







数据集 ImageFolder
if name == 'image':
dataset = datasets.ImageFolder(data_dir, transform)
nlabels = len(dataset.classes)
def __init__(self, root, transform=None, target_transform=None,
loader=default_loader, is_valid_file=None):
super(ImageFolder, self).__init__(root, loader, IMG_EXTENSIONS if is_valid_file is None else None,
transform=transform,
target_transform=target_transform,
is_valid_file=is_valid_file)
self.imgs = self.samples
get_nsamples
取N个样本
def get_nsamples(data_loader, N):
x = []
y = []
n = 0
while n < N:
x_next, y_next = next(iter(data_loader))
x.append(x_next)
y.append(y_next)
n += x_next.size(0)
x = torch.cat(x, dim=0)[:N]
y = torch.cat(y, dim=0)[:N]
return x, y
x_next, y_next = next(iter(data_loader))

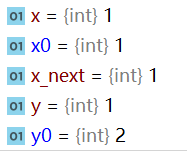
torch.cat(y, dim=0)
竖过来叠一起

get_ydist
随机取一类
def get_ydist(nlabels, device=None):
logits = torch.zeros(nlabels, device=device)
ydist = distributions.categorical.Categorical(logits=logits)
# Add nlabels attribute
ydist.nlabels = nlabels
return ydist
torch.zeros
都是0的元素
torch.distributions.categorical(probs)
按照probs的概率,在相应的位置进行采样,采样返回的是该位置的整数索引。
输出:
probs = torch.FloatTensor([0.9,0.2])
D = Categorical(probs)
for i in range(5):
print(D.sample())

get_zdist
def get_zdist(dist_name, dim, device=None):
# Get distribution
if dist_name == 'uniform':
low = -torch.ones(dim, device=device)
high = torch.ones(dim, device=device)
zdist = distributions.Uniform(low, high)
elif dist_name == 'gauss':
mu = torch.zeros(dim, device=device)
scale = torch.ones(dim, device=device)
zdist = distributions.Normal(mu, scale)
else:
raise NotImplementedError
# Add dim attribute
zdist.dim = dim
return zdist

