







Point-NeRF: Point-based Neural Radiance Fields
目录
Point-NeRF: Point-based Neural Radiance Fields
4.1. Generating initial point-based radiance fields
4.2. Optimizing point-based radiance fields
6.1. Evaluation on the DTU testing set.
6.2. Evaluation on the NeRF Synthetic dataset.
6.3. Evaluation on the Tanks & Temples and the ScanNet dataset.
Converting COLMAP point clouds to Point-NeRF
论文阅读笔记—CVPR2022—Point-NeRF_CV小小白的博客-CSDN博客
原文链接:https://arxiv.org/abs/2201.08845
代码链接:https://github.com/Xharlie/pointnerf
Abstract
像NeRF[35]这样的体积神经渲染方法可以生成高质量的视图合成结果,但对每个场景进行优化,导致过高的重建时间。另一方面,深度多视图立体视觉方法 deep multi-view stereo methods可以通过直接网络推理快速重建场景几何形状。Point-NeRF结合了这两种方法的优点,利用神经三维点云和相关的神经特征来建模辐射场。通过聚合场景表面附近的神经点特征,可以有效地渲染点网络。此外,Point-NeRF可以通过直接推理初始化预先训练的深度网络,生成神经点云;该点云可以是细化的,超过NeRF的视觉质量。Point-NeRF可以与其他三维重建方法相结合,通过一种新的剪枝和生长机制来处理这些方法中的误差和异常值。在DTU[18]、NeRF Synthetics[35]、ScanNet[11]和the Tanks and Temples[23]数据集上的实验表明,Point-NeRF可以超过现有的方法和达到最先进的结果。
这项工作部分是在Adobe研究公司的实习期间完成的。代码和结果: xharlie.github.io/projects/project sites/pointnerf.
1.Introduction
从图像数据建模真实的场景和渲染逼真的新视角是计算机视觉和图形学中的一个中心问题。NeRF[35]及其扩展[29,32,63]通过对神经辐射场的建模,在这方面取得了巨大的成功。这些方法[35,38,63]通常通过ray marching使用全局MLPs对整个空间重建辐射场。由于每个场景网络拟合缓慢,不必要的采样,导致重构长时间。
我们使用Point-NeRF来解决这个问题,这是一种新的基于点的辐射场表示,它使用三维神经点来建模一个连续的体积辐射场。与纯粹依赖于每个场景拟合的NeRF不同,Point-NeRF可以通过前馈深度神经网络有效地初始化,并跨场景进行预训练。此外,PointNeRF通过利用近似于实际场景几何形状的经典点云,避免了在空场景空间中的光线采样。与其他神经辐射场模型[8,35,53,62]相比,Point-nerf具有更有效的重建效率和更准确的渲染效果。
我们的Point-nerf表示由一个具有每个点神经特征的点云组成:每个神经点编码局部三维场景几何和它周围的外观。先前的基于点的渲染技术[2]使用类似的神经点云,但使用栅格化和在图像空间中操作的2D CNNs进行渲染。相反,我们将这些神经点视为三维中的局部神经基函数来建模一个连续的体积辐射场,从而能够利用可微射线行进进行高质量的渲染。特别是,对于任何三维位置,我们建议使用MLP网络来聚集其邻域内的神经点,以回归该位置的体积密度和与视图相关的辐射。这表示了一个连续的辐射场。
我们提出了一个基于学习的框架来有效地初始化和优化基于点的辐射场。为了生成一个初始场,我们利用深度多视图立体 multi-view stereo (MVS)技术[59],即应用基于成本体积的网络cost-volume-based network来预测深度,然后不投影到三维空间。此外,训练深度CNN从输入图像中提取二维特征图,自然地提供每个点特征。这些来自多个视图的神经点被组合成一个神经点云,形成了场景中一个基于点的辐射场。我们用基于点的体积渲染网络从端到端训练这个点生成模块,以渲染新的视角图像,并以地面真相监督它们。这导致了一个可推广的模型,可以直接预测基于点的辐射场。一旦预测到,初始基于点的场将在短时间内进一步优化每个场景,以实现逼真的渲染。如图1(左)所示,使用Point-NeRF进行21分钟的优化后,其效果优于训练了几天的NeRF模型。
