







ShaRF: Shape-conditioned Radiance Fields from a Single View
Abstract
我们提出了一种方法来估计神经场景表示的对象只给定一个单一的图像。我们的方法的核心是估计物体的几何支架,并将其作为重建底层辐射场的指导。我们的公式是基于生成过程,首先将潜在代码映射到体素化形状voxelized shape,然后将其渲染为图像,对象的外观由第二个潜在代码控制。在推理过程中,我们优化了潜在代码和网络,以拟合一个新对象的测试图像。形状和外观的显式分离允许我们的模型对给定的一幅图像进行微调。然后,我们可以以几何上一致的方式呈现新的视图,它们忠实地表示输入对象。此外,我们的方法能够推广到训练领域之外的图像(更真实的渲染,甚至真实的照片)。最后,推断出的几何支架geometric scaffold本身就是对物体三维形状3D shape的精确估计。我们在几个实验中证明了我们的方法在合成图像和真实图像中的有效性。
1. Introduction
These representations overcome specific shortcomings that traditional representations face (e.g. space discretization for voxels, requirement for accurate geometry for textured meshes).
这些表示克服了传统表示所面临的特定缺点(例如,体素的空间离散化,对纹理网格的精确几何形状的要求)。
在本文中,我们提出了一种生成方法,用于从单个图像的逆渲染,使用显式和隐式表示。在我们的方法中,渲染图像中一个对象的几何和外观是由两个网络控制的。第一个网络将一个潜在的代码映射到一个显式的体素化的形状。第二个网络隐式地估计物体周围的辐射场(任何点的颜色和体积密度),使用估计的形状作为几何支架,以及控制外观的第二个潜在代码。
因此,辐射场是由这两个因素决定的。最终的图像是通过向场景投射光线并累积颜色和密度到像素值来渲染的。在对网络进行训练后,我们的模型可以输入一个新的测试图像,并通过重新渲染来估计其几何和外观属性:我们对潜在代码进行优化,并微调网络参数,使渲染的图像与输入相匹配。在这一点上,我们的模型已经准备好渲染测试对象的新视图,因为我们的模型中的隐式表示和显式表示都知道它的三维形状。
通过对一个物体使用显式的几何表示,我们引导外观重建聚焦于其表面。对象周围的空卷不能提供有用的信息。此外,在对一个测试图像进行推理时,我们只有一个视图。因此,我们不能像之前的工作那样(Mildenhalletal.,2020),依赖多视图一致性来进行精确的形状/外观重建,我们的几何支架弥补了这一一点。
总之,我们的贡献是:
- a new model to represent object classes that enables reconstructing objects from a single image,新模型表示对象类,使重建对象从一个图像
- a new representation that combines an intermediate volumetric shape representation to condition a high fidelity radiance field新表示结合中间体积形状表示条件高保真辐射场
- optimization and fine-tuning strategies during inference that allow estimating radiance fields from real images优化和微调策略在推理,允许估计辐射场从真实图像。
2.Related Work
Scene Representation.
Neural Rendering.
3D Reconstruction.
Concurrent Work. 同时工作。
3. Background
Radiance fields.
Rendering a new view.