a=zdist.sample()
a.size() #256
Evaluator
# Evaluator
NNN = 8000
x_real, _ = utils.get_nsamples(train_loader, NNN)
evaluator = Evaluator(generator_test, zdist, ydist,
batch_size=batch_size, device=device,
fid_real_samples=x_real, inception_nsamples=NNN, fid_sample_size=NNN)
class Evaluator(object):
def __init__(self, generator, zdist, ydist, batch_size=64,
inception_nsamples=10000, device=None, fid_real_samples=None,
fid_sample_size=10000):
self.generator = generator
self.zdist = zdist
self.ydist = ydist
self.inception_nsamples = inception_nsamples
self.batch_size = batch_size
self.device = device
if fid_real_samples is not None:
self.fid_real_samples = fid_real_samples.numpy() #真样本
self.fid_sample_size = fid_sample_size #样本数
def compute_inception_score(self):
self.generator.eval()
imgs = []
while(len(imgs) < self.inception_nsamples):
ztest = self.zdist.sample((self.batch_size,))
ytest = self.ydist.sample((self.batch_size,))
samples, _ = self.generator(ztest, ytest)
samples = [s.data.cpu().numpy() for s in samples]
imgs.extend(samples)
inception_imgs = imgs[:self.inception_nsamples]
score, score_std = inception_score(
inception_imgs, device=self.device, resize=True, splits=10,
batch_size=self.batch_size)
fid_imgs = np.array(imgs[:self.fid_sample_size])
if self.fid_real_samples is not None:
fid = calculate_fid_given_images(
self.fid_real_samples,
fid_imgs,
batch_size=self.batch_size,
cuda=True)
return score, score_std, fid
def create_samples(self, z, y=None):
self.generator.eval()
batch_size = z.size(0)
# Parse y
if y is None:
y = self.ydist.sample((batch_size,))
elif isinstance(y, int):
y = torch.full((batch_size,), y,
device=self.device, dtype=torch.int64)
# Sample x
with torch.no_grad():
x = self.generator(z, y)
return x
Trainer
# Trainer
trainer = Trainer(
generator, discriminator, g_optimizer, d_optimizer,
gan_type=config['training']['gan_type'],
reg_type=config['training']['reg_type'],
reg_param=config['training']['reg_param'],
D_fix_layer=config['discriminator']['layers']
)
training:
gan_type: standard
reg_type: real
reg_param: 10.
discriminator:
name: resnet2
layers: 2
class Trainer(object):
def __init__(self, generator, discriminator, g_optimizer, d_optimizer,
gan_type, reg_type, reg_param, D_fix_layer=0, data_fix='ImageNet'):
self.generator = generator
self.discriminator = discriminator
self.g_optimizer = g_optimizer
self.d_optimizer = d_optimizer
# self.G_fix_layer = G_fix_layer
self.D_fix_layer = D_fix_layer
self.data_fix = data_fix
self.gan_type = gan_type
self.reg_type = reg_type
self.reg_param = reg_param
def generator_trainstep(self, y, z, FLAG=500):
assert(y.size(0) == z.size(0))
# toggle_grad(self.generator, True)
toggle_grad_D(self.discriminator, False, self.D_fix_layer)
self.generator.train() #切换成train模式
self.discriminator.train()
self.g_optimizer.zero_grad()
x_fake, loss_w = self.generator(z, y)
d_fake = self.discriminator(x_fake, y)
gloss = self.compute_loss(d_fake, 1)
gloss.backward()
self.g_optimizer.step()
# print('loss_w:---', loss_w)
return gloss.item(), x_fake.detach()
def discriminator_trainstep(self, x_real, y, x_fake0):
toggle_grad_D(self.discriminator, True, self.D_fix_layer)
self.generator.train()
self.discriminator.train()
self.d_optimizer.zero_grad()
# On real data
x_real.requires_grad_()
d_real = self.discriminator(x_real, y)
dloss_real = self.compute_loss(d_real, 1)
if self.reg_type == 'real' or self.reg_type == 'real_fake':
dloss_real.backward(retain_graph=True)
reg = self.reg_param * compute_grad2(d_real, x_real).mean()
reg.backward()
else:
dloss_real.backward()
# # On fake data
# with torch.no_grad():
# x_fake = self.generator(z, y)
#
# x_fake0 = x_fake.detach() * 1.0
x_fake0.requires_grad_()
d_fake = self.discriminator(x_fake0, y)
dloss_fake = self.compute_loss(d_fake, 0)
if self.reg_type == 'fake' or self.reg_type == 'real_fake':
dloss_fake.backward(retain_graph=True)
reg = self.reg_param * compute_grad2(d_fake, x_fake0).mean()
reg.backward()
else:
dloss_fake.backward()
if self.reg_type == 'wgangp':
reg = self.reg_param * self.wgan_gp_reg(x_real, x_fake0, y)