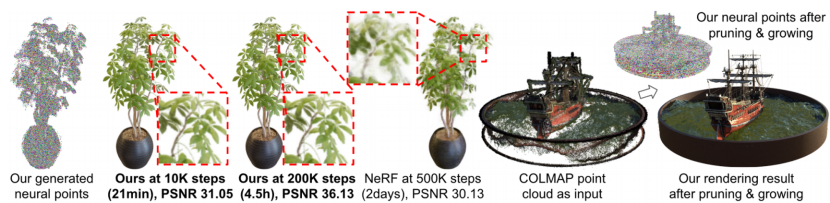
图1。Point-NeRF使用神经三维点来有效地表示和渲染一个连续的辐射体积。基于点的辐射场是可以通过网络从多视角图像中预测的。然后可以对每个场景进行优化,以在几十分钟内实现超过NeRF[35]的重建质量。Point-NeRF还可以利用现成的重建方法,如COLMAP[44],并能够执行点修剪和生长,自动修复这些方法中常见的孔和异常值。
除了使用内置的点云重建外,我们的方法是通用的,也可以基于其他重建技术的点云生成一个辐射场。然而,由COLMAP[44]这样的技术产生的重建点云实际上包含对最终渲染产生不利影响的孔和异常值。为了解决这个问题,我们引入了点生长和剪枝 point growing and pruning作为我们的优化过程的一部分。我们在体积渲染[13]过程中利用几何推理,在高体积密度区域增长点云边界附近的点,在低密度区域修剪点。该机制有效地提高了我们最终的重建和渲染质量。我们在图1(右)中展示了一个例子,我们将COLMAP点转换为辐射场,并成功地填补大孔并产生逼真的效果图。
我们在DTU数据集[18]上训练我们的模型,并在DTU测试场景、NeRF合成、Tanks & Temples[23]和ScanNet[11]场景上进行评估。结果表明,我们的方法可以实现最先进的新视图合成,优于许多现有技术,包括基于点的方法[2],NeRF,NSVF[29],和许多其他可推广的神经方法[8,53,62](见(Tab。1和2)))
2. Related Work
场景表示。传统的和神经方法研究了许多三维场景表示,包括体积[19,25,41,46,56]、点云[1,40,51]、网格[20,52]、深度图[17,28]和隐式函数[9,33,37,60]。近年来,各种神经场景表示在[4,30,47,66]中被提出,推进了新视图合成和现实渲染的技术水平,体积神经辐射场(NeRFs)[35]产生高保真结果。nerf通常被重建为全局mlp[35,38,63],编码整个场景空间;在重建复杂和大规模的场景时,这可能是低效和昂贵的。相反,Point-NeRF是一种局部的神经表示法,它结合了体积辐射场和经典的用于近似场景几何的点云。我们分配细粒度的神经点来建模复杂的局部场景的几何形状和外观,从而获得比NeRF更好的渲染质量(见图6,7)。
具有每体素神经特征[8,16,29]的体素网格也是一种局部神经辐射表示。然而,我们的基于点的表示可以更好地适应实际的表面,从而导致更好的质量。此外,我们直接预测良好的初始神经点特征,绕过了大多数基于体素的方法[16,29]所需要的每个场景的优化。
多视图的重建和渲染。多视图三维重建已被广泛研究和解决的一些结构从运动的[43,49,50]和多视图立体技术[10,14,25,44,59]。点云通常是来自MVS或深度传感器的直接输出,尽管它们通常被转换为网格[21,31]以进行渲染和可视化。网格划分可能会引入错误,并且可能需要基于图像的渲染[6,12,65]来进行高质量的渲染。我们直接使用来自深度MVS的点云来实现现实的渲染。
点云已被广泛应用于渲染中,通常是通过基于栅格化的点溅射,甚至是可微的栅格化模块[26,55]。然而,重建的点云通常会有孔洞和异常值,从而导致渲染中的伪影。基于点的神经渲染方法通过绘制神经特征和使用2D cnns来渲染[2,24,34]来解决这个问题。相比之下,我们的基于点的方法利用了3D体渲染,比以前的基于点的方法获得了明显更好的结果。
神经辐射场。NeRFs[35]在新视角合成方面显示了显著的高质量结果。它们已经被扩展到实现动态场景捕获[27,39]、恢复[3,5]、外观编辑[57]、快速渲染[16,61]和生成模型[7,36,45]。然而,大多数方法[3,27,39,57]仍然遵循原始的NeRF框架,并训练每个场景的mlp来表示辐射场。我们利用场景中具有空间变化的神经特征的神经点来编码其辐射场。这种本地化localized表示可以比网络容量有限的纯mlp建模更复杂的场景内容。更重要的是,我们证明了我们的基于点的神经场可以通过一个预先训练的深度神经网络有效地初始化,该网络可以跨越场景,并导致高效的辐射场重建。先前的工作也提出了可推广的基于辐射场的方法。PixelNeRF[62]和IBRNet[53]在每个采样射线点聚合多视图二维图像特征,回归体渲染特性用于辐射场渲染。相反,我们利用场景表面周围的三维神经点的特征来模拟辐射场。这比PixelNeRF和IBRNet避免了巨大的空空间的采样点,导致更高的渲染质量和更快的辐射场重建。MVSNeRF[8]可以实现非常快的基于体素的辐射场重建。然而,它的预测网络需要固定数量的3幅小基线图像作为输入,因此只能有效地重建局部辐射场。我们的方法可以从任意数量的视图中融合神经点,并实现MVSNeRF无法支持的完整的360个辐射场的快速重建。