4. Our method
在本节中,我们将介绍我们的图像合成生成框架,以及如何用于单图像辐射场估计。
4.1. Generative Neural Rendering
我们的方法的目标是从单一图像估计一个物体的辐射场,这样我们可以渲染新的视图。我们通过生成神经渲染过程来近似图像形成过程,该过程基于两个潜在变量,一个控制物体的形状,另一个控制其外观(图2)。我们现在描述一个完整过程通过模型。
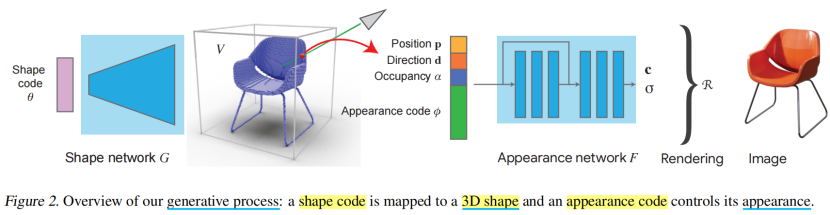

首先,一个形状网络G将一个潜在代码θ映射为一个以体素网格V∈R1283表示的三维形状。每个体素i包含一个标量αi∈[0,1],表示其占用率:G(θ)⇒V。体素网格指定对象存在的世界坐标中的连续体积区域。
其次,我们估计了一个辐射场,即该区域内任何一个三维点p的颜色c和密度σ,使用一个外观网络appearance network F,它扩展了(1):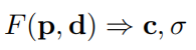
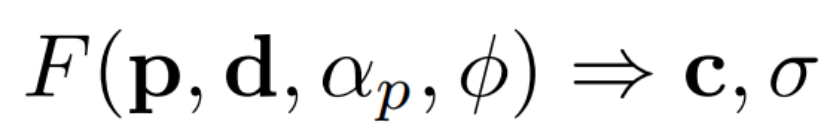
这个扩展的辐射场现在基于两个元素:(1)是形状网络 shape network产生的体素化形状V voxelized shape V,通过p点处的占用值αp;(2)是一个控制对象外观的潜在代码φ。
最后,我们可以用辐射场的渲染过程R来合成一个新的物体视图.请注意,两个网络G和F之间的所有操作都是完全可微的。
我们的生成公式带来了几个优点。它建立了物体的内在属性(形状和外观),从而估计它们是有效和精确的。通过使用显式几何支架,我们条件网络F估计特定三维形状的辐射场。特别地,我们通过指示一个特定物体的占用率αp和外观潜在代码φ来指导网络估计物体表面上的适当颜色值。此外,在推理过程中,我们不能依赖于多视图约束,因为我们给定了一个单一的测试图像。在这种情况下,几何支架提供了有价值的三维信息,以引导辐射场估计到物体表面。最后,在G产生的形状支架上调节外观网络,通过构造来增强形状和外观潜在空间之间的分离,这在推广到不同的领域时是有益的(Sec。5.3).
4.2. Shape Network
我们使用一个离散的体素网格来表示形状的支架。体素表示与卷积架构自然集成,所选择的分辨率在几何细节和内存需求之间提供了良好的平衡(我们的128^ 3分辨率足以捕获单个对象的细节)。此外,对于体素网格范围内的任意点p,我们都可以利用三线性插值有效地估计其占用值αp。这个过程是可微的,允许形状网络G和外观网络F之间的通信。此外,该支架为外观网络提供了一个强大的几何信号,通过αp将其作为一个输入,并通过等式 (4)实现对物体表面上更多点的采样.
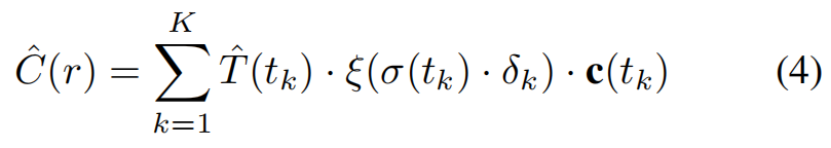
架构:
该网络由一系列完全连接的层组成,然后是一系列的三维卷积块(具有ReLU和批处理标准化层;详见补充材料)。该网络将一个形状的潜在码θ映射到一个体素化的形状V。
训练:
作为训练数据,我们使用一个ShapeNet类的三维对象(例如椅子或汽车),每个实例都有自己的形状潜在代码θ。在训练过程中,我们同时优化了网络G和这些潜在代码θ(见图2),类似于生成潜在优化(GLO)技术(Bojanowskietal.,2018)。损失包括三部分。首先,预测的Vˆ和地面真实体素网格V之间的加权二值交叉熵损失(Brock等人,2016)。其次,我们在体素上使用对称损失,因为我们假设对象是左右对称的。最后,我们通过将估计的体素投影到两个随机视图j中,并与相应的物体轮廓Sj进行比较,从而纳入了一个体素到图像的投影损失。总体损失为:
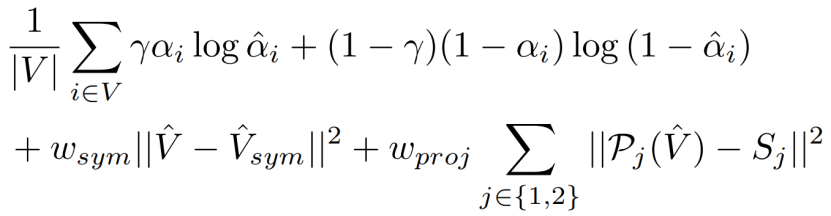
式中,ˆαi为体素i上的占用率,wsym和wproj分别为对称性和投影损失的权值,γ为惩罚假阴性的权值,Pj是物体轮廓在随机视图j上的可微投影。后一种操作类似于等式(4),没有c因子。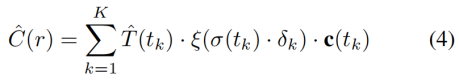