reg.backward()
elif self.reg_type == 'wgangp0':
reg = self.reg_param * self.wgan_gp_reg(x_real, x_fake0, y, center=0.)
reg.backward()
self.d_optimizer.step()
toggle_grad_D(self.discriminator, False, self.D_fix_layer)
# Output
dloss = (dloss_real + dloss_fake)
if self.reg_type == 'none':
reg = torch.tensor(0.)
return dloss.item(), reg.item()
def compute_loss(self, d_out, target):
targets = d_out.new_full(size=d_out.size(), fill_value=target)
if self.gan_type == 'standard':
loss = F.binary_cross_entropy_with_logits(d_out, targets)
elif self.gan_type == 'wgan':
loss = (2*target - 1) * d_out.mean()
else:
raise NotImplementedError
return loss
def wgan_gp_reg(self, x_real, x_fake, y, center=1.):
batch_size = y.size(0)
eps = torch.rand(batch_size, device=y.device).view(batch_size, 1, 1, 1)
x_interp = (1 - eps) * x_real + eps * x_fake
x_interp = x_interp.detach()
x_interp.requires_grad_()
d_out = self.discriminator(x_interp, y)
reg = (compute_grad2(d_out, x_interp).sqrt() - center).pow(2).mean()
return reg
训练生成器
for x_real, y in train_loader:
y.clamp_(None, nlabels-1)
# Generators updates
z = zdist.sample((batch_size,))
gloss, x_fake = trainer.generator_trainstep(y, z, FLAG + 1.0)
FLAG = FLAG * 0.9995
x_real :真实图片
generator_trainstep
y没用
x_fake, loss_w = self.generator(z, y)
d_fake = self.discriminator(x_fake, y)
gloss = self.compute_loss(d_fake, 1)
gloss.backward()
Build models
# Build models
generator = Generator(
z_dim=config['z_dist']['dim'],
nlabels=config['data']['nlabels'],
size=config['data']['img_size'],
**config['generator']['kwargs']
)
discriminator = Discriminator(
config['discriminator']['name'],
nlabels=config['data']['nlabels'],
size=config['data']['img_size'],
**config['discriminator']['kwargs']
)
resnet2_AdaFM.Generator
class Generator(nn.Module):
def __init__(self, z_dim, nlabels, size, embed_size=256, nfilter=64, **kwargs):
super().__init__()
s0 = self.s0 = 4
nf = self.nf = nfilter
self.z_dim = z_dim
small_nf = self.small_nf = 64
# Submodules
self.small_embedding = nn.Embedding(nlabels, embed_size)
self.small_fc = nn.Linear(z_dim, 8 * small_nf * s0 * s0)
# self.small_net_1 = StyleBlock_firstLayer(8 * small_nf, 8 * small_nf, initial=True)
self.small_net_2 = StyleBlock_noise(8 * small_nf, 8 * small_nf, upsample=True)
self.small_net_3 = StyleBlock_noise(8 * small_nf, 8 * small_nf, upsample=True)
# self.small_Attn = Self_Attn(8 * small_nf)
self.small_H = AdaptiveInstanceNorm_H(8 * small_nf, 16)
# self.resnet_3_0 = ResnetBlock(8*nf, 4*nf)
# self.resnet_3_1 = ResnetBlock(4*nf, 4*nf)
#
# self.resnet_4_0 = ResnetBlock(4*nf, 2*nf)
# self.resnet_4_1 = ResnetBlock(2*nf, 2*nf)
#
# self.resnet_5_0 = ResnetBlock(2*nf, 1*nf)
# self.resnet_5_1 = ResnetBlock(1*nf, 1*nf)
self.resnet_3_0 = ResnetBlock_adafm(8 * nf, 4 * nf)
self.resnet_3_1 = ResnetBlock_adafm(4 * nf, 4 * nf)
# self.small_Attn = Self_Attn(4 * nf)
self.resnet_4_0 = ResnetBlock_adafm(4 * nf, 2 * nf)
self.resnet_4_1 = ResnetBlock_adafm(2 * nf, 2 * nf)
self.resnet_5_0 = ResnetBlock_adafm(2 * nf, 1 * nf)
self.resnet_5_1 = ResnetBlock_adafm(1 * nf, 1 * nf)
self.conv_img = nn.Conv2d(nf, 3, 3, padding=1)
layers = [PixelNorm()]
# layers = []
layers.append(EqualLinear(z_dim, style_dim))
layers.append(nn.LeakyReLU(0.2))
for i in range(7):
layers.append(EqualLinear(style_dim, style_dim))
layers.append(nn.LeakyReLU(0.2))
self.small_style = nn.Sequential(*layers)
def forward(self, z, y, FLAG=500):
assert (z.size(0) == y.size(0))
batch_size = z.size(0)
if y.dtype is torch.int64:
yembed = self.small_embedding(y)
else:
yembed = y
yembed = yembed / torch.norm(yembed, p=2, dim=1, keepdim=True)
yz = torch.cat([z, yembed], dim=1)
style_w = self.small_style(z)
# print('yembed ============ ', yembed.shape)
out = self.small_fc(z)
out = out.view(batch_size, 8 * self.small_nf, self.s0, self.s0)
# out = self.small_net_1(z, style_w)
# out = F.interpolate(out, scale_factor=2)
out = self.small_net_2(out, style_w)
# out = F.interpolate(out, scale_factor=2)
out_h = self.small_net_3(out, style_w)
# out_h = self.small_Attn(out_h)
out_h = self.small_H(out_h)