3. Point-NeRF Representation
我们提出了我们的新的基于点的辐射场表示,设计用于有效的重建和渲染(见图2(b))。我们从一些准备工作开始。
Volume rendering and radiance fields.
基于物理的体积渲染可以通过可微的射线行进进行数值评估。具体来说,一个像素的亮度可以通过使一条射线穿过像素,沿着光线在{xj|j=1,...,M}处采样M个阴影点,并利用体积密度累积辐射来计算,如:

这里,τ表示体积透射率;σj和rj是xj处每个阴影点j的体积密度和辐射,∆t是相邻阴影样本之间的距离。
辐射场表示在任何三维位置上的体积密度σ和与视图相关的辐射r。NeRF[35]提出使用多层感知器(MLP)来回归这种辐射场。我们建议使用Point-NeRF来利用神经点云来计算体积属性,允许更快和更高质量的渲染。
Point-based radiance field.
我们用![]() 来表示一个神经点云,其中每个点i都位于pi处,并与一个编码局部场景内容的神经特征向量fi相关联。我们还分配每个点一个尺度置信值γi∈[0,1],它表示该点位于实际场景表面附近的可能性。我们从这个点云中回归出辐射场。
来表示一个神经点云,其中每个点i都位于pi处,并与一个编码局部场景内容的神经特征向量fi相关联。我们还分配每个点一个尺度置信值γi∈[0,1],它表示该点位于实际场景表面附近的可能性。我们从这个点云中回归出辐射场。
给定任意三维位置x,我们在一定半径R内查询它周围的K个相邻的神经点。我们的基于点的辐射场可以被抽象为一个神经模块,它将体积密度σ和与视图相关的辐射r(沿着任何观察方向d)回归为:

我们使用一个类似点网的PointNet-like[40]神经网络,具有多个子mlp,来做这种回归。总的来说,我们首先对每个神经点进行神经处理,然后对多点信息进行聚合,得到最终的估计值。
Per-point processing
我们使用一个MLP F来处理每个相邻的神经点,以预测阴影位置x的一个新的特征向量:

本质上,原始特征fi编码了pi周围的局部3D场景内容。这个MLP网络表达了一个局部三维函数,在x输出特定的神经场景描述fi,x,由其局部帧中的神经点建模。相对位置x−p的使用使网络对点平移不变,以更好地泛化。
View-dependent radiance regression回归
我们使用标准的逆距离加权来聚合神经特征fi,x,从这K个相邻点回归,得到一个描述x处场景外观的单一特征fx:

然后MLP,R,从给定观察方向d的特征回归视图相关的辐射:

逆距离权值wi广泛应用于分散数据插值;我们利用它来聚合神经特征,使更近的神经点对阴影计算有更大的贡献。此外,我们在此过程中使用了per-point confidence γ;这在最终的重建中得到了优化,具有稀疏性损失 sparsity loss,给了网络拒绝不必要的点的灵活性。
Density regression
为了计算x处的体积密度σ,我们遵循一个类似的多点聚合。然而,我们首先使用MLP T回归每点的密度σi,然后进行基于距离的逆加权,回归方法如下:

因此,每个神经点直接贡献于体积密度,而点置信度γi与此贡献明确相关。我们在我们的点去除过程中利用了这一点。 (see Sec. 4.2).
讨论
与之前基于神经点的方法[2,34]不同,它将点特征栅格化,然后用二维cnn来渲染它们,我们的表示和渲染完全是三维的。通过使用近似场景几何的点云,我们的表示自然而有效地适应场景表面,并避免在空场景空间中采样阴影位置。对于沿着每条射线的阴影点,我们实现了一个有效的算法来查询相邻的神经点;细节在补充材料中。
4. Point-NeRF Reconstruction
我们现在介绍我们的管道来有效地重建基于点的辐射场。我们首先利用一个跨场景训练的深度神经网络,通过直接网络推理来生成一个基于点的初始场。 (Sec. 4.1).通过我们的点生长和修剪技术,进一步优化了这个初始场,导致了我们最终的高质量的辐射场重建(Sec. 4.2).图3显示了该工作流程,并通过相应的梯度更新进行初始预测和超级优化。

Figure 3. The dash lines虚线 indicate gradient updates for radiance field initialization and per-scene optimization.
4.1. Generating initial point-based radiance fields
给定一组已知的图像I1,...,IQ和一个点云,我们的Point-NeRF表示可以通过优化随机初始化的每点神经特征和具有渲染损失的mlp(类似于NeRF)来重建。然而,这种纯粹的每个场景的优化依赖于一个现有的点云,而且可能会非常慢。因此,我们提出了一个神经生成模块来预测所有的神经点属性,包括点位置pi、神经特征fi和点置信度γi,通过一个前馈神经网络进行有效的重建。对网络的直接推断输出了一个良好的基于点的初始辐射场。然后,可以对初始字段进行微调,以实现高质量的渲染。在很短的时间内,渲染质量会更好或与NeRF相当,后者需要相当长的时间来优化(参见Tab。1和2)。
Point location and confifidence.
我们利用深度MVS方法,使用基于成本体积的3D CNNs cost volume based 3D CNNs [10,59]来生成3D点位置。这种网络能产生高质量的密集几何结构,并能很好地跨领域推广。对于每个在视点q处有摄像机参数Φq的输入图像Iq,我们遵循MVSNet[17],首先通过从相邻视点扭曲二维图像特征,构建平面扫描代价体积 plane-swept cost volume,然后使用深度3D CNNs回归深度概率体积regress depth probability volume。深度图depth map是通过线性组合每个平面的深度值来计算的。我们将depth map未投影unprojected到三维空间,以得到每个视图q的点云{p1,...,pNq}。
由于深度概率描述了点在表面上的可能性,因此我们对深度概率体积进行三线性采样,以获得每个点pi上的点置信度γi。上述过程可以表示为

其中Gp,γ是基于mvsnet的网络。Iq1,Φq1,……是在MVS重建中使用的附加相邻视图;在大多数情况下,我们使用了两个附加的视图。
Point features
我们使用二维CNN Gf从每个图像Iq中提取神经二维图像特征图。这些特征图与Gp,γ的点(深度)预测对齐,并用于直接预测每个点的特征fi如下:
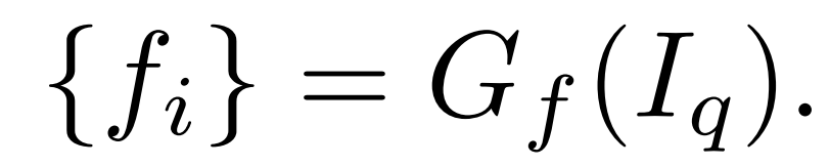
特别是,我们为Gf使用了一个VGG网络架构,它有三个降采样层。我们将不同分辨率的中间特征结合为fi,提供了一个有意义的点描述来建模多尺度场景外观。(见图2.(a))

