ch6/mlir/LowerToLLVM.cpp
mlir::RewritePatternSet patterns(&getContext());
// 将 AffineDialect lower到 StandardDialect
mlir::populateAffineToStdConversionPatterns(patterns, &getContext());
// 将 Loop lower到non-affine loop nest (Standard Dialect)
mlir::populateLoopToStdConversionPatterns(patterns, &getContext());
// 将 StandardDialect lower到 LLVMDialect
mlir::populateStdToLLVMConversionPatterns(typeConverter, patterns);
// Toy Dialect中仅存的toy.print需要独立编写PrintOpLowering
// 类似于上一节第二步中的TransposeOpLowering
patterns.add<PrintOpLowering>(&getContext());
- 第五步:确定 lower 模式 —— Full
// 位于../mlir/examples/toy/Ch6/mlir/LowerToLLVM.cpp
void ToyToLLVMLoweringPass::runOnFunction() {
...
auto module = getOperation();
if (failed(applyFullConversion(module, target, std::move(patterns))))
signalPassFailure();
}
- 第六步:将定义好的 lowering 添加到 optimization pipeline 中
// 位于 ../mlir/examples/toy/Ch6/toyc.cpp
if(isLoweringToLLVM){
pm.addPass(mlir::toy::createLowerToLLVMPass());
}
执行toyc-ch6 ../../test/Examples/Toy/Ch6/llvm-lowering.mlir -emit=mlir-llvm,最终会获得的 LLVM Dialect 格式的 MLIR表达式如下
// LLVM IR Dialect 形式的 MLIR表达式
module{
llvm.func @free(!11vm<"i8*">)
llvm.mlir.global internal constant @nl("\0A\00")
llvm.mlir.global internal constant @frmt_spec("%f\00")
llvm.func @printf(!llvm<"i8*">, ...) -> !llvm.i32
llvm.func @malloc(!llvm.i64) -> !llvm<"i8*"> llvm.func @main(){
%0=llvm.mlir.constant(1.000000e+00 : f64) : !llvm.double
%1=llvm.mlir.constant(2.000000e+00 : f64) : !llvm.double
%2=llvm.mlir.constant(3.000000e+00 : f64) : !llvm.double
...
}
- 第七步:从LLVM Dialect到LLVM IR,再到CodeGen
现在已经转换到 LLVM Dialect,最终需要lower到 LLVM IR,使用 MLIR 内置的转换函数translateModuleToLLVMIR即可。然后利用 LLVM tool chain 即可完成多后端 CodeGen。
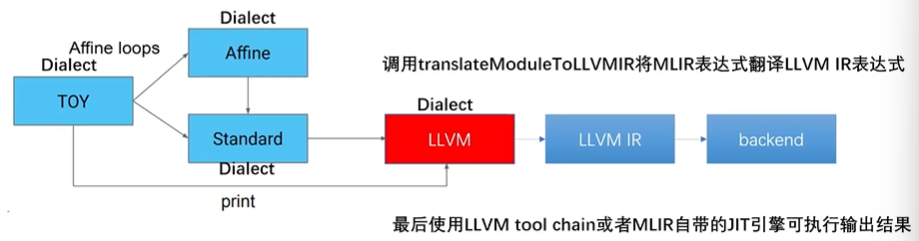
// 生成的LLVM IR表达式
define void @main() local_unnamed_addr #1{
.preheader3:
%θ = tail call 132 (i8*, ...) @printf(i8* nonnull dereferenceable(1) getelementptr inbounds ([4 x i8], [4xi8]*@frmt_spec,i64 0,i64 0),double 1.000000e+00)
%1 = tail call i32 (i8*, ...) @printf(i8* nonnull dereferenceable(1) getelementptr inbounds([4 x i8],[4 x i8]*@frmt_spec,i64 0,i64 0),double 1.600000e+01)
%putchar=tail call i32 @putchar(132 10)
...
}
总结
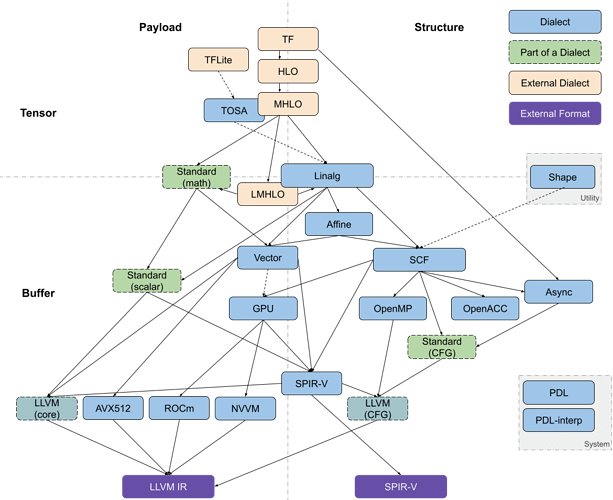
本文介绍的 Toy 接入 MLIR 流程本质上还是高级语言的转换流程,但目前 MLIR 在人工智能领域应用较热,二者的转换前端区别较大,一个是抽象语法树(AST),一个是计算图IR(Computation Graph IR)。下图是以 Tensorflow 为例的转换流程。具体的流程为可参考 Codegen Dialect Overview - MLIR - LLVM Discussion Forums
再附上--emit=<value>的使用方法,使用./toyc-ch6 -h来查询。
--emit=<value> - Select the kind of output desired
=ast - output the AST dump
=mlir - output the MLIR dump
=mlir-affine - output the MLIR dump after affine lowering
=mlir-llvm - output the MLIR dump after llvm lowering
=llvm - output the LLVM IR dump
=jit - JIT the code and run it by invoking the main
END
上一篇:MLIR初识 —— Dialect及Operation详解
下一篇:MLIR再深入 —— CodeGen 总结
Toy Tutorial - MLIR (llvm.org)
MLIR Toy Tutorials 第三章 高级语义分析和转换
MLIR Toy Tutorials 第四章 使用接口启用泛化转换














 1405
1405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