out = F.interpolate(out_h, scale_factor=2)
out = self.resnet_3_0(out)
out = self.resnet_3_1(out)
# out = self.small_Attn(out)
out = F.interpolate(out, scale_factor=2)
out = self.resnet_4_0(out)
out = self.resnet_4_1(out)
out = F.interpolate(out, scale_factor=2)
out = self.resnet_5_0(out)
out = self.resnet_5_1(out)
out0 = self.conv_img(actvn(out))
out = torch.tanh(out0)
loss_w = style_w.pow(2).sum(1)
return out, loss_w
Discriminator
class Discriminator(nn.Module):
def __init__(self, z_dim, nlabels, size, embed_size=256, nfilter=64, **kwargs):
super().__init__()
self.embed_size = embed_size
s0 = self.s0 = size // 32
nf = self.nf = nfilter
ny = nlabels
# Submodules
self.conv_img = nn.Conv2d(3, 1 * nf, 3, padding=1)
self.resnet_0_0 = ResnetBlock(1 * nf, 1 * nf)
self.resnet_0_1 = ResnetBlock(1 * nf, 2 * nf)
self.resnet_1_0 = ResnetBlock(2 * nf, 2 * nf)
self.resnet_1_1 = ResnetBlock(2 * nf, 4 * nf)
self.resnet_2_0 = ResnetBlock(4 * nf, 4 * nf)
self.resnet_2_1 = ResnetBlock(4 * nf, 8 * nf)
self.resnet_3_0 = ResnetBlock(8 * nf, 8 * nf)
self.resnet_3_1 = ResnetBlock(8 * nf, 16 * nf)
self.resnet_4_0 = ResnetBlock(16 * nf, 16 * nf)
self.resnet_4_1 = ResnetBlock(16 * nf, 16 * nf)
self.resnet_5_0 = ResnetBlock(16 * nf, 16 * nf)
self.resnet_5_1 = ResnetBlock(16 * nf, 16 * nf)
self.fc = nn.Linear(16 * nf * s0 * s0, nlabels)
print('nlabels ============ ', nlabels)
def forward(self, x, y):
assert (x.size(0) == y.size(0))
batch_size = x.size(0)
out = self.conv_img(x)
out = self.resnet_0_0(out)
out = self.resnet_0_1(out)
out = F.avg_pool2d(out, 3, stride=2, padding=1)
out = self.resnet_1_0(out)
out = self.resnet_1_1(out)
out = F.avg_pool2d(out, 3, stride=2, padding=1)
out = self.resnet_2_0(out)
out = self.resnet_2_1(out)
out = F.avg_pool2d(out, 3, stride=2, padding=1)
out = self.resnet_3_0(out)
out = self.resnet_3_1(out)
out = F.avg_pool2d(out, 3, stride=2, padding=1)
out = self.resnet_4_0(out)
out = self.resnet_4_1(out)
out = F.avg_pool2d(out, 3, stride=2, padding=1)
out = self.resnet_5_0(out)
out = self.resnet_5_1(out)
out = out.view(batch_size, 16 * self.nf * self.s0 * self.s0)
out = self.fc(actvn(out))
# index = torch.LongTensor(range(out.size(0)))
# if y.is_cuda:
# index = index.cuda()
# out = out[index, y]
return out
训练判别器
# Discriminator updates
dloss, reg = trainer.discriminator_trainstep(x_real, y, x_fake)
def discriminator_trainstep(self, x_real, y, x_fake0):
toggle_grad_D(self.discriminator, True, self.D_fix_layer)
self.generator.train()
self.discriminator.train()
self.d_optimizer.zero_grad()
# On real data
x_real.requires_grad_()
d_real = self.discriminator(x_real, y)
dloss_real = self.compute_loss(d_real, 1)
if self.reg_type == 'real' or self.reg_type == 'real_fake':
dloss_real.backward(retain_graph=True)
reg = self.reg_param * compute_grad2(d_real, x_real).mean()
reg.backward()
else:
dloss_real.backward()
# # On fake data
# with torch.no_grad():
# x_fake = self.generator(z, y)
#
# x_fake0 = x_fake.detach() * 1.0
x_fake0.requires_grad_()
d_fake = self.discriminator(x_fake0, y)
dloss_fake = self.compute_loss(d_fake, 0)
if self.reg_type == 'fake' or self.reg_type == 'real_fake':
dloss_fake.backward(retain_graph=True)
reg = self.reg_param * compute_grad2(d_fake, x_fake0).mean()
reg.backward()
else:
dloss_fake.backward()
if self.reg_type == 'wgangp':
reg = self.reg_param * self.wgan_gp_reg(x_real, x_fake0, y)
reg.backward()
elif self.reg_type == 'wgangp0':
reg = self.reg_param * self.wgan_gp_reg(x_real, x_fake0, y, center=0.)
reg.backward()
self.d_optimizer.step()
toggle_grad_D(self.discriminator, False, self.D_fix_layer)
# Output
dloss = (dloss_real + dloss_fake)
if self.reg_type == 'none':
reg = torch.tensor(0.)
return dloss.item(), reg.item()
卷积
conv = nn.Conv2d(3, 2 ** layer * 64, 3, padding=1)
img0 = conv(img)
img0 = F.interpolate(img0, [128 // 2 ** layer, 128 // 2 ** layer])
拼接

torch.save(model.state_dict(), model_cp,_use_new_zipfile_serialization=False) # 训练所有数据后,保存网络的参数















 7688
7688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