4.3. Appearance Network.
我们的外观网络F模型的辐射场(7)![]() 类似于NeRF(1)
类似于NeRF(1)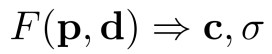 ,但扩展到包括额外的条件反射输入:(a)为p处的占用值αp,由形状网络G估计,(b)为控制对象外观的外观潜在码φ。
,但扩展到包括额外的条件反射输入:(a)为p处的占用值αp,由形状网络G估计,(b)为控制对象外观的外观潜在码φ。
架构:
外观网络F与NeRF具有相似的架构。它由一系列完全连接的层(后面是ReLU)组成,它们将上述输入映射到一个RGB颜色c和一个密度值σ。
训练:
作为训练数据,我们使用与Sec4.2.中相同的3D对象。对于每个对象,我们渲染N=50个视图,对于每个视图,我们采样通过其像素的随机射线。请注意,外观潜在代码φ表示单个对象,因此该代码在其所有视图之间共享。最终的数据包括来自每幅图像的所有射线,以及对应的形状潜在码θ、外观潜在码φ和每条射线的地面真实像素颜色。
在Sec.4.2,我们使用GLO对每个训练对象的外观潜在码φ进行优化。对于训练集中的每一个射线r,我们采用分层采样点(Mildenhalletal.,2020)。对于每个采样的3D点p,我们从体素网格G(θ)(p)=V(p)中估计其占用值αp。这些被输入到外观网络F,以及该对象的观看方向d和外观代码φ。网络输出颜色c和密度σ,然后沿射线r累积,如等式(4)给出了像素的最终颜色。我们通过最小化损失(6)来训练外观网络F,并将最终的颜色与地面真相进行比较。
F的训练取决于体素网格V的占用值。虽然我们可以直接使用形状网络G(θ)的V输出,但我们首先使用地面真实体素作为V进行预训练F,然后对G(θ)估计的V进行微调,从而实现更高的渲染质量。
4.4. Inference on a test image
我们的模型本质上是一个渲染器,具有两个潜在代码θ,φ,它们控制输出图像中对象的形状和外观。模型是可微的任何路径从潜在的代码呈现图像,因此它可以用于逆任务:给定一个测试图像及其相机参数K,我们可以重建潜在的代码,然后使用它们来合成一个新的视图的对象。
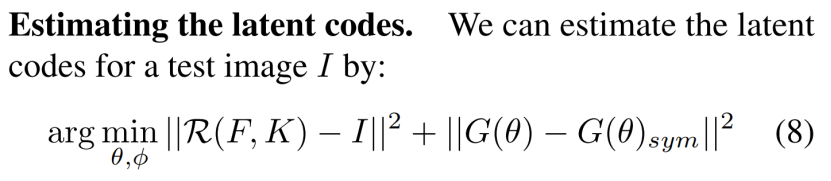
其中,R是来自Sec.3(“渲染新视图”)的渲染过程。请注意,来自等式(7)的F依赖于φ以及在θ上通过它的参数αp (Sec. 4.1).这个损失的第一项衡量了I和它重新呈现的版本之间的差异。因此,最小化这个术语意味着找到导致渲染测试图像的潜在代码θ,φ。第二项鼓励由G估计的体素网格是对称的。
Jointly optimizing latent codes and networks.