End-to-end reconstruction
我们从多个视点组合点云来得到我们最终的神经点云。我们训练点生成网络和表示网络,从端到端呈现损失(见图3).这允许我们的
生成模块产生合理的初始辐射场。它还以合理的权重初始化了我们的point-nerf表示中的mlp,显著节省了每个场景的拟合时间。
此外,除了使用完整的生成模块外,我们的管道还支持使用从COLMAP[44]等其他方法重建的点云,其中我们的模型(不包括MVS网络)仍然可以为每个点提供有意义的初始神经特征。详情请参考我们的补充资料。
4.2. Optimizing point-based radiance fields
上述管道可以为新场景输出合理的初始点辐射场。通过可微射线行进,我们可以通过优化神经点云(点特征fi和点置信γi)和我们表示的MLPs,进一步改善辐射场(见图3)。
初始点云,特别是来自外部重建方法(如图1中的元网格或COLMAP)的点云,通常会包含降低渲染质量的孔洞和异常值。在每个场景优化过程中,为了解决这一问题,我们发现直接优化现有点的位置会使训练不稳定,不能填补大洞(见1)。相反,我们应用新的点剪枝和生长技术,逐步提高几何建模和渲染质量。
Point pruning
如Sec. 3所述。我们设计了点置信值γi来描述一个神经点是否靠近一个场景表面。我们利用这些置信度值来修剪不必要的离群点。
请注意, point confidence与体积密度回归中的每点贡献直接相关(Eqn。7);因此,low confidence反映了一个点的局部区域的低体积密度,表明它是空的。因此,我们每10K迭代修剪一次具有γi<0.1的点。
我们还对点置信度[30]施加了一个稀疏性损失:

这迫使置信度值接近于零或1。如图4所示,这种剪枝技术可以去除离群点,减少相应的伪影。

图4。我们的神经点云和渲染新的视图,有或没有点修剪和生长(P&G)。当使用从我们的模型或COLMAP[44]重建的点云时,P&G改进了几何图形和渲染结果。
Point growing.
我们还提出了一种新的技术来增长新的点来覆盖原始点云中缺失的场景几何。与直接利用来自现有点的信息的点剪枝不同,增长点需要在不存在点的空区域中恢复信息。我们通过基于Point-NeRF表示建模的局部场景几何,逐步增长点云边界附近的点来实现这一点。
特别是,我们利用了每条射线的阴影位置(xj in Eqn. 1)在射线行进ray marching中取样,以识别新的候选点。具体来说,我们确定了沿射线具有最高不透明度的阴影位置xjg:

我们计算![]() 作为xjg到它最近的神经点的距离。
作为xjg到它最近的神经点的距离。
对于行进射线 marching ray,我们在xjg处增加一个神经点,如果
这意味着该位置位于表面附近,但远离其他神经点。通过重复这种增长策略,我们的辐射场可以扩展到覆盖初始点云中缺失的区域。点增长特别有利于用像COLMAP这样不密集的方法重建的点云(见图4)。我们表明,即使在只有1000个初始点的极端情况下,我们的技术也能够逐步增加新的点,并合理地覆盖物体表面(见图5)。

图5。从椅子场景中的1000个随机采样的COLMAP点开始,我们的点增长机制可以帮助完成几何图形,并在只有RGB图像的监督下生成高质量的新视图。
5. Implementation details
Network details.
我们对每点处理网络Gf的相对位置和每点特征以及网络R的观察方向应用频率位置编码。我们从网络Gf中不同分辨率的三层中提取多尺度图像特征,得到一个具有56个(8+16+32)通道的向量。此外,我们还从每个输入视点添加了相应的查看方向,以处理与视图相关的效果。因此,我们最终的每点神经特征是一个59通道向量。请参考我们的补充材料的网络架构和神经点查询的细节。
Training and optimization details
我们在DTU数据集上训练我们的完整管道,使用与PixelNeRF和MVSNeRF相同的训练和测试分割。我们首先使用类似于原始MVSNet论文[59]的地面真实深度,对基于MVSNet的深度生成网络进行预训练。然后,然后我们用L2渲染损失Lrended从端到端训练我们的完整管道,利用地面真实值监督我们的渲染像素(通过Eqn。1),得到我们的 Point-NeRF重建网络。使用Adam[22]优化器训练我们的完整管道,初始学习率为5e−4。我们的前馈网络需要0.2秒才能从三个输入视图中生成一个点云。
在每个场景的优化阶段,我们采用了一个结合了渲染和稀疏性损失的损失函数