在实践中,上述目标难以优化。隐式假设是输入图像I可以用从各自的潜在空间采样的潜在码表示,并且可以使用梯度下降方法发现它们。当测试图像与训练集有本质差异时,外观潜码φ不能正确地表达其中的颜色。此外,形状网络G输出的体素网格往往缺乏较薄的细节。这两种现象导致了外观网络F的模糊渲染。
然而,我们观察到,最小化目标(8)的形状和外观网络G,F的参数,除了潜在代码θ,φ,可以导致更详细的形状重建和更准确的渲染,即使测试图像来自与训练集不同的领域。这对应于对网络G,F的微调超出了训练中发现的参数(Sec 4.2和4.3),允许过拟合这个特定的测试图像。
在实践中,我们通过实验设计了最好的结果可以通过一个两阶段的优化过程来达到的结果,我们将在下面描述。
重要的是,请注意目标(8)不需要除了相机参数之外的任何注释(例如,没有地面真实的3D形状)。因此,优化它,w.r.t.网络参数即使在测试时也是一个有效的操作。
Stage 1: Shape code θ and network G
在第一阶段,我们的重点是优化形状码和网络参数,以对测试图像中的对象进行准确的形状估计。为了实现这一点,我们使用外观网络F作为一个神经渲染器,我们可以反向传播来测量图像重建损失(8)。具体地说,我们保持了F的固定,并优化了形状码θ、形状网络G和外观码φ,以获得最佳的图像I重建(8)。换句话说,我们要求形状代码θ和网络G产生一个精确的形状,这样当它用外观代码φ和网络F呈现时,它会再现输入图像I。
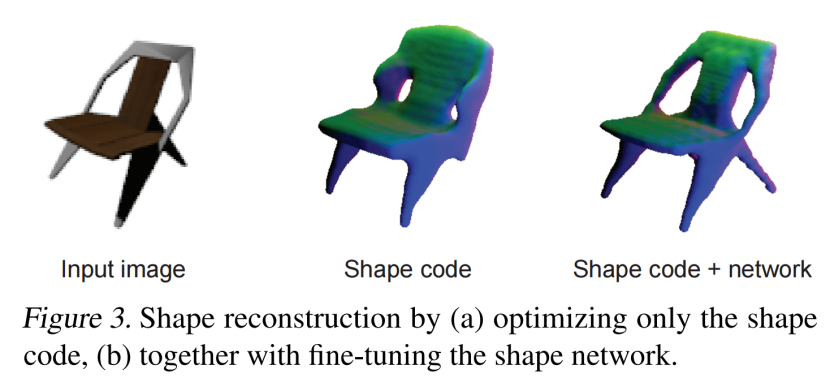
网络G的微调是精确重构的必要元素,因为只优化形状码θ就会导致近似重构和缺少几何细节(图3)。在实验部分中,我们进一步评估了不同的优化策略的性能。
Stage 2: Appearance code φ and network F
在阶段2中,我们对外观代码φ和网络F进行了优化,同时保持形状代码和网络固定在阶段1的输出上。同样,我们的目标是通过最小化(8),使渲染R尽可能接近于输入图像I。换句话说,我们要求外观代码φ和网络F渲染形状V=G(θ)(在阶段1中估计),以便匹配输入图像I。
对外观网络F的微调也很重要,因为它可以更准确地重建输入图像(图4)。当测试图像I与训练数据有显著差异时,这一点尤其明显,在这种情况下,对外观代码φ的优化是不够的。我们在Sec5.3.中对这个设置进行了全面的评估。
Rendering a new view K’.
到目前为止,我们已经找到了形状和外观代码和更新的网络,可以重新渲染测试图像i。为了渲染一个由相机参数K’指定的新视图i’,我们使用R(F,K’)中更新的潜在代码和网络。请注意,我们的优化和微调避免了琐碎的解决方案,例如,当测试图像I被准确地重新渲染,但新的视图是错误的。我们的方法通过(1)结合对象类的先验知识,使用学习到的潜在形状和外观模型(G,F)来实现这一点;(2)以对称损失的形式添加对称先验(Eq.(8));(3)定制F,通过在几何支架上调节物体来聚焦于物体的表面。
6. Conclusion
本文提出了一种利用显式表示和隐式表示从单幅图像中估计辐射场的方法。我们的生成过程为一个对象构建一个几何支架,然后用于估计辐射场。通过反演这个过程,我们恢复了显式参数和隐式参数,并使用它们来合成新的视图。我们在一个标准的新视图合成数据集上展示了最先进的结果,并演示了对与训练数据显著不同的图像的泛化。














 3365
3365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