我们在所有的实验中都使用了a = 2e−3。我们每10K迭代进行点增长和剪枝,以实现最终的高质量重建。
6. Experiments
6.1. Evaluation on the DTU testing set.
我们在DTU测试集上评估我们的模型。我们从直接网络推理和每个场景微调优化中生成了新的视图合成,并将其与之前的最新方法进行了比较,包括PixelNeRF[62]、IBRNet[53]、MVSNeRF[8]和NeRF[35]。IBRNet和MVSNeRF利用类似的每场景微调;我们用10k次迭代对所有方法进行微调,以进行比较。此外,我们展示了我们的结果,只有1k次迭代,以证明优化效率。
6.2. Evaluation on the NeRF Synthetic dataset.
6.3. Evaluation on the Tanks & Temples and the ScanNet dataset.
我们比较了Tanks & Temples上的Point-NeRF与NSVF和ScanNet数据集。更多的比较请参考补充资料。

表3。对坦克和寺庙和ScanNet数据集的定量结果(PSNR/SSIM/LPIPSAlex)。
6.4. Additional experiments.
Converting COLMAP point clouds to Point-NeRF
Point growing and pruning

表1。将我们的Point-NeRF与基于DTU数据集[18]上的基于辐射的模型[29,32,53]和基于点的渲染模型[2]与[8]中引入的新视图合成设置进行比较。下标表示优化过程中的迭代次数。

表2。在合成nerf数据集[32]上,点nerf与基于辐射的模型[29,32,53]和基于点的渲染模型[2]的比较。下标表示迭代的次数。我们的模型不仅在200K步后收敛时超过了其他方法(Point-NeRF200K),而且超过了IBRNet[53],并且在仅优化20K步(Point-NeRF20K)时与NeRF[35]相当。我们的方法还可以基于诸如COLMAP(Point-nerfcol200K)等方法重建的点云来初始化辐射场。
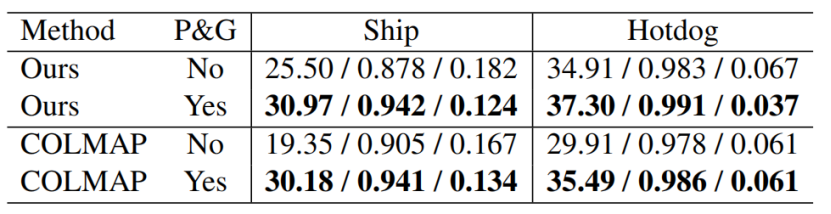
表4。有无点修剪和生长的定量结果(PSNR/SSIM/LPIPSVgg)。当使用我们生成的点或由COLMAP[44]生成的点云时,这些改进是显著的。
7.结论
在本文中,我们提出了一种新的高质量的神经场景重建和渲染的方法。我们提出了一种新的神经场景表示法Point-NeRF,它用一个神经点云来模拟一个体积辐射场。通过直接网络推理,我们从输入图像中直接重建了一个良好的Point-NeRF初始化,并表明我们可以有效地调整一个场景的初始化。这使得高效的Point-NeRF重建,每个场景只有20-40min的优化,导致渲染质量相当于甚至超过NeRF,which需要更长的训练时间(20+小时)。我们还提出了新的有效的生长和修剪技术来实现每个场景的优化,显著地改进了我们的结果,并使我们的方法在不同的点云质量下健壮。我们的Point-NeRF成功地结合了经典点云表示和神经辐射场表示的优势,为一个高效和真实的实际场景重建解决方案迈出了重要的一步。














 590
590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









